Convolutional Neural Networks and Recurrent Neural Networks are widely used in machine learning today. However, they are typically used for completely different use cases.

What are the principles and differences of CNN and RNN in artificial intelligence? In machine learning, each type of artificial neural network is tailored for specific tasks. Below, we will introduce two types of neural networks: Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN).
The main difference between CNN and RNN is their ability to handle temporal information or sequential data (such as sentences). Additionally, convolutional neural networks and recurrent neural networks are used for completely different purposes, and the structure of the neural networks themselves also differs to accommodate those different use cases.
CNNs use filters within convolutional layers to transform data. RNNs reuse activation functions from other data points in the sequence to generate the next output in the sequence.
Although this is a frequently asked question, once you look at the structure of the two neural networks and understand their uses, the differences between CNN and RNN become quite clear.
Now, let’s take a look at CNNs and how they are used to interpret images.
Convolutional Neural Networks are among the most common neural networks used in computer vision to recognize objects and patterns in images. One of their defining features is the use of filters in the convolutional layers.
CNNs have a unique layer called the convolutional layer, which separates them from RNNs and other neural networks.

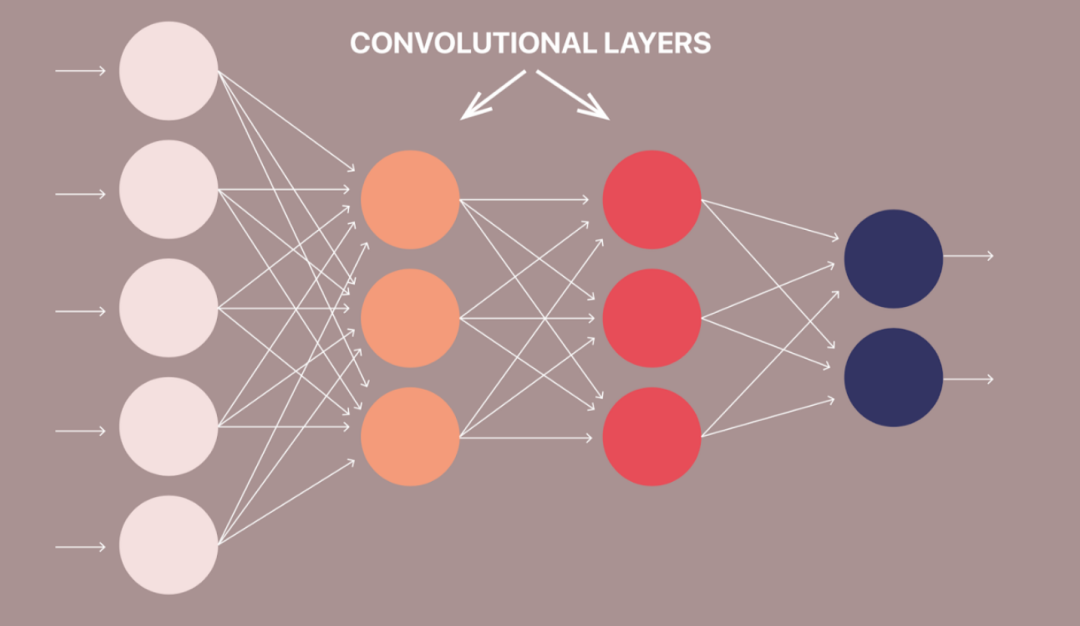
What are the principles and differences of CNN and RNN in artificial intelligence? In the convolutional layer, the input is transformed before being passed to the next layer. CNNs use filters to transform data.
The filters in a CNN are simply a matrix of random numbers, as shown in the following image.


What are the principles and differences of CNN and RNN in artificial intelligence? The number of rows and columns in the filters can vary, depending on the use case and the data being processed. In the convolutional layer, multiple filters move across the image. This process is called convolution. The filters convolve the pixels of the image, changing their values before passing the data to the next layer of the CNN.
To understand how filters transform data, let’s look at how CNNs are trained to recognize handwritten digits. Below is an enlarged version of the 28 x 28 pixel image of the number 7 from the MNIST dataset.

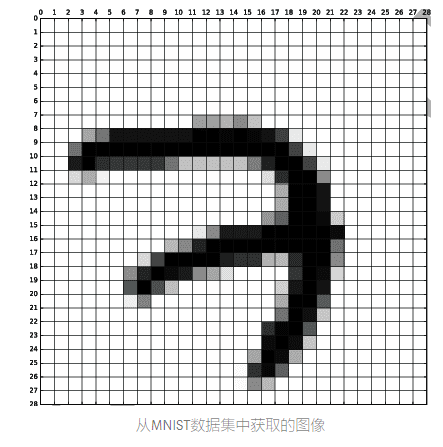
What are the principles and differences of CNN and RNN in artificial intelligence? The image obtained from the MNIST dataset.
Below is the image that converts the same image into its pixel values.


What are the principles and differences of CNN and RNN in artificial intelligence? When the filter convolves through the image, the value matrix in the filter aligns with the pixel values of the image, and a dot product of these values is obtained.


What are the principles and differences of CNN and RNN in artificial intelligence? The filter moves or “convolves” over each 3 x 3 pixel matrix until all pixels are covered. Each computed dot product is then used as input for the next layer.
Initially, the values in the filters are random. As a result, the first pass or convolution becomes the training phase, and the initial output is not very useful. After each iteration, the CNN automatically adjusts these values using the loss function. As training progresses, the CNN continuously adjusts the filters. By adjusting these filters, it can distinguish edges, curves, textures, and more patterns and features in the image.
Although this is an impressive feat, to achieve the loss function, the CNN must be provided with examples of correct outputs in the form of labeled training data.
When transfer learning cannot be applied, many convolutional neural networks require a large amount of labeled data.
If the CNN problem still cannot be resolved, you can check out Jeremy Howard’s great but lengthy video lectures on Fast.ai.
CNNs excel at interpreting visual data and non-sequential data. However, they do not perform well in interpreting temporal information, such as videos (which are essentially sequences of single images) and blocks of text.
Entity extraction in text is a good example of how different parts of data in a sequence can influence each other. For entities, the words before and after the entity in a sentence directly influence how they are classified. To handle temporal or sequential data, such as sentences, we must use algorithms designed to learn from past data and “future data” in the sequence. Fortunately, Recurrent Neural Networks do just that.

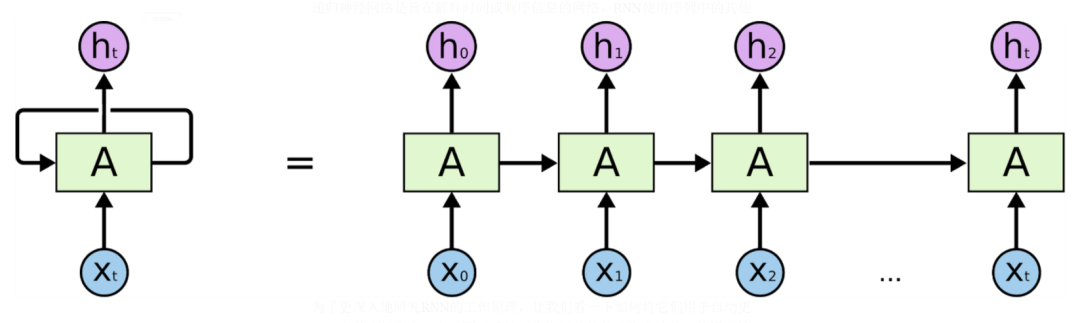
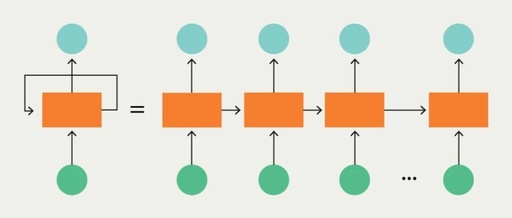
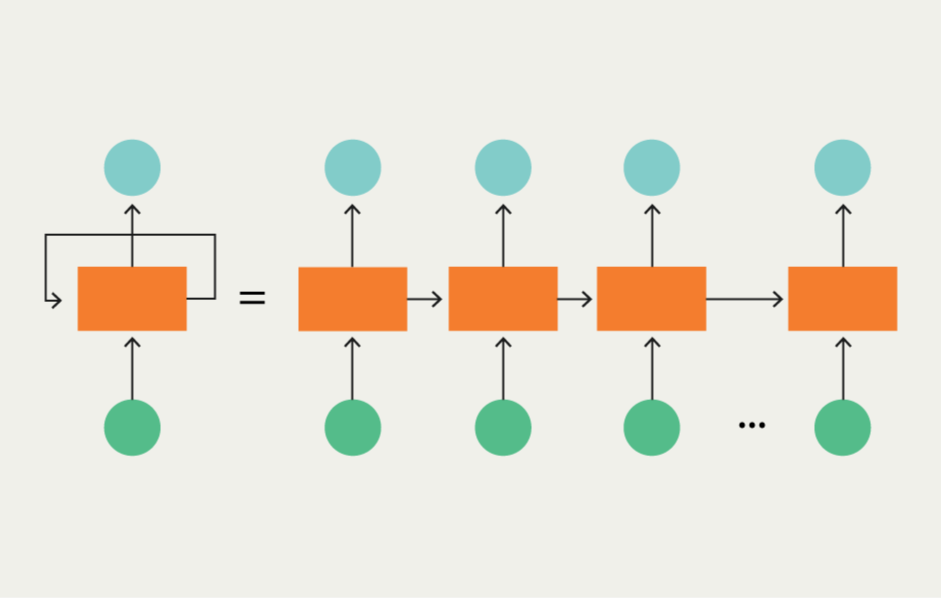
What are the principles and differences of CNN and RNN in artificial intelligence? The structure of Recurrent Neural Networks.
Recurrent Neural Networks are networks designed to interpret temporal or sequential information. RNNs use other data points in the sequence for better predictions. They achieve this by accepting input and reusing activations from previous or subsequent nodes in the sequence. As mentioned earlier, this is important for tasks like entity extraction. Consider the following text:
President Roosevelt is one of the most influential presidents in American history. However, Roosevelt Street in Manhattan is not named after him.
In the first sentence, Roosevelt should be marked as a personal entity. In the second sentence, it should be marked as a street name or location. Without considering the preceding word “president” and the following word “street,” it is impossible to know these distinctions.
To delve deeper into how RNNs work, let’s look at how they are used for autocorrect. At a basic level, an autocorrect system takes the word you type as input. Using that input, the system can predict whether the spelling is correct. If the word does not match any words in the database or does not fit in the context of the sentence, the system will predict what the correct word might be. Let’s visualize how this process works with RNNs:

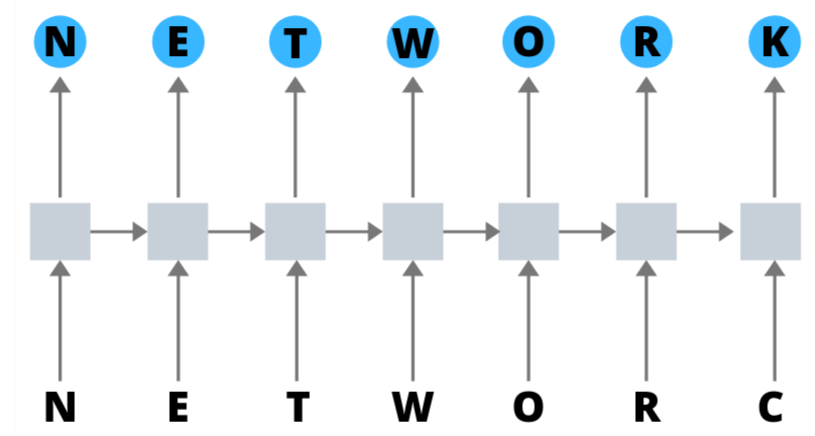
What are the principles and differences of CNN and RNN in artificial intelligence? RNNs will accept two input sources. The first input is the letters you type. The second input will be the activation function corresponding to the letters you previously typed. Suppose you want to input “network” but mistakenly type “networc.” The system takes the previously typed letters “networ” and the current letter “c” as input. Then it predicts “k” as the correct output for the last letter.
If you like, click the follow button at the top left.
Some text and images are sourced from the internet; please contact us for removal if there are copyright issues!