Neural networks are the carriers of deep learning, and among neural network models, the most classic non-RNN model belongs here. Although it is not perfect, it possesses the ability to learn historical information. Whether in the encode-decode framework, attention models, self-attention models, or the more powerful Bert model family, they all stand on the shoulders of RNNs, continuously evolving and becoming stronger.
This article elaborates on all aspects of RNNs, including model structure, advantages and disadvantages, various applications of RNN models, commonly used activation functions, the shortcomings of RNNs, and how GRU and LSTM attempt to address these issues, as well as RNN variants.
The main feature of this article is its illustrated version, followed by concise language and comprehensive summaries.
Overview
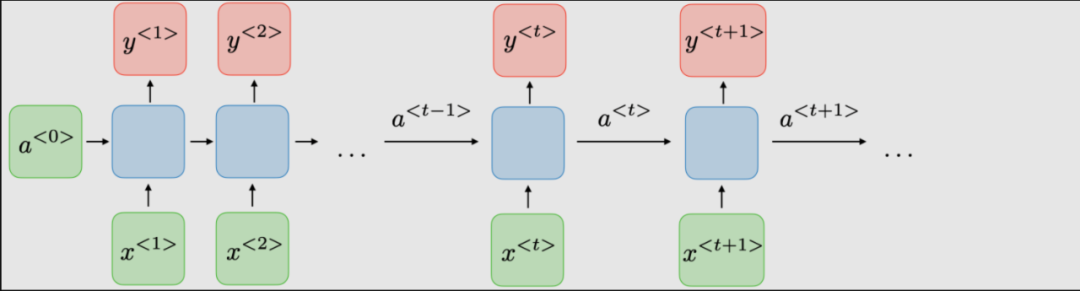
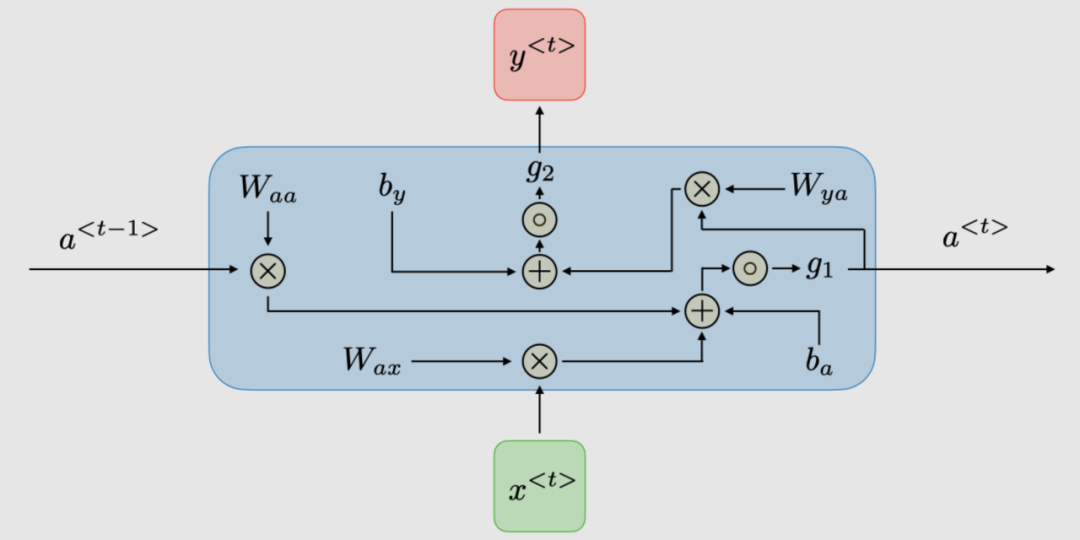
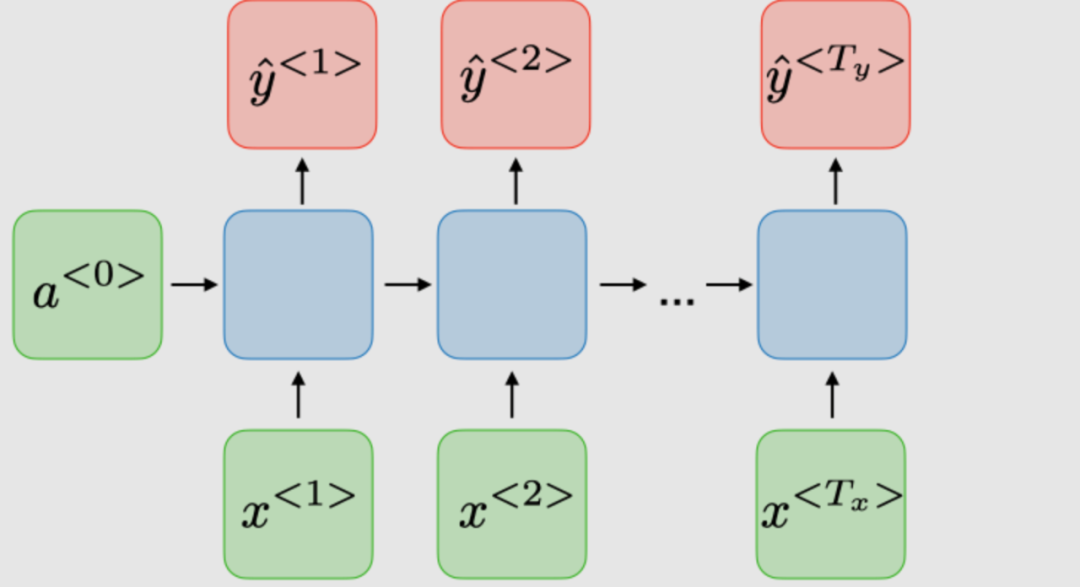
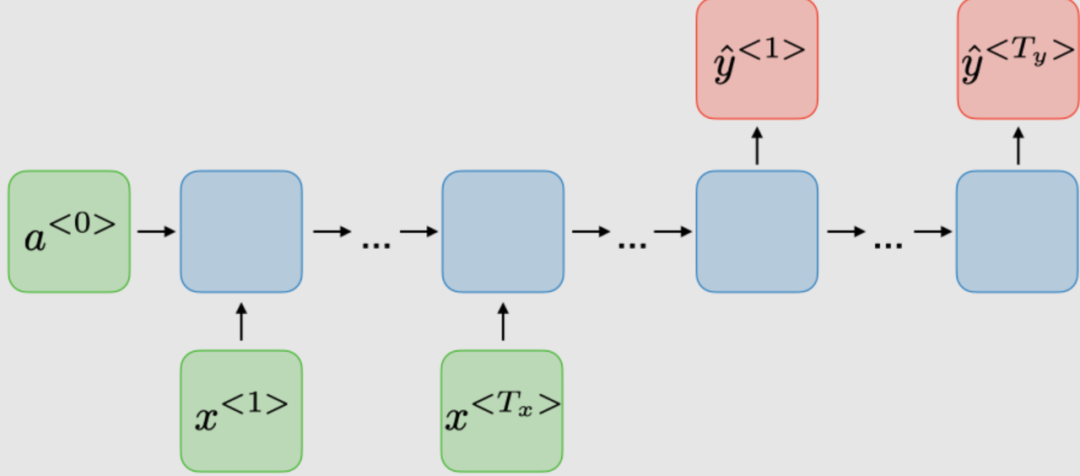
The architecture of traditional RNNs. Recurrent Neural Networks, also known as RNNs, are a class of neural networks that allow previous outputs to be used as inputs, while having hidden states. They are typically represented as follows:
For each time step, the activation function, output is expressed as:
Here, is the shared weight coefficient of the time dimension network.
is the activation function.
The table below summarizes the advantages and disadvantages of typical RNN architectures:
| Advantages | Disadvantages |
|---|---|
| Handles arbitrary length inputs | Slow computation speed |
| Model shape does not change with input length | Difficult to capture information from long ago |
| Computation considers historical information | Cannot consider any future inputs for the current state |
| Weights shared over time |
Applications of RNNs
RNN models are primarily applied in the fields of natural language processing and speech recognition. The table below summarizes different applications:
| RNN Type | Illustration | Examples |
|---|---|---|
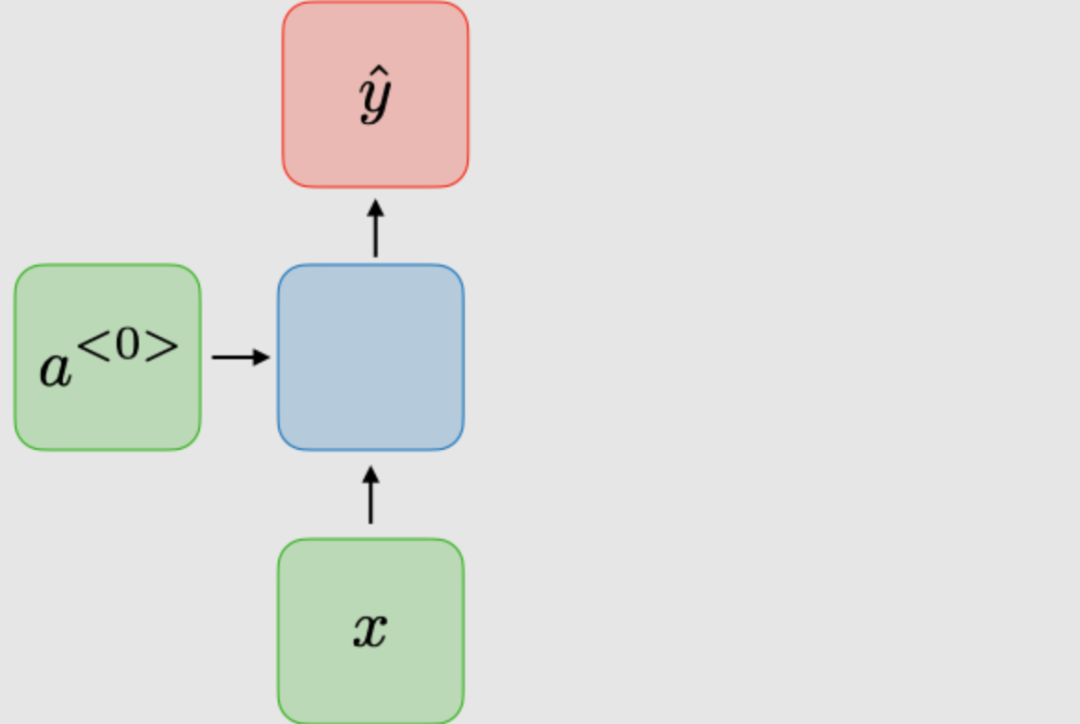
| 1-to-1 |
|
Traditional Neural Networks |
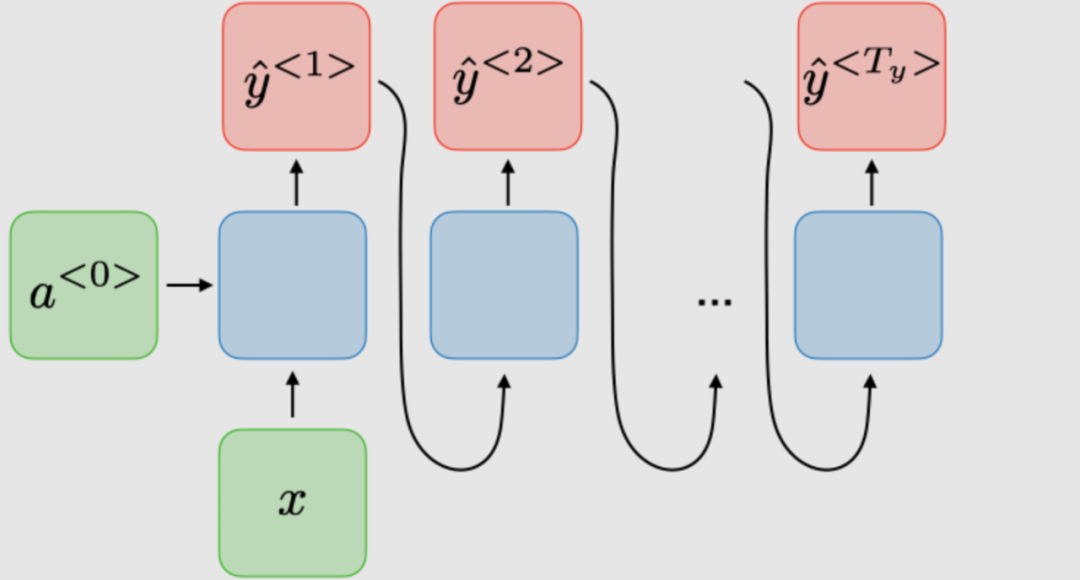
| 1-to-Many |
|
Music Generation |
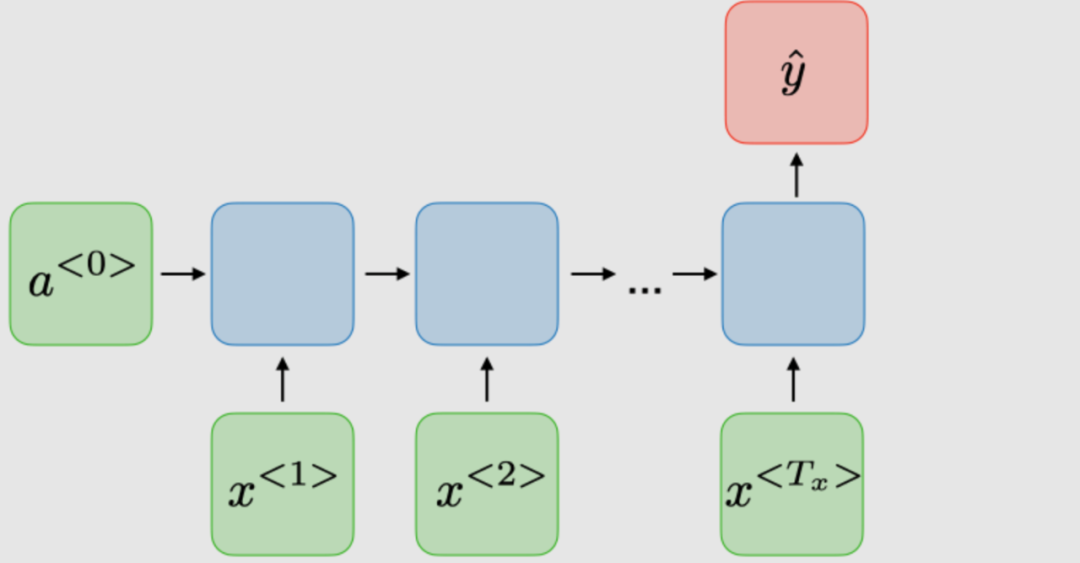
| Many-to-1 |
|
Sentiment Classification |
| Many-to-Many |
|
Named Entity Recognition |
| Many-to-Many |
|
Machine Translation |
Loss Function
For RNN networks, the loss function for all time steps is defined based on the loss at each time step, as follows:
Backpropagation Through Time
Backpropagation occurs at each time point. At time step, the partial derivative of the loss with respect to the weight matrix is represented as follows:
Handling Long-Short Dependencies
Commonly Used Activation Functions
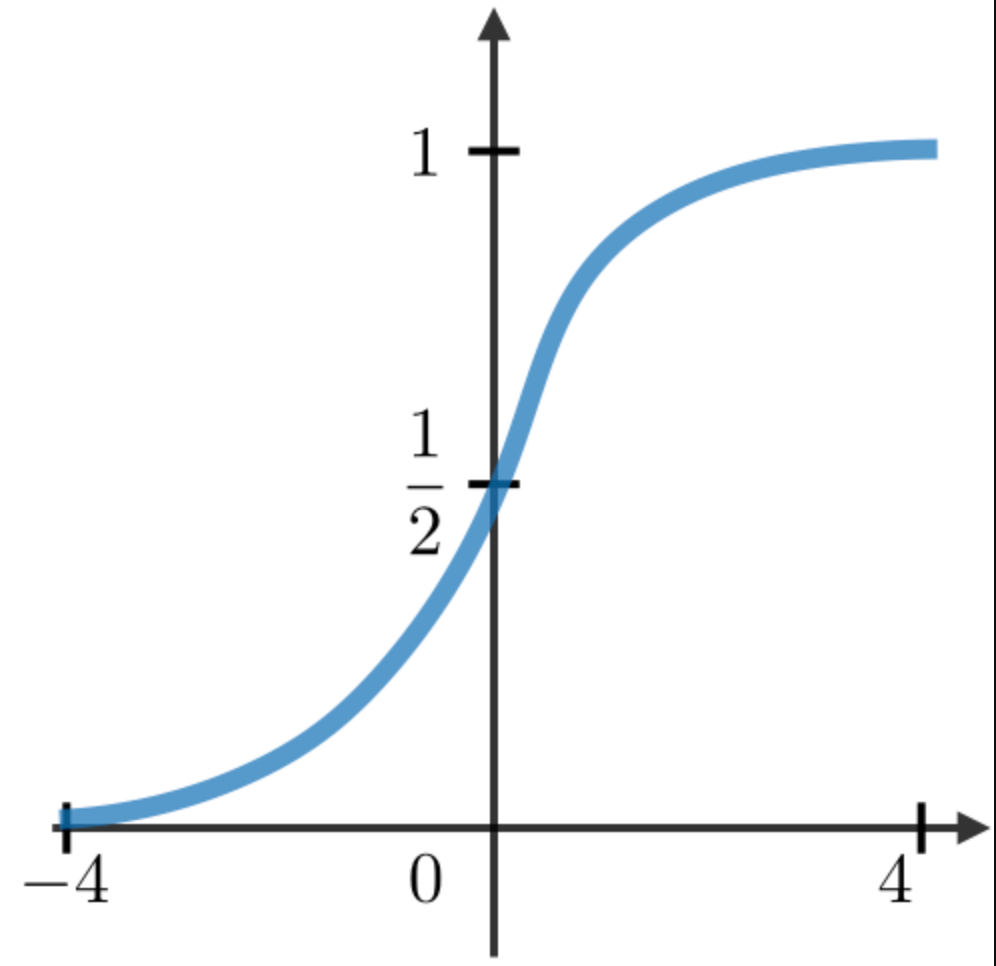
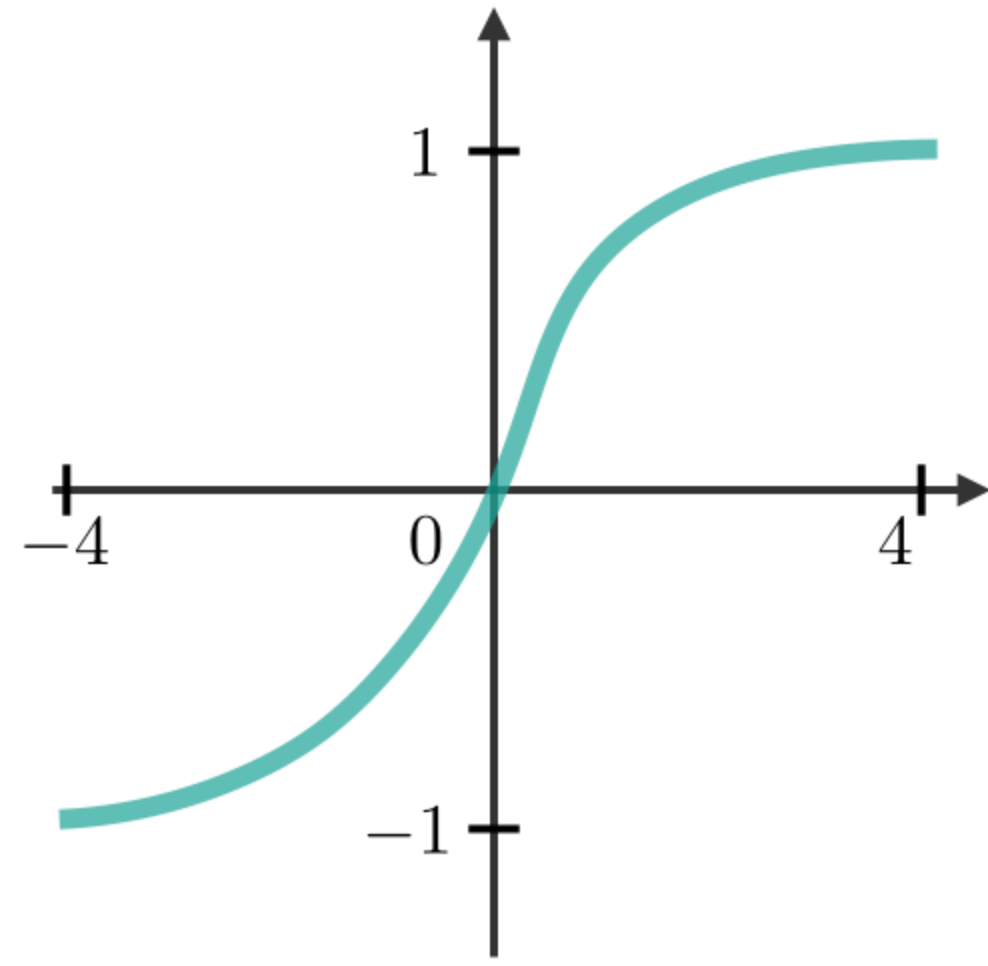
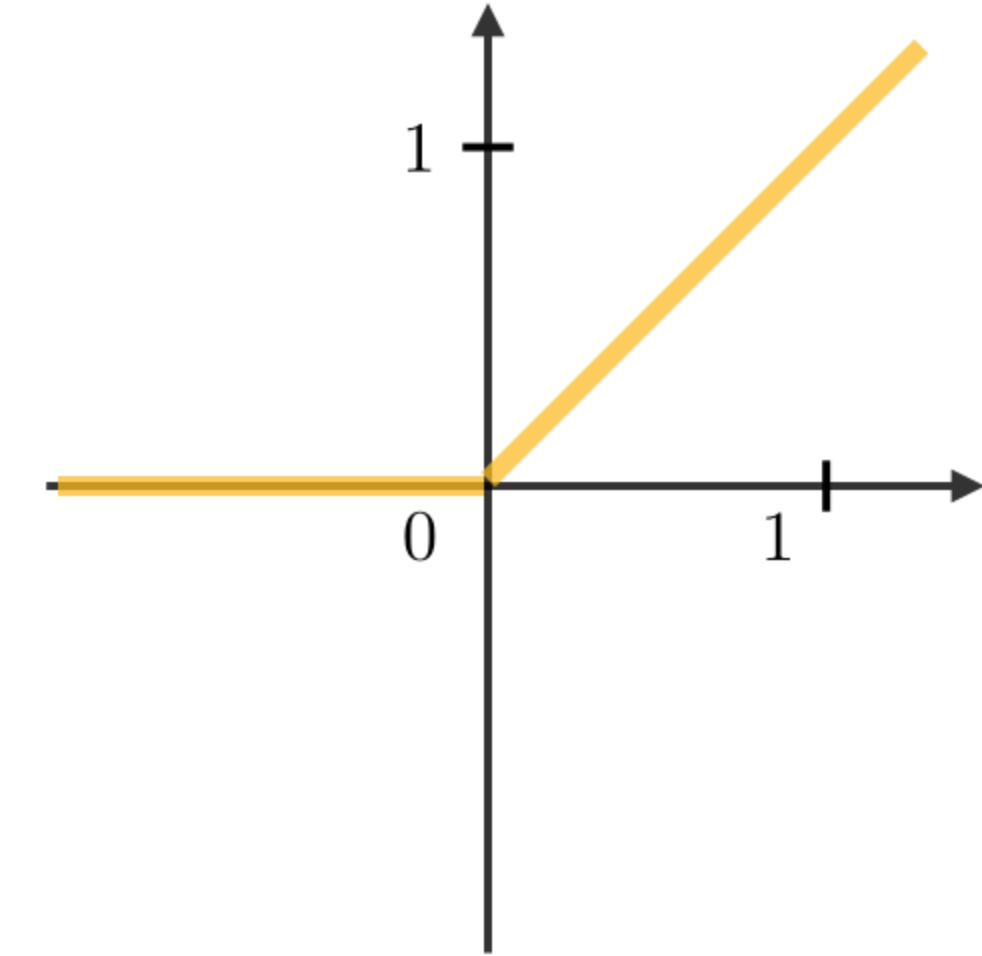
The most commonly used activation functions in RNN modules are described as follows:
| Sigmoid | Tanh | RELU |
|---|---|---|
|
|
|
|
Gradient Vanishing/Explosion
In RNNs, the gradient vanishing and explosion phenomena are often encountered. This occurs because it is difficult to capture long-term dependencies, as the multiplicative gradients can decrease/increase exponentially with the number of layers.
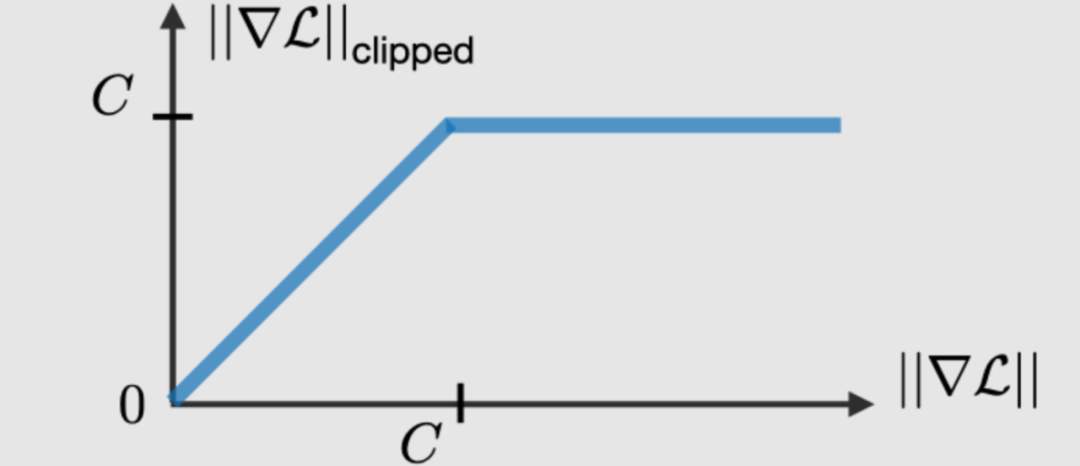
Gradient Clipping
Gradient clipping is a technique used to address the gradient explosion problem encountered during backpropagation. By limiting the maximum value of the gradient, this phenomenon is controlled in practice.
Types of Gates
To solve the vanishing gradient problem, specific gates are used in certain types of RNNs, and they usually have clear purposes. They are typically labeled as:
Where, is the gate-specific coefficient, which is a sigmoid function. The main content is summarized in the table below:
| Type of Gate | Function | Applications |
|---|---|---|
| Update Gate | How important is the past to the present? | GRU, LSTM |
| Reset Gate | Should past information be discarded? | GRU, LSTM |
| Forget Gate | Is it erasing a unit? | LSTM |
| Output Gate | How much of a gate is exposed? | LSTM |
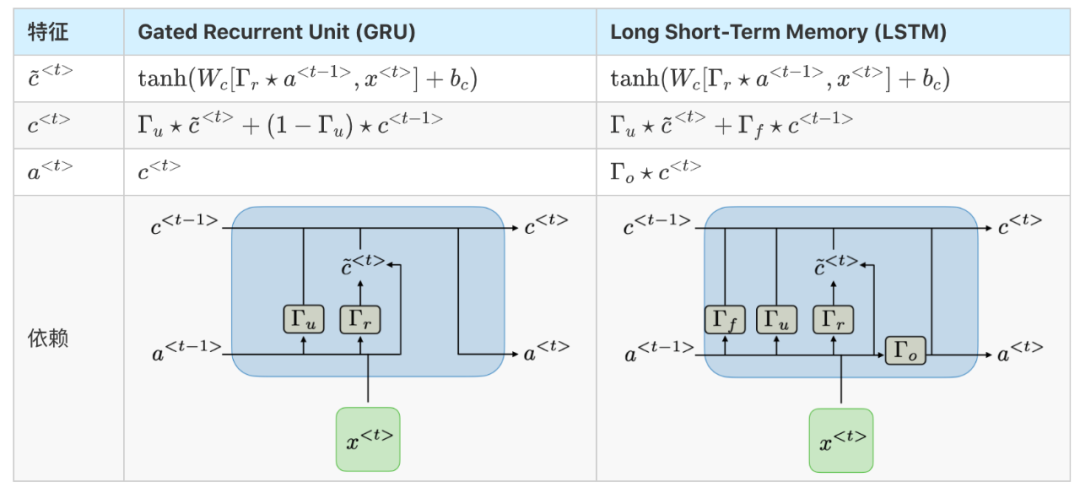
GRU/LSTM
Gated Recurrent Unit (GRU) and Long Short-Term Memory (LSTM) address the vanishing gradient problem encountered in traditional RNNs, with LSTM being a generalization of GRU. The table below summarizes the feature equations of each structure:
Variants of RNNs
The table below summarizes other commonly used RNN models:
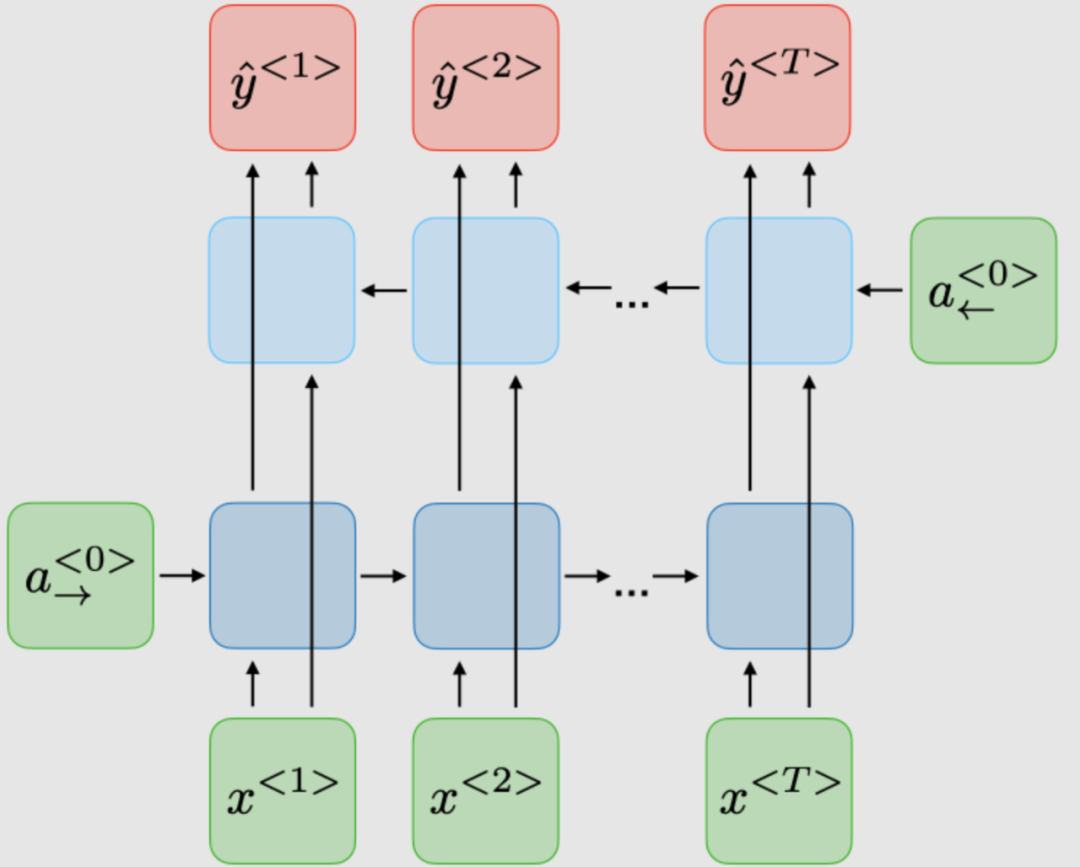
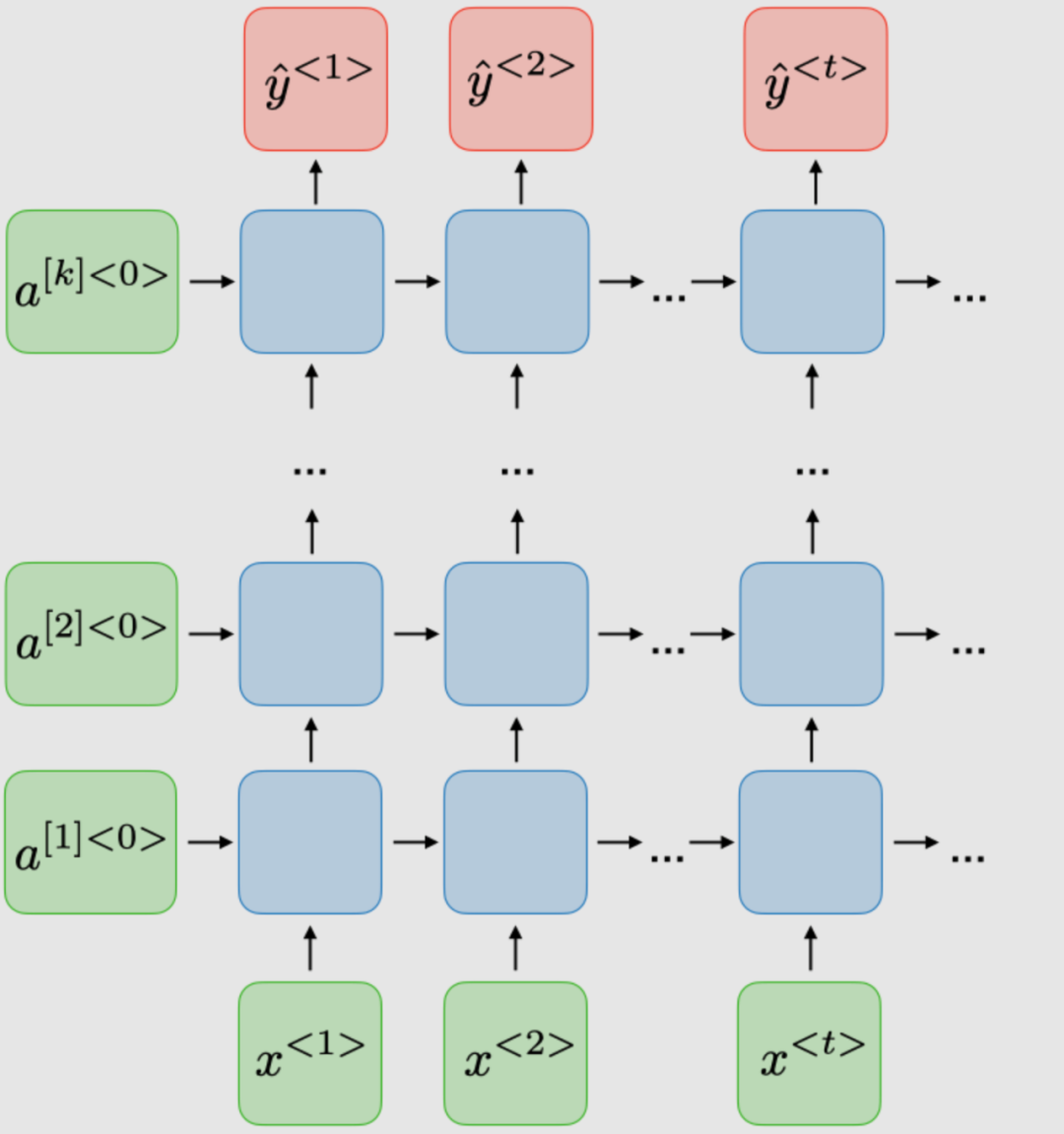
| Bidirectional (BRNN) | Deep (DRNN) |
|---|---|
|
|
|