Follow the public account “ML_NLP“
Set as “Starred“, heavy content delivered immediately!
Link | https://www.zhihu.com/question/325839123
Editor | Public Account of Machine Learning Algorithms and Natural Language Processing
This article is for academic sharing only. If there is infringement, please contact the background for deletion.
As someone who does CV, while learning about Transformers, I had the same question about QKV in Self-Attention: why define three tensors? I found this question and thought everyone explained it well, but it could be clearer. I have a rough understanding, but since creating diagrams is cumbersome and I have little experience, I’ll just share my understanding, which may not be accurate.
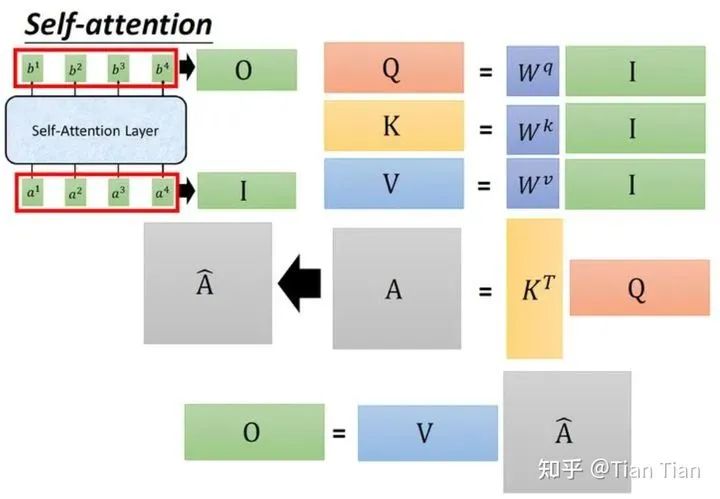
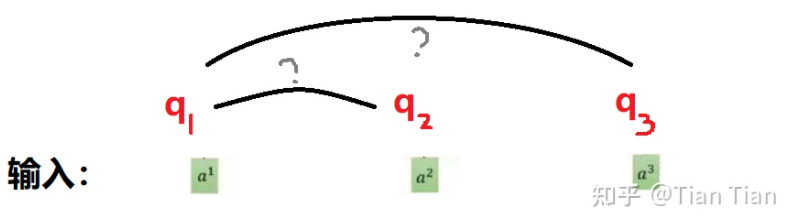
The attention mechanism is essentially about obtaining a weighted representation through training, and self-attention must find the relationship between words using a weight matrix. Therefore, it is definitely necessary to define a tensor for each input and then use multiplication between tensors to obtain the relationships between inputs. So, is it enough to define one tensor for each input? No! If each input has only one corresponding q, then after multiplying q1 and q2 to find the relationship a1 and a2, how do we store and utilize this result? Furthermore, is the relationship between a1 and a2 reciprocal? If a1 finds a2 and a2 finds a1, is there a difference? Defining just one tensor makes the model a bit too simplistic.
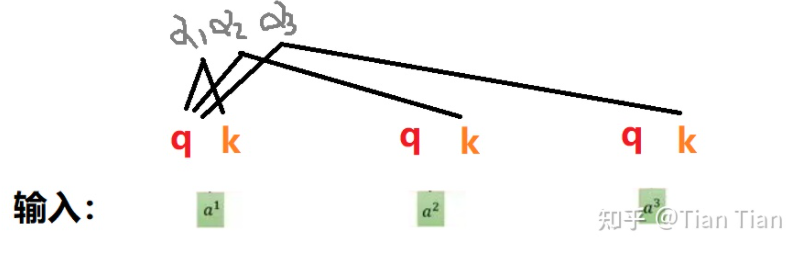
 One tensor is not enough, so we define two, thus we have q and k. You can understand q as representing oneself, used to find relationships with other inputs; k is understood as being used by others, specifically for inputs that come to find relationships with you. In this way, using your own q to multiply with others’ k (of course, it can also work with your own k) allows us to obtain the found relationship: the weight α.
One tensor is not enough, so we define two, thus we have q and k. You can understand q as representing oneself, used to find relationships with other inputs; k is understood as being used by others, specifically for inputs that come to find relationships with you. In this way, using your own q to multiply with others’ k (of course, it can also work with your own k) allows us to obtain the found relationship: the weight α.
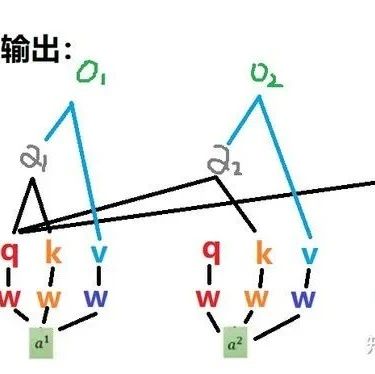
 Is it enough to define just q and k? Probably not. The relationships found need to be utilized; otherwise, they are useless.The weight α needs to be used to weight the input information to reflect the value of the found relationships. So, can we directly weight the inputs? This is not impossible, but it seems a bit direct and rigid. Therefore, we define a v. It’s important to know that v, like q and k, is obtained by multiplying the input a with a coefficient matrix. Thus, defining v adds another layer of learnable parameters to a, and then we weight the adjusted a to apply the relationships learned through the attention mechanism. Therefore, by multiplying α and v, we perform a weighting operation to ultimately obtain the output o.
Is it enough to define just q and k? Probably not. The relationships found need to be utilized; otherwise, they are useless.The weight α needs to be used to weight the input information to reflect the value of the found relationships. So, can we directly weight the inputs? This is not impossible, but it seems a bit direct and rigid. Therefore, we define a v. It’s important to know that v, like q and k, is obtained by multiplying the input a with a coefficient matrix. Thus, defining v adds another layer of learnable parameters to a, and then we weight the adjusted a to apply the relationships learned through the attention mechanism. Therefore, by multiplying α and v, we perform a weighting operation to ultimately obtain the output o.
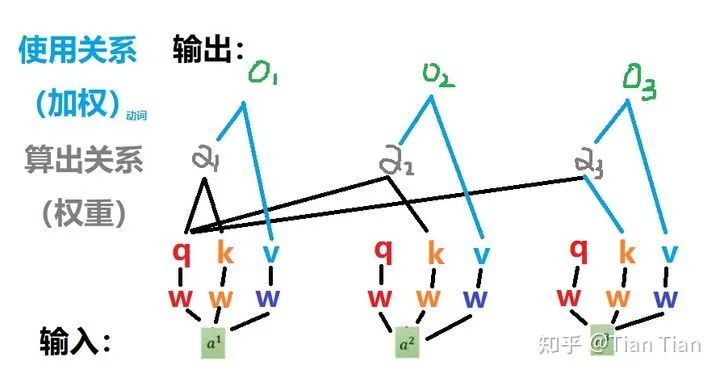 In summary, my feeling is that defining these three tensors serves two purposes: one is to learn the relationships between inputs and find and record the relationship weights between entities, and the other is to introduce learnable parameters under a reasonable structure, enhancing the network’s learning capability. The diagram below illustrates their relationships well, sourced from “Understanding the Principles and Code of Vision Transformer: This Technical Review is Enough”. Please delete if infringing.
This is my personal shallow interpretation; please advise if there are inaccuracies. I will continue learning about attention…
In summary, my feeling is that defining these three tensors serves two purposes: one is to learn the relationships between inputs and find and record the relationship weights between entities, and the other is to introduce learnable parameters under a reasonable structure, enhancing the network’s learning capability. The diagram below illustrates their relationships well, sourced from “Understanding the Principles and Code of Vision Transformer: This Technical Review is Enough”. Please delete if infringing.
This is my personal shallow interpretation; please advise if there are inaccuracies. I will continue learning about attention…
Recommended Reading:
A Discussion on VAE and VQVAE: From Continuous to Discrete Distribution
Detailed Explanation of Huggingface BERT Source Code: Application Models and Training Optimization
What is the Meaning of Achieving SOTA on Incorrect Data?
Click the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: