
Click the above “Beginner’s Visual Learning” and choose to add “Star” or “Top”
Important content delivered in real-time
Translator: Mr. Geek
This article is translated from Ivan Ozhiganov’s article “Deep Dive Into OCR for Receipt Recognition” published on DZone. All copyright, image codes, and data belong to the author. The translated content has been slightly modified for localization.
Optical Character Recognition (OCR) technology is currently widely used in handwriting recognition, printed text recognition, and text image recognition. From document recognition, bank card, and ID recognition to advertisements and posters, the invention of OCR technology has greatly simplified the way we process data.
At the same time, the rapid development of Machine Learning (ML) and Convolutional Neural Networks (CNN) has brought a huge leap in text recognition! In this study, we will also use CNN technology to recognize paper receipts from retail stores. For demonstration purposes, we will only use Russian version receipts for testing.
Our goal is to develop a client to recognize and obtain relevant documents, with a server-side to recognize and parse the data. Are you ready? Let’s see how to do it together!
Preprocessing
First, we need to receive image-related data, ensuring it is aligned horizontally and vertically. Next, we will use algorithms to detect whether it is a receipt, and finally binarize it for easier recognition.
Rotate Image to Recognize Receipts
We have three solutions to recognize receipts, which we will test below.
1. High-threshold adaptive binarization technology. 2. Convolutional Neural Networks (CNN). 3. Haar feature classifier.
Adaptive Binarization Technology
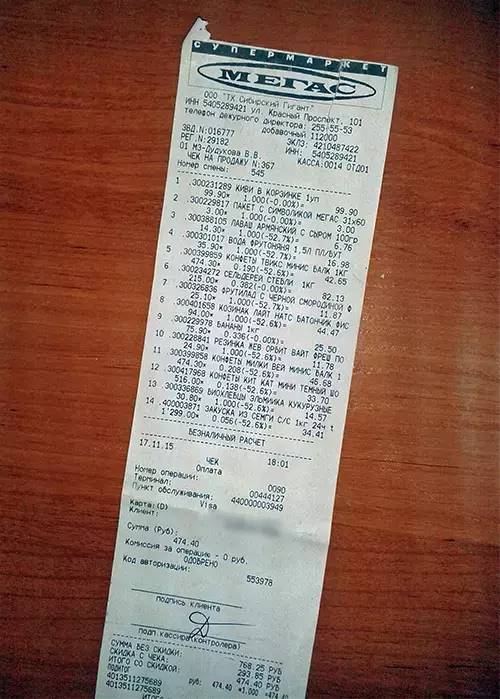
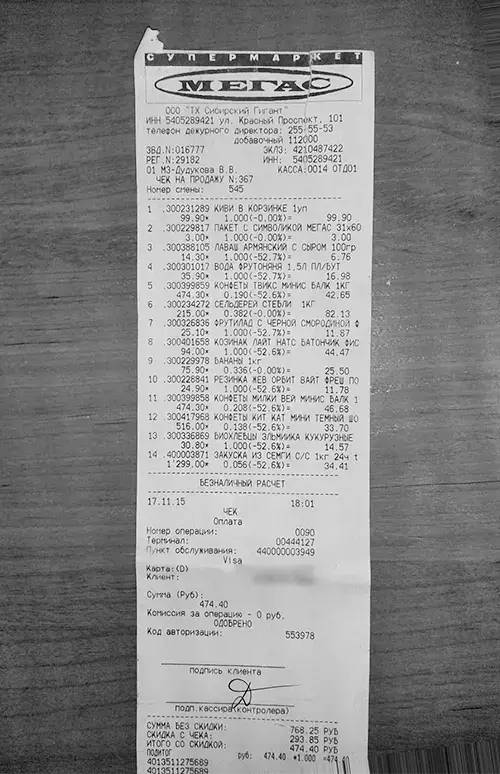
First, we see that the image contains complete data, while the receipt has some contrast with the background. To better recognize the relevant data, we need to rotate the image to align it horizontally along the vertical direction.
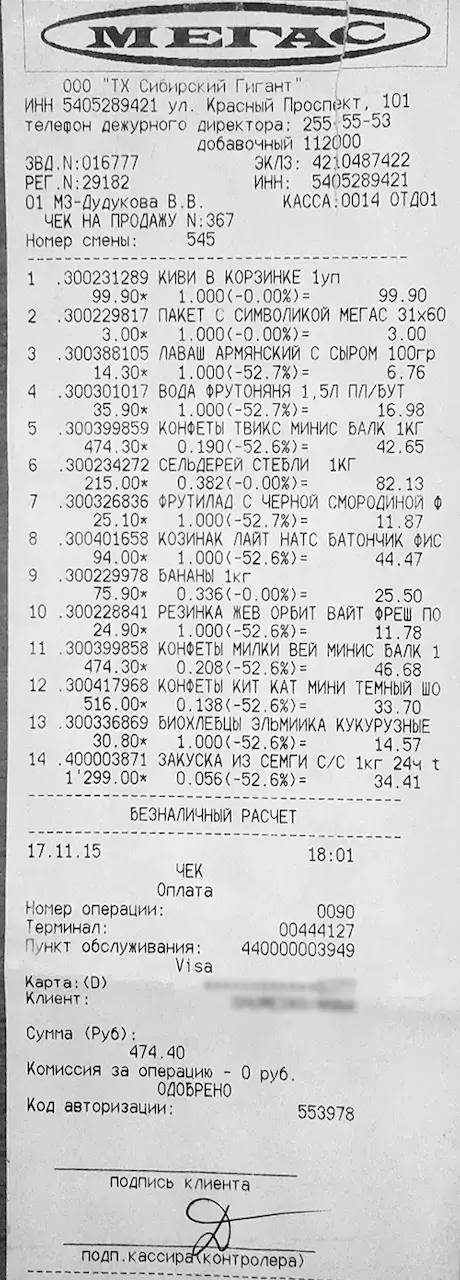
We use the adaptive threshold function from OpenCV and the scikit-image framework to adjust the receipt data. By utilizing these two functions, we can retain white pixels in high-gradient areas and black pixels in low-gradient areas. This gives us a high-contrast sample image. Thus, by cropping, we can obtain the relevant information of the receipt.
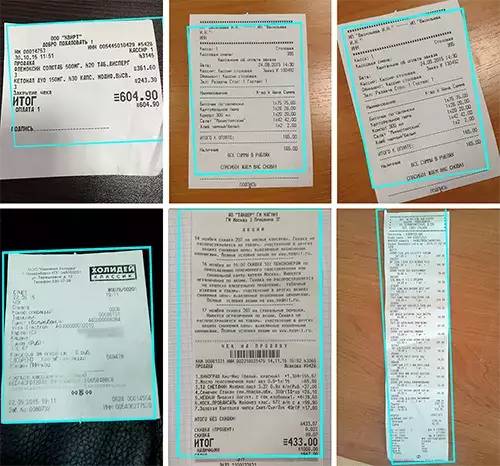
Using Convolutional Neural Networks (CNN)
Initially, we decided to use CNN for the related location detection, just like we did in previous object detection projects. We use angle judgment to pick up relevant key points. Although this solution is useful, it performs worse in comparison to high-threshold detection cropping.
Because CNN can only find the angle coordinates of text, and the angle variations of the text are significant, this means that the CNN model is not very accurate. For details, please refer to the results of the CNN tests below.
Using Haar Feature Classifier to Recognize Receipts
As a third option, we attempted to use the Haar feature classifier for classification screening. However, after a week of classification training and adjusting relevant parameters, we did not achieve any positive results, and even found that CNN performed much better than Haar.

Binarization
Finally, we used the adaptive_threshold method from OpenCV for binarization, and after processing, we obtained a good image.

Text Detection
Next, we will introduce several different text detection components.
Detecting Text via Connected Components
First, we use the findContours function in OpenCV to find the connected text groups. Most of the connected components are characters, but there are also noisy texts left from binarization. Here, we filter the relevant text by setting the size of the threshold.
Then, we execute a synthesis algorithm to synthesize characters, such as: Й and =. By searching for the nearest character combinations to form words. This algorithm requires you to find the nearest character for each relevant letter and then find the best choice from several letters to display.

Next, the text forms lines. We determine if the text belongs to the same line by checking if the heights are consistent.

Of course, the drawback of this solution is that it cannot recognize noisy text.
Using Grids to Detect Text
We found that almost all receipts have text of the same width, so we managed to draw a grid on the receipts and used the grid to segment each character:
The grid immediately simplified the difficulty of receipt recognition. The neural network can accurately recognize characters within each grid. This solves the problem of noisy text. Ultimately, we can accurately count the number of texts.
We used the following algorithm to recognize the grid.
First, I used this connected component algorithm in the binarized image.

Then we found that some in the bottom left corner are true, so we adjusted the grid recognition using a two-dimensional periodic function.
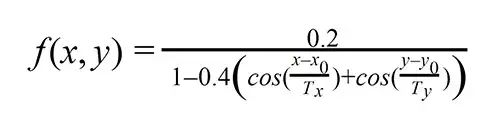
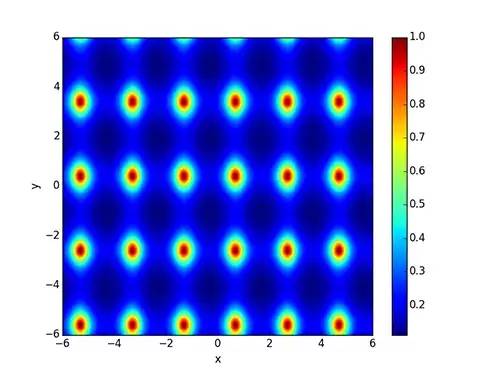
The main idea behind correcting grid distortion is to use the peaks of the graphics to find nonlinear geometric distortion. In other words, we must find the maximum value of this function. Additionally, we need an optimal distortion value.
We used the RectBivariateSpline function in the Scipy Python module to parameterize the geometric distortion and optimized it using Scipy functions. The results are as follows:

In summary, this method is slow and unstable, so we firmly do not intend to use this solution.
Optical Character Recognition
We recognize text through connected components and identify complete words.
Recognizing Text Found Through Connected Components
For text recognition, we use Convolutional Neural Networks (CNN) to receive relevant fonts for training. In the output part, we improve the probability through comparison. After comparing several initial options and finding a 99% accuracy rate, we further improved accuracy by comparing dictionaries and eliminating related similar characters, such as the errors caused by “З” and “Э”.

However, when it comes to noisy text, this method performs poorly.
Recognizing Complete Words
When the text is too noisy, it is necessary to find complete words to perform individual letter recognition. We use the following two methods to solve this problem:
-
LSTM Networks
-
Image Non-Uniform Segmentation Techniques
LSTM Networks
You can read these articles for a deeper understanding of using Convolutional Neural Networks to recognize text in sequences, or can we use neural networks to build language-independent OCR? For this, we used the OCRopus library for recognition.
We used monospaced fonts as manual recognition samples for training.

After training, we tested our neural network using other data, and of course, the test results were very positive. Here are the data we obtained:

The trained neural network performed excellently on simple examples. Similarly, we also recognized complex situations where the grid was unsuitable.
We extracted relevant training samples and trained them through the neural network.

To avoid overfitting of the neural network, we frequently stopped and corrected the training results, continuously adding new data as training samples. Finally, we obtained the following results:

The new network excels at recognizing complex vocabulary, but performs poorly in simple text recognition.
We believe this convolutional neural network can refine recognition of individual characters to enhance text recognition.
Image Non-Uniform Segmentation Techniques
Since the receipt fonts are monospaced, we decided to segment the fonts by character. First, we need to know the width of each letter. Therefore, the width of the characters is particularly important, and we need to estimate the length of each letter. Using functions, we obtain the following image. We select various patterns to choose specific letter widths.
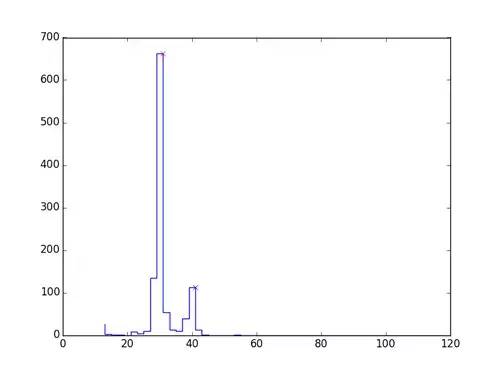
We obtain an approximate width of a word by dividing by the number of letters in the character, giving an approximate classification:

The best distinctions are:
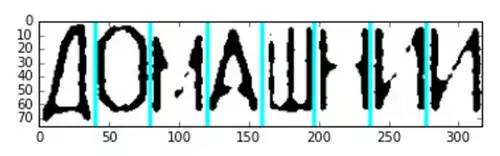
The accuracy of this segmentation scheme is very high:
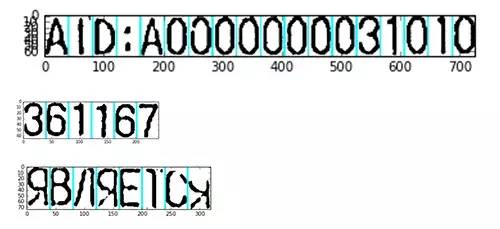
Of course, there are also situations where recognition is not very good:

After segmentation, we use CNN for recognition processing.
Extracting Meaning from Receipts
We use regular expressions to find purchase information in receipts. All receipts have a common point: the purchase price is written in XX.XX format. Therefore, relevant information can be extracted by extracting the purchase lines. The personal tax number is ten digits and can also be easily obtained through regular expressions. Similarly, NAME / SURNAME and other information can also be found using regular expressions.
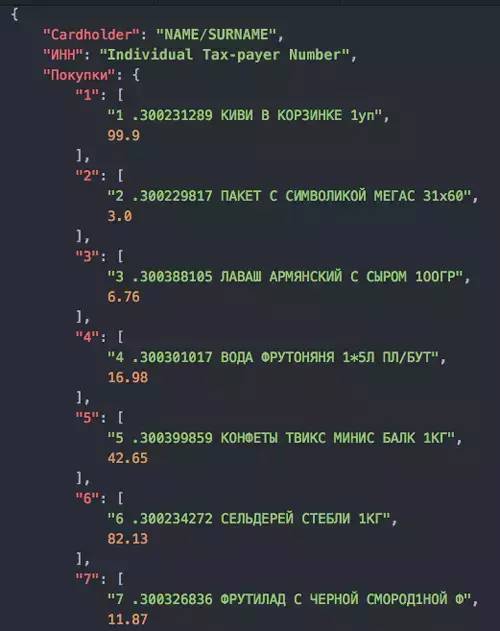
Conclusion
-
No matter what method you choose, whether LSTM or other more complex solutions, there is no wrong choice. Some methods are difficult to use, but others are quite simple, depending on the recognition samples.
-
We will continue to optimize this project. Currently, the system performs better in the absence of noise.
Original link: https://dzone.com/articles/using-ocr-for-receipt-recognition
Original author: Ivan Ozhiganov
Good news!
The Beginner's Visual Learning knowledge community is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Chinese Tutorial for Extension Modules" on the “Beginner's Visual Learning” public account to download the first Chinese version of the OpenCV extension module tutorial on the internet, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than 20 chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" on the “Beginner's Visual Learning” public account to download 31 practical vision projects, including image segmentation, mask detection, lane line detection, vehicle counting, eye line addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" on the “Beginner's Visual Learning” public account to download 20 practical projects based on OpenCV for advanced learning.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format; otherwise, the request will not be approved. After successful addition, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~