Click the above “Beginner Learning Vision”, select to add “Star” or “Top”
Important content delivered at the first time
This article is reprinted from | 3D Vision Workshop
1. Arbitrary-Oriented Scene Text Detection via Rotation Proposals
Main Idea
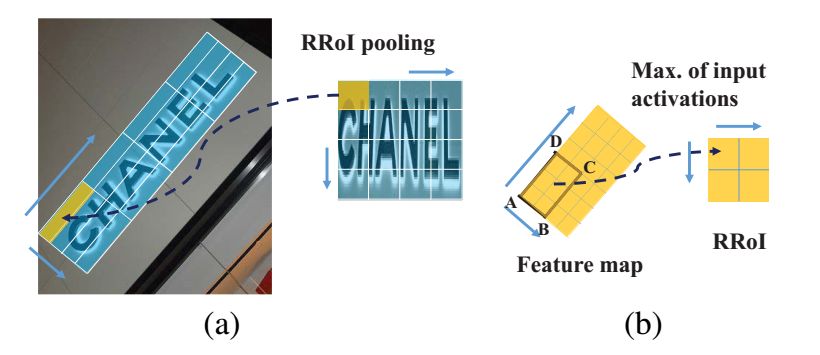
This article introduces a novel network framework based on rotation for detecting text in natural scene images oriented in arbitrary directions. The main idea of the paper is the Rotation Region Proposal Network (RRPN), which aims to generate inclined proposals with text direction angle information and uses the angle information for bounding box regression, allowing the proposals to fit the text areas more accurately in terms of direction. Additionally, a Rotated Region of Interest (RRoI) pooling layer is proposed to project the proposals of arbitrary orientation onto the feature map for classification by the classifier. Compared to previous text detection systems, the region proposal-based architecture ensures computational efficiency for detecting text in arbitrary directions.
Main Innovations
1. Unlike previous segmentation-based frameworks, the framework in this paper can predict the direction of text lines using a region proposal-based approach, allowing the proposals to better adapt to text regions and making it easier to correct the text area ranges for better readability.
2. A new strategy for improving arbitrary direction region proposals is proposed to enhance the performance of detecting text in arbitrary directions.
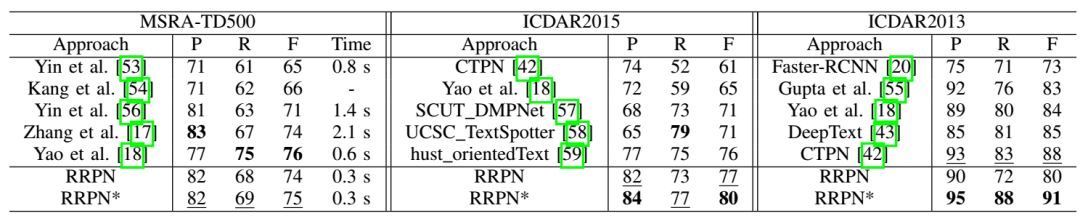
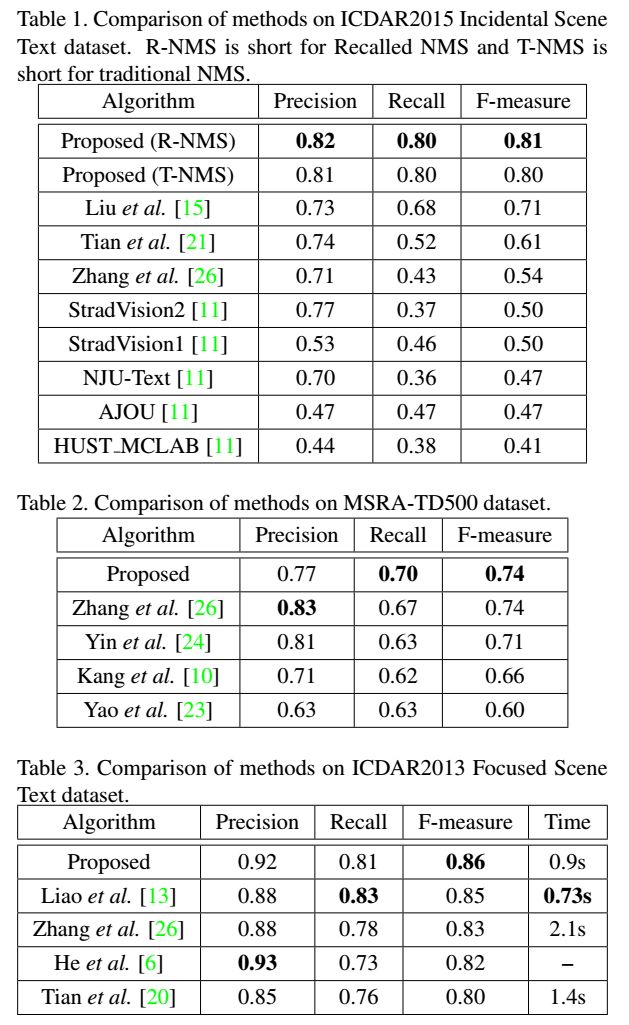
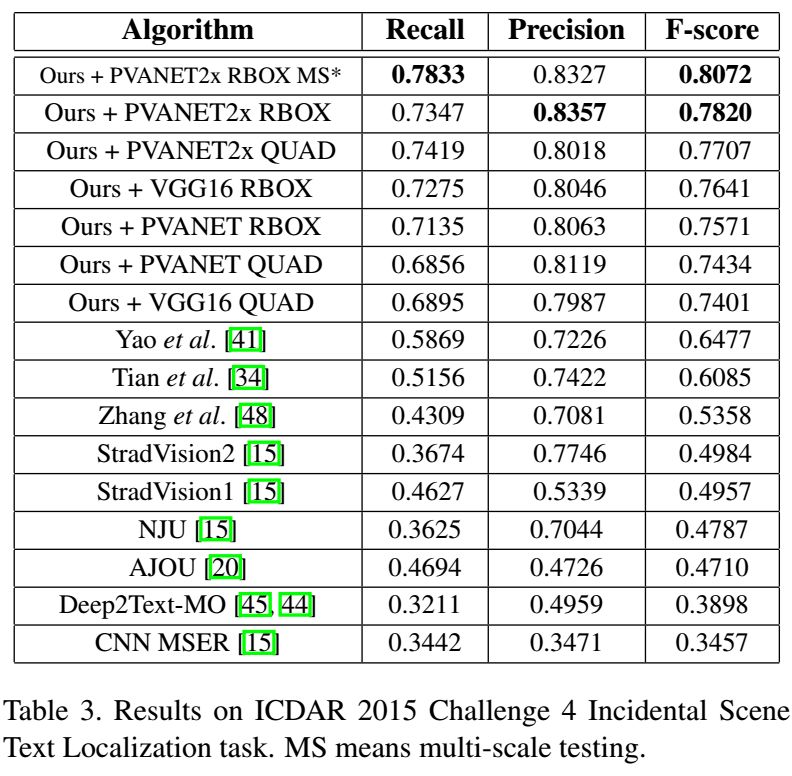
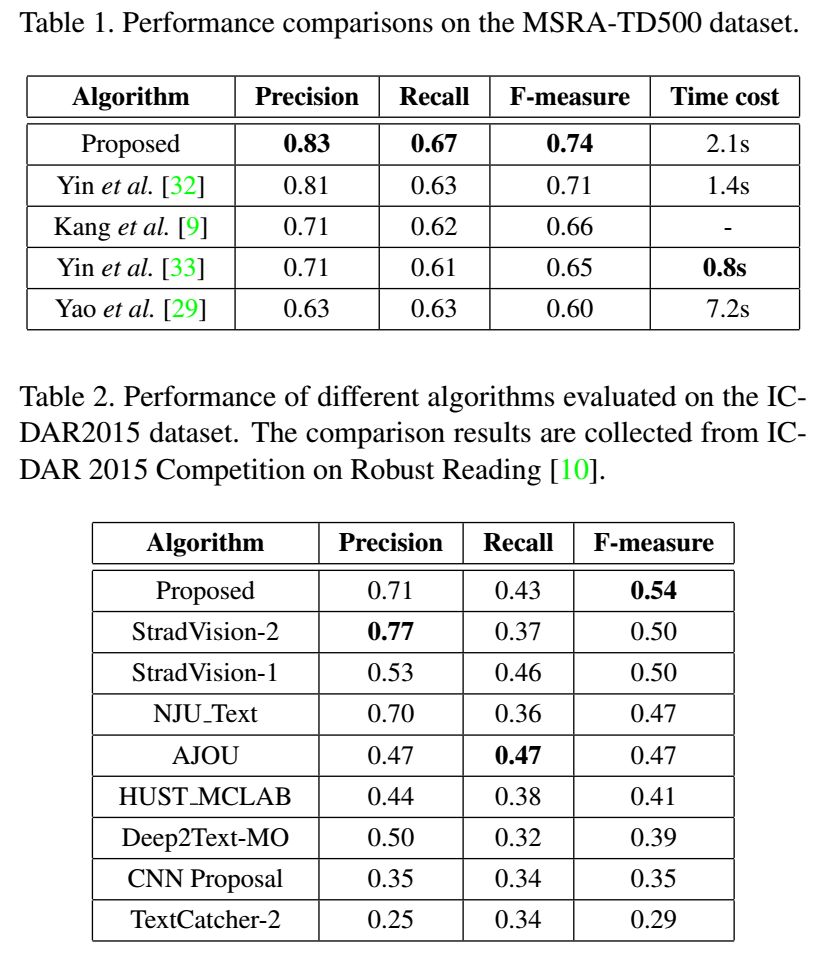
3. On the MSRA-TD500, ICDAR2013, and ICDAR2015 datasets, the proposed network is more accurate and efficient compared to previous methods.
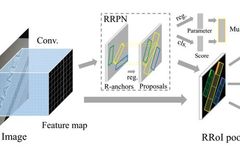
Network Structure
As can be seen, the idea is similar to Faster RCNN. The design of anchors is shown below, with 3 scales and 3 ratios, and the rotation angle range is -π/6 to 2π/3.
Experimental Results
2. Deep Direct Regression for Multi-Oriented Scene Text Detection
Main Idea
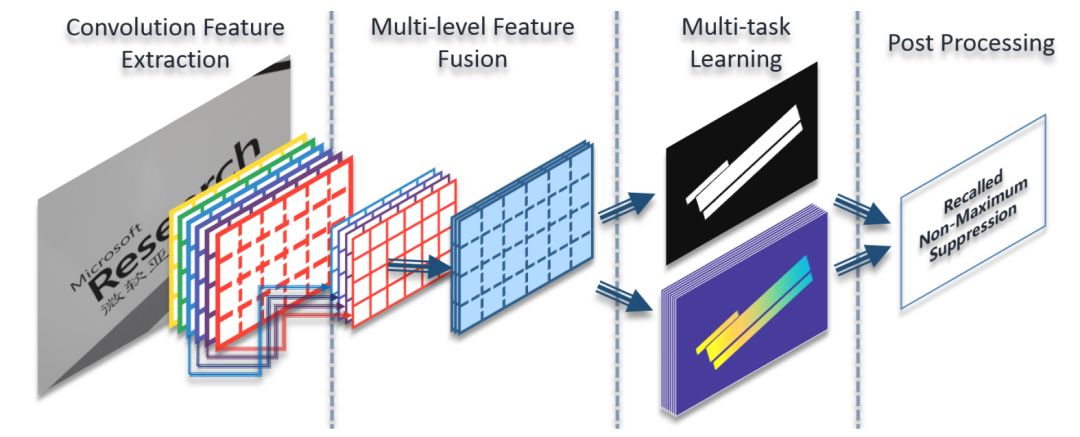
This paper proposes a multi-directional scene text detection method based on deep direct regression. The detection framework is simple and effective, consisting of a fully convolutional network and post-processing. The fully convolutional network is optimized end-to-end, achieving dual-task outputs for pixel-level classification of text and non-text and direct regression of text boundary vertex coordinates.
Main Contributions
1. Direct regression for multi-directional scene text detection.
2. The pipeline consists of only two parts: one is the convolutional neural network, and the other is a single-step post-processing call to non-maximum suppression. Modules like line grouping and character partitioning are eliminated, saving a lot of parameter tuning work.
3. Since the method in this paper can predict irregular quadrilateral boundaries, it has significant advantages in tasks that require locating the four vertices of each character-level text.
Network Structure
Experimental Results
3. Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection
Main Idea
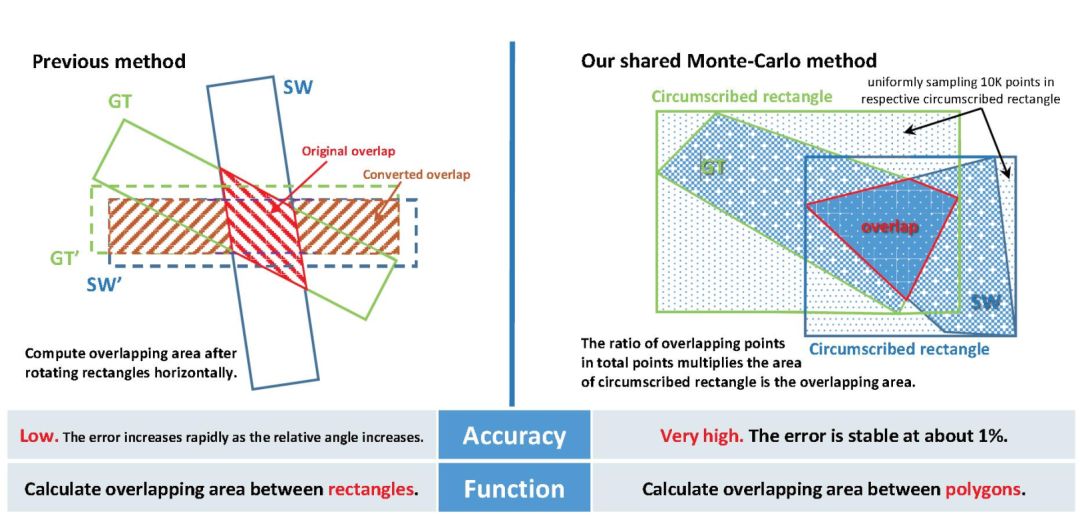
Due to the multi-directionality of text, perspective distortion, as well as variations in text size, color, and scale, detecting incidental scene text is a challenging task. Early studies mainly focused on using rectangular bounding boxes or horizontal sliding windows for text localization, which could lead to redundant background noise, unnecessary overlaps, or even information loss. To address these issues, this paper proposes a new text detection method based on Convolutional Neural Networks (CNNs), called Deep Matching Prior Network (DMPNet). It first uses quadrilateral sliding windows at several specific intermediate convolutional layers to roughly detect text with significant overlaps, then proposes a shared Monte Carlo method for fast and accurate calculation of polygonal areas. Based on this, a relative regression sequential protocol is designed that can accurately predict text with compact quadrilaterals. Furthermore, an auxiliary smooth LN Loss is proposed to further refine the text positions, showing better overall performance in terms of robustness and stability compared to L2 loss and smooth L1 loss.
Main Contributions
1. The first prior quadrilateral sliding window is proposed, significantly improving recall rates.
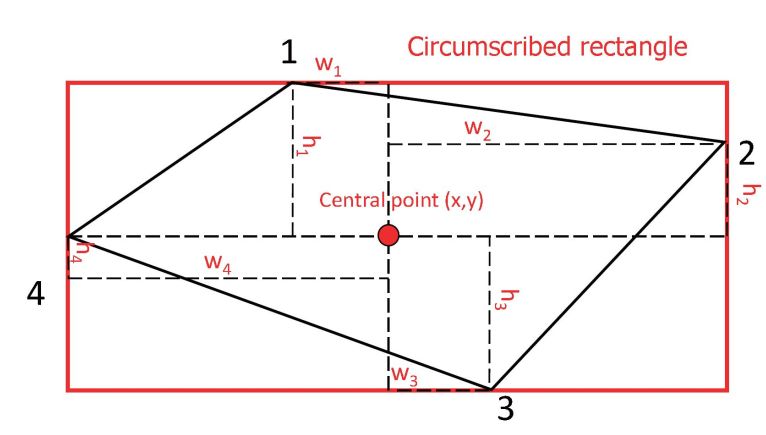
2. A unique protocol that determines the order of 4 points in any planar convex quadrilateral is proposed, enabling the method to use relative regression to predict quadrilateral bounding boxes.
3. The proposed shared Monte Carlo computation method can quickly and accurately calculate polygon overlapping areas.
4. The proposed smooth LN loss performs better than L2 loss and smooth L1 loss in comprehensive performance.
Network Structure
Experimental Results
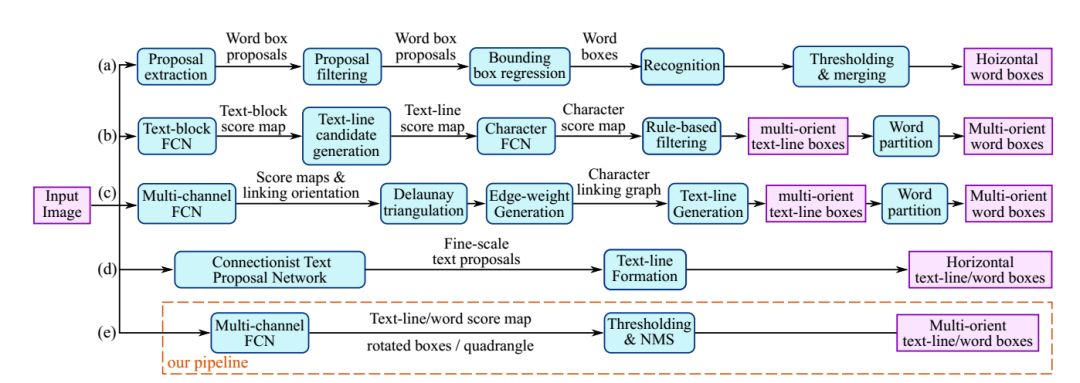
4. DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images
Main Idea
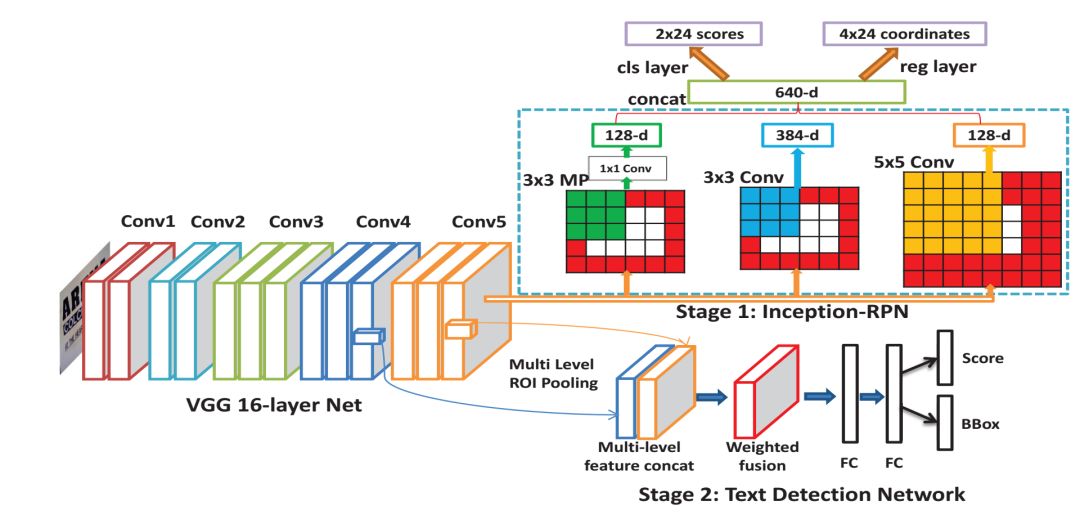
This paper proposes a unified framework for text region proposal generation and text detection in natural images based on fully convolutional networks (CNN). First, an initial region proposal network (Inception RPN) is proposed, and a set of prior bounding boxes with text features is designed to achieve a high word recall rate with only 100 candidate proposals. Next, a powerful text detection network is proposed, which embeds ambiguous text category (ATC) information and multi-level region of interest pooling (MLRP) for text and non-text classification and precise localization. Finally, an iterative bounding box voting scheme is applied to pursue high recall in a complementary manner and introduce filtering algorithms to retain the most suitable bounding boxes while removing redundant internal and external boxes for each text instance.
Main Contributions
1. The inception-RPN is proposed, which applies multi-scale sliding windows to the top of convolutional feature maps and associates a set of text feature prior bounding boxes with each sliding position to generate region proposals for words. The multi-scale sliding window features can retain local and contextual information at the respective positions, helping filter out non-text bounding boxes. The initial RPN achieves high recall rates with only a few hundred region proposals.
2. Additional ATC information and multi-level ROI pooling (MLRP) are introduced into the text detection network to help it learn more discriminative information to distinguish text in complex backgrounds.
3. To better utilize intermediate models throughout the training process, an iterative bounding box voting scheme is proposed to achieve high word recall in a complementary manner. Moreover, based on empirical observations, multiple inner or outer boxes can coexist for a single text instance. To address this, a filtering algorithm is used to retain the most suitable bounding boxes and remove the rest.
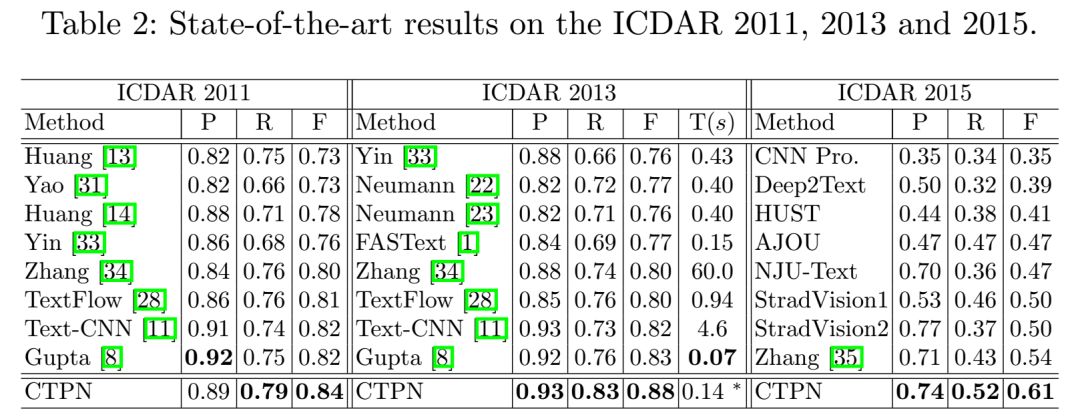
4. The method in this paper achieves F-measures of 0.83 and 0.85 on the ICDAR robust text detection benchmarks in 2011 and 2013, respectively, outperforming previous state-of-the-art results.
Network Structure and Experimental Results
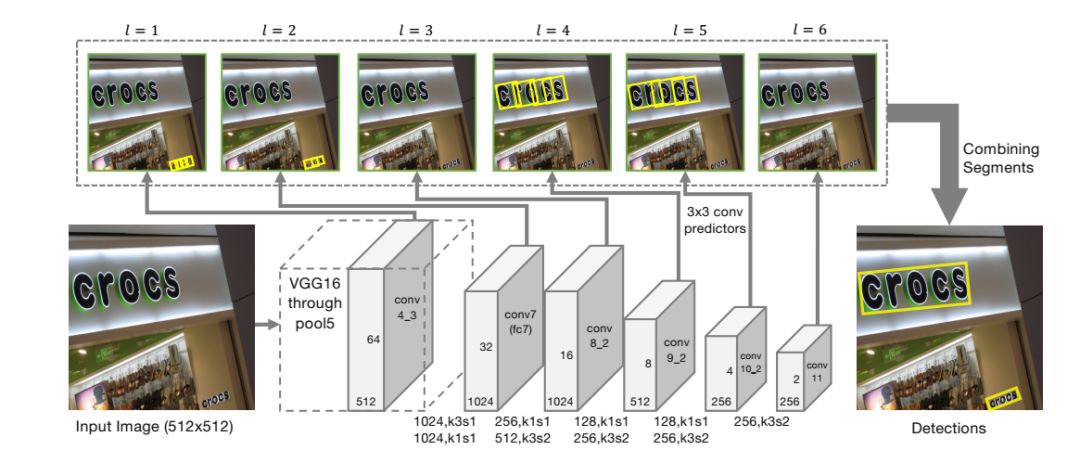
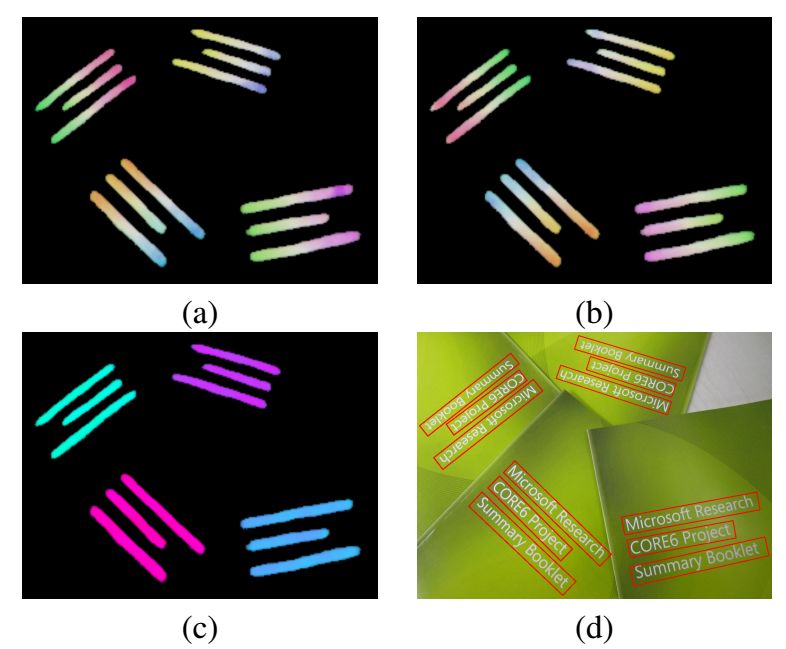
5. Detecting Oriented Text in Natural Images by Linking Segments
Main Idea
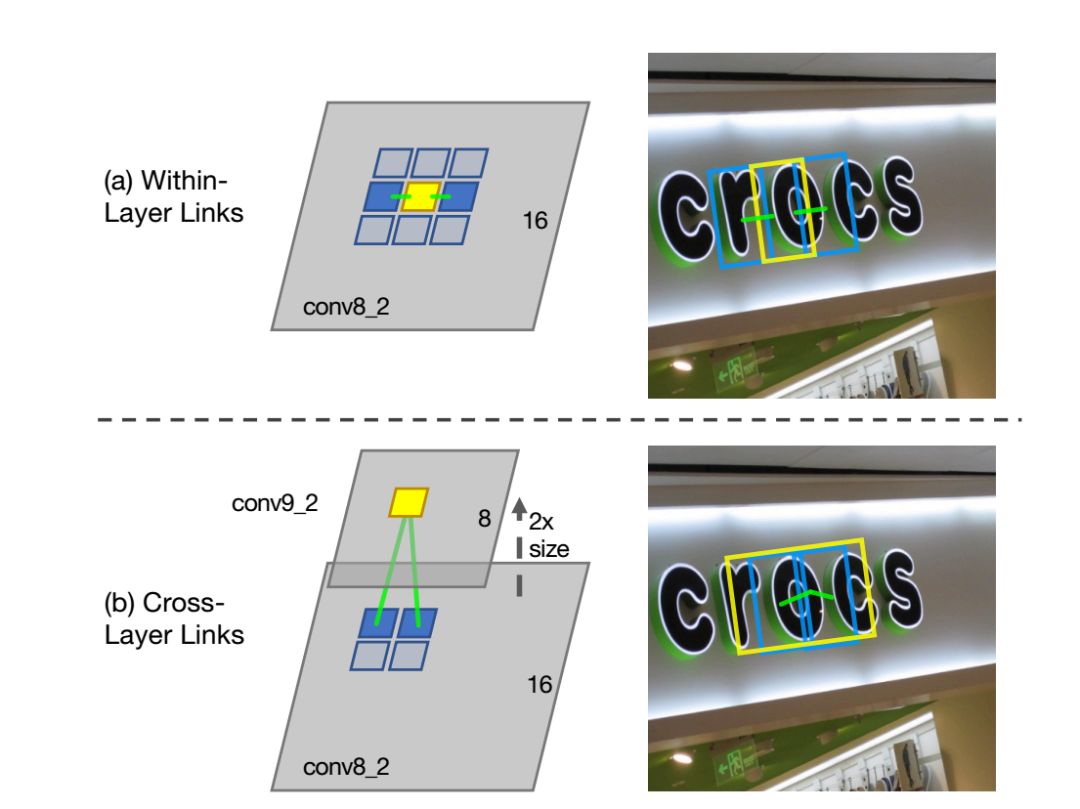
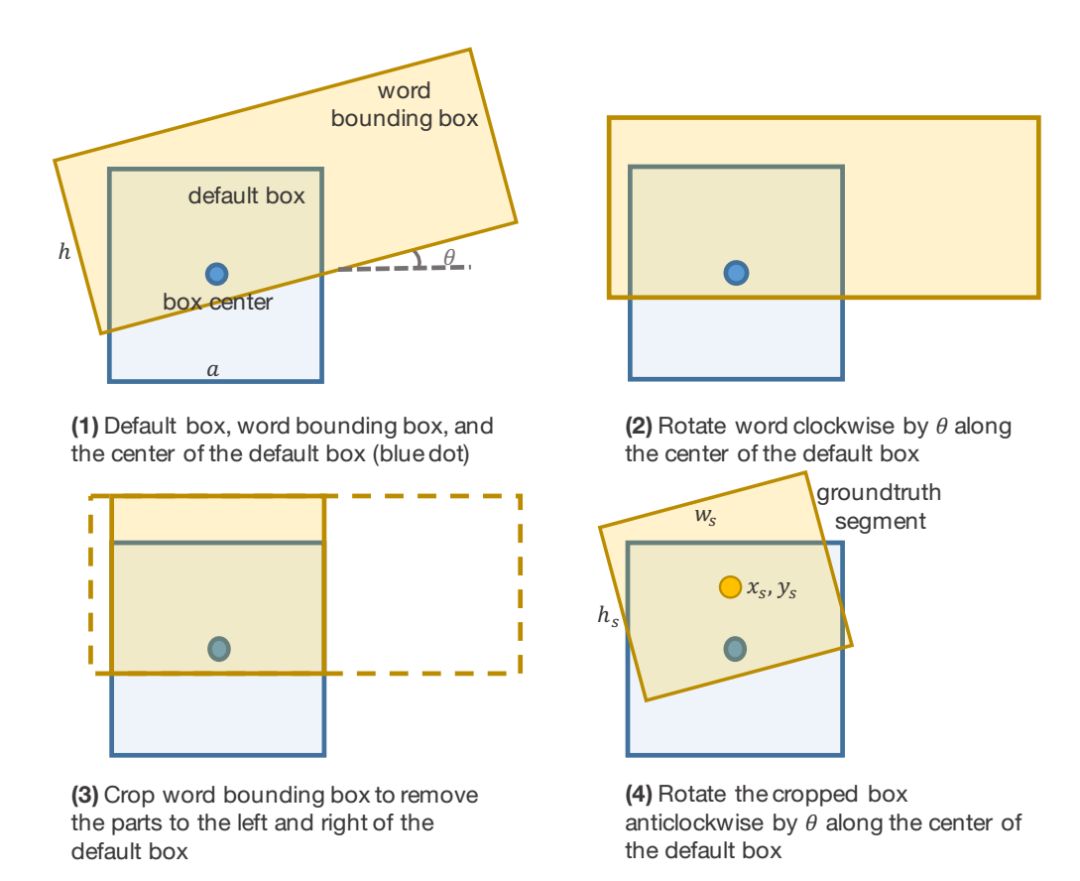
Most state-of-the-art text detection methods are designed for horizontal Latin text and are not fast enough for real-time applications. This paper introduces a text detection approach called SegLink. The main idea is to decompose text into two locally detectable elements, namely segments and links. Segments are oriented boxes covering parts of words or text lines; links connect two adjacent segments, indicating they belong to the same word or text line. Both elements are densely detected at multiple scales through an end-to-end trained fully convolutional neural network.
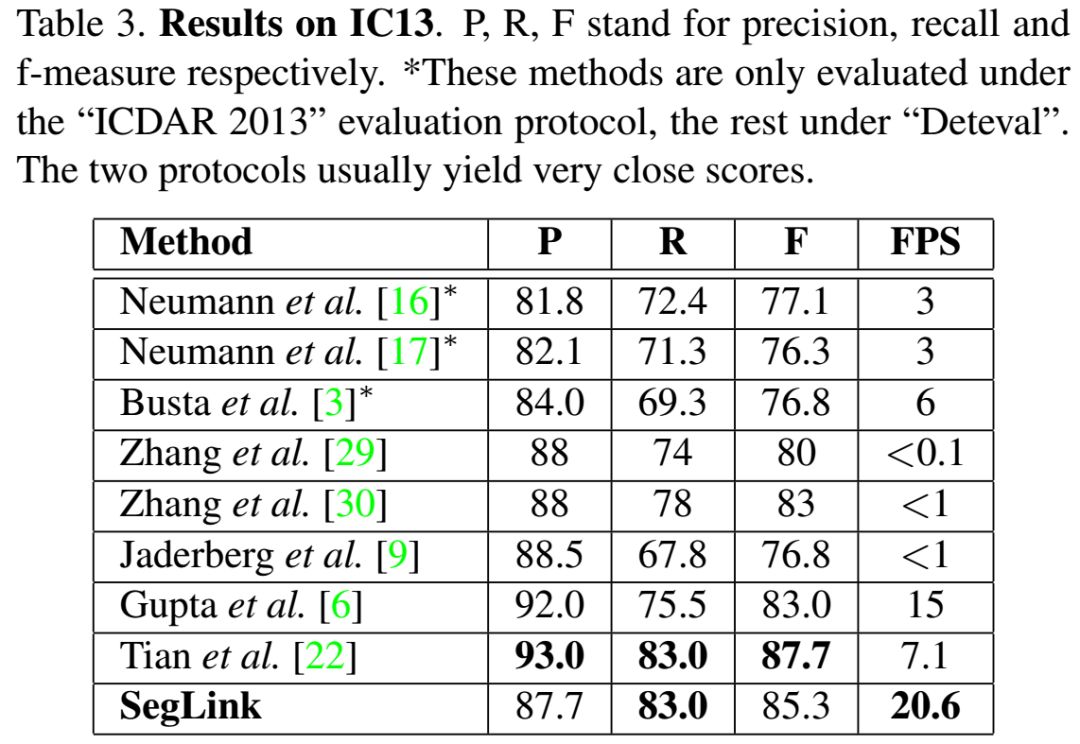
The final detection is produced by combining segments connected by links. Compared to previous methods, SegLink improves in accuracy, speed, and ease of training. It achieves a 75.0% F-measure on the standard ICDAR 2015 challenge (Challenge 4), significantly surpassing the previous best levels. It runs at over 20 FPS on 512×512 images. Furthermore, SegLink can detect non-Latin text lines, such as Chinese, without modification.
Main Contributions
The main contribution is the proposal of a new segment-link detection method. Experiments demonstrate that the proposed method has several significant advantages compared to other state-of-the-art methods:
1) Robustness: The structure of SegLink is simple and elegant, showing robustness in complex backgrounds. The method achieves very competitive results on standard datasets. In particular, it greatly surpasses the previous best levels on the 2015 ICDAR dataset.
2) Efficiency: Due to its single-stream, fully convolutional design, SegLink has high efficiency. It processes over 20 images of size 512×512 per second.
3) Versatility: SegLink can detect long non-Latin text lines, such as Chinese, without modification, as demonstrated on a multilingual dataset.
Network Structure
Experimental Results
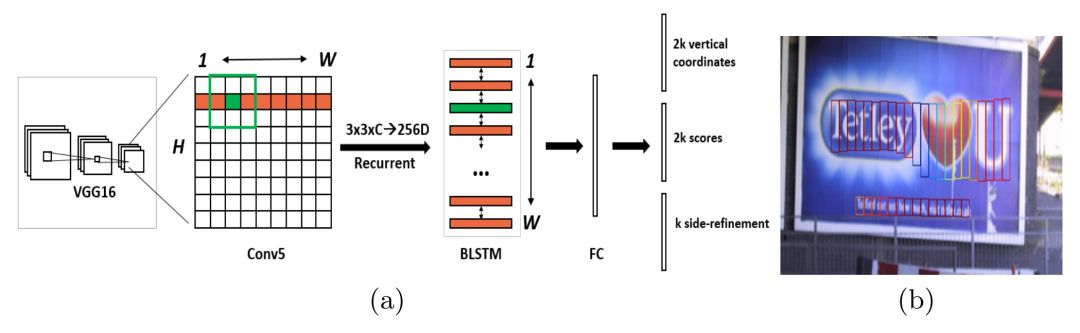
6. Detecting Text in Natural Image with Connectionist Text Proposal Network
Main Idea
This paper proposes a new Connectionist Text Proposal Network (CTPN) that can accurately locate text lines in natural images. CTPN directly detects text lines in a series of fine-scale text proposals within convolutional feature maps. The paper develops a vertical anchor mechanism that jointly predicts the position and text/non-text scores of each fixed-width proposal, greatly enhancing localization accuracy. The sequential proposals are naturally connected by a recurrent neural network, seamlessly integrating the recurrent neural network with the convolutional network to form an end-to-end trainable model, allowing CTPN to explore the rich contextual information of images and detect very blurry text. CTPN reliably works on multi-scale and multi-language text without further post-processing, unlike previous bottom-up multi-step filtering methods.
Network Structure and Experimental Results
7. EAST: An Efficient and Accurate Scene Text Detector
Main Idea
This work proposes a simple yet powerful pipeline for fast and accurate text detection in natural scenes. The pipeline utilizes a single neural network to directly predict words or text lines in arbitrary orientations and quadrilaterals across the entire image, eliminating unnecessary intermediate steps (such as candidate aggregation and word segmentation). The simplicity of the pipeline allows us to focus on designing loss functions and neural network structures. Experiments on standard datasets such as ICDAR 2015, COCO Text, and MSRA-TD500 demonstrate that the algorithm significantly outperforms the latest methods in terms of accuracy and efficiency.
Main Contributions
The contributions of this work are threefold:
1. We propose a scene text detection method that includes two stages: a fully convolutional network and an NMS merging stage. The FCN directly generates text regions, excluding redundant and time-consuming intermediate steps.
2. The pipeline is flexible enough to produce character-level or line-level predictions, with geometries that can be either rotated boxes or quadrilaterals, depending on specific applications.
3. The proposed algorithm significantly outperforms the latest methods in both accuracy and speed.
Network Structure
Experimental Results
8. Multi-Oriented Text Detection with Fully Convolutional Networks
Main Idea
This paper proposes a new method for detecting text in natural images. During the coarse-to-fine process of localizing text lines, both local and global cues are considered. First, a fully convolutional network (FCN) model is trained to predict the saliency map of the text regions as a whole. Then, the feature maps are combined with character components to estimate text line hypotheses. Finally, another FCN classifier is used to predict the centroids of each character to eliminate false hypotheses.
Main Contributions
1. Utilizing FCN to learn a strong text labeling model, proposing a new method for computing text saliency maps. The text labeling model is trained and tested in a holistic manner, showing high stability against scale and orientation changes of scene text and high efficiency in coarse localization of text blocks. It is also suitable for multi-script text.
2. Proposing an effective method for extracting multi-directional text candidate bounding boxes, demonstrating that both local (character components) and global (text blocks from saliency maps) cues are useful and complementary.
3. Proposing a new method for filtering false candidates. We train an effective model (another FCN) to predict the character centroids within candidate text lines. The results show that the predicted character centroids provide accurate locations for each character and are effective features for removing false candidate characters.
Network Structure and Experimental Results
9. Robust Scene Text Recognition with Automatic Rectification
Main Idea
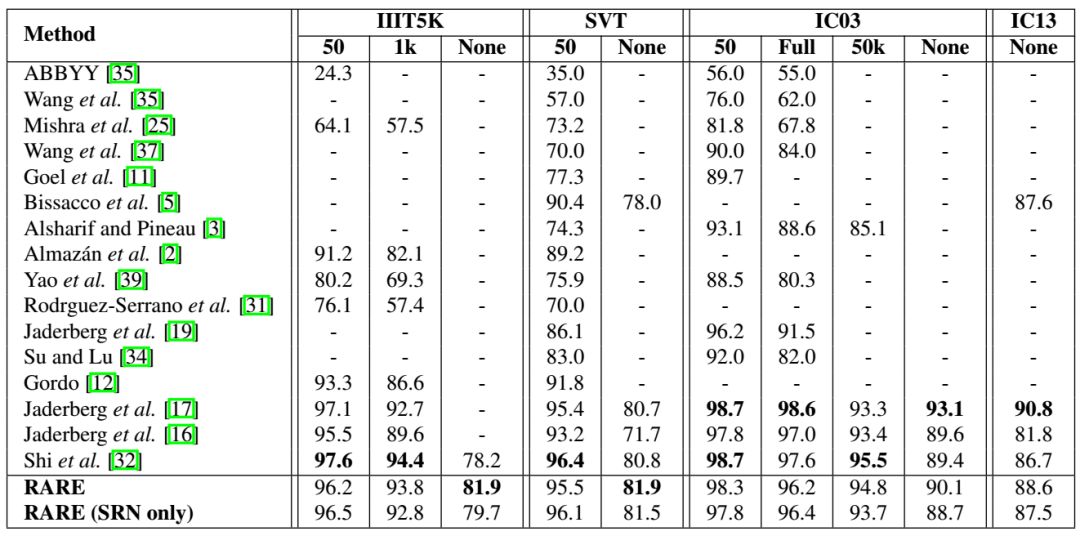
Recognizing text in natural images is a challenging task with many unresolved issues. Unlike text in documents, text in natural images often has irregular shapes due to perspective distortion, curved character placements, etc. This paper proposes a robust recognition model for irregular text called RARE (Robust Automatic Rectifier). RARE is a specially designed deep neural network composed of a Spatial Transformer Network (STN) and a sequence recognition network (SRN). During testing, the image is first corrected to a more “readable” image through the predicted TPS transformation for subsequent SRN, which recognizes the text through a sequence recognition method. Results show that the model can recognize various irregular texts, including perspective and curved texts. RARE is end-to-end trainable and only requires images and corresponding text labels, making it very convenient to train and deploy models in practical systems.
Main Contributions
1. Proposing a scene text recognition method that is robust to irregular text.
2. Using an attention-based model and extending the STN framework, as the original STN was only tested on ordinary convolutional networks.
3. The encoder of the SRN adopts a convolutional recursive structure, which is a new variant of the attention-based model.
Network Structure
Experimental Results
The above content, if there is any copyright infringement, please contact the author, and they will delete the article themselves.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply in the “Beginner Learning Vision” public account background:Extension Module Chinese Tutorial, you can download the first Chinese version of the OpenCV extension module tutorial available online, covering extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters.
Download 2: Python Vision Practical Project 52 Lectures
Reply in the “Beginner Learning Vision” public account background: Python Vision Practical Project, you can download 31 vision practical projects including image segmentation, mask detection, lane detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply in the “Beginner Learning Vision” public account background: OpenCV Practical Project 20 Lectures, you can download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future), please scan the WeChat ID below to add to the group, and note: “nickname + school/company + research direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format for remarks, otherwise, it will not be approved. Successfully added, you will be invited to the relevant WeChat group based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~