Selected from GitHub
Author: Tigran Galstyan et al.
Translated by Machine Heart
Contributors: Nurhachu Null, Jiang Siyuan
For humans, transliteration is a relatively easy and interpretable task, making it suitable for explaining what neural networks do and whether their actions are similar to those of humans on the same task. Therefore, we start with the transliteration task to further explain from a visualization perspective what individual neurons in neural networks have actually learned and how they make decisions.
Table of Contents:
-
Transliteration
-
Network Structure
-
Analyzing Neurons
-
How Does ‘t’ Become ‘ծ’?
-
How Do Neurons Learn?
-
Visualizing Cells in Long Short-Term Memory (LSTM) Networks
-
Summary and Comments
Transliteration
Among billions of internet users, about half use languages represented by non-Latin alphabets, such as Russian, Arabic, Chinese, Greek, and Armenian. Often, they also casually write these languages using Latin letters.
-
Привет: Privet, Privyet, Priwjet, …
-
كيف حالك: kayf halk, keyf 7alek, …
-
Բարև Ձեզ: Barev Dzez, Barew Dzez, …
As a result, there is an increasing amount of user-generated content in “Latinization” or “Romanization” formats, which are difficult to parse, search, and even recognize. Transliteration is the task of automatically converting this content into a standardized format.
-
Aydpes aveli sirun e.: Այդպես ավելի սիրուն է:
What factors make this problem difficult?
-
As shown above, different language users employ different romanization methods. For example, v or w in Armenian is written as վ.
-
Multiple letters can be romanized into a single Latin letter. For example, r can represent ր or ռ in Armenian.
-
A single letter can be romanized into multiple Latin letters or combinations of Latin letters. For instance, the combination ch represents ч in Cyrillic or չ in Armenian, but c and h represent different things individually.
-
English words and cross-language Latin symbols, such as URL, often appear in non-Latin text. For example, the letters in youtube.com and MSFT do not change.
Humans are good at resolving these ambiguities. We have previously shown that LSTMs can also learn to resolve all of these ambiguities, at least in Armenian. For example, our model can correctly transliterate es sirum em Deep Learning to ես սիրում եմ Deep Learning, rather than ես սիրում եմ Դեեփ Լէարնինգ.
Network Architecture
We took a lot of Armenian text from Wikipedia and used probabilistic rules to obtain romanized text. The probabilistic rules cover most of the romanization rules used by people in Armenian.
We encoded Latin letters into one-hot vectors and then used a character-level bidirectional LSTM. At each time step, the network tries to guess the next character in the original Armenian sentence. Sometimes a single Armenian letter is represented by multiple Latin letters, so aligning the romanized text with the original text before using LSTM is very helpful (otherwise, we would need to use sentence-to-sentence LSTMs, which are very difficult to train). Luckily, we can align, as the Romanian text is generated solely by us. For example, dzi should be romanized as ձի, where dz corresponds to ձ and i corresponds to ի. Therefore, we added a placeholder in the Armenian text: ձի became ձ_ի, so now z can be romanized as _. After the transliteration is complete, we just need to remove all _ from the output string.
Our neural network contains two LSTMs (with a total of 228 units), which traverse the Latin sequence forwards and backwards. The output of the LSTM at each step is connected (connection layer), followed by a dense layer with 228 neurons on top of the hidden layer, and then another dense layer with a softmax activation function to obtain the output probabilities. We also connect the input layer to the hidden layer, resulting in 300 neurons. This is more streamlined than the simplified network used in the same topic described in our previous blog (the main difference is that we did not use a second layer of bidirectional LSTM (biLSTM)).
Analyzing Neurons
We attempt to answer the following two questions:
-
How does the network handle examples with several possible output results? (e.g., r => ր vs ռ, etc.)
-
What specific problems do certain neurons solve?
How Does ‘t’ Become ‘ծ’?
First, we use a specific character as input and another specific character as output. For example, we are interested in how ‘t’ becomes ‘ծ’ (we know that t can become տ, թ, or ծ).
We plotted histograms for the correct outputs of each neuron for the cases of being ‘ծ’ and not being ‘ծ’. For most neurons, these histograms are quite similar, with only the following two cases:
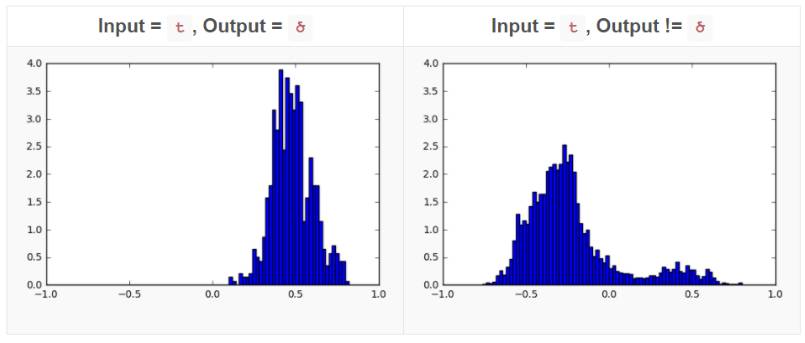
These two histograms indicate that by observing the activation results of this specific neuron, we can guess with high accuracy whether the output result of ‘t’ is ‘ծ’. To quantify the difference between these two histograms, we used the Hellinger distance, which divides the maximum and minimum values of the neuron activation results into 1000 parts and then applies the Hellinger distance formula. We calculated the Hellinger distance for each neuron and displayed the most interesting ones in a graph:
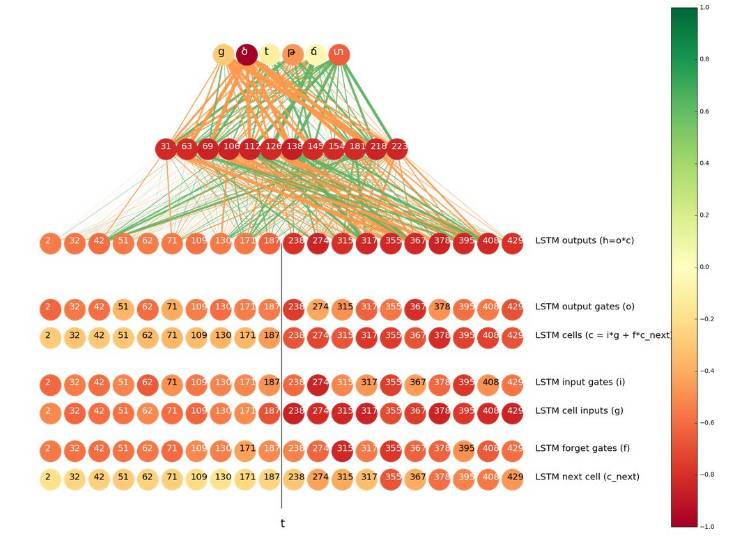
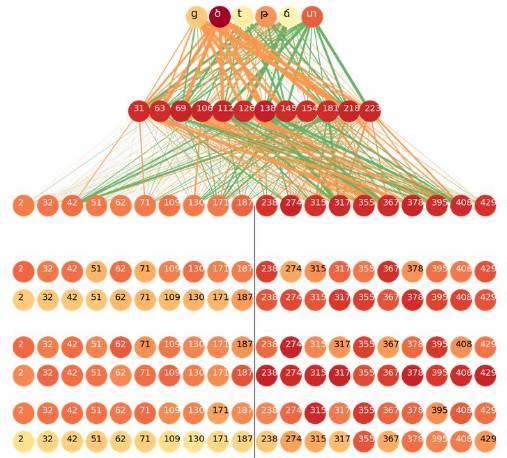
The color of the neurons represents the distance between the two histograms (darker colors indicate greater distances). The width of the lines connecting two neurons represents the contribution from lower layers to higher layers, i.e., the mean. Orange and green lines represent positive or negative signals, respectively.
The neurons at the top of the image come from the output layer, while those below the output layer come from the hidden layer (the top 12 neurons represent the distance between histograms). The neurons below the hidden layer are from the connection layer. The neurons in the connection layer are divided into two parts: the left half of the neurons are LSTMs propagating from the input sequence to the output sequence, while the right half are LSTMs propagating from the output to the input. We displayed the top ten neurons from each LSTM based on the distance of the histograms.
In the case of ‘t’ => ‘ծ’, it is clear that the top 12 neurons in the hidden layer all send positive signals to ‘ծ’ and ‘ց’ (ց is often romanized as ‘t’ in Armenian), and negative signals to ‘տ’, ‘թ’, and other characters.

We can also see that the output color from right to left is darker, indicating that these neurons “have more knowledge about whether to predict as ‘ծ'”; on the other hand, the connection between these neurons and the top 12 neurons in the hidden layer is lighter, meaning they contribute more to the activation of the top 12 neurons in the hidden layer. This is a very natural result because when the next symbol is ‘s’, ‘t’ generally becomes ‘ծ’, and only the right-to-left LSTM can realize the next character.
We perform a similar analysis on the neurons and gates inside the LSTM. The analysis results are displayed in the bottom 6 rows of the graph. Interestingly, the most “confident” neurons are those known as cell inputs. Input cells and gates depend on the current step’s input and the previous step’s hidden state (just like the right-to-left LSTM we discussed, which is the hidden state of the next character), so they are all “aware” of the next ‘s’; however, for some reason, the cell input is more confident than other parts.
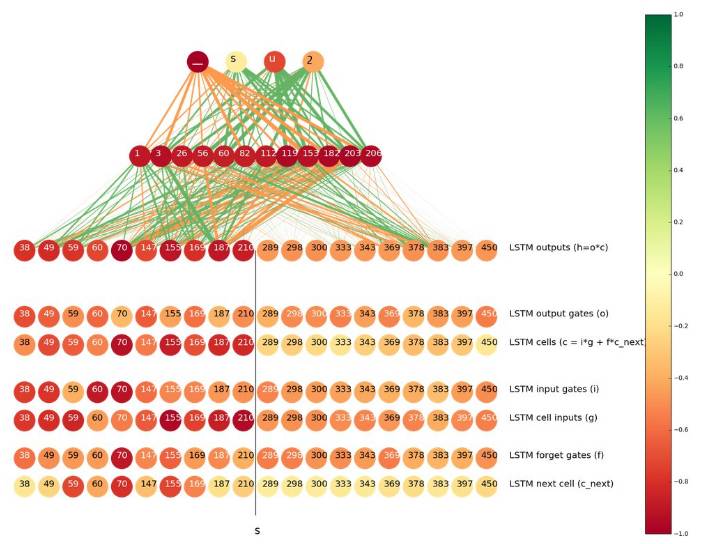
In the case where ‘s’ should be transliterated to ‘_’, as ‘s’ becomes ‘_’, especially in the case of ‘ts’ => ‘ծ_’, useful information is more likely to come from the forward LSTM from input to output. This situation can be seen in the figure below:
How Do Neurons Learn?
In the second part of the analysis, we explain how each neuron helps in ambiguous situations. We used a Latin character set that can be transliterated into more than one Armenian letter. We then removed sample results that appeared less than 300 times in 5000 sample sentences because our distance metric does not work well on those fewer samples. We then analyzed each neuron given the input-output pairs.
For example, this is an analysis of neuron #70 in the output layer of the left-to-right LSTM. We saw in previous visualizations that it helps decide whether ‘s’ will be transliterated to ‘_’. Below are the top 4 input-output pairs judged by this neuron:

So this neuron is most helpful in predicting ‘s’ as ‘_’, which we already knew, but it also helps decide whether the Latin letter ‘h’ should be transliterated to Armenian letter ‘հ’ or placeholder ‘_’. (For example, the Armenian letter ‘չ’ is often romanized as ‘ch’, so ‘h’ sometimes becomes ‘_’).
When the input is ‘h’ and the output is ‘_’, we visualized the Hellinger distances between the activation histograms of the neurons, and found that in the case of ‘h’ => ‘_’, neuron #70 is also one of the top ten neurons in the left-to-right LSTM.
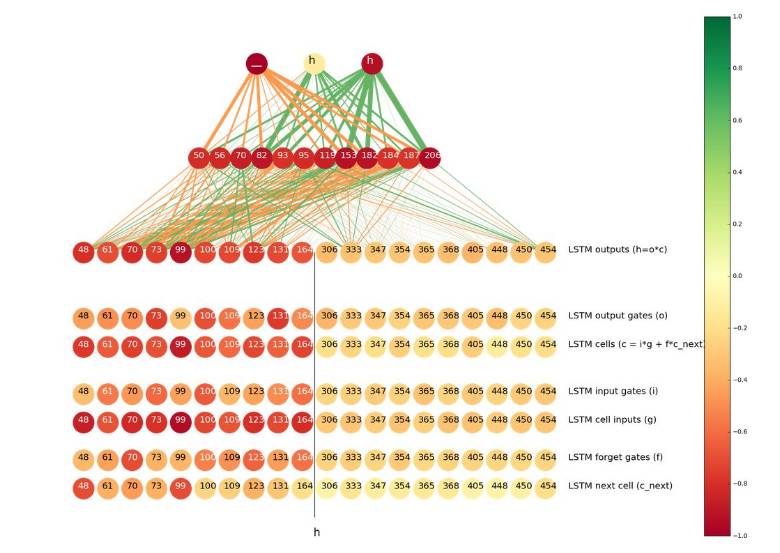
Visualizing LSTM Cells
Inspired by the paper “Visualizing and Understanding Recurrent Networks” by Andrej Karpathy, Justin Johnson, and Fei-Fei Li, we attempted to find the neurons most responsive to the suffix ‘թյուն’ (romanized as ‘tyun’).

The first row visualizes the output sequence. The following rows show the activation levels of the most interesting neurons:
-
Cell #6 in the reverse LSTM from output to input
-
Cell #147 in the forward LSTM from input to output
-
The 37th neuron in the hidden layer
-
The 78th neuron in the connection layer

We can see that cell #6 is very active on ‘tyuns’ but not active on other parts of the sequence. Cell #144 in the forward LSTM has the exact opposite behavior; it is interested in everything except for ‘tyuns’.
We know that in Armenian, the prefix ‘t’ in ‘tyuns’ should always become ‘թ’, so we believe that if a neuron is interested in ‘tyuns’, it may help decide whether the Latin ‘t’ should be transliterated to ‘թ’ or ‘տ’. Therefore, we visualized the most important neurons in the case of the input-output pair ‘t’ => ‘թ’.
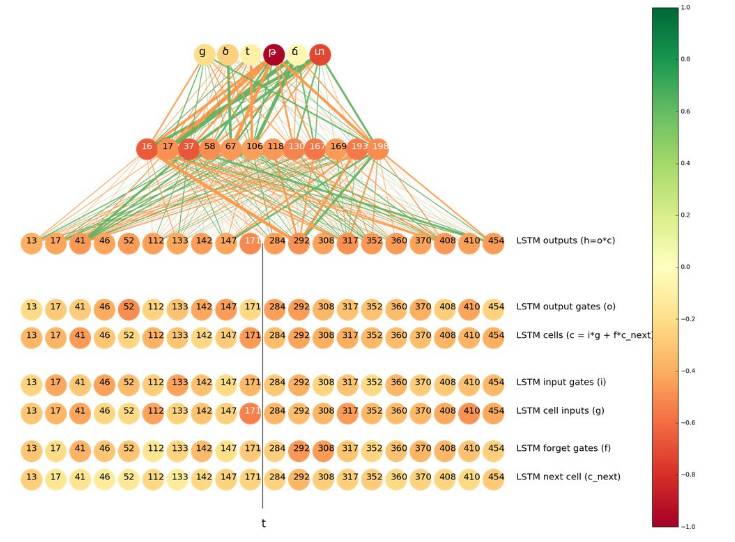
In fact, cell #147 in the forward LSTM is also among the top 10.
Conclusion
The interpretability of neural networks remains a challenge in machine learning. Convolutional neural networks and long short-term memory perform well on many learning tasks, but few tools can understand the internal workings of these systems. Transliteration is a good problem for analyzing the actual roles of neurons.
Our experiments demonstrate that even in very simple examples, a large number of neurons are involved in decision-making, but it is possible to find a subset of neurons that are more influential than others. On the other hand, depending on the context, most neurons are involved in multiple decision processes. Since the loss function we used when training the neural network did not enforce independence and interpretability among neurons, this is expected. Recently, there have been attempts to use information-theoretic regularization methods for greater interpretability. Testing these ideas on the transliteration task would be interesting.

Original text address: http://yerevann.github.io/2017/06/27/interpreting-neurons-in-an-LSTM-network/
This article is translated by Machine Heart. Please contact this public account for authorization to reprint..
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or inquiries: [email protected]
Advertisement & Business Cooperation: [email protected]
Click to read the original text and view the Machine Heart official website↓↓↓