
Selected from arXiv
Author:Vihar Kurama
Translated by Machine Heart
Contributors: Liu Xiaokun, Li Yazhou
Recently, CMU and the University of Montreal proposed a novel multi-level memory RNN architecture—Nested LSTM. When accessing internal memory, Nested LSTM has greater flexibility compared to traditional Stacked LSTM, allowing it to handle longer temporal scales of internal memory; experiments also show that NLSTM outperforms Stacked LSTM on various tasks. The authors believe that Nested LSTM has the potential to directly replace Stacked LSTM.
Although there has been some research on hierarchical memory, LSTM and its variants remain the most popular deep learning models for sequential tasks, such as character-level language modeling. Specifically, the default Stacked LSTM architecture uses a series of LSTMs stacked layer by layer to process data, where the output of one layer becomes the input of the next. In this paper, the researchers propose and explore a brand new Nested LSTM architecture (NLSTM) and believe it has the potential to directly replace Stacked LSTM.
In NLSTM, the memory units of LSTM can access internal memory, selectively reading and writing using standard LSTM gates. This key feature enables the model to achieve more effective temporal hierarchy compared to traditional Stacked LSTM. In NLSTM, the (external) memory units can freely choose to read and write relevant long-term information to internal units. In contrast, in Stacked LSTM, high-level activations (similar to internal memory) directly generate outputs, thus must contain all short-term information relevant to the current prediction. In other words, the main difference between Stacked LSTM and Nested LSTM is that NLSTM can selectively access internal memory. This allows internal memory to avoid remembering and processing events over longer temporal scales, even if those events are not related to the current event.
In this paper, the authors’ visualization graphs prove that, compared to high-level memory in Stacked LSTM, the internal memory of NLSTM can indeed operate over longer temporal scales. Experiments also show that NLSTM outperforms Stacked LSTM on various tasks.
Nested LSTM
Intuitively, the output gate in LSTM encodes information worth remembering, which may not be related to the current time step. Nested LSTM creates a temporal hierarchy of memory based on this intuitive understanding. Accessing internal memory is gated in the same way, so that long-term information can only be selectively accessed under contextually relevant conditions.
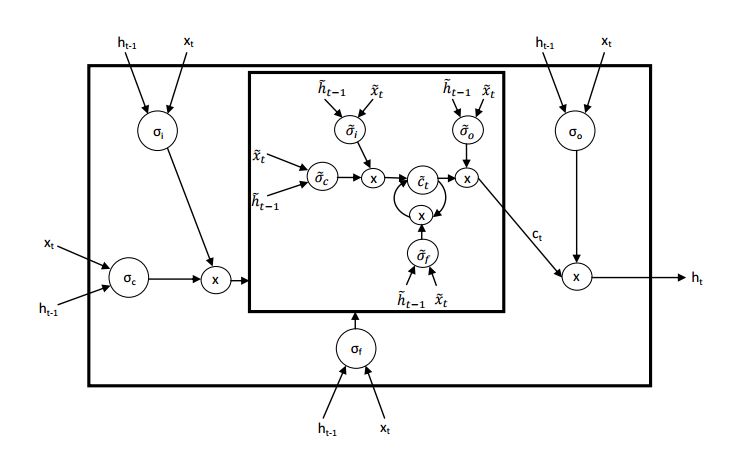
Figure 1: Nested LSTM Architecture
Architecture
In the LSTM network, the update formula for the cell state and the gating mechanism can be represented as the following equations:
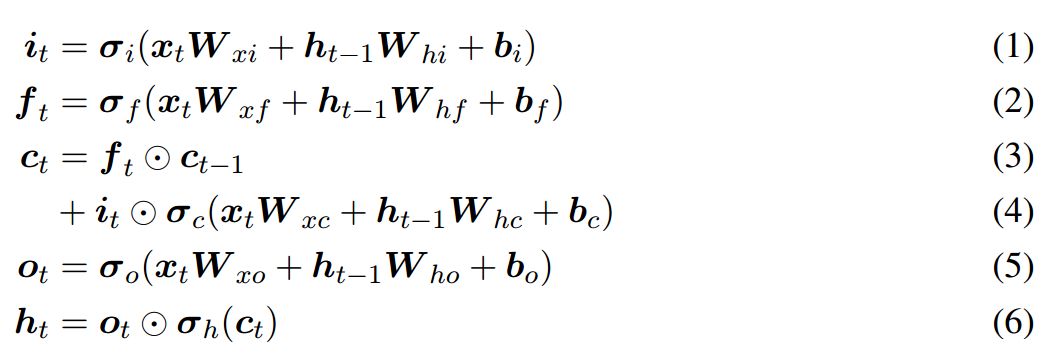
These equations are very similar to those defined by Graves (2013) and others, but do not include peephole connections. Nested LSTM uses the learned state function c_t = m_t(f_t⊙c_t−1, i_t⊙g_t) to replace the addition operation for calculating c_t in LSTM. We represent the state of the function as m, the internal memory at time t, and we call this function to compute c_t and m_t+1. We can use another LSTM unit to implement this memory function, thus generating Nested LSTM as shown in Figure 1. Similarly, this memory function can be replaced by another Nested LSTM unit, allowing for the construction of arbitrarily deep nested networks.
Given the architectural features described above, the inputs and hidden states of the memory function in NLSTM are:
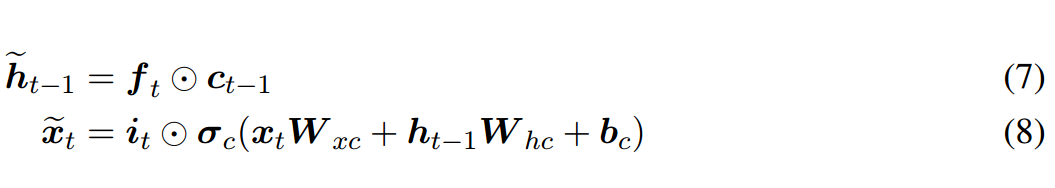
In particular, note that if the memory function is additive, then the entire system will degenerate to classic LSTM, thus the state update for the memory unit is:

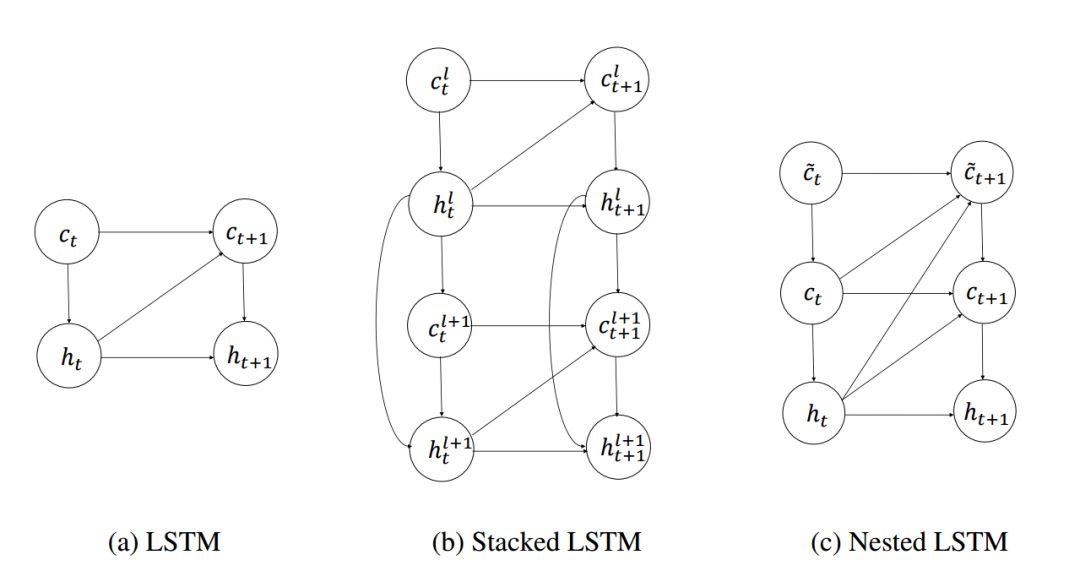
Figure 2: Computational Graphs of LSTM, Stacked LSTM, and Nested LSTM. The hidden state, external memory unit, and internal memory unit are represented by h, c, and d, respectively. The current hidden state can directly influence the content of the next internal memory unit, while the internal memory unit only influences the hidden state through the external memory unit.
In the Nested LSTM variant architecture proposed in this paper, we will use LSTM as the memory function, and the operation of the internal LSTM is controlled by the following set of equations:
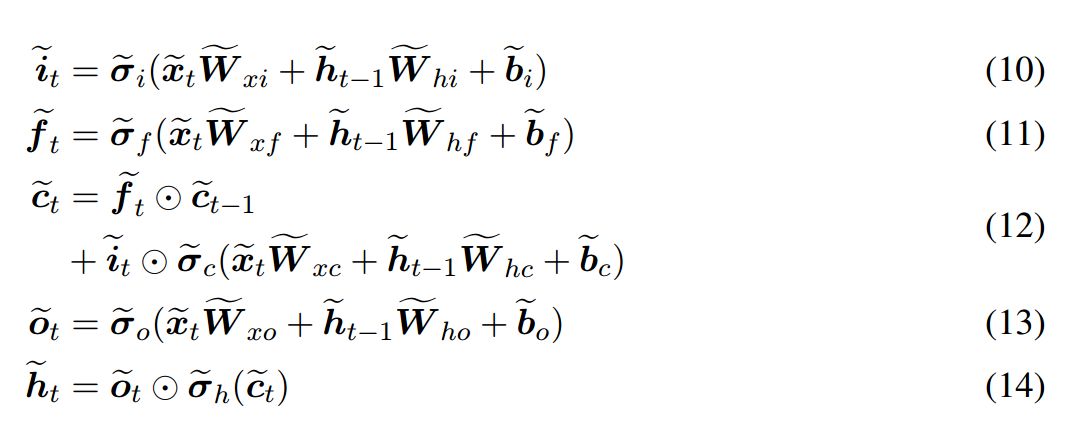
Now, the update method for the external LSTM’s cell state is:

Experiments
Visualization

Figure 3: Visualization of unit activations for input features of internal units (left) and external units (right). Red indicates negative unit state values, while blue indicates positive unit state values. Deeper colors indicate larger values. For the internal LSTM state, tanh(c_t tilde) is visualized (since c_t tilde is unconstrained), while for the external LSTM state, c_t is visualized directly.

Figure 4: Visualization of tanh(c^n_t), representing unit activations for input characters of the first (right) and second (left) stacked layers. Red indicates negative unit state values, while blue indicates positive unit state values. Deeper colors indicate larger values.
Penn Treebank Character-Level Language Modeling
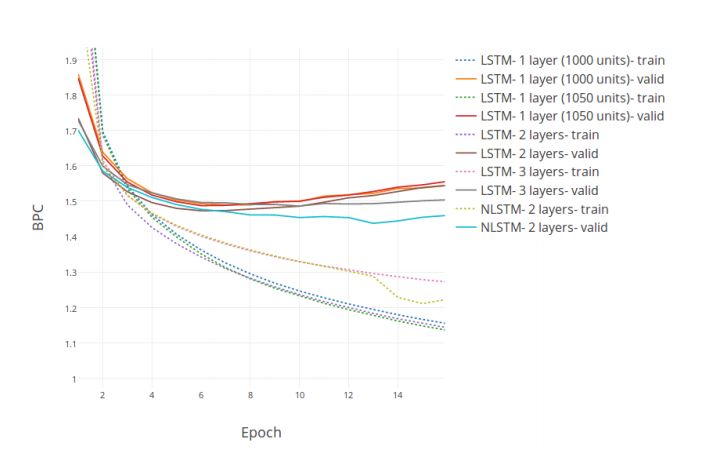
Figure 5: BPC (bits per character) vs. Epoch curve on the PTB test and validation sets.
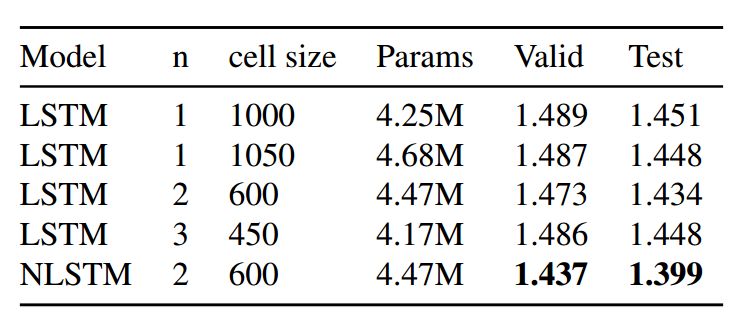
Table 1: Comparison of BPC loss between Nested LSTM and multiple baseline models. The BPC loss for testing is related to the loss of each model at the epoch with the minimum validation (valid) BPC value.
Chinese Poetry Generation
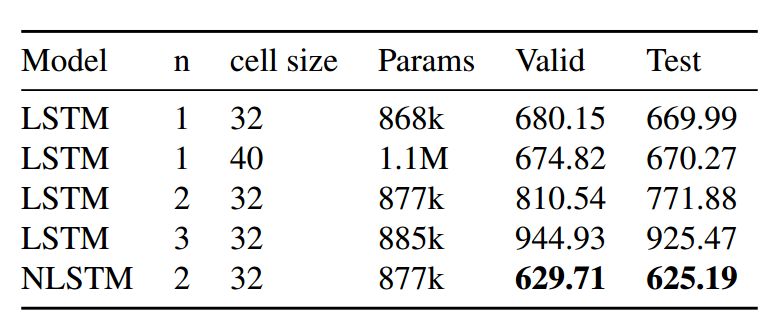
Table 2: Comparison of perplexity between Nested LSTM and multiple baseline models on the Chinese Poetry Generation dataset.
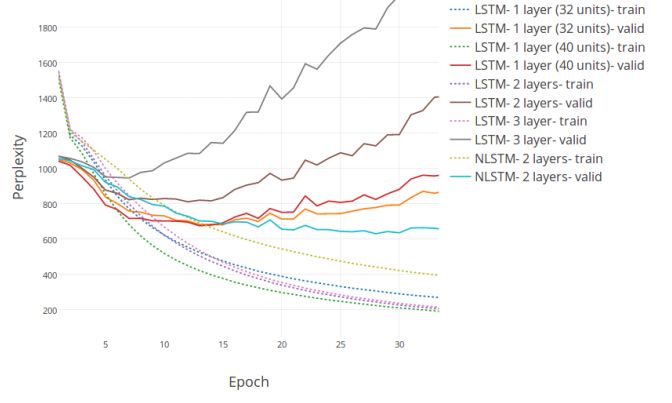
Figure 6: Perplexity vs. Epoch curve for character-level predictions on the Chinese Poetry Generation test and validation sets.
MNIST Glimpses
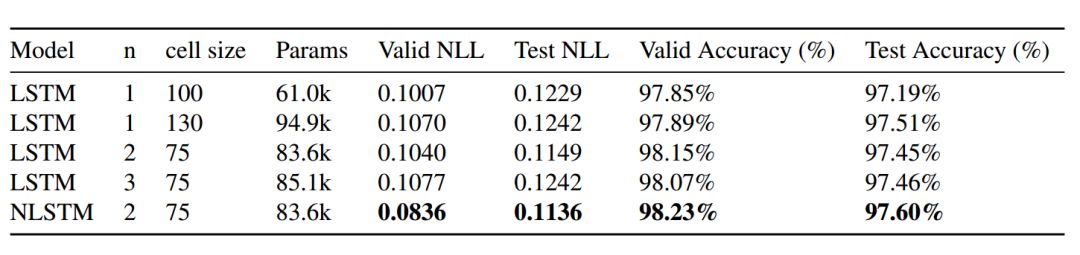
Table 3: Comparison of NLL (negative log likelihood) and accuracy between Nested LSTM and multiple baseline models on the MNIST Glimpses task. The epoch used is the one where each model had the highest accuracy on the validation set. Similar to NLL, the validation NLL of the model was used to determine the epoch for the test NLL.
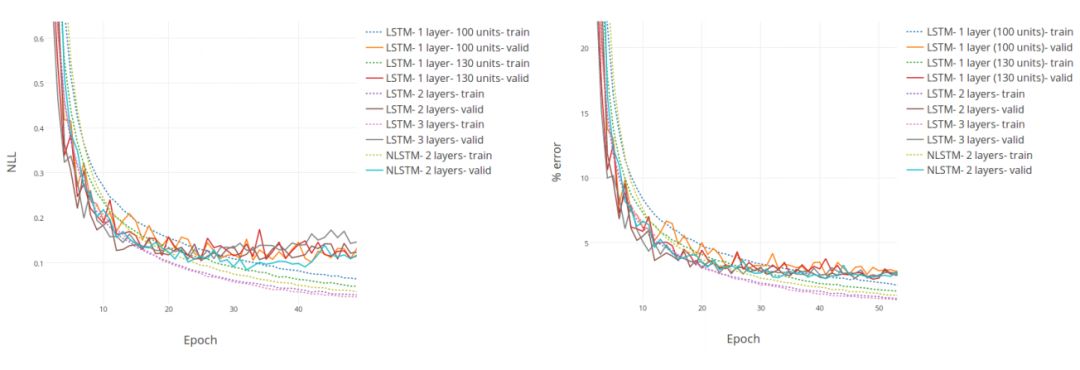
Figure 7: NLL (left) and error rate (right) vs. Epoch curves on the training and validation sets of MNIST Glimpses.
Paper: Nested LSTMs

Paper link: https://arxiv.org/pdf/1801.10308.pdf
In this paper, we propose Nested LSTM (NLSTM), a novel multi-level memory RNN architecture. NLSTM increases the depth of LSTM through nesting (as opposed to stacking). The value of a memory unit in NLSTM is computed by an LSTM unit (which has its own internal memory unit). Specifically, the NLSTM memory unit does not compute the value of the (external) memory unit like classic LSTM: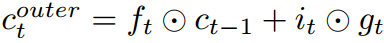 but utilizes cascading:
but utilizes cascading: 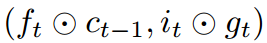 as the input to the internal LSTM (or NLSTM) memory unit, and sets
as the input to the internal LSTM (or NLSTM) memory unit, and sets 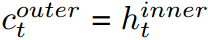 . Our experiments show that, with a similar number of parameters, Nested LSTM outperforms Stacked and single-layer LSTM on various character-level language modeling tasks, and that the internal memory of LSTM can learn longer-term dependencies compared to the high-level units of Stacked LSTM.
. Our experiments show that, with a similar number of parameters, Nested LSTM outperforms Stacked and single-layer LSTM on various character-level language modeling tasks, and that the internal memory of LSTM can learn longer-term dependencies compared to the high-level units of Stacked LSTM.
This article is translated by Machine Heart, please contact this public account for authorization..
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or Seeking Coverage: [email protected]
Advertising & Business Cooperation: [email protected]
Click “Read the Original” to participate in the discussion of this paper on PaperWeekly