
Author | Christopher Olah
Source | Datawhale
Translation | Liu Yang
Proofreading | Hu Yanjun (OneFlow)
About ten years ago, deep neural networks began to achieve breakthrough results in fields such as computer vision, attracting great interest and attention.
However, some people still express concerns. One reason is that neural networks are black boxes: if a neural network is well-trained, it can achieve high-quality results, but it is difficult to understand how it works. If a neural network fails, it is also challenging to identify the problem.
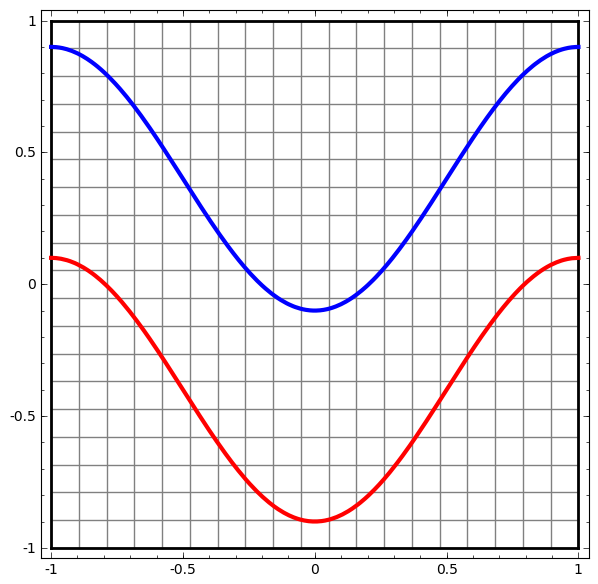
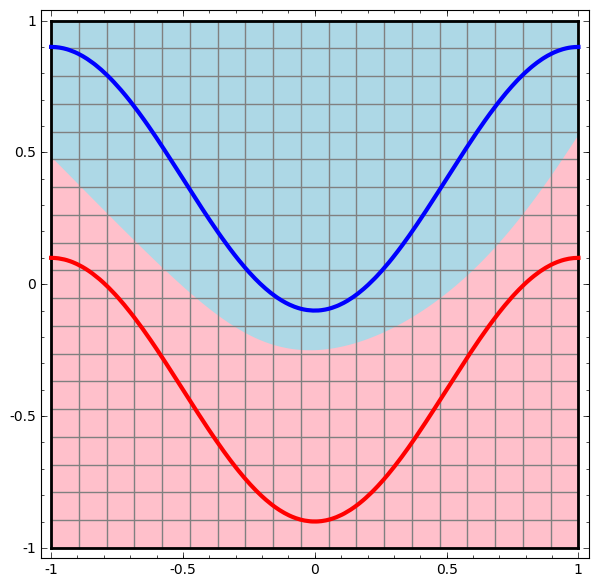
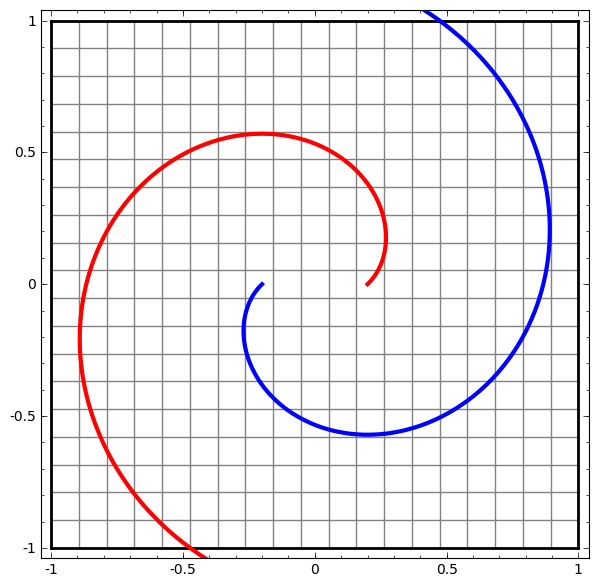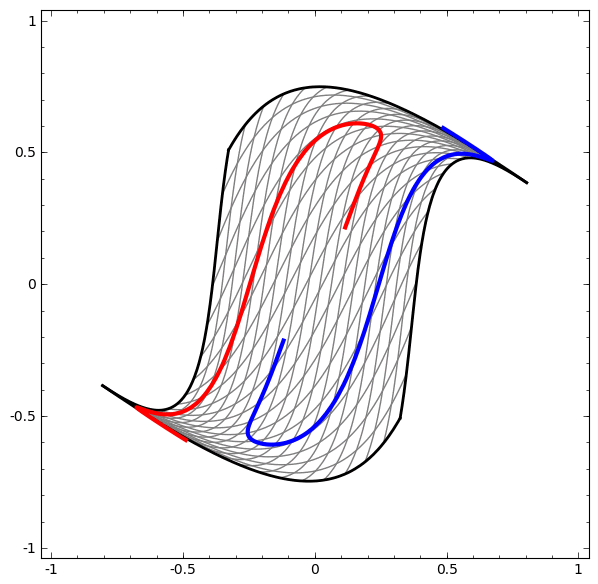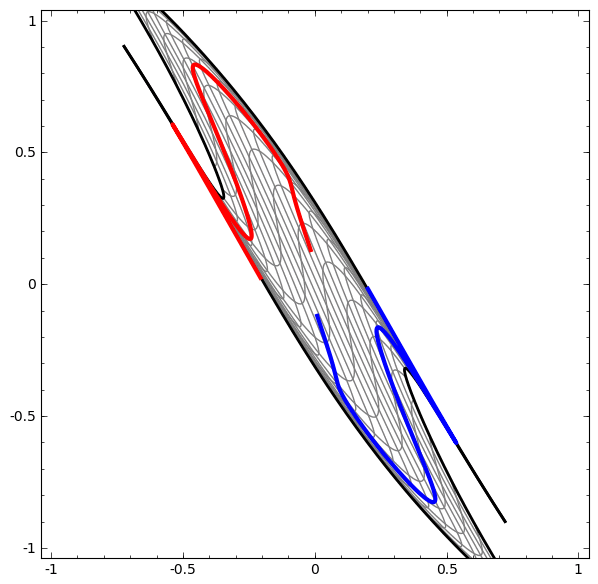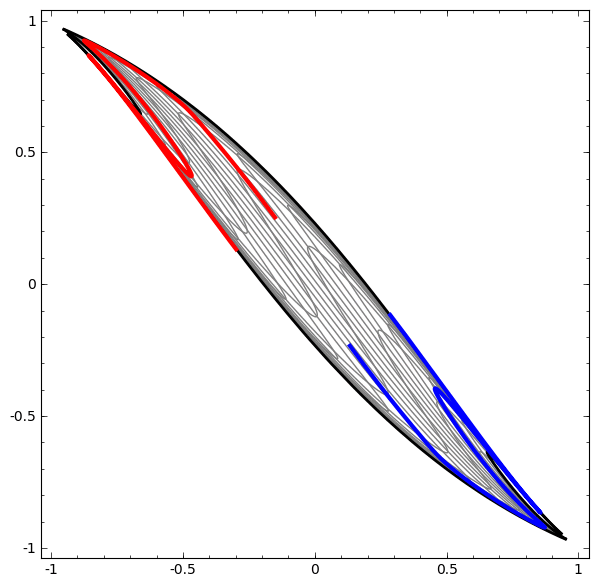
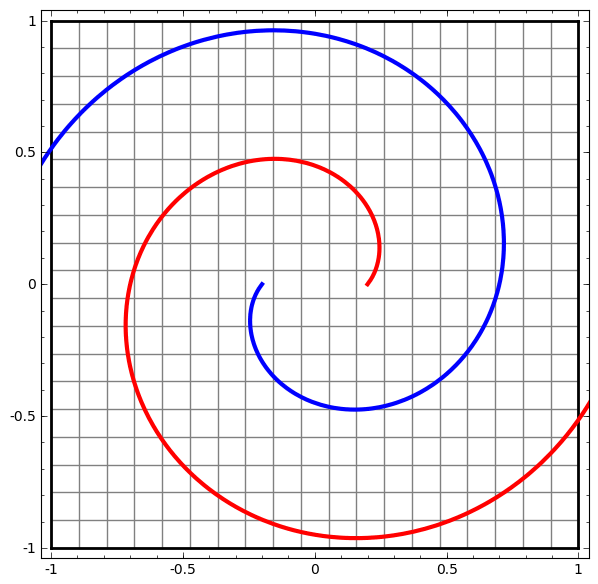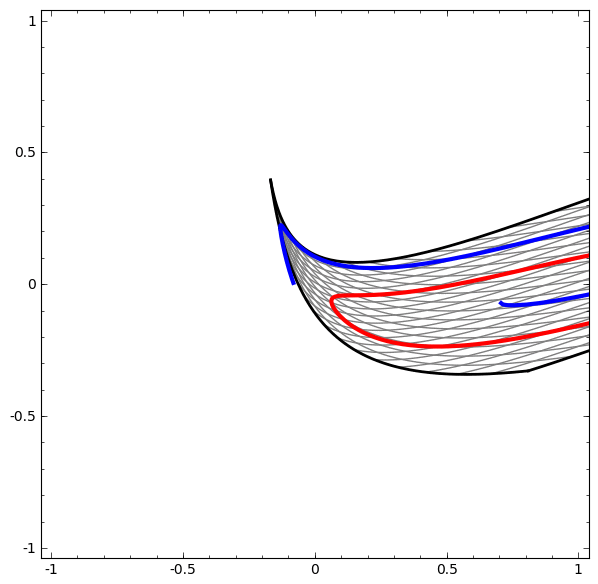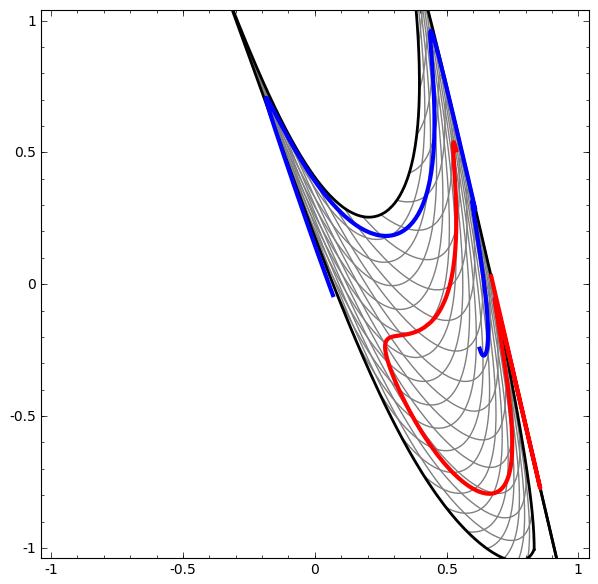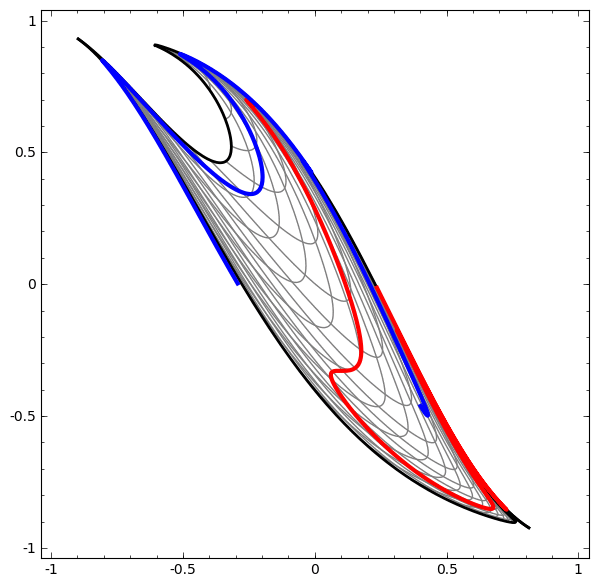
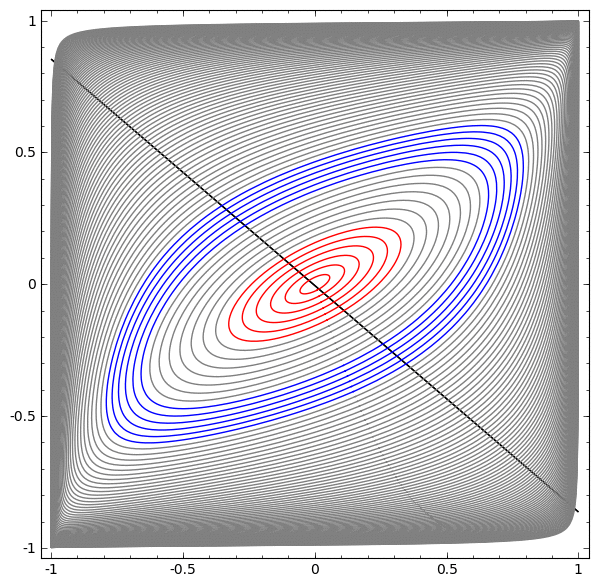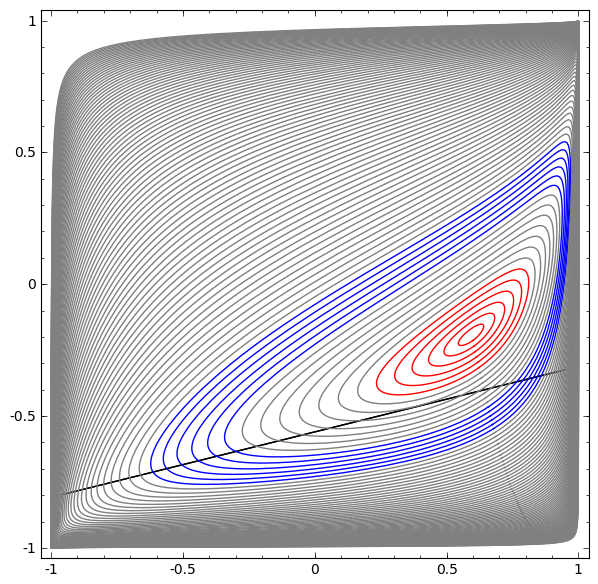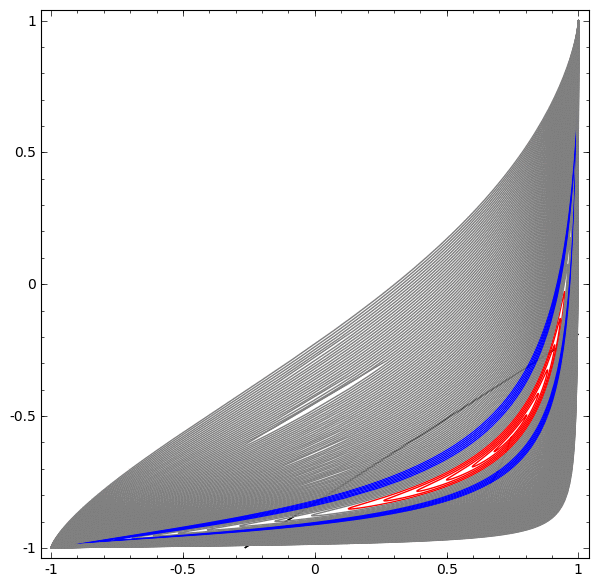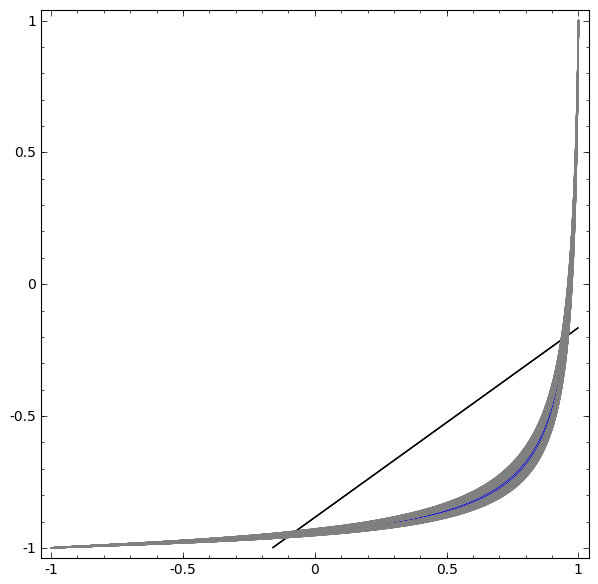
Although it is difficult to understand deep neural networks as a whole, we can start with low-dimensional deep neural networks, which are networks with only a few neurons per layer, making them much easier to understand. We can use visualization methods to understand the behavior and training of low-dimensional deep neural networks. Visualization methods allow us to intuitively understand the behavior of neural networks and observe the connection between neural networks and topology.
Next, I will discuss many interesting things, including the lower bounds of the complexity of neural networks that can classify specific datasets.
-
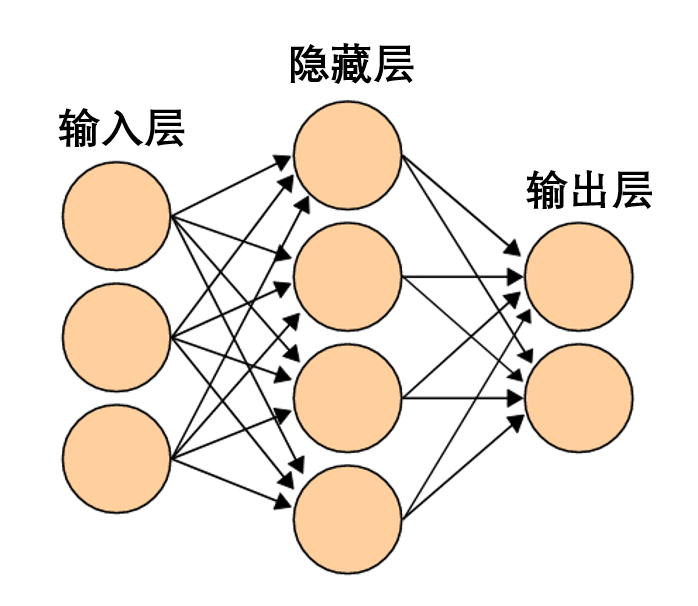
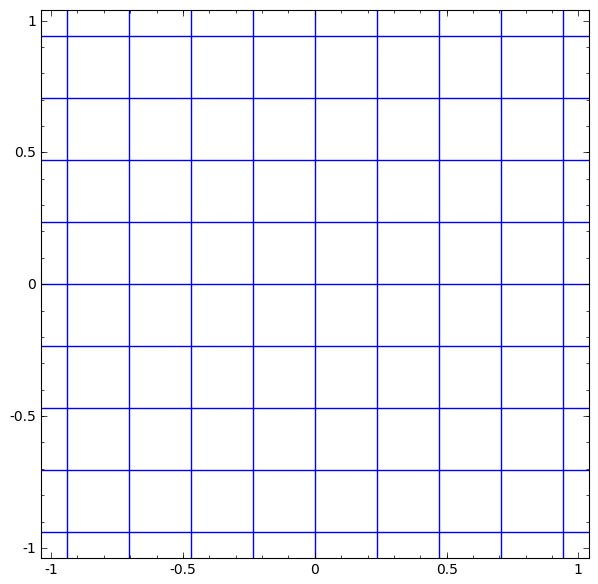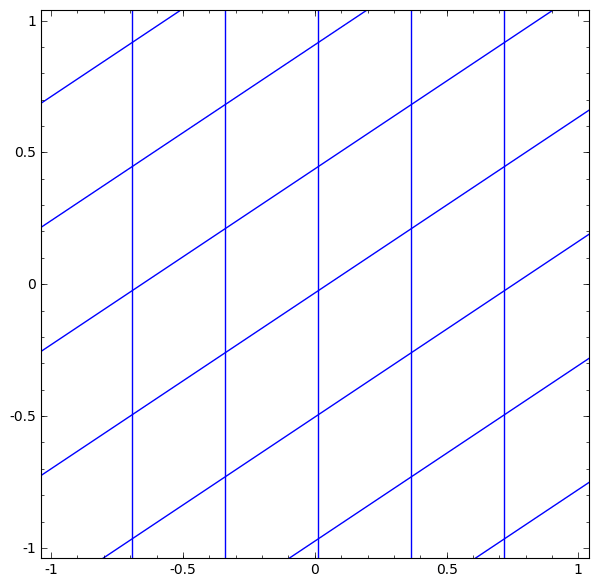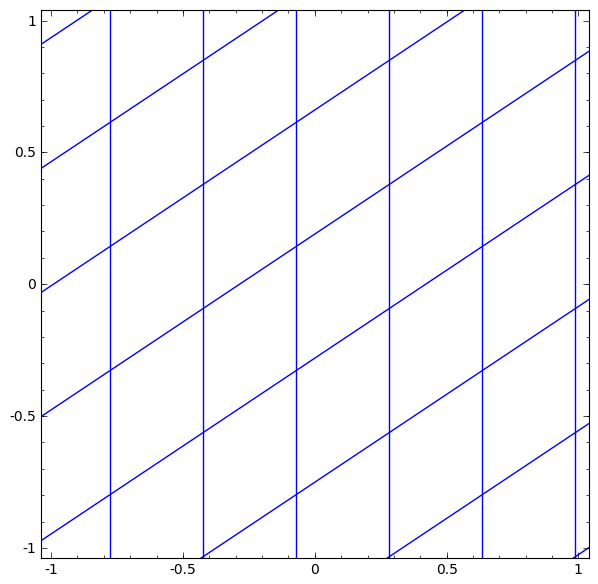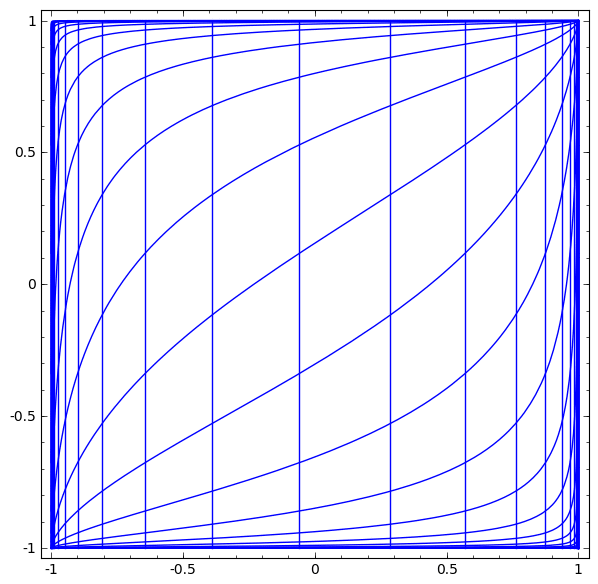
Linear transformation using the “weight” matrix W
-
Translation using vector b
-
Pointwise representation using tanh

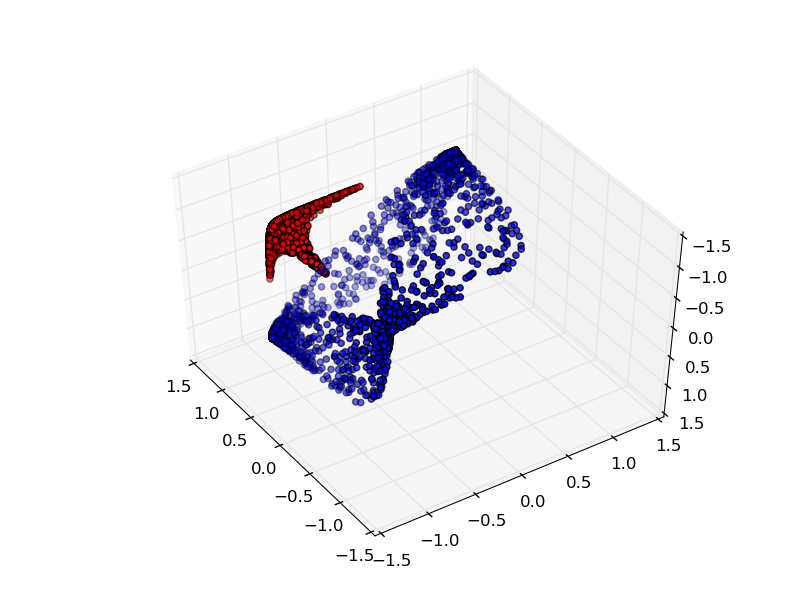
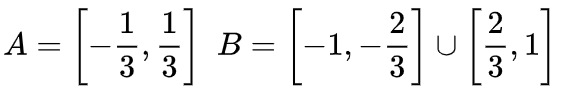
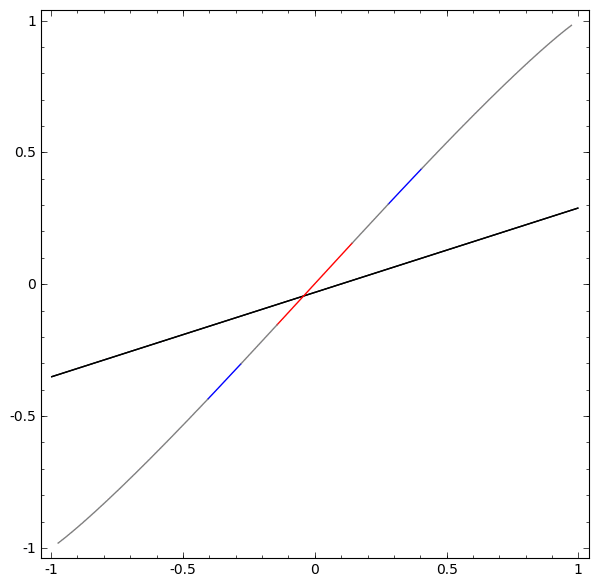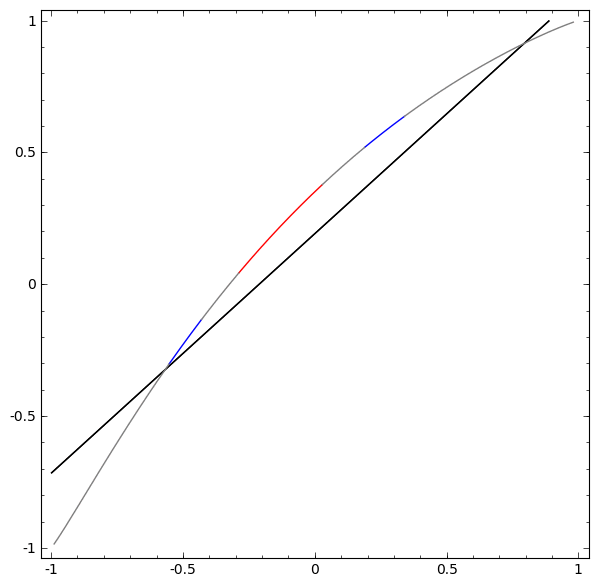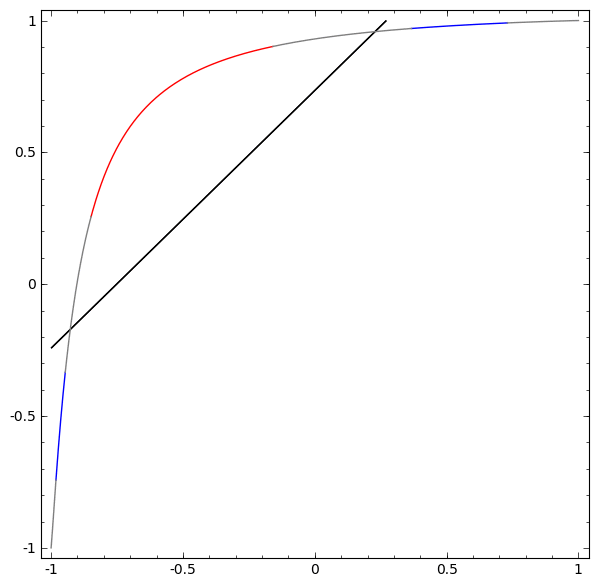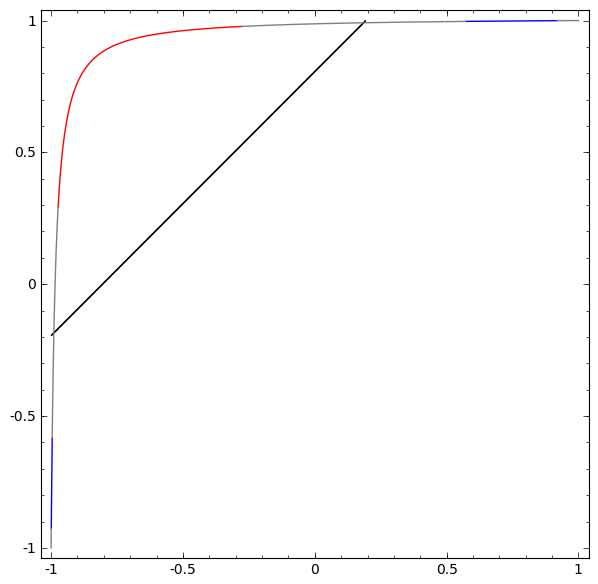
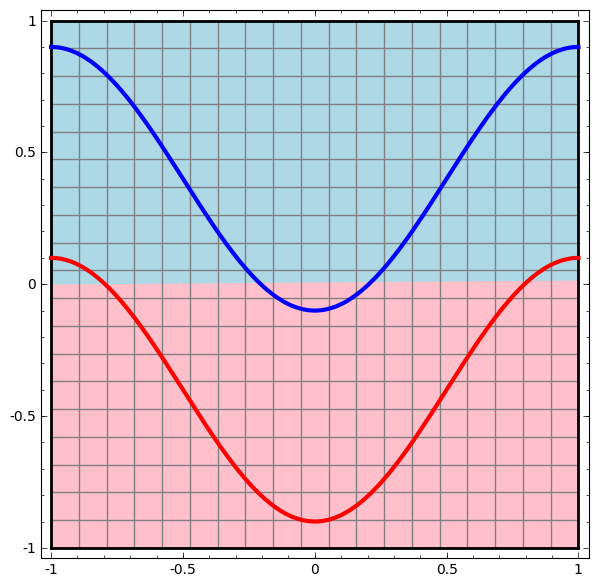
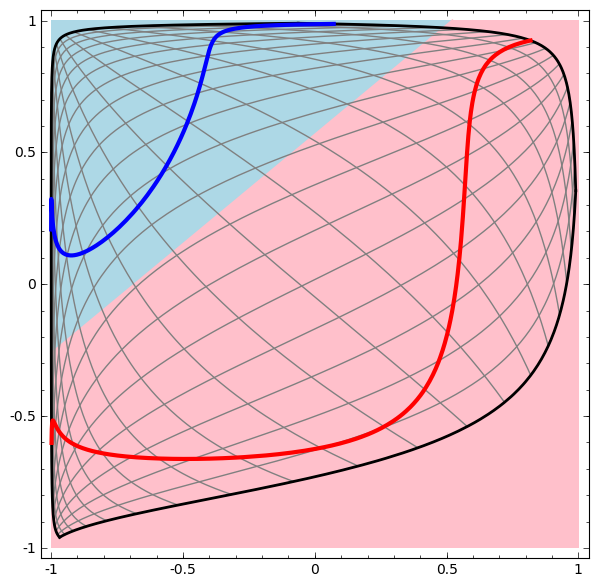
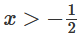 is activated, one hidden unit is activated; when
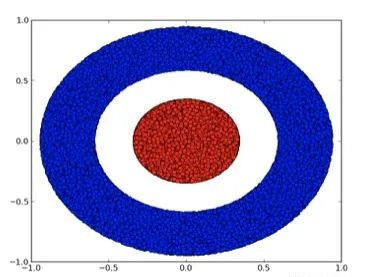
is activated, one hidden unit is activated; when 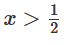 is activated, the other hidden unit is activated. When the first hidden unit is activated while the second hidden unit is not, it can be determined that this is a data point belonging to class A.
is activated, the other hidden unit is activated. When the first hidden unit is activated while the second hidden unit is not, it can be determined that this is a data point belonging to class A.
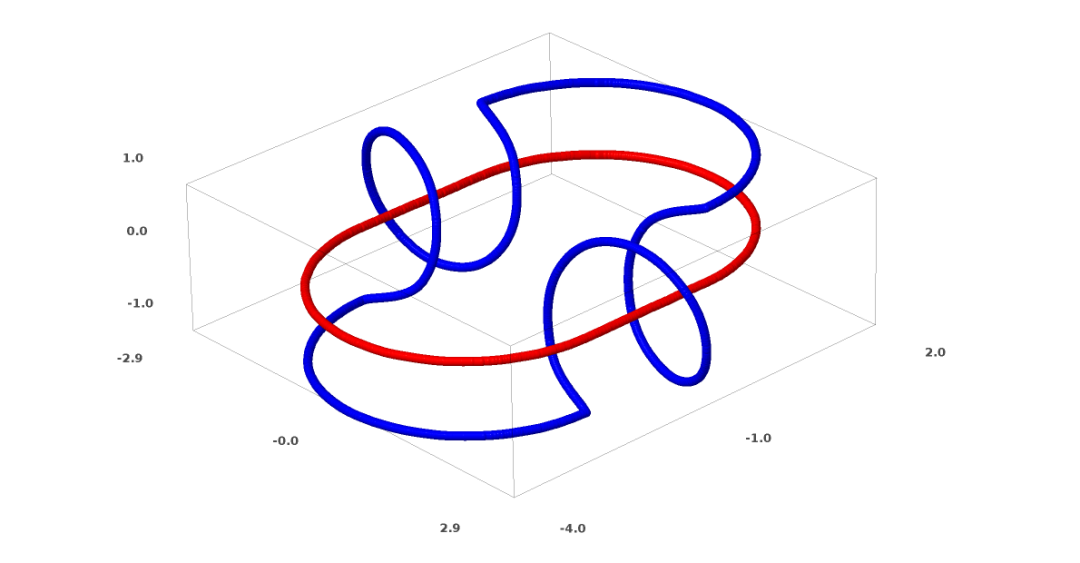
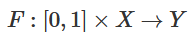
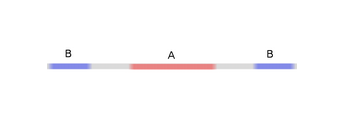
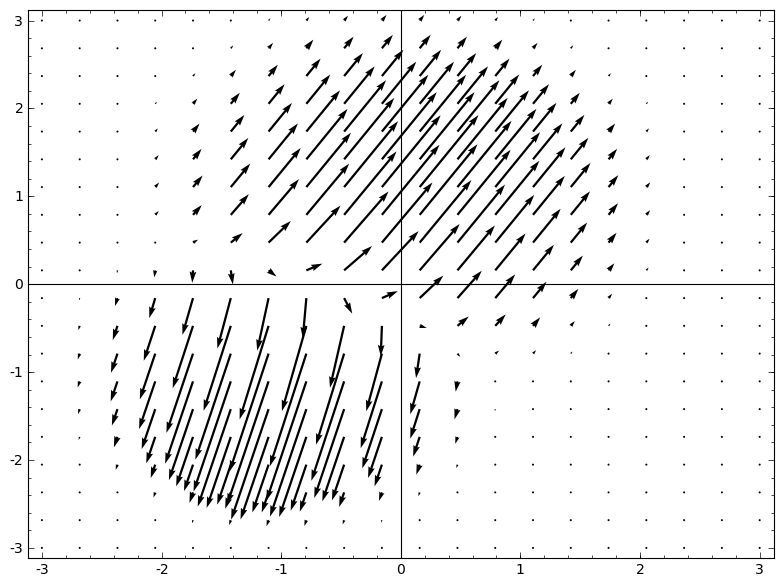
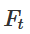 is homeomorphic to X.
is homeomorphic to X.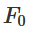 is the characteristic function,
is the characteristic function, 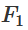 maps A to B. That is,
maps A to B. That is, 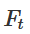 continuously transitions from mapping A to itself to mapping A to B.
continuously transitions from mapping A to itself to mapping A to B.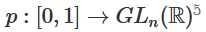 therefore,
therefore, 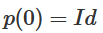 ,
, 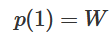 .
. we can continuously transition the characteristic function to W transformation, multiplying the matrix
we can continuously transition the characteristic function to W transformation, multiplying the matrix 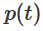 at each point in time.
at each point in time.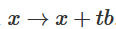 .
.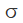 can be achieved through pointwise applications.
can be achieved through pointwise applications.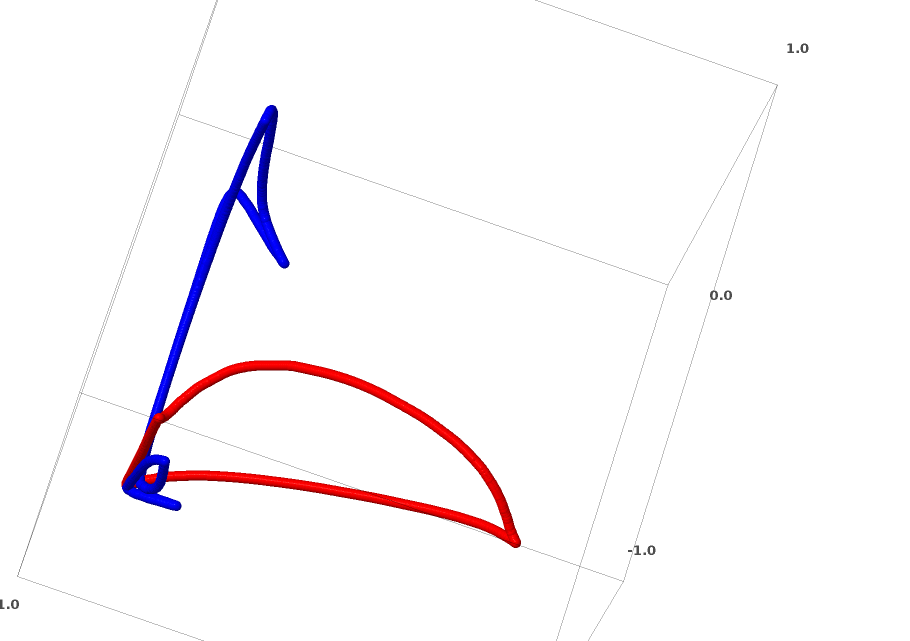

ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。
阅读至此了,分享、点赞、在看三选一吧🙏