Click on the top "Xiaobai Learns Vision", select to add "Star" or "Pin"
Heavyweight content delivered at the first time
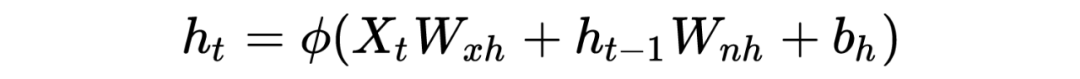
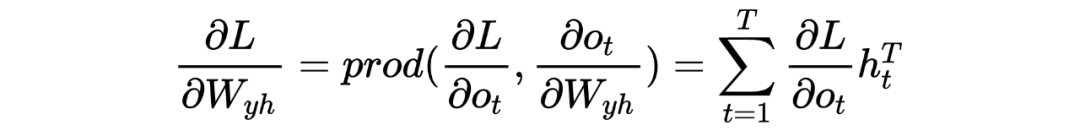
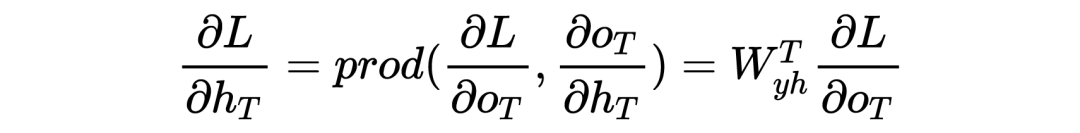
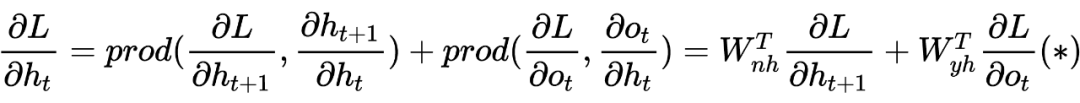
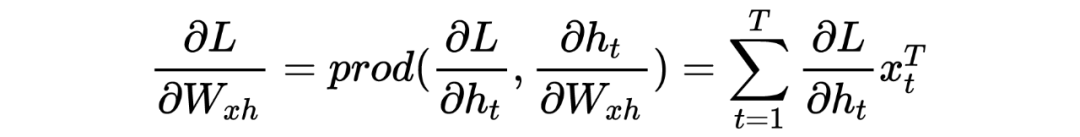
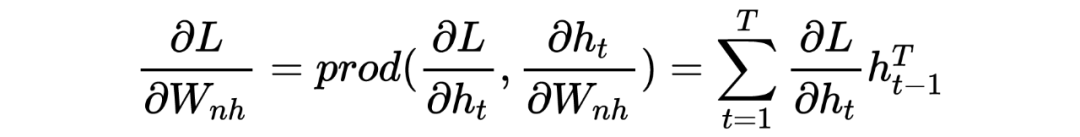
2 Explanation of Gradient Vanishing (Exploding) Principle
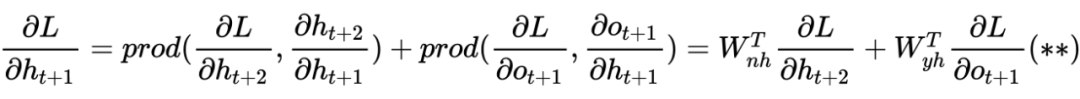
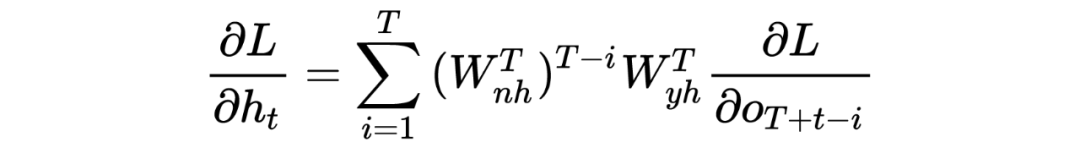
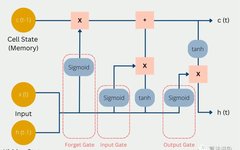
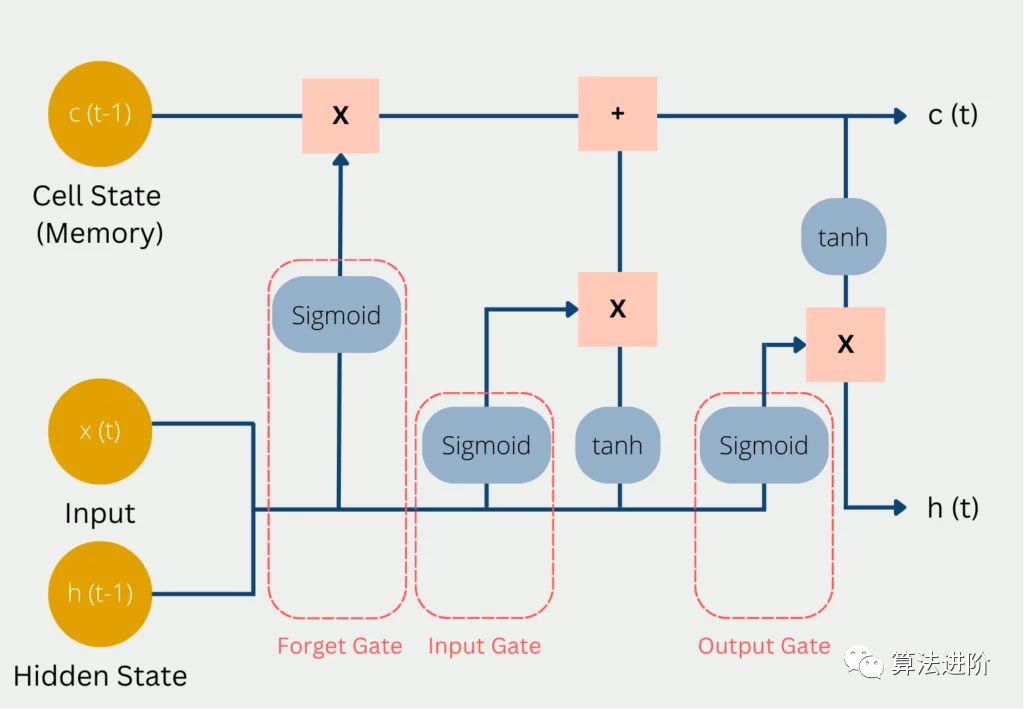
3 Introduction to LSTM Underlying Theory
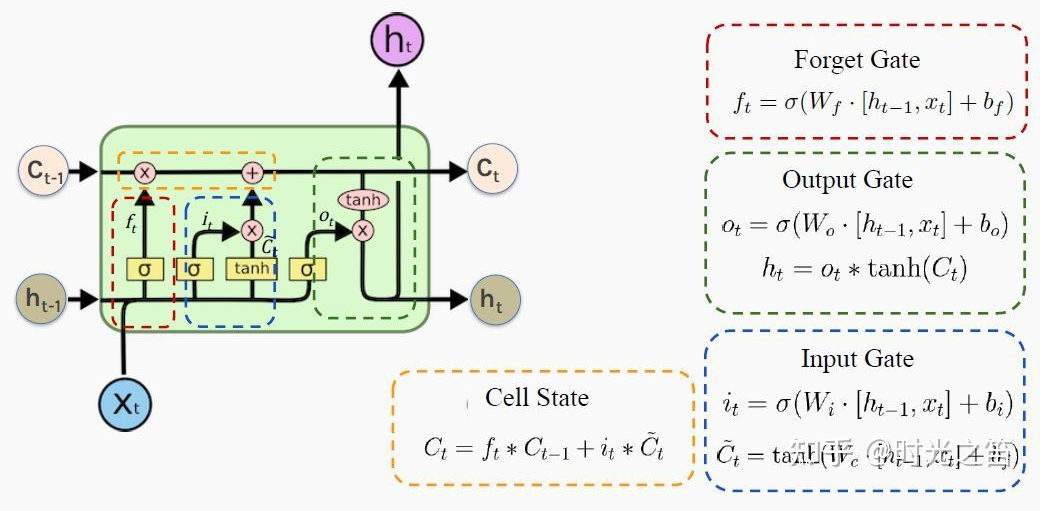
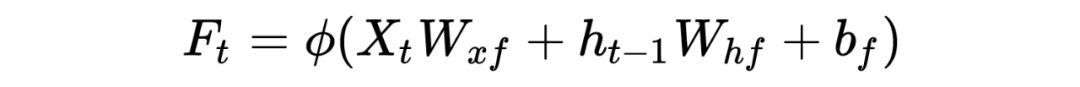
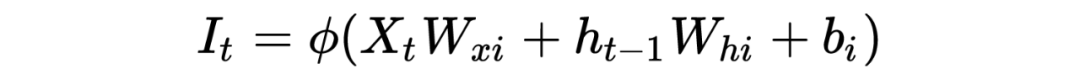
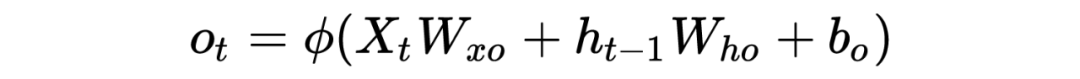
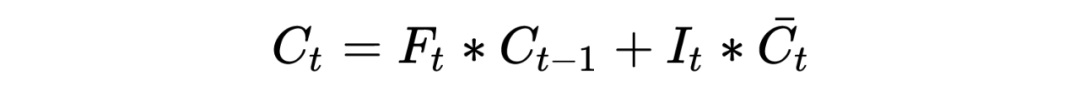
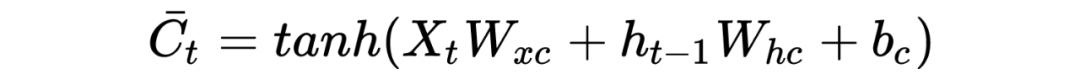
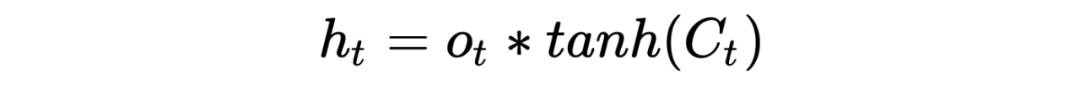
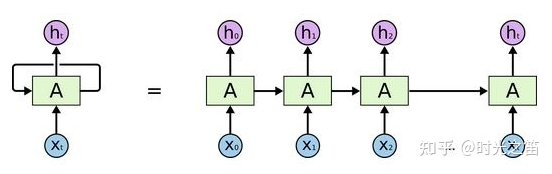
PS: Beginners may find it painful to see so many symbols, but the logic goes from simple to complex. Thoroughly understanding RNN helps with understanding later models. I have also omitted many details here; the overall model framework is like this, which is completely sufficient for understanding how the model works. As for how it was derived and the more detailed derivation process, due to the author’s limited ability, please refer to relevant RNN papers and engage in more discussions and learning!
4 What to Do About “Right Shift” in Model Prediction!
5 Improved Model Output

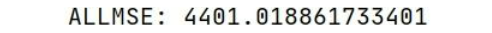
6 Final Code
from keras.callbacks import LearningRateScheduler
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
import matplotlib.pyplot as plt
from keras.layers import Dense
from keras.layers import LSTM
from keras import optimizers
import keras.backend as K
import tensorflow as tf
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']##Chinese garbled problem!
plt.rcParams['axes.unicode_minus']=False#Horizontal axis negative sign display problem!
###Initialize parameters
my_seed = 369#Random seed
tf.random.set_seed(my_seed)##Running tf can truly fix the random seed
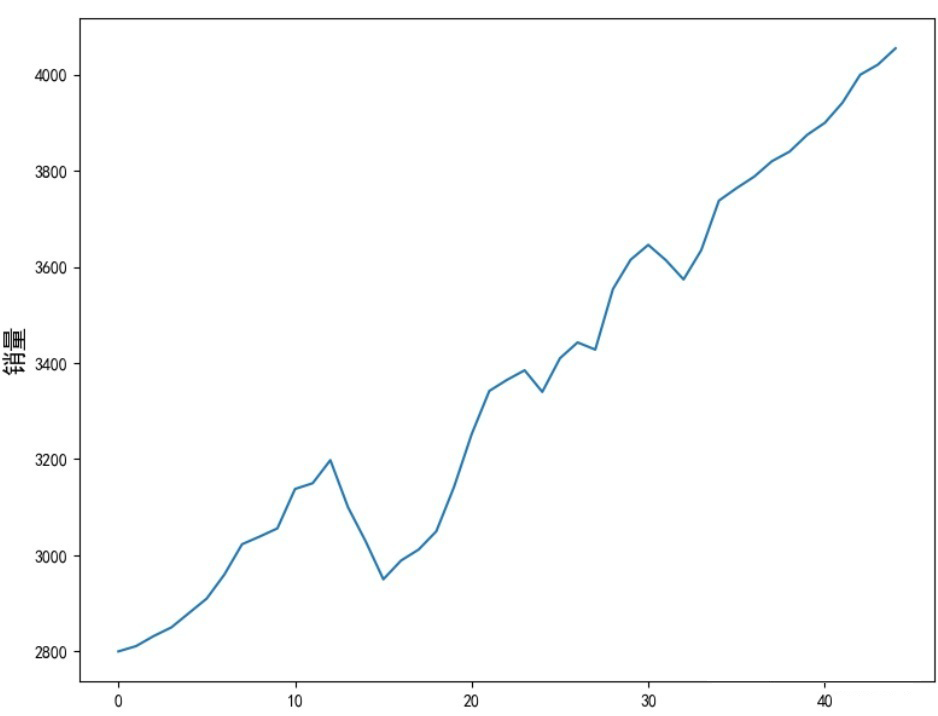
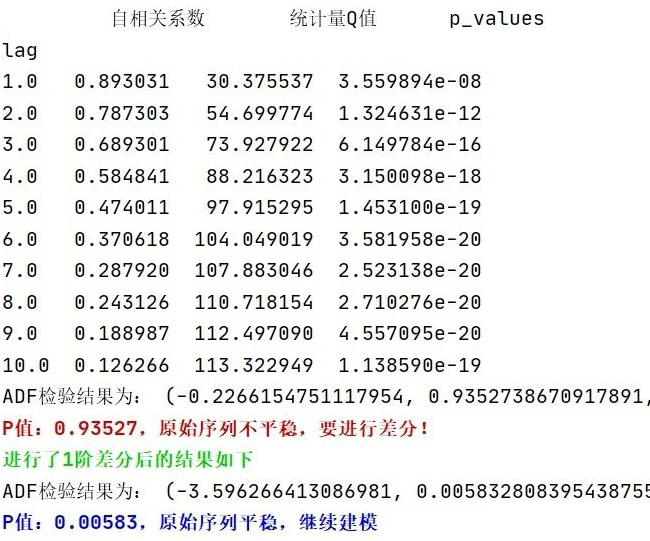
sell_data = np.array([2800,2811,2832,2850,2880,2910,2960,3023,3039,3056,3138,3150,3198,3100,3029,2950,2989,3012,3050,3142,3252,3342,3365,3385,3340,3410,3443,3428,3554,3615,3646,3614,3574,3635,3738,3764,3788,3820,3840,3875,3900,3942,4000,4021,4055])
num_steps = 3##Take sequence step length
test_len = 10##Test set length
S_sell_data = pd.Series(sell_data).diff(1).dropna()##Differencing
revisedata = S_sell_data.max()
sell_datanormalization = S_sell_data / revisedata##Data normalization
##Data shape transformation, very important!!
def data_format(data, num_steps=3, test_len=5):
# Group according to test_len
X = np.array([data[i: i + num_steps]
for i in range(len(data) - num_steps)])
y = np.array([data[i + num_steps]
for i in range(len(data) - num_steps)])
train_size = test_len
train_X, test_X = X[:-train_size], X[-train_size:]
train_y, test_y = y[:-train_size], y[-train_size:]
return train_X, train_y, test_X, test_y
transformer_selldata = np.reshape(pd.Series(sell_datanormalization).values,(-1,1))
train_X, train_y, test_X, test_y = data_format(transformer_selldata, num_steps, test_len)
print('\033[1;38mOriginal sequence dimension information:%s;Converted training set X data dimension information:%s,Y data dimension information:%s;Test set X data dimension information:%s,Y data dimension information:%s\033[0m'%(transformer_selldata.shape, train_X.shape, train_y.shape, test_X.shape, test_y.shape))
def buildmylstm(initactivation='relu',ininlr=0.001):
nb_lstm_outputs1 = 128#Number of neurons
nb_lstm_outputs2 = 128#Number of neurons
nb_time_steps = train_X.shape[1]#Time series length
nb_input_vector = train_X.shape[2]#Input sequence
model = Sequential()
model.add(LSTM(units=nb_lstm_outputs1, input_shape=(nb_time_steps, nb_input_vector),return_sequences=True))
model.add(LSTM(units=nb_lstm_outputs2, input_shape=(nb_time_steps, nb_input_vector)))
model.add(Dense(64, activation=initactivation))
model.add(Dense(32, activation='relu'))
model.add(Dense(test_y.shape[1], activation='tanh'))
lr = ininlr
adam = optimizers.adam_v2.Adam(learning_rate=lr)
def scheduler(epoch):##Write learning rate change function
# Reduce the learning rate to 1/10 of the original every epoch
if epoch % 100 == 0 and epoch != 0:
lr = K.get_value(model.optimizer.lr)
K.set_value(model.optimizer.lr, lr * 0.1)
print('lr changed to {}'.format(lr * 0.1))
return K.get_value(model.optimizer.lr)
model.compile(loss='mse', optimizer=adam, metrics=['mse'])##Based on the nature of the loss function, regression modeling generally uses "distance error" as the loss function, while classification generally selects "cross-entropy" loss function
reduce_lr = LearningRateScheduler(scheduler)
###Data set is small, all participate, epochs generally proportional to batch_size
##callbacks: Callback function, calling reduce_lr
##verbose=0: Non-redundant printing, that is, do not print the training process
batchsize = int(len(sell_data) / 5)
epochs = max(128,batchsize * 4)##Minimum loop count 128
model.fit(train_X, train_y, batch_size=batchsize, epochs=epochs, verbose=0, callbacks=[reduce_lr])
return model
def prediction(lstmmodel):
predsinner = lstmmodel.predict(train_X)
predsinner_true = predsinner * revisedata
init_value1 = sell_data[num_steps - 1]##Due to the existence of step length relationship, here the starting point is num_steps
predsinner_true = predsinner_true.cumsum() ##Differencing restoration
predsinner_true = init_value1 + predsinner_true
predsouter = lstmmodel.predict(test_X)
predsouter_true = predsouter * revisedata
init_value2 = predsinner_true[-1]
predsouter_true = predsouter_true.cumsum() ##Differencing restoration
predsouter_true = init_value2 + predsouter_true
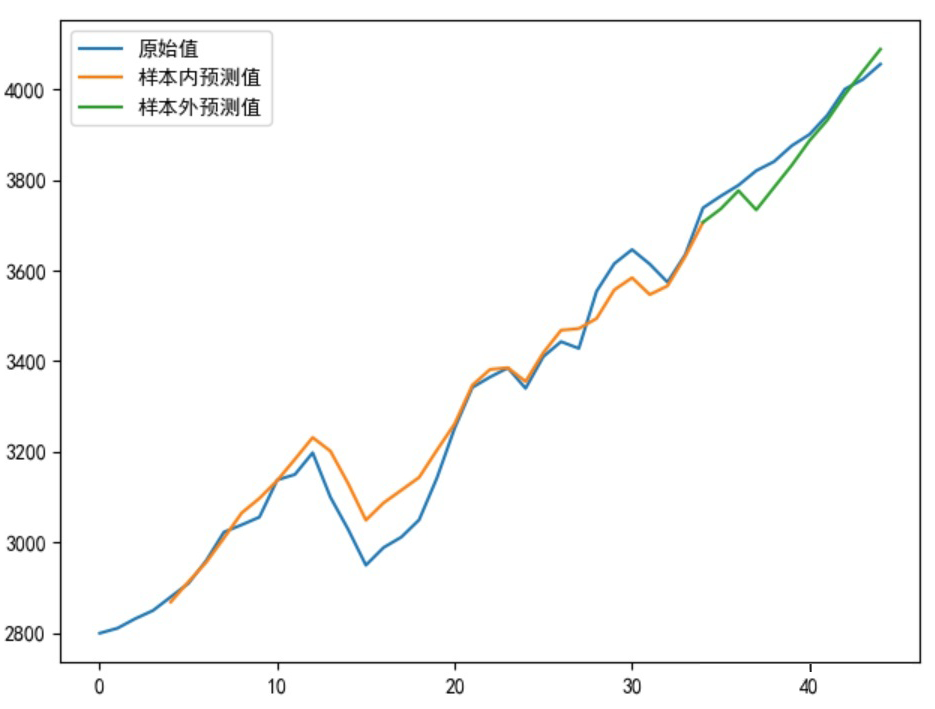
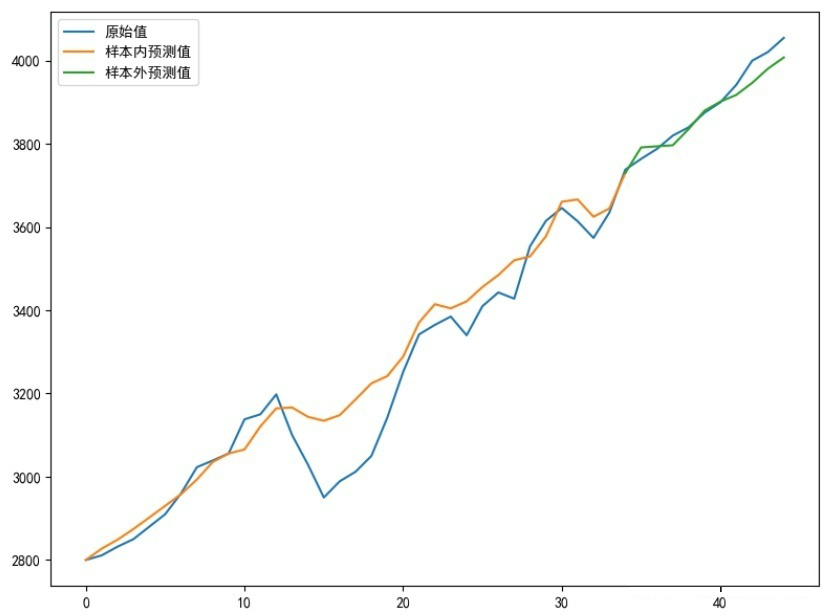
# Plotting
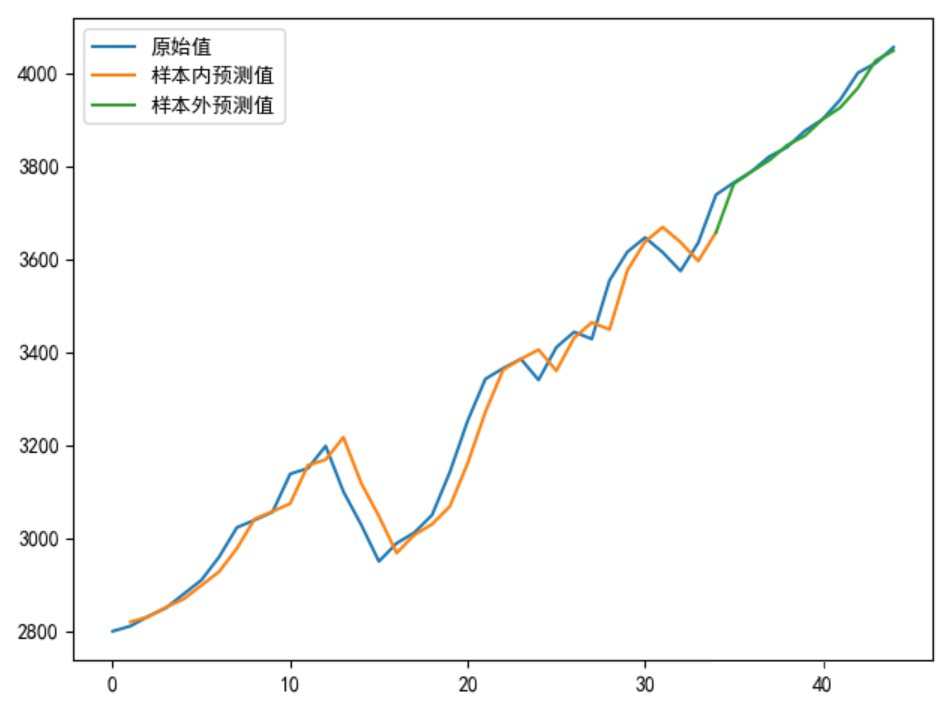
plt.plot(sell_data, label='Original Value')
Xinner = [i for i in range(num_steps + 1, len(sell_data) - test_len)]
plt.plot(Xinner, list(predsinner_true), label='Sample Inner Predicted Value')
Xouter = [i for i in range(len(sell_data) - test_len - 1, len(sell_data))]
plt.plot(Xouter, [init_value2] + list(predsouter_true), label='Sample Outer Predicted Value')
allpredata = list(predsinner_true) + list(predsouter_true)
plt.legend()
plt.show()
return allpredata
mymlstmmodel = buildmylstm()
presult = prediction(mymlstmmodel)
def evaluate_model(allpredata):
allmse = mean_squared_error(sell_data[num_steps + 1:], allpredata)
print('ALLMSE:',allmse)
evaluate_model(presult)
7 Summary
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "OpenCV Extension Module Chinese Tutorial" in the background of "Xiaobai Learns Vision" public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of "Xiaobai Learns Vision" public account to download 31 vision practical projects, including image segmentation, mask detection, lane line detection, vehicle counting, adding eyeliner, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV for learning advancement.
Group Chat
Welcome to join the public account reader group to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided later). Please scan the WeChat ID below to join the group, and note: "nickname + school/company + research direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, it will not be approved. After adding successfully, invitations will be sent to relevant WeChat groups based on research direction. Please do not send advertisements in the group, or you will be removed. Thank you for understanding~