
Click the blue text to follow us

Speech Recognition Method Based on Multi-Task Loss with Additional Language Model
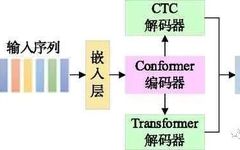
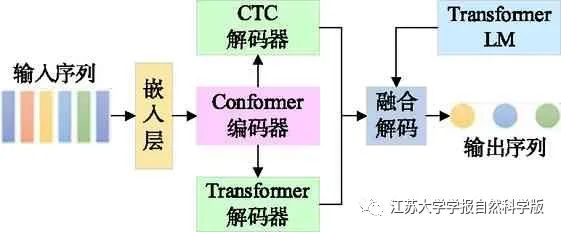
1 Model Structure
2 Determination of Each Module Structure in the Model
2.1 Speech Signal Features and Language Models
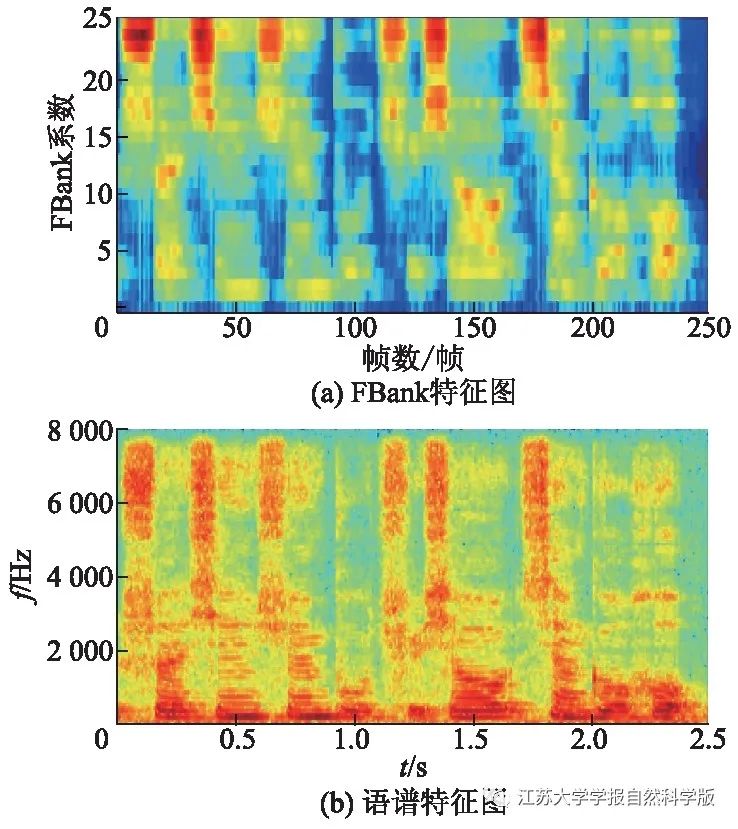
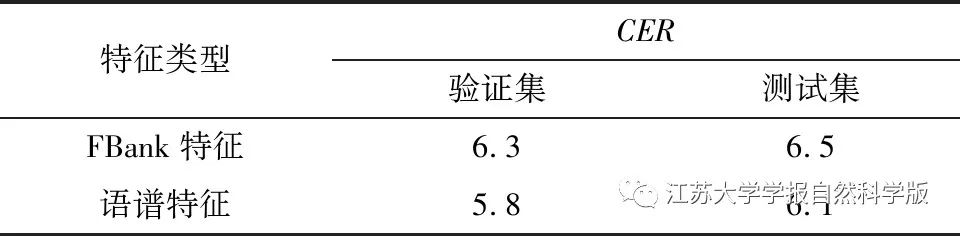

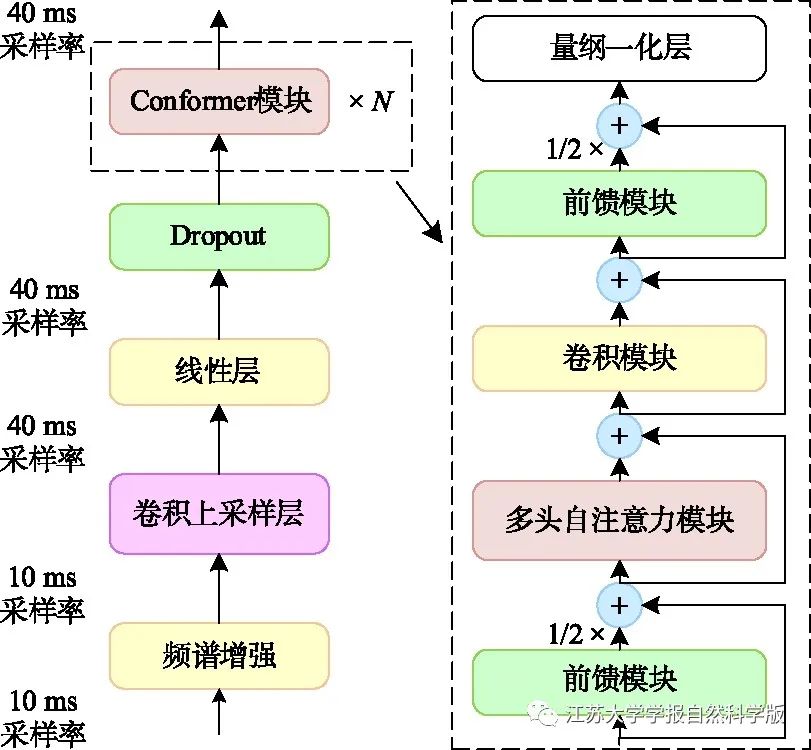
2.2 Conformer Network and Multi-Task Loss
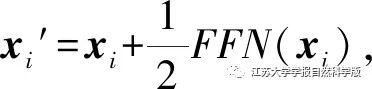
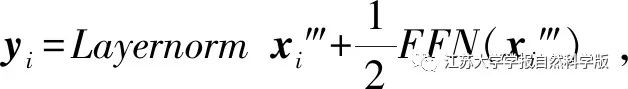
2.3 Re-scoring Mechanism of the Additional Language Model
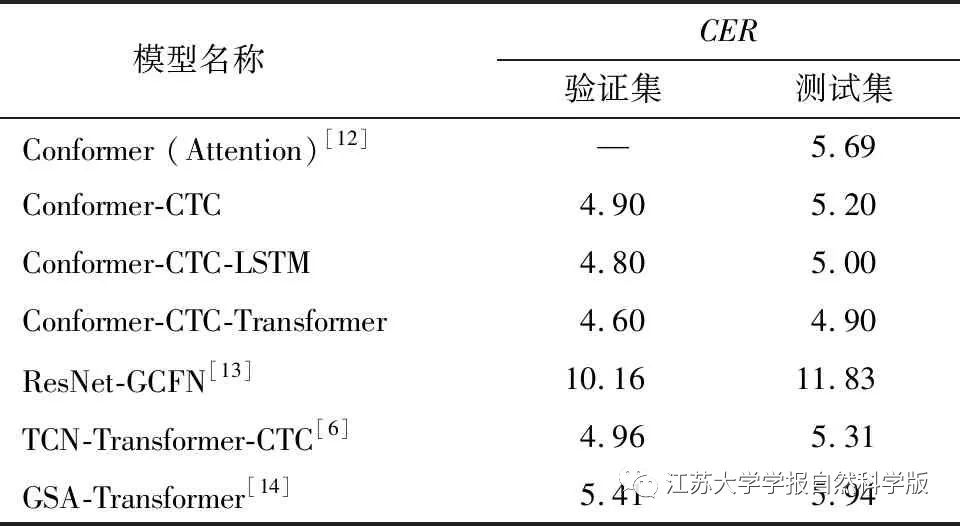
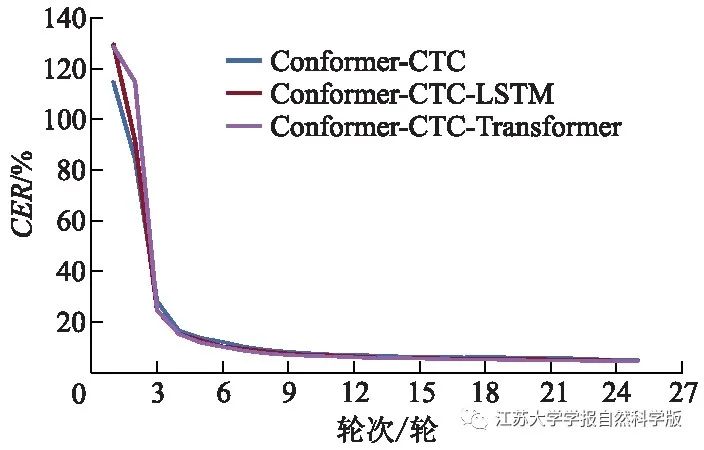
3 Experimental Results and Analysis
3.1 Experimental Data and Basic Configuration
3.2 Experimental Analysis