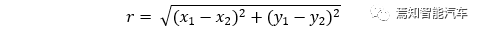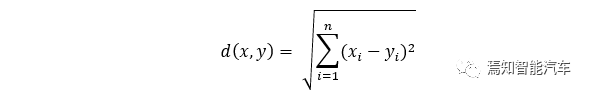Produced by | Yan Zhi
Knowledge Circle | To join the “Domain Controller Group,” please add WeChat 136581676, note domain
Machine learning is familiar to everyone; it is a branch of artificial intelligence (AI) and computer science that mainly uses data and algorithms to mimic human learning processes, gradually improving its accuracy. The rapid development of intelligent driving in recent years has also benefitted from advancements in machine learning, with more and more machine learning algorithms being mass-produced in the automotive industry.
Today we will look at a commonly used algorithm in machine learning—KNN. KNN stands for K-Nearest Neighbors, and it is also referred to as K-Nearest Neighbors in some translations; it is a supervised learning algorithm. This article will start from the core concept, analyze the specific mathematical methods for implementation, and finally conduct a data experiment on network intrusion detection using KNN in Python.
KNN Core Concept
KNN excels at data classification. For example, based on the Doppler speed, azimuth angle, and equivalent radar cross-section characteristics detected by millimeter-wave radar, KNN can classify objects as cars, bicycles, motorcycles, and pedestrians. Similarly, KNN can also be used to predict whether a vehicle being tracked will turn left or right.
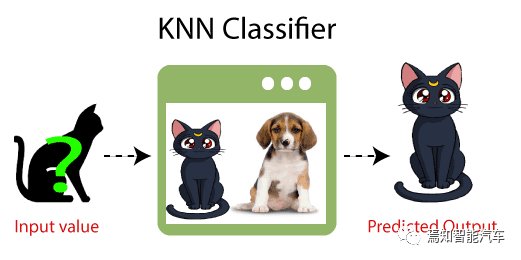
Figure 1: Conceptual Diagram of KNN Classifier
So what is the principle behind KNN? It is quite simple; like many machine learning algorithms, KNN can find analogies from human activities. As the saying goes: “Those close to vermilion turn red, and those close to ink turn black.” To quickly understand a person, one effective method is to observe what kind of friends they have around them. Suppose you have just joined a new company for three months and have a good understanding of your colleagues and whether they can be trusted. Now another colleague who has just returned from an assignment of half a year comes back to the local office; how can you quickly judge if they can be trusted? One method is to observe who the closest K colleagues of this person are—are they mostly trustworthy or untrustworthy?
Similarly, the algorithmic idea of KNN is that when predicting the classification of a new value, it first looks at the K labeled training data points closest to it to see which category they lean towards. This means that the new data point will be assigned a value based on its matching degree with the data points in the training set.
Detailed Explanation of KNN Algorithm
After discussing the abstract concept, let’s take a look at the specific implementation of KNN. The two most critical points in this concretization process are: determining K and determining the distance calculation method.
Determining the value of K is undoubtedly crucial in the KNN model. As the name suggests, KNN is about finding the K nearest neighbors. Similarly, using the example of the colleague returning from assignment mentioned above, if the value of K is too small, only evaluating him based on the one closest person could lead to a biased conclusion. If the value of K is too large, for example, taking the entire company of 1000 people, it loses the concept of “closeness.” The characteristics of these 1000 people become less relevant to him.
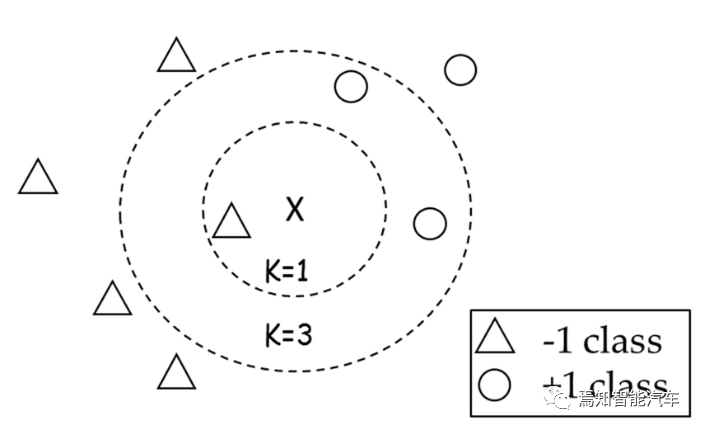
The following diagram intuitively illustrates the impact of the value of K on the KNN classification model. X is the point we need to predict the category for. If K is set to 1, then the nearest neighbor is a triangle, and it will be classified as a triangle. However, if K is set to 3, then among the three nearest neighbors, there are two circles and one triangle, with circles being the majority, so it will be classified as a circle.
Figure 2: K Value in KNN Classification
Another key point of the algorithm is determining the distance calculation method, which means how to measure proximity. As shown in the above diagram, when discussing the value of K, we actually assume the geometric distance between two points as the measure of proximity. In the Cartesian coordinate system, this is:
This corresponds to the X and Y coordinates, which are the two-dimensional feature values of the sample points. If we generalize this to n dimensions, we can define the distance as:
This is the commonly used Euclidean distance in machine learning, also known as the Euclidean distance. Of course, there are many other definitions of distance between data points, such as Manhattan distance and Mahalanobis distance, but these will not be discussed here. The KNN classification algorithm primarily uses Euclidean distance.
To implement the most basic KNN classification algorithm, you only need to confirm the value of K and the distance calculation method as described above. However, in practical applications, there are often areas that can be further optimized for specific problems, with the most common being: adjusting the weight of distance and optimizing the search algorithm. In the KNN function of Sklearn, these two are also important parameters.
Adjusting the distance weight can enhance the influence of nearby neighbors. In the basic KNN classification algorithm, it only finds the K nearest neighbors and then counts the majority class among them to classify. However, this approach sometimes overlooks the concept of “closeness.” As shown in the diagram below, the test data point is X, and K is set to 3. The three nearest points, shown within the dashed circle, are counted directly, and X should be classified as a square. However, among the three nearest neighbors, the distance to the triangle is significantly smaller than that to the square. If distance weights are added during the counting process (i.e., the closer to the test point, the higher the weight), then X might be classified as a triangle. This is akin to a person’s close partner often reflecting more accurately what kind of person they are than a few colleagues.
Figure 3: Distance Weight in KNN Classification
In addition to distance weights, another common optimization point is the search algorithm. KNN essentially calculates the distance between the test point and all training data points, then searches for the N nearest neighbors, which is also the most computationally intensive part. If the training set data volume is large and a brute force search method is used, the overall training efficiency will be low. Fortunately, there are already rich research and available options regarding search algorithms, such as KD Tree and Ball Tree, which are commonly used algorithms to optimize searches in the KNN process. KD Tree is efficient for Euclidean distances, while Ball Tree can be used for high-dimensional distances.
KNN Advantages and Disadvantages in Practical Applications
Having understood the implementation of the KNN algorithm, let’s take a look at its characteristics.
Advantages of KNN Algorithm:
1. Simple implementation. Compared to many other machine learning algorithms that are complex and based on calculus and probability theory, the mathematical principles and specific implementation of KNN are straightforward and can be understood with basic middle school mathematics.
2. Good robustness. KNN is not sensitive to outliers in the training data and has good robustness to significantly noisy data.
3. Good performance on non-linear data, as there are no assumptions about the data in this algorithm, and linear regression is not required.
4. Good prediction performance. If the training data is very large, it can be more effective.
Disadvantages or Limitations of KNN Algorithm:
1. K’s value always needs to be determined, which can be a complex and iterative tuning process.
2. High computational cost. Since it calculates the distance between all training samples, it requires storing all training data during the prediction process, which has high memory requirements.
3. The prediction speed significantly slows down as the training data volume increases.
4. Sensitive to the scale of data and irrelevant features.
Where is KNN used in Practical Engineering Applications?
1. Bank credit rating. KNN can be used in banking systems to predict whether a person is suitable for loan approval, based on whether they share characteristics with defaulters.
2. Voice recognition. With the help of the KNN algorithm, we can classify input voice data and predict the speaker’s intent.
3. Handwriting detection. KNN is also commonly used to recognize handwritten characters, especially Arabic numerals.
4. Vehicle behavior prediction. KNN can predict the next possible action of a vehicle based on the real-time motion data of the preceding vehicle.
5. Network intrusion detection. KNN can determine whether a network is under attack based on network feature data.
Python Example of KNN
There is a function “KNeighborsClassifier” for the KNN classifier in Sklearn, and the official documentation is very detailed. Here, to better understand the KNN algorithm, we will rewrite the code and conduct a data experiment in Python.
As mentioned above, KNN is commonly used for network intrusion detection (IDS). For this data experiment, we will use the NSL-KDD dataset. This is a relatively authoritative intrusion detection dataset in the field of network security, which can detect whether an intrusion has occurred based on network feature data and identify the type of attack. IDS is increasingly being implemented in vehicular networks, and this module has also been added to AUTOSAR Adaptive. The general idea is for the vehicle’s domain controller or computing platform to collect network data features and upload them to the cloud for analysis to detect whether the vehicle’s network has been attacked or intruded.
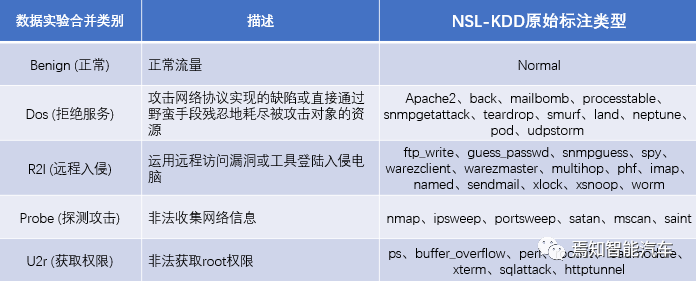
The NSL-KDD dataset classifies many types of attacks, and in this experiment, we will merge them into five major categories, as shown in the following table.
Table 1: Overview of NSL-KDD Dataset
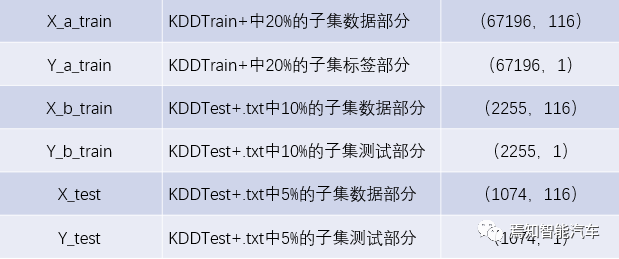
The original NSL-KDD dataset is imbalanced and also contains text features, so preprocessing is necessary, including resampling, one-hot encoding for text features, and normalization, etc. This will not be detailed here. The overview of the preprocessed dataset is shown in Table 2.
Table 2: Overview of Dataset Used in Data Experiment
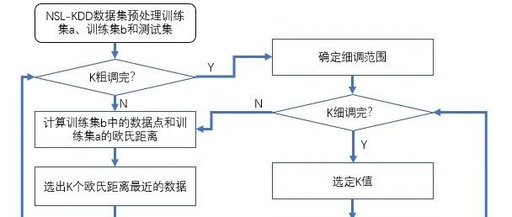
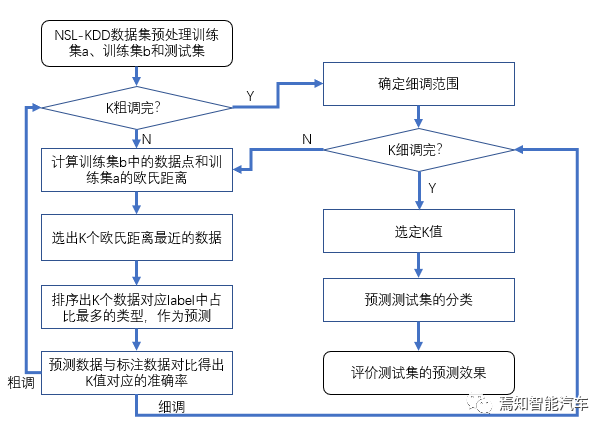
The general process of this data experiment is shown in the following diagram: first, use training sets a and b to roughly and finely tune to determine the value of K, and then predict the test set and evaluate:
Figure 4: Basic Process of Data Experiment
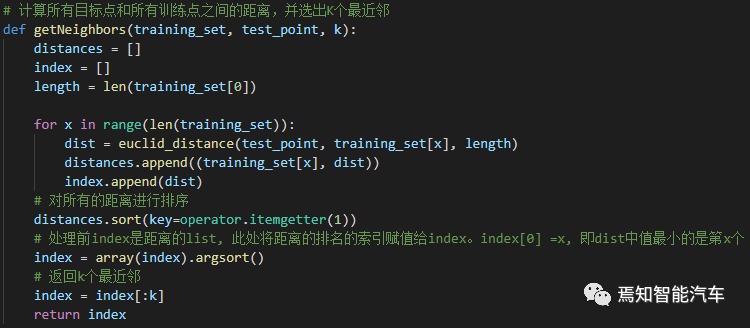
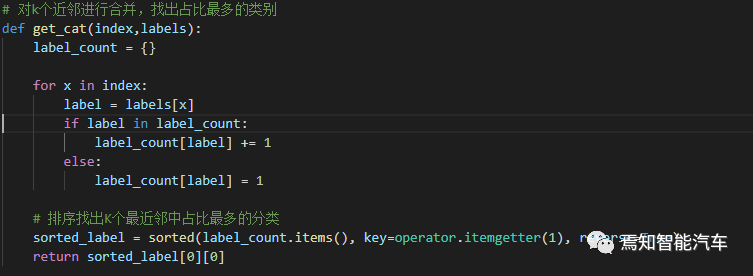
The code to find the K nearest data points based on Euclidean distance is as follows:
Then, the function to find the most common category among the K nearest neighbors:
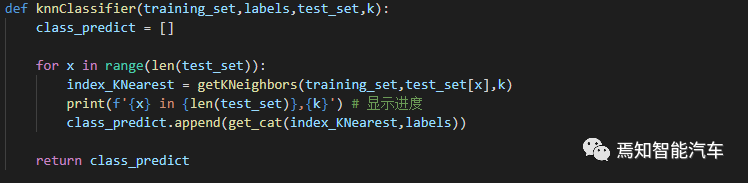
After that, the main function of the KNN classifier:
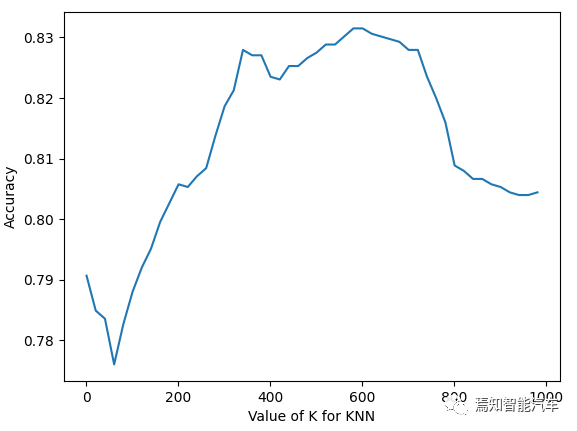
Based on the training data a, let K take values from 1 to 1000 in steps of 20, predict the training data b, and compare the results with the label information of data b to obtain the relationship between K and accuracy as shown in the following diagram.
Figure 5: Relationship Between K Value and Accuracy Under Rough Tuning
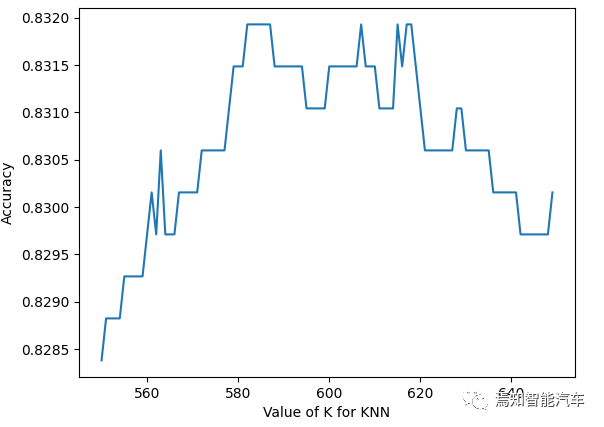
From this, we take values for K in the range of 550 to 650 in steps of 1 to obtain the following relationship between K and accuracy. Thus, we determine the value of K to be 582.
Figure 6: Relationship Between K Value and Accuracy Under Fine Tuning
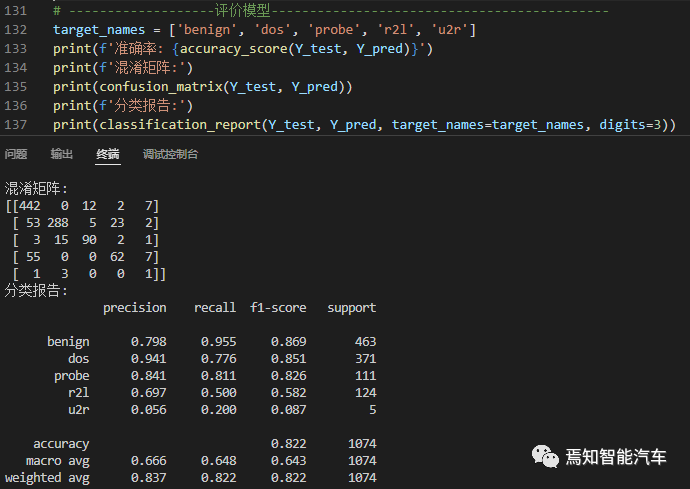
Based on the determined value of K, substitute the data from the test dataset and predict the results. The predicted results are compared with the annotations of the test set to obtain the following model evaluation metrics:
Figure 7: Evaluation of KNN Classifier Model
From the evaluation metrics, it can be seen that there is still room for improvement in overall accuracy, and the accuracy and recall rates for different attack types vary. For example, the goal of a DoS attack is to exhaust resources, and the abnormal data flow is relatively obvious, resulting in higher classification accuracy. In contrast, remote intrusion (R2L) is relatively covert, making classification more challenging. Of course, due to the different classifiers having varying recognition capabilities for different attack types, intrusion detection systems (IDS) are often deployed in the cloud and use multiple models as redundancy checks to improve network information security.
Final Thoughts
This article briefly discusses the principles of KNN and uses KNN’s application in network intrusion detection as an example to complete a data experiment. The rapid development of intelligent vehicles in recent years is underpinned by artificial intelligence. AI is also expected to be further implemented in the automotive industry. Machine learning algorithms such as KNN are believed to be increasingly applied in the automotive industry, whether in single-vehicle intelligence, cloud data processing under vehicle networking, vehicle network information security, or automotive enterprise document management tools, all of which are stages for AI to shine. In this era, learning a bit of AI knowledge may be as important as learning computer skills in the late 1990s. Let us encourage each other with this thought.
1. https://www.javatpoint.com/k-nearest-neighbor-algorithm-for-machine-learning
2. https://www.researchgate.net/figure/Illustration-example-of-KNN-algorithm_fig1_282448172
3. https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_knn_algorithm_finding_nearest_neighbors.htm
4. NSL-KDD | Datasets | Research | Canadian Institute for Cybersecurity | UNB