

Ali Sister’s Guide: BERT, a landmark in the field of natural language processing, did not appear out of nowhere; it has its development principles behind it. Today, the Ant Financial Wealth Dialogue Algorithm Team has organized and compared the development history of deep learning models in the field of natural language processing. From simple neurons to the currently most complex BERT model, this article provides an in-depth yet accessible introduction to the progress of deep learning in the NLP field, and outlines future application directions for NLP in conjunction with industry. By reading this article, you will gain a deeper understanding of the overall context of deep learning.
A neural network structure typically consists of an input layer, hidden layers, and an output layer. The input layer represents our features, while the output layer represents our predictions. The goal of a neural network is to fit a function f*: features -> prediction. During training, network parameters are adjusted to minimize the difference between the prediction and the actual label, allowing the current network to approximate the ideal function f*.
Neuron
The basic component of a neural network layer is the neuron, which consists of two parts: a linear product of the outputs from the previous layer and the parameters of the current layer, and a nonlinear transformation of that linear product. (Without the nonlinear transformation, multiple layers of linear products can be reduced to a single layer of linear products.)
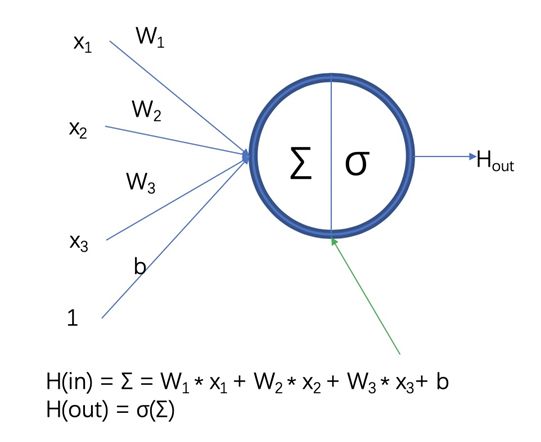
Figure 1
Shallow Neural Network
A network with only one hidden layer is referred to as a shallow network.
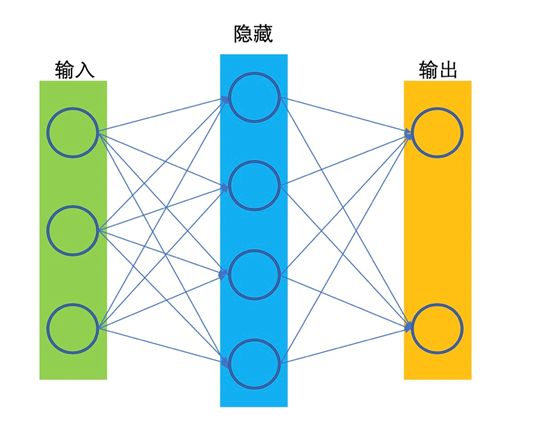
Figure 2
Deep Learning Network (Multilayer Perceptron)
In contrast to shallow networks, those with two, three, or more hidden layers are referred to as deep networks.
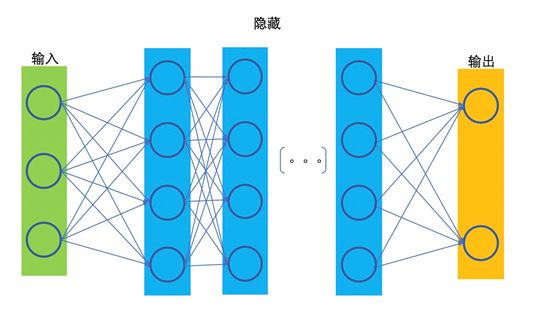
Figure 3
In general understanding, a sufficiently wide network can fit any function. A deep network, on the other hand, can fit this function with fewer parameters because deep neurons can capture more complex feature representations than shallow neurons.
In the networks shown in Figures 2 and 3, we refer to them as fully connected networks, where the neurons in the hidden layer are connected to all the outputs of the previous layer. In contrast, there are networks that connect only to part of the neurons’ outputs from the previous layer, such as convolutional networks described below.
Convolutional Networks (CNN)
Convolutional network neurons are connected only to part of the neurons’ outputs from the previous layer. (Intuitively, this is because human visual neurons are sensitive only to local information rather than all global information having an equivalent effect on the same synapse.)
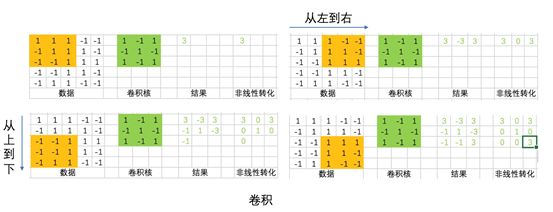
The same convolution kernel performs a product operation from left to right and top to bottom with the input, yielding outputs of varying strengths. Intuitively, the sensitivity of the convolution kernel to different data distributions in the original data is not uniform. If we understand the convolution kernel as a certain pattern, data distributions that conform to this pattern will yield stronger outputs, while those that do not conform will yield weak outputs or even no output at all.
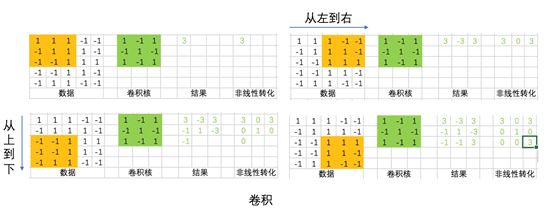
A convolution kernel is a pattern extractor, and multiple convolution kernels constitute multiple pattern extractors. By applying multiple feature extractors to the original data, we form a convolutional layer.
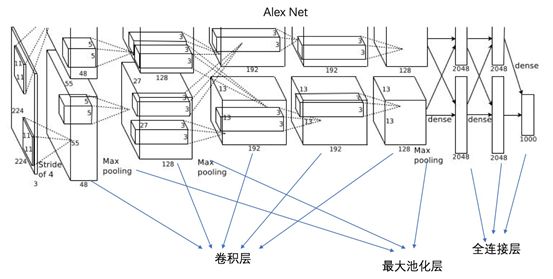
AlexNet, due to GPU memory limitations, used two GPUs to split the model. Essentially, the convolutional layer is used for feature extraction, the max pooling layer is used to extract strong features and reduce parameters, and the fully connected layer incorporates all high-level features into the final classification decision.
Recurrent Neural Networks (RNN)
CNN is used for spatial feature extraction, while RNN is used for temporal feature extraction.
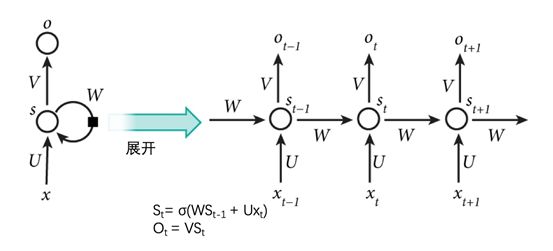
In RNN, x1, x2, x3, xt are different inputs over time, while matrices V, U, W are shared. Meanwhile, the RNN network maintains its own state S. S changes with the input; different inputs or inputs at different times influence the state S of the RNN network to varying degrees. The state S of the RNN network determines the final output.
Intuitively, we understand that an RNN network is a neural network (action) capable of simulating any function, combined with a history storage (memory). The combination of action and memory makes RNN a Turing machine.
Long Short-Term Memory Networks (LSTM)
The problem with RNN is the presence of nonlinear operations σ, and the propagation through multiplication between steps can lead to long sequence historical information not being effectively conveyed to the end, which is addressed by LSTM networks.
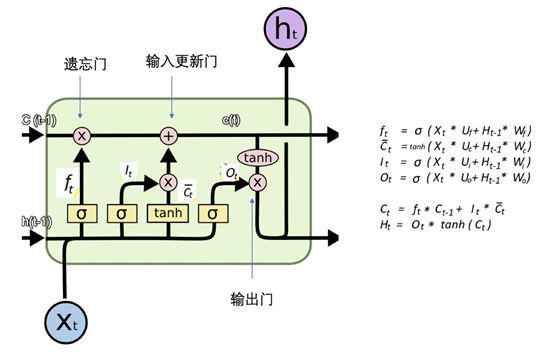
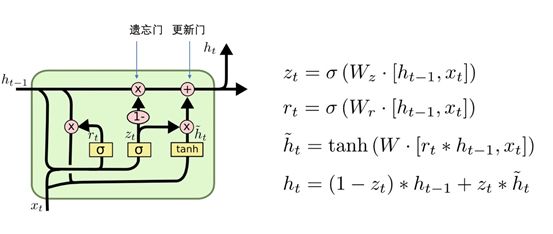
In the LSTM cell, there are typically a forget gate (pointwise multiplication, determining what to remove from the state), an input update gate (elementwise addition, determining what to add to the state), and an output gate (pointwise multiplication, determining what the output of the state is). Although it seems complex, it is essentially a matrix operation.
To simplify calculations, there are later variants of LSTM called GRU, as shown in the following figure:
Text Convolutional Networks (TextCNN)
CNN is widely used in computer vision, with a strong ability to capture local features, providing great help to researchers analyzing and utilizing image data. TextCNN, proposed by Kim in 2014 at EMNLP, applies CNN to the task of text classification in NLP.
Intuitively, TextCNN obtains n-gram feature representations in sentences through one-dimensional convolution. TextCNN is very effective at extracting shallow features from text, performing well in short text scenarios such as search and dialogue, focusing on intent classification, making it widely used and fast, generally being the first choice; for long text, TextCNN primarily relies on filter windows to extract features, which limits its ability in long-distance modeling and is insensitive to word order.
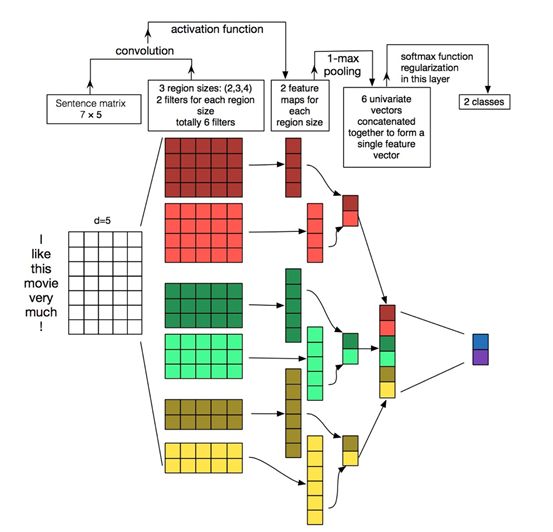
Convolution Kernel (filter) → n-gram Features
The difference between text convolution and image convolution lies in performing convolution only in one direction of the text sequence. Convolution operations are performed on every possible window of words in the sentence to obtain feature maps.
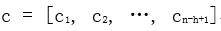
Among them, 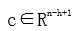 . Performing max-pooling operations on the feature map, taking the maximum value max{c} as the extracted feature from the filter. By selecting the maximum value from each feature map, we can capture its most important features.
. Performing max-pooling operations on the feature map, taking the maximum value max{c} as the extracted feature from the filter. By selecting the maximum value from each feature map, we can capture its most important features.
Each filter convolution kernel produces a feature, and a TextCNN network comprises many convolution kernels of different window sizes, such as commonly used filter sizes ∈{3,4,5} with each filter’s feature maps=100.
Enhanced Sequential Inference Model (ESIM)
ESIM (Enhanced Sequential Inference Model) is a commonly used and powerful model for short text matching tasks. Its enhancement over LSTM mainly lies in: outputting new representations from the input of two LSTM layers (Encoding Layer) through a sequential inference interaction model.
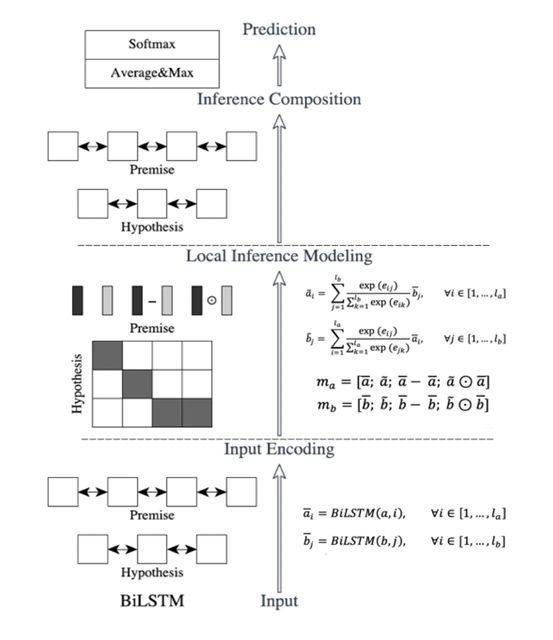
Image source: paper “Enhanced LSTM for Natural Language Inference”
As shown in the figure, ESIM is the left part of the diagram. The overall network structure is quite clear, and the entire pathway roughly includes three steps.
Step 1: Encoding Layer. In this step, each token is processed through a pre-trained encoding using the Bi-LSTM layer to obtain a “new encoding” aimed at learning the contextual information of each token through LSTM.
Step 2: Local Inference Layer. Step two is essentially a calculation process of intra-sentence attention. By performing intra-sentence attention operations on the results obtained from the two sentences in step one, we can derive a new vector representation here. Next, we calculate the changes in the vector before and after the attention operation, aiming to further extract local inference information and capture some inference relationships, such as sequential relationships.
Step 3: Combined Inference & Prediction Layer. The extracted results are then processed again through Bi-LSTM, and average & max pooling is performed (the specific operation involves performing average and max pooling separately and concatenating the results), followed by a fully connected layer for Softmax prediction of probabilities.
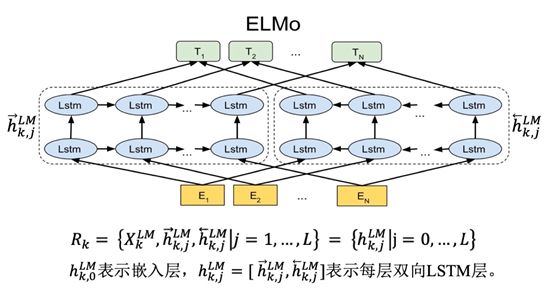
ELMo
Intuitively, ELMo (Embedding from Language Model) addresses the issue of polysemy. For example, when asking for the word vector of “apple”, ELMo considers the context in which “apple” appears, so we should inquire about the word vector for “apple” in the context of “apple stock price”. ELMo provides dynamic representations at the word level, carrying contextual information, effectively capturing contextual information. The introduction of ELMo has had a good guiding and inspirational effect on later models such as GPT and BERT. A good word vector should meet two characteristics:
-
It can reflect complex semantic and syntactic features.
-
It can accurately produce appropriate semantics for different contexts.
Traditional word2vec provides a fixed embedding representation for each word, which cannot generate embeddings carrying contextual information and cannot judge polysemy based on context. Each word in ELMo must first be combined with context through a multi-layer LSTM network to obtain the final representation. Since LSTM is designed to capture contextual information, ELMo can combine more contextual information, outperforming word2vec in handling polysemy.
The network structure diagram during ELMo pre-training is somewhat similar to traditional language models, intuitively understood as replacing the nonlinear layers in the middle with LSTM, allowing the LSTM network to better extract contextual information for each word in the current context while adding both forward and backward contextual information.
Pre-training
Given a sequence containing N words, the forward language model predicts the k-th word based on the previous k-1 words. At position k, each LSTM layer outputs a context-dependent vector representation.
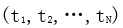 , j=1,2,…,L. The output of the top LSTM layer is used to predict the next position using cross-entropy loss.
, j=1,2,…,L. The output of the top LSTM layer is used to predict the next position using cross-entropy loss.
 .
.
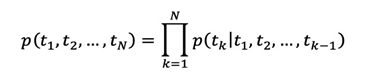
The backward language model reverses the sequence and uses subsequent information to predict preceding words. Similar to the forward model, given 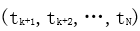 , the output of the j-th layer is obtained through a backward deep LSTM network.
, the output of the j-th layer is obtained through a backward deep LSTM network.
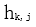
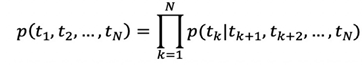
The bidirectional language model combines the forward and backward language models, constructing a joint maximum likelihood estimation for the forward and backward models.
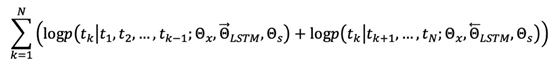
Among them, 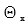 are the parameters for the sequence word vector layer,
are the parameters for the sequence word vector layer, 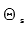 are the parameters for the cross-entropy layer, which share these two parts of parameters during training.
are the parameters for the cross-entropy layer, which share these two parts of parameters during training.
The embedded language model combines the internal information of multiple layers of LSTM to compute 2L+1 sets of representations for the center word using a bidirectional language model of L layers.
Fine-tune
In downstream tasks, ELMo integrates the outputs of multiple layers into one vector, adding the outputs of all LSTM layers with the normalized weights learned from softmax s=Softmax(w), as shown below:
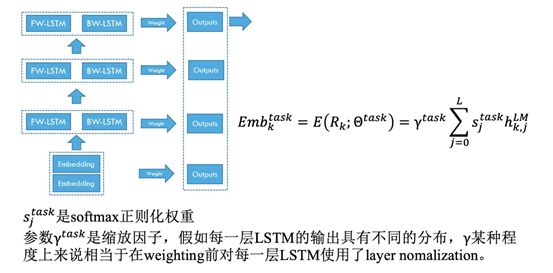
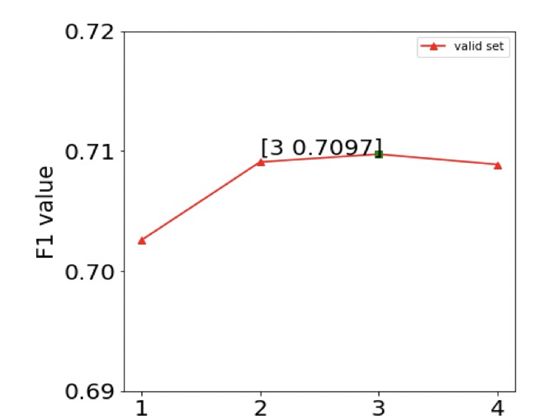
Intuitively, the higher-level LSTM vectors in biLMs capture the semantic information of vocabulary, while the lower-level LSTM vectors capture the syntactic information of vocabulary. This hierarchical effect brought by deep models makes it possible to apply a set of word vectors to different tasks, as the amount of information required for each task varies. Additionally, the number of LSTM layers should not be too high, as multi-layer LSTM networks are not easy to train well and have overfitting issues. The following figure shows the experimental results of a multi-layer LSTM applied to text classification problems, where the model’s performance increases and then decreases as the number of LSTM layers increases.
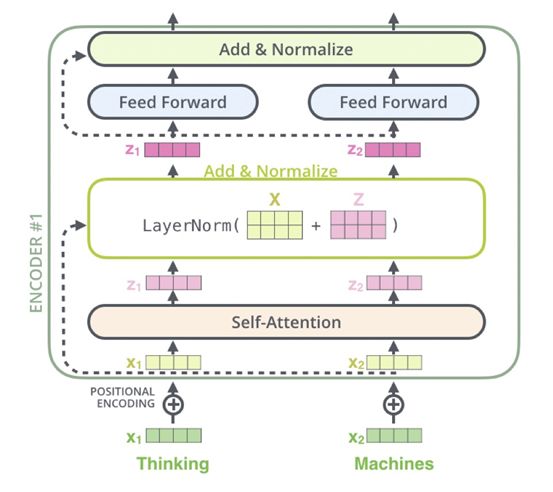
Transformer
It has been said that to improve LSTM performance, one just needs to add attention. However, now attention is all you need. Transformer addresses the training issues of deep networks in the NLP field.
Attention has previously been used in many NLP tasks to locate key tokens or features, such as adding a layer of Attention at the end of text classification to enhance performance. Transformer originated from the attention mechanism and completely discards traditional RNNs; the entire network structure is entirely composed of the Attention mechanism. Transformer can be constructed by stacking Transformer Layers, with the author’s experiments building a total of 12 layers of Encoder-Decoder, each with 6 layers, achieving a new high in BLEU values in machine translation.
The visualization of the entire process is as follows: with N=2 as an example, while the actual Transformer has N=6.
Encoder Phase: Input “Thinking Machines” corresponds to the word vectors, added with positional vectors Positional Encoding; self-attention is performed for each position; Add & Norm are done in two steps, with residual connection and layer normalization yielding a new output for each position, followed by feed-forward fully connected layers and Add & Norm, resulting in the output of an Encoder Layer, which is repeated twice, finally outputting to the Decoder’s Encoder-Decoder Layer.
Decoder Phase: First, the input to the Decoder undergoes a Masked Self-Attention Layer, followed by performing Encoder-Decoder Attention with the output from the Encoder phase and the first output of the Decoder, and finally connecting to a fully connected layer + Softmax to output the word with the highest probability at the current position.
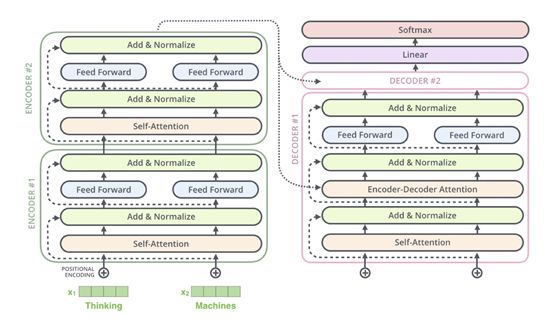
The structure of Transformer is relatively easy to understand, but it contains many details, such as Multi-Head Attention, Feed Forward, Layer Norm, Positional Encoding, etc.
The advantages of Transformer are:
-
Parallel computing improves training speed. This is a significant breakthrough compared to LSTM, where the computation at the current step depends on the previous hidden state, making it a continuous process; each computation must wait for the previous one to complete before proceeding, limiting the model’s parallel capability. In contrast, Transformer does not use the LSTM structure; each step of the Attention mechanism only depends on the output of the previous layer and does not rely on the information of the previous word, allowing parallel computation during training, thus improving training speed.
-
One-step global relationship capture. Information is lost during sequential computation; although LSTM’s gating mechanisms alleviate long-term dependency issues to some extent, they are still powerless against particularly long-term dependencies. Transformer uses the Attention mechanism, effectively reducing the distance between any two positions in the sequence to 1, which is very effective in addressing the challenging long-term dependency issues in NLP.
Summary Comparison of CNN, RNN, and Self-Attention:
CNN: Can only see local areas, suitable for images, as abstracting higher-level information in images only requires the local regions of the next layer’s features; in text, it excels at extracting local features, making it more suitable for short texts.
RNN: Theoretically can see all history, suitable for text, but suffers from gradient vanishing issues.
Self-Attention: Compared to RNN, it does not suffer from gradient vanishing issues. Compared to CNN, it is more suitable for long texts because it can see information over greater distances; while CNN needs many layers to achieve abstraction, Self-Attention can accomplish this at a very low level, which is undoubtedly a significant advantage.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is essentially the most foundational language model in the NLP field, pre-trained on massive corpora to obtain the most comprehensive local and global feature representations for sequences.
The BERT network structure is as follows; BERT’s Encoder network structure is identical to that of the Transformer. Assuming the dimension of the embedding vector is n and the input sequence contains n tokens, the input to one layer of the BERT model is a matrix of size n, and its output is also a matrix of size n, allowing N layers of BERT to be easily concatenated. The BERT large model uses N=24 layers of such Transformer blocks.
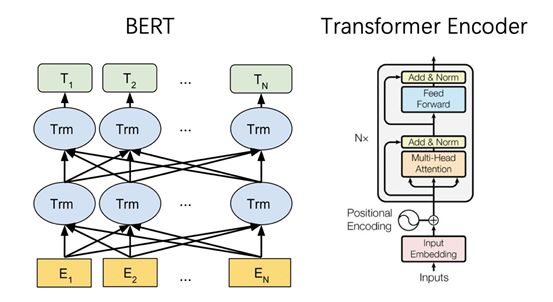
Objective Function
★ 1. Masked Language Model, MLM
MLM is designed to train deep bidirectional language representation vectors. BERT employs a very direct method: it masks certain words in the sentence, allowing the encoder to predict what those words are. The specific operation process is illustrated in the following example: first, a small probability is used to mask some characters, and then the language model predicts these characters based on the context.

BERT’s specific training method involves randomly masking 15% of the words as training samples.
-
Among them, 80% are replaced with masked tokens.
-
10% are replaced with a random word.
-
10% remain unchanged.
Intuitively, the reason only 15% of the words are masked is due to performance overhead; training a bidirectional encoder is slower than a unidirectional encoder. Masking 80% and keeping 20% of specific words during pre-training and not masking the input sequences during specific task fine-tuning, such as classification tasks, would create a gap, leading to task inconsistency; the 10% replacement with random words and 10% maintaining the original words forces the encoder to learn the representation vectors for each token, resulting in a compromise.

★ 2. Next Sentence Prediction
Pre-training a binary classification model to learn the relationships between sentences. The method of predicting the next sentence is very helpful for learning the relationships between sentences.
Training method: The ratio of positive to negative samples is 1:1, with 50% of the sentences being positive samples, meaning that given sentence A and B, B is the actual next sentence of A; negative samples are sentences randomly selected from the corpus to serve as B. Two specific tokens, [CLS] and [SEP], are used to connect the two sentences, and the prediction is output at the [CLS] position.

Input Representation
Input: The first token [CLS] of each input sequence is specifically used for classification, directly utilizing the last output at this position as the input embedding for classification tasks.
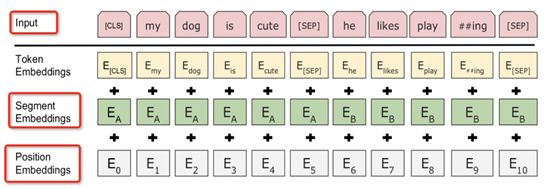
Intuitively, during pre-training, [CLS] does not participate in masking, thus this position’s output makes attention to all positions in the sequence, allowing the output at [CLS] to adequately express the information of the entire sentence, similar to a global feature; while the embedding corresponding to word tokens focuses more on the semantic and syntactic expressions of that token, similar to a local feature.
Position Embeddings: The PositionEncoding of the transformer is constructed directly using sin and cos, while PositionEmbeddings are embedding vectors learned by the model, supporting up to 512 dimensions.
Segment Embeddings: In pre-training tasks of sentence pairs and tasks such as question-answering and similarity matching, it is necessary to distinguish between the preceding and following sentences. The sentence pairs are input as the same sequence, separated by a special token [SEP]. Each token in the first sentence is added with Sentence A Embedding, while the second sentence is added with Sentence B Embedding. In experiments, EA =1 and EB =0.
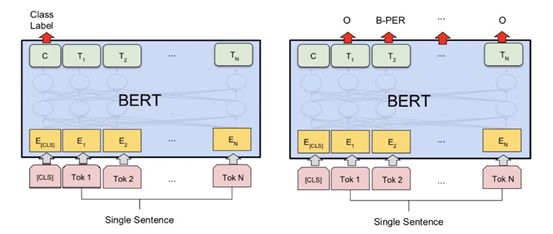
Fine-tune
For different tasks, BERT uses different parts of the output for predictions; for classification tasks, it utilizes the embedding at the [CLS] position, while for NER tasks, it utilizes the output embedding of each token.
BERT’s Main Contributions Include:
The Effectiveness of Pre-training: In this regard, BERT has changed the game, as the experimental results of BERT language representation pre-trained on massive unsupervised data combined with a simple network model fine-tuned with a small amount of training data have shown significant advantages over complex and cleverly designed network structures.
Network Depth: Based on DNN language models (NNLM, CBOW, etc.), obtaining word vector representations has achieved great success in the NLP field, while the BERT pre-training network based on the Transformer’s Encoder can be made very deep.
Bidirectional Language Model: Prior to BERT, the main limitations of ELMo and GPT were that standard language models were unidirectional; GPT used the Decoder structure of Transformer, considering only the preceding context. ELMo’s left-to-right and right-to-left language models were independently trained, sharing embeddings, and concatenating LSTMs from both directions did not truly represent context; they remained fundamentally unidirectional, and multi-layer LSTMs are difficult to train.
Objective Function: In comparison to language model tasks that only predict the next word, training a language model that contains more information requires completing more complex tasks. BERT primarily addresses the tasks of masked language modeling and sentence pair prediction, which involve two losses: one for Masked Language Model and another for Next Sentence Prediction.
Summary
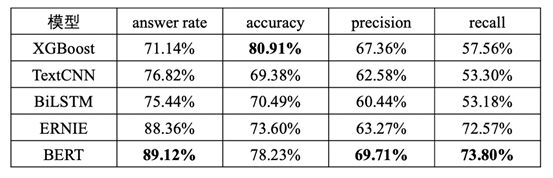
We have practiced the mainstream models mentioned above in NLU intent classification tasks, including Xgboost, TextCNN, LSTM, BERT, and ERNIE, among others. Below is a comparison experiment conducted during the early model research phase on the selected test data, where the BERT model demonstrated significant advantages.
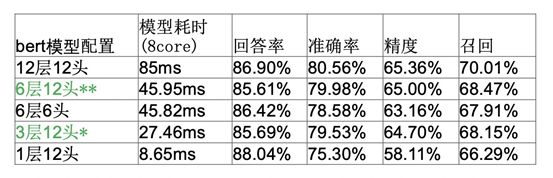
Meanwhile, during our deployment process, we tested the time consumption of BERT, providing the test results for reference. Regarding our question-answering queries:
(1) The number of BERT layers is linearly related to time consumption, and increasing the number of attention heads has a minimal effect on time consumption;
(2) For short text query intent understanding, it relies more on shallow syntactic and semantic features, thus the number of BERT layers has a minor impact on model precision and recall;
(3) The number of attention heads determines how many angles the query can be understood from; in our experiments, reducing the number of heads had a slightly larger impact on precision and recall than reducing the number of layers, while time consumption showed no significant reduction.
In the field of images, AlexNet opened the door to deep learning, while ResNet is a landmark in deep learning for images.
With the rise of Transformer and BERT, networks are also evolving towards 12-layer and 24-layer architectures, achieving state-of-the-art results. BERT has proven that in the NLP field, deep networks outperform shallow networks.
In the field of natural language, Transformer has opened the door to deep networks, and BERT has also become a landmark in the field of natural language processing.
About Us
We are the Ant Financial Wealth Dialogue Algorithm Team, dedicated to using the latest algorithms to create the best models, developing smarter dialogue systems, and capturing the gem of AI. We welcome discussions and sharing. The team is currently actively recruiting algorithm experts in NLP, recommendation, and user profiling (P6-P9), and please contact:
References:
Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
Hochreiter S, Schmidhuber J. LSTM can solve hard long time lag problems[C]//Advances in neural information processing systems. 1997: 473-479.
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
Chen Q, Zhu X, Ling Z, et al. Enhanced LSTM for natural language inference[J]. arXiv preprint arXiv:1609.06038, 2016.
Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.

You May Also Like
Click the image below to read

Jia Yangqing: My Insights on Artificial Intelligence

How to Ace Technical Interviews? Alibaba Experts Recommend 8 Essential Books

After Five Years as a Technical Supervisor at Alibaba, I Have Something to Say

Follow “Alibaba Technology”
Stay Ahead of Cutting-edge Technologies