Click the above “Beginner’s Guide to Vision“, select to add “Starred” or “Pinned“
Important content delivered promptly
This article is reprinted from: OpenCV Academy
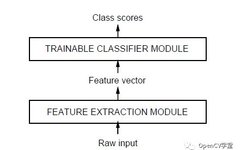
Traditional pattern recognition neural network (NN) algorithms are based on gradient descent and learn to recognize and classify different target samples based on a large number of sample feature data from inputs. These traditional pattern recognition methods include KNN, SVM, NN, etc. They have an unavoidable problem: they must manually design algorithms to implement feature extraction from input images, considering various invariance issues in the feature extraction process. The most common invariances to consider are rotation invariance, illumination invariance, and scale invariance. Rotation invariance can be achieved by calculating image gradients and angles, illumination effects can be avoided through normalization, and scale invariance can be constructed by building a scale pyramid. Among these, SIFT and SURF are typical representatives of such features. Additionally, contour-based HOG features, LBP features, etc., can also be used. The feature data is then used as input to select suitable machine learning methods such as KNN, SVM, etc., to achieve classification or recognition. The biggest drawback of these methods is that the feature extraction design process completely relies on humans, with too many human factors involved, failing to leverage the machine’s ability to actively learn and extract features. The advantage is that humans can fully control every detail of feature extraction and every feature data. The illustration is as follows:
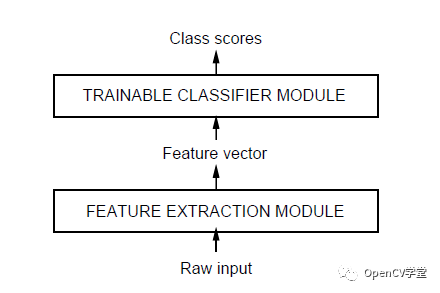
Deep learning methods represented by Convolutional Neural Networks (CNN) achieve object recognition and classification by completely handing over feature extraction to machines, eliminating the need for manual design in the entire feature extraction process, which is fully automated by machines. Feature extraction is achieved through convolution with different filters, allowing for a certain degree of invariance to distortion and illumination. Max pooling layers sample to achieve scale invariance while maintaining the three invariances of traditional feature data and minimizing manual design details in the feature extraction method. Through supervised learning, the computer’s computational capabilities are utilized to actively search for suitable feature data. This completes the transition from a traditional white-box mechanism for feature extraction algorithms to a machine-led black-box mechanism, optimizing the recognition and classification results. The earliest convolutional neural network model appeared in 1998, primarily used for OCR (Optical Character Recognition), named the LeNet-5 network, whose structure is as follows:
-
Input Layer represents the input data (image)
-
Convolution Layer extracts features using a 5×5 convolution kernel, followed by 2x max pooling for downsampling. The above image has two convolution layers.
-
Fully Connected Layer, the multi-layer perceptron (MLP) of traditional neural networks. The above image has two fully connected layers.
-
Output Layer
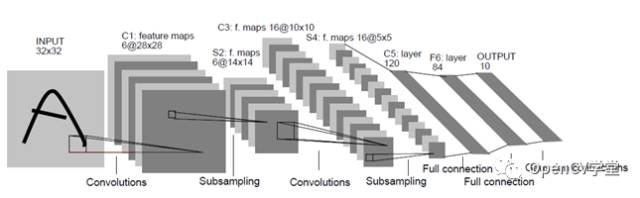
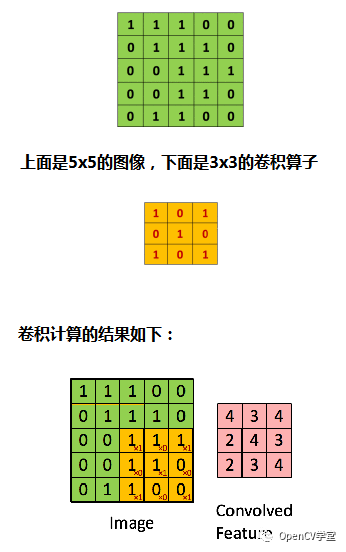
First, we need to understand the concept of image convolution. Convolution is a mathematical operation, which can be simply explained as shown in the figure below:
For the convolution layer of a convolutional neural network, we generally define the input image as wxh pixels in width and height, and define K mxn convolution kernels. For each convolution kernel, the input image is convolved with it to generate k(w-m+1)(h-n+1) convolution images. After downsampling, we obtain DMN (M=(w-m+1)/2, N=(h-n+1)/2), where D represents the depth, i.e., the number of feature maps. After the first layer of convolution pooling, when continuing to perform convolution operations, we must consider the depth of the image, completing three-dimensional convolution in the depth direction, as illustrated below:
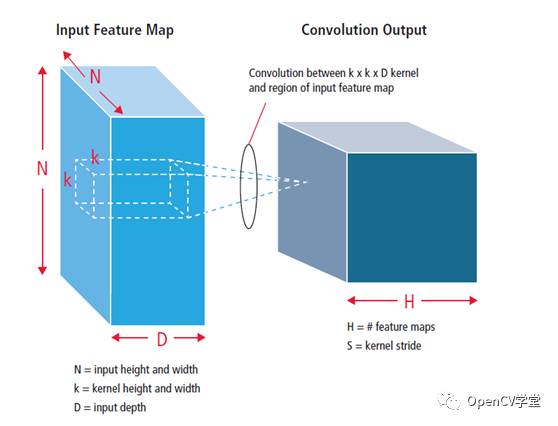
This results in the second layer of convolution. If needed, a third layer of convolution can be performed up to N layers of convolution operations. After each convolution layer operation is completed, some additional data processing, such as ReLU, is also required. The mathematical representation and curve of ReLU are as follows:
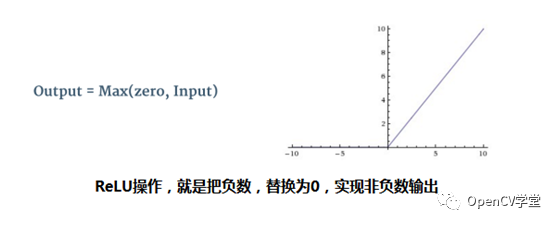
Comparing the Feature Map outputs before and after the ReLU operation:

The fully connected layer is the multi-layer perceptron (MLP) of traditional neural networks, which connects all neurons of this layer to every neuron of the next layer through activation functions to achieve the final output layer. The traditional MLP network structure is as follows:
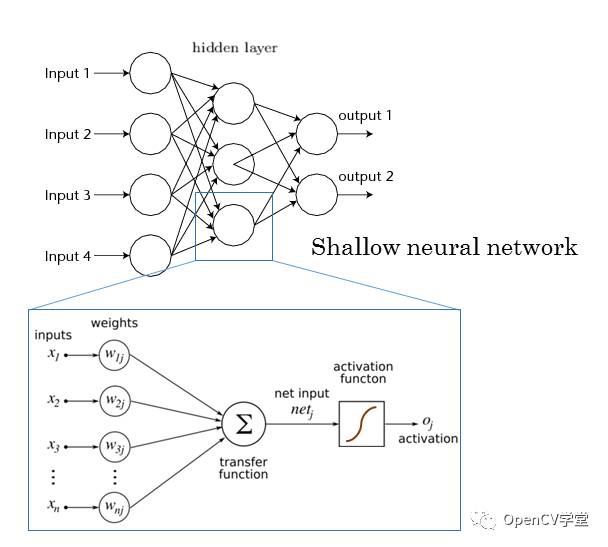
Compared to traditional feature extraction and pattern recognition methods, convolutional neural networks have several advantages:
-
Training is relatively easy, with no complex feature extraction process, which lowers the learning threshold for image recognition, allowing more data-savvy individuals to find shortcuts to learning image processing and computer vision.
-
The convolution layer reduces the number of parameters compared to traditional neural networks by sharing weight parameters, lowering memory requirements.
-
Maintains stability against image distortion, deformation, and pixel migration, exhibiting certain invariant characteristics.
Community Group
Welcome to join the public account reader group to communicate with peers. We currently have WeChat groups for SLAM, 3D Vision, Sensors, Autonomous Driving, Computational Photography, Detection, Segmentation, Recognition, Medical Imaging, GAN, Algorithm Competitions, etc. (which will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format for notes, otherwise, you will not be approved. After successful addition, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for your understanding~

