
Click on the above “Beginner’s Visual Learning” and choose to add a Star or “Pin”
Heavyweight content delivered at the first time
First, we know that a monocular camera cannot recover the absolute scale, but if we have prior knowledge of the actual scene, this problem can be partially solved, which is most evident in autonomous driving scenarios. The simplified principle is shown in the figure below:
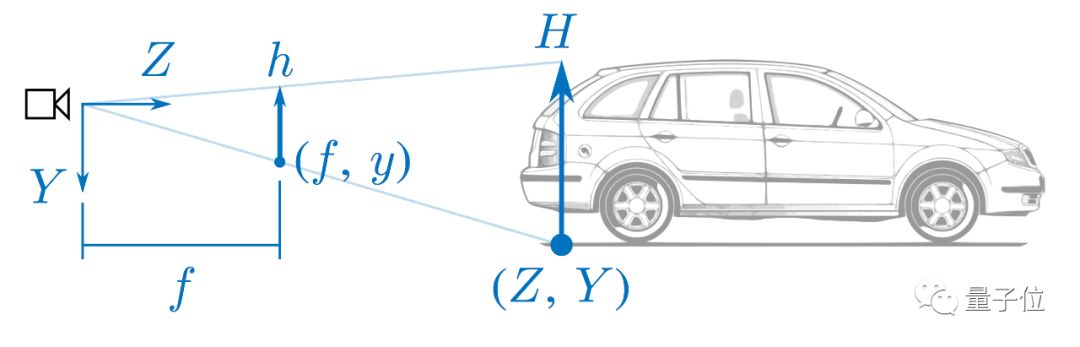
In the above figure, some simplifications are made to the actual scene. All uppercase letters represent actual coordinates in the 3D world, while lowercase letters represent pixel coordinates on the camera imaging plane. f is the actual focal length of the camera, assumed to be known through calibration.
We can actually find two similar triangles related to Z in the figure to recover the actual scale:
The first is h/H = f/Z, rearranging gives Z=Hf/h.
From the above formula, we can see that we need to know the actual width (or height) of the vehicle in the real world, and then we can calculate the actual distance of the object based on its pixel height in the image. Intuitively, objects should appear larger when close and smaller when far away.
The second is y/Y = f/Z, similarly giving Z=Yf/y.
In this method, we need to know the camera’s installation height from the ground and the vertical coordinate of the contact point of the wheels with the ground in the image. Intuitively, if we are on a straight road, the closer an object is to us, the lower its vertical coordinate should be in the image, while the farther an object is, the higher its vertical coordinate should be.
So what kind of cues do these CNN depth estimation methods rely on? The first part of the article studies this issue. The author used a fake car by changing its size and position to fit onto a real image to validate various hypotheses.
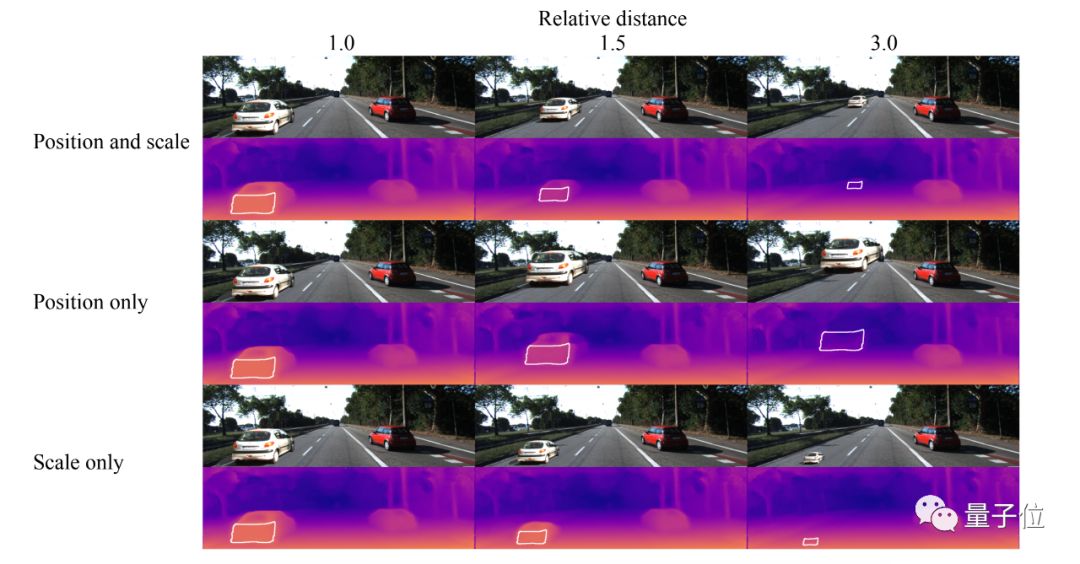
In the first row, the height and size are changed simultaneously according to normal logic, and the overall prediction is reasonable.
In the second row, only the vertical position was changed during the placement of the texture, without scaling the object’s size; it can be seen that as the vertical coordinate changes, the object’s distance also changes accordingly.
However, in the third row, keeping the object’s vertical coordinate constant while only scaling the size, the output of the entire neural network remains quite consistent without drastic changes. (Just pay attention to the results within the white box in the prediction, which is the distance of the car’s rear.) Below is a quantitative result:

It can be seen that scale only completely loses the ability to predict, but the other two methods still show correct trends.
Therefore, the first conclusion of this article is that CNN estimates the distance of objects based on their vertical coordinates in the image, not based on the object’s width and height.
This conclusion is quite counterintuitive, and I share some personal thoughts at the end of the article.
In the second part, the author explores the impact of camera pose on CNN depth estimation algorithms. Theoretically, a robust algorithm should be invariant to changes in camera pose. However, this is not the case in practice. The author analyzes the disturbances of pitch and roll angles separately.
First, for pitch, the author can determine the position of the horizon using a robust fitting method based on the predicted depth map, which will not be elaborated here. The author then simulates changes in the camera’s pitch angle using center cropping. The first point is that the depth map predicted by CNN can partially reflect changes in the position of the horizon, but there is still a gap compared to the ideal situation. The second point is that based on the previous analysis that CNN calculates depth based on the vertical coordinates of the contact points of objects, it is not surprising that under this center crop setting, the depth varies completely with the position of the crop, even though the scene itself has not changed.
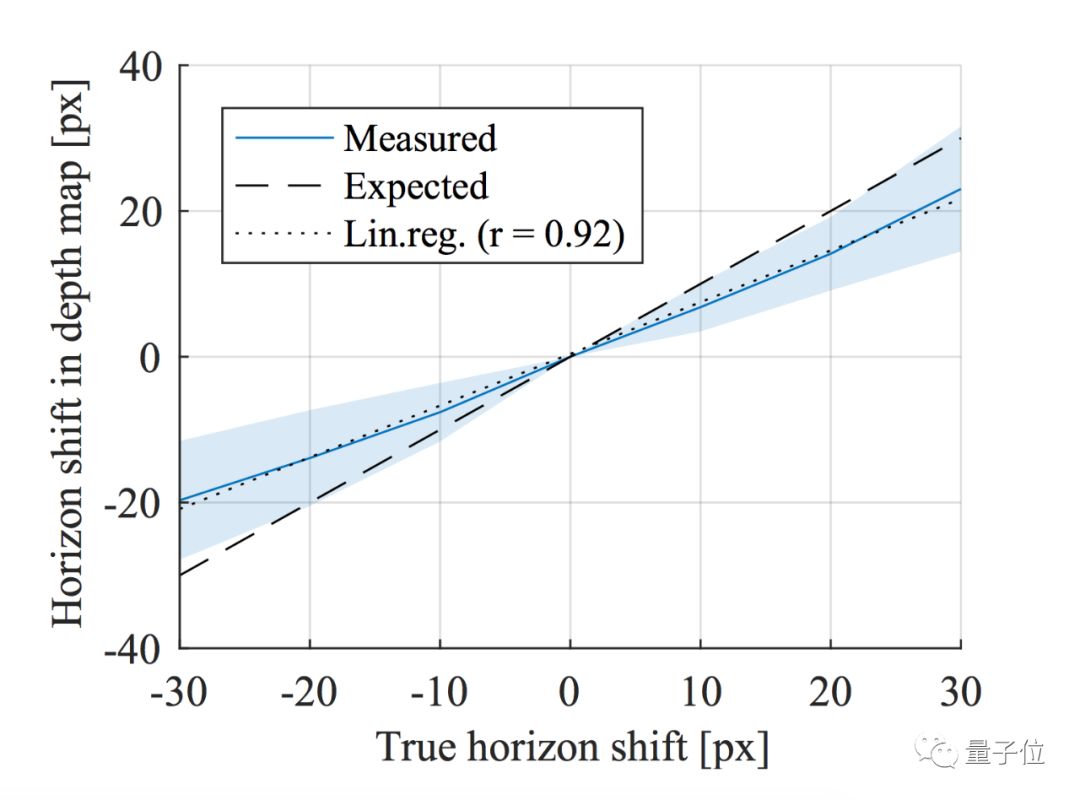
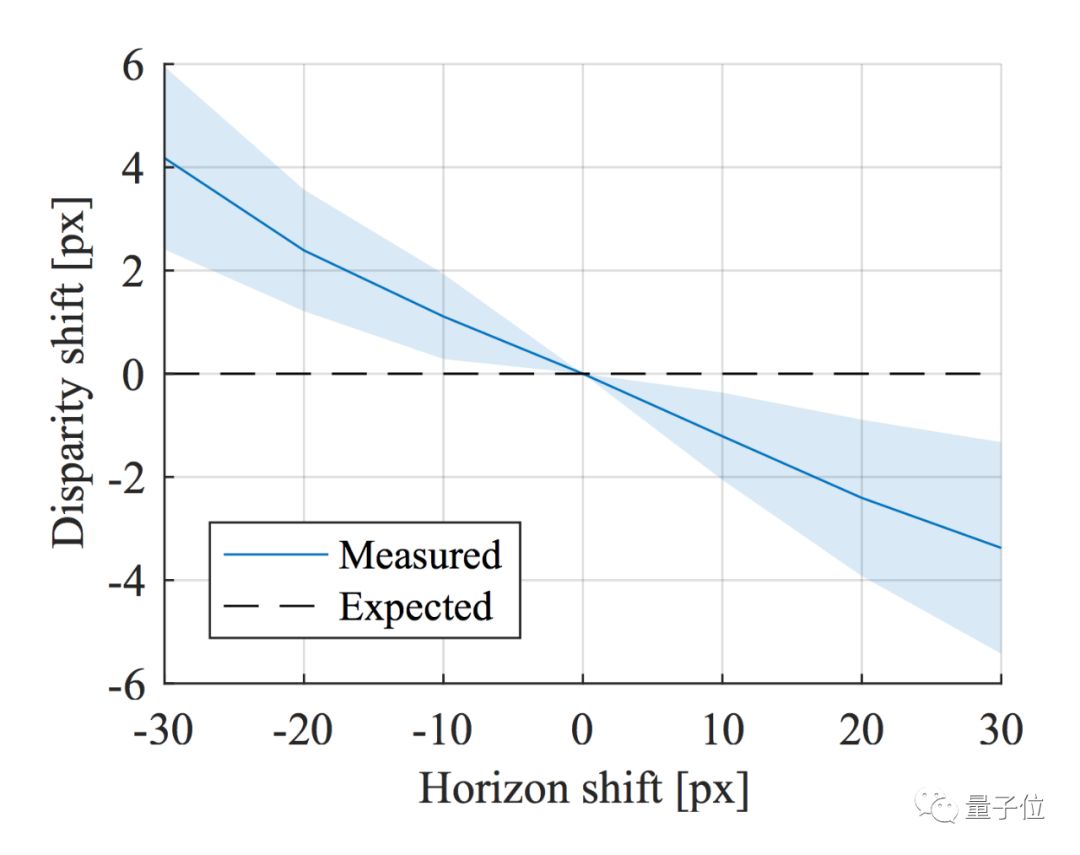
For the roll angle, a similar sensitivity analysis can also be performed. The final conclusion is that the roll angle predicted by CNN does have some correlation with the ground truth, but it is much weaker than for pitch.
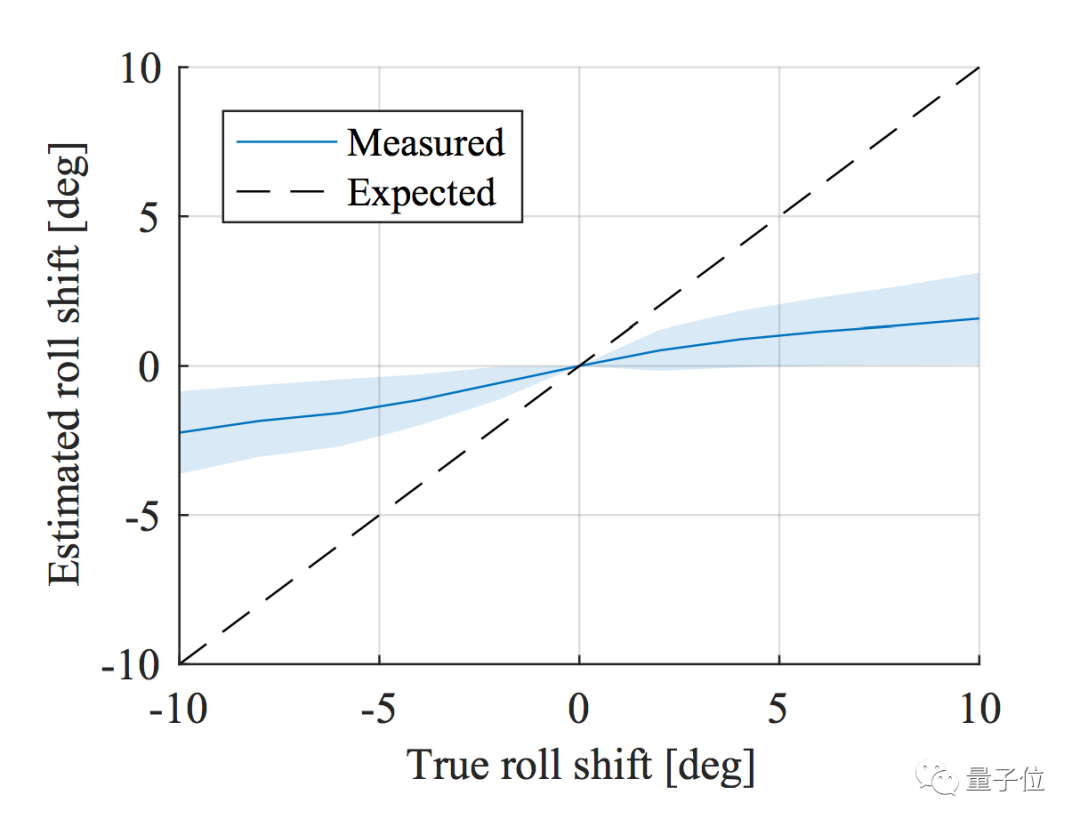
The third part, which is also the most interesting part, is to verify the invariance of CNN to color and texture.


It can be seen that removing color and retaining grayscale, or using a fake color prediction result is still reasonable. However, if using an average color or a specified color, the entire prediction result is significantly affected.
This actually indicates that although it is not necessary to explicitly model semantic information, texture is still crucial for depth prediction.
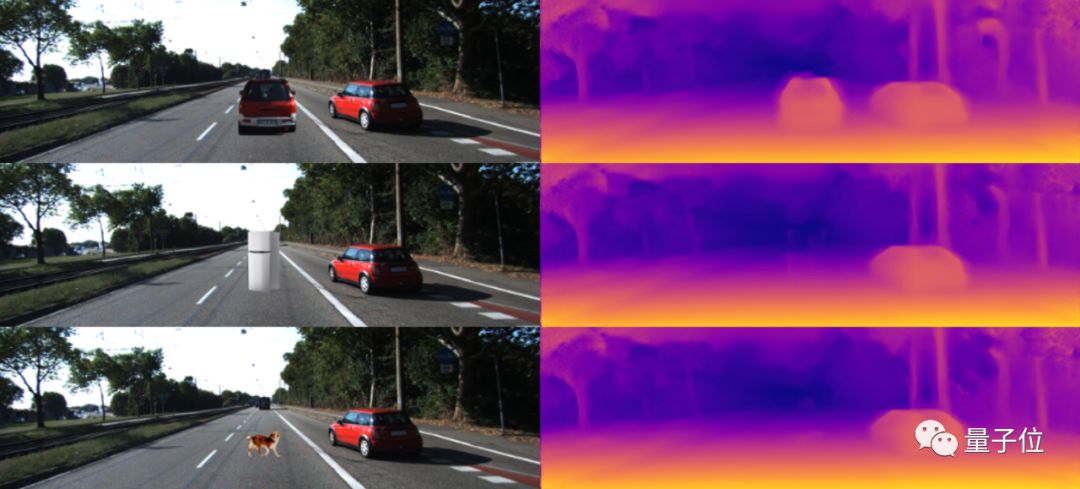
The article also conducted many other experiments to verify the sensitivity of CNN to unknown objects and contours, which will not be elaborated here. Just to mention one interesting example: if we add some unknown objects that did not appear in the training set to the image, unsurprisingly, the model completely fails to perceive their existence. However, if we add some shadows under these objects, the model suddenly can identify the entire object.
From this small experiment, we can glimpse what information CNN relies on to recognize objects, and how much CNN likes to find “shortcuts” in the data to fit the data.

Having said so much, there are also a few points I think can be further explored, including:
1. In indoor scenes, such as in datasets like NYU Depth, how does CNN estimate depth without a large ground plane?
2. In the first analysis experiment, since CNN measures distance based on the vertical coordinates of the contact points of the wheels, where does this information come from? The network structure is basically an FCN, which has translation invariant characteristics, so it should not include coordinate information. Did padding leak positional information? Or did lane lines or other cues leak this information? This is also quite interesting. Intuitively, the scale of objects is information that CNN can capture more easily, but in reality, it is not, indicating that there are some cues that CNN can utilize directly that we have not discovered.
3. Since CNN is sensitive to cropping and rotation, if we use random cropping and random rotation as data augmentation during training, will the depth cues relied upon by CNN change?
In summary, existing algorithms based on CNN for depth estimation essentially rely on overfitting certain information in the scene for depth estimation. Overall, these methods do not consider any geometric constraints, so their generalization ability in different scenes is relatively weak.
How to combine the advantages of geometric methods and learning methods is a long-standing topic.
On one hand, this problem can be split into two parts: one part estimates relative depth at different positions using geometric methods, while the other part predicts absolute scales using some scene priors or data-driven methods, and then combines the two to obtain a reliable and robust depth estimate.
On the other hand, perhaps we can predict some invariant physical quantities and combine them with geometric information to obtain the final depth information, such as the dimensions of certain specific vehicle types, lane line information, etc. There are still many open questions to be solved in this field.
How do neural networks see depth in single images? Author: Tom van Dijk, Guido de Croon Proceedings of the IEEE International Conference on Computer Vision. 2019.https://arxiv.org/abs/1905.07005
Good news!
Beginner’s Visual Learning Knowledge Circle
Is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the "Beginner's Visual Learning" WeChat account backend to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Project 52 Lectures
Reply "Python Visual Practical Project" in the "Beginner's Visual Learning" WeChat account backend to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, and more, to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the "Beginner's Visual Learning" WeChat account backend to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the WeChat reader group to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes, otherwise, you will not be approved. After successful addition, you will be invited to the relevant WeChat group according to your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for understanding~