
Click on "XiaoBai Learns Vision" above, choose to add "Star" or "Top"
Heavy content delivered at the first time
Introduction
This article aims to address overfitting in neural networks.
Overfitting will be your main concern as you train the model with only 2000 data samples.There are some methods to help overcome overfitting, namely dropout and weight decay (L2 regularization).
We will discuss data augmentation, which is unique to computer vision, and is used everywhere when deep learning models interpret images.
Data Augmentation
Insufficient learning examples will prevent you from training a model that can generalize to new data, leading to overfitting. If you had unlimited data, your model would be exposed to all the features of the current data distribution, thus preventing overfitting.
By generating realistic images with various random variations, data augmentation uses existing training samples to create more training data.
Your model should not see the same image twice during training. This makes the model more general and exposes it to other features of the data.
Keras can achieve this by defining various random transformations to be applied to the images using the ImageDataGenerator function.
Let’s start with an illustration.
####-----data augmentation configuration via ImageDataGenerator-------####
datagen = ImageDataGenerator(
rotation=40,
width_shift=0.2,
height_shift=0.2,
shear=0.2,
zoom=0.2,
horizontal_flip=True,
fill_mode='nearest')
Let’s quickly review this code:
-
rotation: This is the range of random rotation for the image. It is between (0-180) degrees. -
width_shift and height_shift: The range (as a fraction of total width or height) in which to randomly flip the image vertically or horizontally. -
shear: Used to randomly apply shear transformations. -
zoom: Used to randomly zoom in on the image. -
horizontal_flip: Used to randomly flip half of the image horizontally. -
fill_mode: The method used to fill in new pixels that may appear after rotation or width/height changes.
Displaying Augmented Images
####-----Let's display some randomly augmented training images-------####
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()

Figure: Using data augmentation to generate cat images
If you set up training a new network with data augmentation, the network will never receive the same input twice.
However, since it only receives input from a small number of original photos, these inputs remain highly correlated; you can only remix existing information.
Thus, this may not be enough to eliminate overfitting. Before the densely connected classifier, you should include a Dropout layer in the algorithm to further combat overfitting.
Real-Time Data Augmentation Applications
1. Healthcare
Managing datasets is not a solution for medical imaging applications, as obtaining a large number of professionally labeled samples takes a long time and money.
Networks designed with augmentation must be more reliable and realistic than predictions in similar X-ray images. However, we can increase the amount of data in subsequent illustrations using data augmentation.
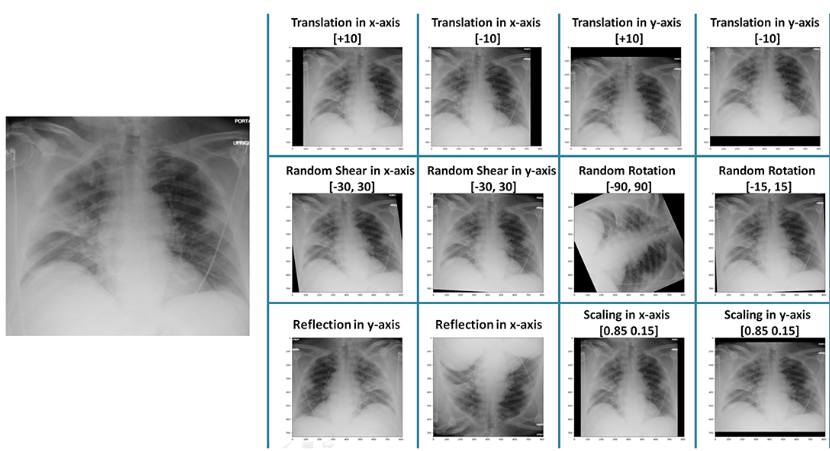
Figure: Data augmentation in X-ray images
2. Autonomous Vehicles
Autonomous vehicles are a different use case where data augmentation is beneficial.
For example, CARLA is designed to produce flexibility and realism in physical simulations. CARLA aims to facilitate the outcomes, guidance, and validation of autonomous driving systems. It is based on Unreal Engine 4 and provides a complete simulation environment for testing autonomous driving technology in a safe environment.
When data scarcity becomes an issue, simulated environments created using reinforcement learning techniques can assist in training and testing AI systems. The ability to model simulated environments to create realistic scenarios opens up a world of possibilities for data augmentation.
Defining CNN Model from Scratch
####------Defining CNN, including dropout--------####
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Let’s train the network using data augmentation and loss function.
####-------Train CNN using data-augmentation--------#####
train_datagen = ImageDataGenerator(rescale=1./255, rotation=40, width_shift=0.2, height_shift=0.2, shear=0.2, zoom=0.2, horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(150, 150), batch_size=32, class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(150, 150), batch_size=32, class_mode='binary')
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
####-------Save the model--------#####
model.save('cats_and_dogs_small_2.h5')
With data augmentation and dropout, the model is no longer overfitting. The training curve and validation curve are close to each other. With this accuracy, you exceed the non-regularized model by 15%, achieving 82%. Let’s plot the curves.
Display Loss and Accuracy Curves During Training
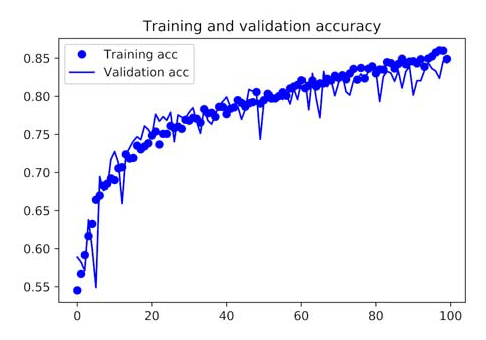
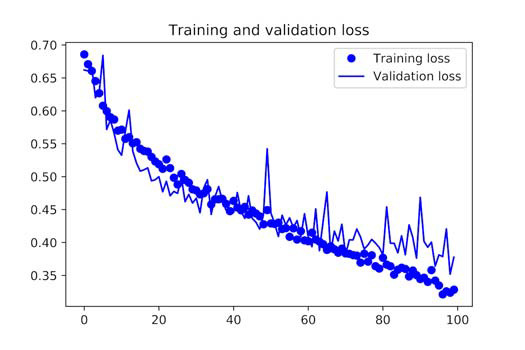
By using other regularization methods and fine-tuning network parameters (such as the number of filters in each convolutional layer or the number of layers in the network), you can achieve higher accuracy, up to 86% or 87%.
However, since you are dealing with a small amount of data, achieving higher levels by training your own CNN from scratch will be a challenge.
You must adopt a pre-trained model as a further step to improve your accuracy in this challenge.
Conclusion
-
The quality, quantity, and contextual nature of training data significantly affect the accuracy of deep learning models. However, one of the biggest problems in developing deep learning models is the lack of data. -
Obtaining such data in production use can be both expensive and time-consuming. Companies use data augmentation, a low-cost and efficient technique, to develop high-precision AI models faster and reduce reliance on collecting and preparing training instances. -
This article explains how we use data augmentation techniques to train our models. Data augmentation is used when collecting a large amount of data is challenging. As discussed in the blog, healthcare and autonomous vehicles are two of the most notable fields using this approach.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of "XiaoBai Learns Vision" public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of "XiaoBai Learns Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of "XiaoBai Learns Vision" public account to download 20 practical projects based on OpenCV to achieve advanced OpenCV learning.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will be gradually subdivided in the future). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, you will not be approved. After successful addition, you will be invited to the relevant WeChat group based on research direction. Please do not send advertisements in the group, otherwise, you will be asked to leave the group. Thank you for your understanding~