
This article provides an overview of the content:
1. Introduction to CatBoost
CatBoost is a machine learning library open-sourced by the Russian search giant Yandex in 2017 and is a type of Boosting algorithm. CatBoost, along with XGBoost and LightGBM, is known as one of the three mainstream tools for GBDT, all of which are improved implementations under the GBDT algorithm framework. XGBoost is widely used in industry, LightGBM effectively enhances the computational efficiency of GBDT, while Yandex’s CatBoost claims to perform better than XGBoost and LightGBM in terms of algorithm accuracy.
CatBoost is a GBDT framework that implements fewer parameters based on symmetric decision trees (oblivious trees), supports categorical variables, and achieves high accuracy. Its main pain point is efficiently and reasonably handling categorical features, which is evident from its name, as CatBoost is composed of Categorical and Boosting. Additionally, CatBoost addresses Gradient Bias and Prediction shift issues, thereby reducing overfitting and improving the accuracy and generalization ability of the algorithm.
Compared to XGBoost and LightGBM, CatBoost’s innovations include:
-
Embedding an innovative algorithm that automatically processes categorical features into numerical features. It first performs some statistics on categorical features, calculating the frequency of a certain category feature, and then adds hyperparameters to generate new numerical features. -
CatBoost also uses combined categorical features, leveraging the relationships between features, greatly enriching the feature dimensions. -
Using ranking boosting methods to combat noise points in the training set, thus avoiding gradient estimation bias and addressing the prediction shift problem. -
Employing completely symmetric trees as the base model.
2. Categorical Features
2.1 Related Work on Categorical Features
Categorical features are those that are not numerical but rather discrete sets, such as province names (Shandong, Shanxi, Hebei, etc.), city names (Beijing, Shanghai, Shenzhen, etc.), and education levels (undergraduate, master’s, doctorate, etc.). In gradient boosting algorithms, the most common approach is to convert these categorical features into numerical ones, typically transforming them into one or more numerical features.
If a low-cardinality feature is present, meaning that the number of unique values after deduplication is relatively small, one-hot encoding is generally used to convert the feature into numerical form. One-hot encoding can be performed during data preprocessing or during model training; from the perspective of training time, the latter is more efficient, and CatBoost adopts this method for low-cardinality categorical features.
Clearly, for high-cardinality categorical features, such as user IDs, this encoding method can generate a large number of new features, leading to the curse of dimensionality. A compromise is to group categories into a limited number of clusters before applying one-hot encoding. A commonly used method is to group based on Target Statistics (TS), which estimates the expected value of the target variable for each category. Some even use TS directly as a new numerical variable to replace the original categorical variable. Importantly, by setting thresholds for TS numerical features based on log loss, Gini coefficients, or mean squared error, one can obtain the optimal split among all possible splits that divide the categories into two for the training set. In LightGBM, categorical features are represented by gradient statistics (GS) at each step of gradient boosting. Although this provides important information for tree construction, it has two drawbacks:
-
Increased computation time, as GS needs to be calculated for each categorical feature at every iteration; -
Increased storage requirements, as for a categorical variable, it is necessary to store the categories for each node separation.
To overcome these shortcomings, LightGBM sacrifices some information by grouping all long-tail categories into one category, claiming that this approach is much better than one-hot encoding when handling high-cardinality categorical features. However, if TS features are used, only one number needs to be calculated and stored for each category.
Therefore, adopting TS as a new numerical feature is the most effective method for handling categorical features with minimal information loss. TS is also widely used in click prediction tasks, where categorical features include users, regions, ads, and advertisers. Next, we will focus on TS, temporarily setting aside one-hot encoding and GS.
2.2 Target Statistics (TS)
The design intent of the CatBoost algorithm is to better handle categorical features in GBDT. When dealing with categorical features in GBDT, the simplest method is to replace the categorical feature with the average value of the corresponding labels. In decision trees, the label average will serve as the criterion for node splitting. This method is known as Greedy Target-based Statistics, abbreviated as Greedy TS, and can be expressed with the formula:
This method has an obvious flaw: features usually contain more information than labels. If we force the average label value to represent the feature, it will lead to conditional shift problems when the training and testing datasets have different structures and distributions.
A standard way to improve Greedy TS is to add a prior distribution term, which can reduce the impact of noise and low-frequency categorical data on the data distribution:
where is the added prior term, and is typically a weight coefficient greater than . Adding a prior term is a common practice; for features with fewer categories, it can reduce the influence of noise data. For regression problems, the prior term can usually be taken as the mean of the dataset labels. For binary classification, the prior term is the prior probability of the positive class. Using multiple dataset arrangements is also effective, but direct calculation may lead to overfitting. CatBoost employs a novel method to compute leaf node values that avoids overfitting issues that arise from direct calculations in multiple dataset arrangements.
Of course, the paper “CatBoost: unbiased boosting with categorical features” also mentions several other methods to improve Greedy TS, including Holdout TS, Leave-one-out TS, and Ordered TS. I will not translate these methods from the paper; interested readers can refer to the original paper.
2.3 Feature Combination
It is noteworthy that any combination of several categorical features can be viewed as a new feature. For example, in a music recommendation application, if two categorical features are user ID and music genre, converting the user ID and music genre into numerical features based on some users’ preference for rock music will lose information. Combining these two features can solve this problem and yield a new powerful feature. However, the number of combinations will grow exponentially with the number of categorical features in the dataset, making it impossible to consider all combinations in the algorithm. When constructing new split points for the current tree, CatBoost adopts a greedy strategy to consider combinations. For the first split of the tree, no combinations are considered. For the next split, CatBoost combines all combinations of the current tree’s categorical features with all categorical features in the dataset, dynamically transforming the new combined categorical features into numerical features. CatBoost also generates combinations of numerical and categorical features in the following way: all split points selected in the tree are treated as categorical features with two values and are considered for combination like categorical features.
2.4 Summary of CatBoost Handling Categorical Features
-
First, it will calculate some statistics of the data. It calculates the frequency of a certain category, adds hyperparameters, and generates new numerical features. This strategy requires that the same label data cannot be arranged together (i.e., all of one type followed by all of another); the dataset needs to be shuffled before training. -
Second, it uses different arrangements of the data (essentially a ). Before establishing the tree in each round, a die is rolled to decide which arrangement to use for generating the tree. -
Third, it considers different combinations of categorical features. For example, combining color and type can create features like blue dog. When the number of categorical features that need to be combined increases, CatBoost only considers a portion of the combinations. When selecting the first node, only one feature is considered, such as A. When generating the second node, combinations of A with any categorical feature are considered, choosing the best among them. This greedy algorithm generates combinations. -
Fourth, unless dealing with dimensions that are very small like gender, it is not recommended to generate one-hot encoding vectors manually; it is better to let the algorithm handle it.
3. Overcoming Gradient Bias
To learn how CatBoost overcomes gradient bias, I propose three questions:
-
Why is there gradient bias? -
What problems does gradient bias cause? -
How to solve gradient bias?
Like all standard gradient boosting algorithms, CatBoost fits the current model’s gradient by constructing new trees. However, all classical boosting algorithms suffer from overfitting issues caused by biased point-wise gradient estimates. The gradients used at each step are estimated using the same data points in the current model, leading to a shift in the estimated gradient’s distribution compared to the true distribution of gradients in any domain of the feature space, resulting in overfitting. To address this issue, CatBoost makes several improvements to the classical gradient boosting algorithm, briefly introduced as follows.
Many algorithms utilizing GBDT techniques (e.g., XGBoost, LightGBM) divide the construction of the next tree into two stages: selecting the tree structure and calculating the values of the leaf nodes after fixing the tree structure. To choose the optimal tree structure, the algorithm enumerates different splits, builds trees with these splits, computes values for the resulting leaf nodes, and then scores the obtained trees to select the best split. The values of the leaf nodes in both stages are computed as approximations of the gradient or Newton step. In CatBoost, the first stage uses an unbiased estimate of the gradient step, while the second stage employs the traditional GBDT scheme. Since the original gradient estimate is biased, how can it be changed to an unbiased estimate?
Let be the model after constructing trees, and let be the gradient value above the training sample after constructing trees. To make unbiased to the model , we need to train model without the involvement of . Since we need to compute unbiased gradient estimates for all training samples, it seems impossible to train without using any samples. We use the following trick to handle this issue: for each sample , we train a separate model , and this model never updates using gradient estimates based on that sample. We use to estimate the gradient on , and use this estimate to score the resulting tree. The pseudocode is described below, where is the loss function to be optimized, is the label value, and is the formula calculation value.

4. Prediction Shift and Ordered Boosting
4.1 Prediction Shift
To learn about prediction shift, I propose two questions:
-
What is prediction shift? -
What methods can solve the prediction shift problem?
Prediction shift is caused by gradient bias. In each iteration of GBDT, the loss function uses the same dataset to obtain the current model’s gradient, and then trains the base learner, but this leads to biased gradient estimates, which in turn causes overfitting issues in the model. CatBoost alleviates the gradient estimation bias by adopting ordered boosting methods to replace the gradient estimation methods in traditional algorithms, thereby improving the model’s generalization ability. Below, we will describe and analyze prediction shift in detail.
First, let’s look at the overall iteration process of GBDT:
The GBDT algorithm iteratively builds a strong learner through a series of classifiers to achieve higher accuracy classification. It employs a forward distribution algorithm, using Classification and Regression Trees (CART) as weak learners.
Assuming that the strong learner obtained from the previous iteration is , and the loss function is , the goal of this iteration is to find a CART regression tree model weak learner that minimizes the loss function for this round. Formula (1) represents the objective function for this round of iteration.
GBDT uses the negative gradient of the loss function to fit an approximation of the loss for each round, with formula (2) representing the aforementioned gradient.
Typically, formula (3) is used to approximate .
The strong learner for this round is obtained as shown in formula (4):
During this process, the shift occurs as follows:
The conditional distribution computed based on random calculations shifts from the distribution of the test set , causing the base learner defined by formula (3) to deviate from that defined by formula (1), ultimately affecting the model’s generalization ability.
4.2 Ordered Boosting
To overcome the prediction shift problem, CatBoost proposes a new algorithm called Ordered boosting.

From the Ordered boosting algorithm illustrated above, it can be seen that to obtain an unbiased gradient estimate, CatBoost trains a separate model for each sample , where model is trained using a training set that does not include the sample. We use to obtain the gradient estimate for the sample and use this gradient to train the base learner and obtain the final model.
While Ordered boosting is beneficial, it is often impractical in most real-world tasks due to the need to train different models, significantly increasing memory consumption and time complexity. In CatBoost, we have improved the gradient boosting algorithm based on decision trees.
As mentioned earlier, in the traditional GBDT framework, constructing the next tree is divided into two stages: selecting the tree structure and calculating the values of the leaf nodes after fixing the tree structure. CatBoost primarily optimizes the first stage. During the tree construction phase, CatBoost has two boosting modes: Ordered and Plain. The Plain mode uses the standard GBDT algorithm after transforming categorical features with built-in ordered TS. Ordered is an optimization of the Ordered boosting algorithm. For detailed descriptions of these two boosting modes, please refer to the paper “CatBoost: unbiased boosting with categorical features”.
5. Fast Scoring
CatBoost uses symmetric trees (oblivious trees) as base predictors. In these trees, the same splitting criteria are applied across the entire layer of the tree. This type of tree is balanced and less prone to overfitting. Gradient boosting symmetric trees have been successfully applied to various learning tasks. In symmetric trees, the index of each leaf node can be encoded as a binary vector of length equal to the tree depth. This has been widely applied in the CatBoost model evaluator: we first binarize all floating-point features, statistical information, and one-hot encoded features, and then use binary features to calculate model predictions.
6. Fast Training Based on GPU
-
Dense numerical features. One of the biggest challenges for any GBDT algorithm is searching for the best splits. This step is the main computational burden when building decision trees, especially for datasets with dense numerical features. CatBoost uses oblivious decision trees as the base model and discretizes features into a fixed number of bins to reduce memory usage. In terms of GPU memory usage, CatBoost is at least as efficient as LightGBM. The main improvement lies in the use of a histogram computation method that does not rely on atomic operations. -
Categorical features. CatBoost implements various methods for handling categorical features and uses perfect hashing to store the values of categorical features to reduce memory usage. Due to GPU memory limitations, it stores bit-compressed perfect hashes in CPU RAM, along with required data streams, overlapping computations, and memory operations. Observations are grouped using hashing. For each group, we need to calculate some prefix statistics. The calculation of these statistics is implemented using segmented scan GPU primitives. -
Multi-GPU support. The GPU implementation in CatBoost supports multiple GPUs. Distributed tree learning can be parallelized by data or features. CatBoost employs a computational scheme using multiple arrangements of learning datasets to calculate statistics for categorical features during training.
7. Advantages and Disadvantages of CatBoost
7.1 Advantages
-
Outstanding performance: In terms of performance, it can rival any advanced machine learning algorithm; -
Robustness: It reduces the need for tuning many hyperparameters and lowers the chances of overfitting, making the model more generalizable; -
Ease of use: It provides a Python interface integrated with scikit, as well as R and command-line interfaces; -
Practicality: It can handle both categorical and numerical features; -
Scalability: It supports custom loss functions;
7.2 Disadvantages
-
Handling categorical features requires a large amount of memory and time; -
The setting of different random numbers has a certain impact on the model’s prediction results;
8. CatBoost Examples
All datasets and code in this article are available on my GitHub: https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/tree/master/Ensemble%20Learning/CatBoost
8.1 Installing CatBoost Dependencies
pip install catboost8.2 CatBoost Classification
(1) Dataset
Here, I used the 2015 flight delay Kaggle dataset, which contains both categorical and numerical variables. This dataset has approximately 5 million records, and I used 1% of the data: 50,000 rows. The official dataset link: https://www.kaggle.com/usdot/flight-delays#flights.csv. The features used for modeling are as follows:
-
Month, Day, Weekday: Integer data -
Route or Flight Number: Integer data -
Departure and Arrival Airports: Numerical data -
Departure Time: Floating-point data -
Distance and Flight Time: Floating-point data -
Arrival Delay Status: This feature is used as the target for prediction and converted to a binary variable: whether the flight is delayed by more than 10 minutes
Experiment Description: When tuning CatBoost, it is challenging to assign metrics to categorical features. Therefore, results are provided both without passing categorical features and evaluating two models: one including categorical features and another excluding them. If no content is passed in the cat_features parameter, CatBoost will treat all columns as numerical variables. Note that if a column contains string values, the CatBoost algorithm will throw an error. Additionally, int variables with default values will also be treated as numerical data by default. In CatBoost, variables must be declared to be treated as categorical variables.
(2) Code without Categorical Features Option
import pandas as pd, numpy as npfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn import metricsimport catboost as cb
# There are approximately 5 million records, I used 1% of the data: 50,000 rows
# data = pd.read_csv("flight-delays/flights.csv")# data = data.sample(frac=0.1, random_state=10) # 500->50
# data = data.sample(frac=0.1, random_state=10) # 50->5
# data.to_csv("flight-delays/min_flights.csv")
# Read 50,000 rows
data = pd.read_csv("flight-delays/min_flights.csv")
print(data.shape) # (58191, 31)
data = data[["MONTH", "DAY", "DAY_OF_WEEK", "AIRLINE", "FLIGHT_NUMBER", "DESTINATION_AIRPORT", "ORIGIN_AIRPORT", "AIR_TIME", "DEPARTURE_TIME", "DISTANCE", "ARRIVAL_DELAY"]]data.dropna(inplace=True)
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"] > 10) * 1
cols = ["AIRLINE", "FLIGHT_NUMBER", "DESTINATION_AIRPORT", "ORIGIN_AIRPORT"]for item in cols: data[item] = data[item].astype("category").cat.codes + 1
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25)
cat_features_index = [0, 1, 2, 3, 4, 5, 6]
def auc(m, train, test): return (metrics.roc_auc_score(y_train, m.predict_proba(train)[:, 1]), metrics.roc_auc_score(y_test, m.predict_proba(test)[:, 1]))
# Hyperparameter tuning using grid search to find optimal parametersparams = {'depth': [4, 7, 10], 'learning_rate': [0.03, 0.1, 0.15], 'l2_leaf_reg': [1, 4, 9], 'iterations': [300, 500]}cb = cb.CatBoostClassifier()cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv=3)cb_model.fit(train, y_train)# View best scoreprint(cb_model.best_score_) # 0.7088001891107445# View best parametersprint(cb_model.best_params_) # {'depth': 4, 'iterations': 500, 'l2_leaf_reg': 9, 'learning_rate': 0.15}
# With Categorical features, fit data with optimal parametersclf = cb.CatBoostClassifier(eval_metric="AUC", depth=4, iterations=500, l2_leaf_reg=9, learning_rate=0.15)clf.fit(train, y_train)
print(auc(clf, train, test)) # (0.7809684655761157, 0.7104617034553192)(3) Code with Categorical Features Option
import pandas as pd, numpy as npfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn import metricsimport catboost as cb
# Read 50,000 rows
data = pd.read_csv("flight-delays/min_flights.csv")
print(data.shape) # (58191, 31)
data = data[["MONTH", "DAY", "DAY_OF_WEEK", "AIRLINE", "FLIGHT_NUMBER", "DESTINATION_AIRPORT", "ORIGIN_AIRPORT", "AIR_TIME", "DEPARTURE_TIME", "DISTANCE", "ARRIVAL_DELAY"]]data.dropna(inplace=True)
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"] > 10) * 1
cols = ["AIRLINE", "FLIGHT_NUMBER", "DESTINATION_AIRPORT", "ORIGIN_AIRPORT"]for item in cols: data[item] = data[item].astype("category").cat.codes + 1
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25)
cat_features_index = [0, 1, 2, 3, 4, 5, 6]
def auc(m, train, test): return (metrics.roc_auc_score(y_train, m.predict_proba(train)[:, 1]), metrics.roc_auc_score(y_test, m.predict_proba(test)[:, 1]))
# With Categorical featuresclf = cb.CatBoostClassifier(eval_metric="AUC", one_hot_max_size=31, depth=4, iterations=500, l2_leaf_reg=9, learning_rate=0.15)clf.fit(train, y_train, cat_features=cat_features_index)
print(auc(clf, train, test)) # (0.7817912095285117, 0.7152541135019913)8.3 CatBoost Regression
from catboost import CatBoostRegressor
# Initialize data
train_data = [[1, 4, 5, 6], [4, 5, 6, 7], [30, 40, 50, 60]]
eval_data = [[2, 4, 6, 8], [1, 4, 50, 60]]
train_labels = [10, 20, 30]# Initialize CatBoostRegressormodel = CatBoostRegressor(iterations=2, learning_rate=1, depth=2)# Fit modelmodel.fit(train_data, train_labels)# Get predictionspreds = model.predict(eval_data)print(preds)9. Thoughts on CatBoost
9.1 Relationship and Differences Between CatBoost, XGBoost, and LightGBM
(1) The XGBoost algorithm was first proposed by Tianqi Chen in March 2014, but it only gained fame in 2016. Microsoft released the first stable version of LightGBM in January 2017. In April 2017, Yandex open-sourced CatBoost. Since the introduction of XGBoost, many articles have aimed at various improvements, with CatBoost and LightGBM being two of them.
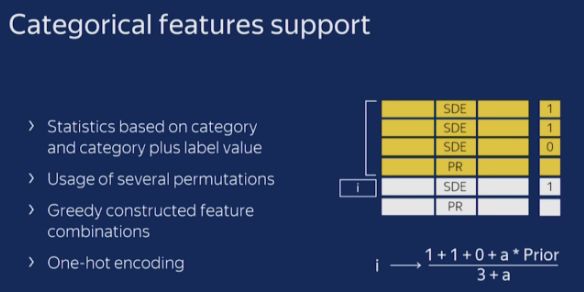
(2) CatBoost handles categorical features very flexibly, allowing direct input of categorical feature column identifiers, with the model automatically using one-hot encoding. It can also limit the length of one-hot feature vectors by setting the one_hot_max_size parameter. If categorical feature column identifiers are not passed, CatBoost treats all columns as numerical features. For features exceeding the set one_hot_max_size value, CatBoost will use an efficient encoding method similar to mean encoding, which reduces overfitting. The process is as follows:
-
Randomly shuffle the input sample set and generate multiple random arrangements; -
Convert floating-point or attribute values into integers; -
Transform all categorical feature values into numerical results based on the following formula;
where countInClass indicates how many sample labels are present in the current categorical feature value; prior is the initial value in the numerator, determined by initial parameters; and totalCount is the number of samples having the same categorical feature value as the current sample among all samples (including the current sample).
Similar to CatBoost, LightGBM can also handle categorical feature data by using feature names as input. It does not perform one-hot encoding, which makes it much faster compared to one-hot encoding. LightGBM employs a special algorithm to determine the splitting values for attribute features.
train_data = lgb.Dataset(data, label=label, feature_name=['c1', 'c2', 'c3'], categorical_feature=['c3'])Note that before creating a dataset suitable for LightGBM, categorical feature variables must be converted to integer variables, as this algorithm does not allow string data to be passed to the categorical variable parameters.
XGBoost differs from CatBoost and LightGBM in that it cannot handle categorical features itself; it only accepts numerical data like random forests. Therefore, categorical feature data must be processed through various encoding methods, such as ordinal encoding, one-hot encoding, and binary encoding, before being passed to XGBoost.
10. References
Interpretation of CatBoost Papers:
[1] Prokhorenkova L, Gusev G, Vorobev A, et al. CatBoost: unbiased boosting with categorical features[C]//Advances in Neural Information Processing Systems. 2018: 6638-6648.
[2] Dorogush A V, Ershov V, Gulin A. CatBoost: gradient boosting with categorical features support[J]. arXiv preprint arXiv:1810.11363, 2018.
Machine learning algorithm Catboost, link: https://www.biaodianfu.com/catboost.html
What is the use of oblivious trees in machine learning? – Li Damao’s answer – Zhihu https://www.zhihu.com/question/311641149/answer/593286799
CatBoost algorithm summary, link: http://datacruiser.io/2019/08/19/DataWhale-Workout-No-8-CatBoost-Summary/
Explanation of CatBoost Algorithm:
[6] Complete guide to catboost, link: https://zhuanlan.zhihu.com/p/102570430
CatBoost principles and practices – Dukey’s article – Zhihu https://zhuanlan.zhihu.com/p/37916954
Model fusion – CatBoost, link: https://www.cnblogs.com/nxf-rabbit75/p/10923549.html#auto_id_0
Simple summary of CatBoost’s handling of categorical features, link: https://blog.csdn.net/weixin_42944192/article/details/102463796
Python3 Machine Learning Practice: Ensemble Learning with CatBoost – AnFany’s article – Zhihu https://zhuanlan.zhihu.com/p/53591724
Reflections on CatBoost:
[16] Introduction | Overview of the similarities and differences between XGBoost, Light GBM, and CatBoost from structure to performance, link: https://mp.weixin.qq.com/s/TD3RbdDidCrcL45oWpxNmw