Click on the above “Beginner’s Guide to Vision”, select to add “Bookmark” or “Pin”
Important content delivered immediately

-
Since capsule networks incorporate pose information, they can achieve good representation with just a small amount of data, making this a significant improvement over CNNs. For example, to recognize handwritten digits, the human brain needs dozens to hundreds of examples, while CNNs require tens of thousands of data points to train effectively, which is clearly too brute-force! -
They are closer to the human brain’s way of thinking, better modeling the hierarchical relationships of internal knowledge representations in neural networks. The intuition behind capsules is very simple and elegant.
-
The current implementations of capsule networks are significantly slower than other modern deep learning models (I think this is due to the coupling coefficients and the stacking of convolution layers), making improving training efficiency a major challenge.
Artificial neural networks should not pursue viewpoint invariance in “neuronal” activity (using a single scalar output to summarize the activity of a local pool of repeated feature detectors), but should use local “capsules” that perform some quite complex internal computations on their inputs and then encapsulate the results of these computations into a small vector containing rich information. Each capsule learns to recognize a visual entity implicitly defined within a limited observation condition and deformation range and outputs the probability of the entity’s existence within that limited range along with a set of “instance parameters”, which may include the precise pose, lighting conditions, and deformation information relative to that implicitly defined typical version of the visual entity. When a capsule operates correctly, the probability of the visual entity’s existence has local invariance—when the entity moves along the appearance manifold within the limited range covered by the capsule, the probability does not change. However, the instance parameters are “covariant”—as the observation conditions change and the entity moves along the appearance manifold, the instance parameters will change accordingly, as they represent the intrinsic coordinates of the entity on the appearance manifold.
-
Artificial neurons output a single scalar. Convolutional networks use convolutional kernels to stack the results calculated by the same kernel across different regions of a two-dimensional matrix to form the output of the convolutional layer. -
Viewpoint invariance is achieved through max pooling methods, as max pooling continuously searches the regions of a two-dimensional matrix and selects the largest number in the region, thus satisfying our desired activity invariance (i.e., we slightly adjust the input, and the output remains the same). In other words, if we slightly alter the object we want to detect in the input image, the model can still detect the object. -
Pooling layers lose valuable information and do not consider the relative spatial relationships between encoded features, thus we should use capsules. All the important information regarding the states of features detected by capsules will be encapsulated in vector form (neurons are scalars).

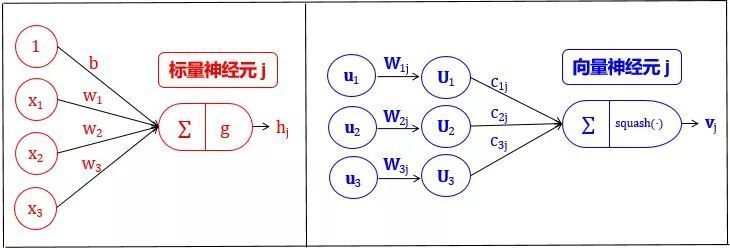
Dynamic Routing Algorithm
-
All weights are non-negative scalars -
For each lower-level capsule i, the sum of all weights cij equals 1 -
For each lower-level capsule i, the number of weights equals the number of higher-level capsules -
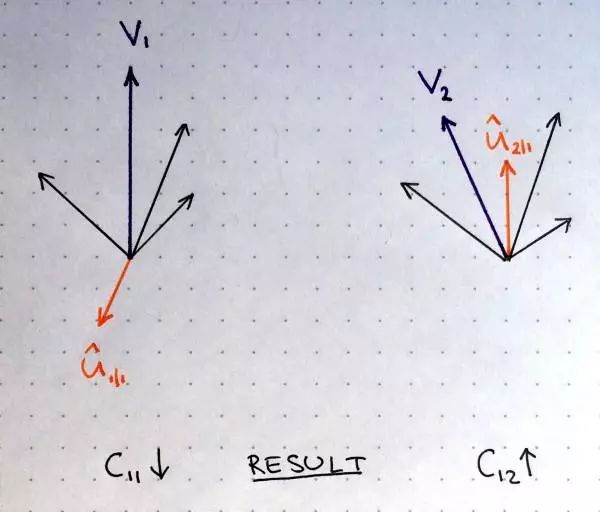
These weights are determined by an iterative dynamic routing algorithm

-
More iterations often lead to overfitting -
In practice, it is recommended to use 3 iterations
-
First layer: Convolutional layer -
Second layer: PrimaryCaps (Primary Capsule) layer -
Third layer: DigitCaps (Digit Capsule) layer -
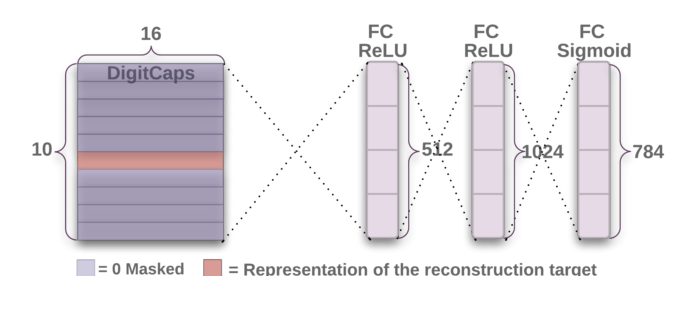
Fourth layer: First fully connected layer -
Fifth layer: Second fully connected layer -
Sixth layer: Third fully connected layer
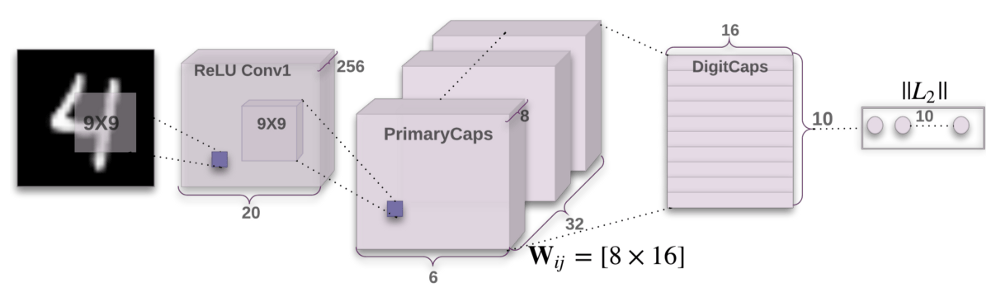
-
Input: 28×28 image (grayscale) -
Output: 20×20×256 tensor -
Convolutional kernels: 256 kernels of size 9×9×1 with a stride of 1 -
Activation function: ReLU
-
Input: 20×20×256 tensor -
Output: 6×6×8×32 tensor (total of 32 capsules) -
Convolutional kernels: 8 kernels of size 9×9×256 per capsule with a stride of 1
-
Input: 6×6×8×32 tensor -
Output: 16×10 matrix
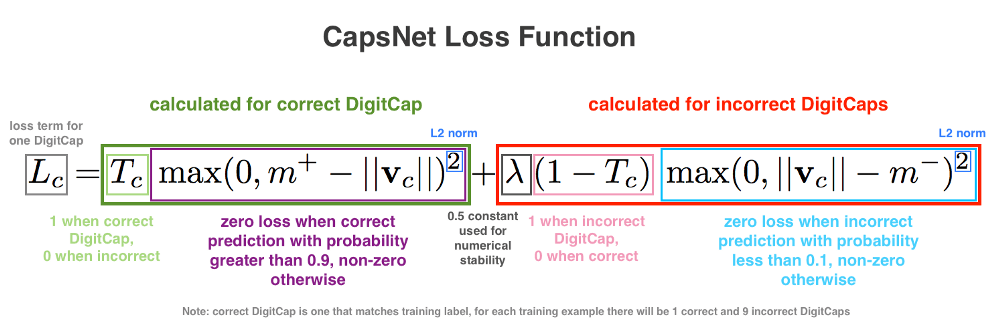

-
Input: 16×10 matrix -
Output: 512 vector
-
Input: 512 vector -
Output: 1024 vector
-
Input: 1024 vector -
Output: 784 vector
Good news!
The Beginner's Guide to Vision Knowledge Group
is now open to the public 👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the "Beginner's Guide to Vision" public account backend to download the first OpenCV extension module tutorial in Chinese on the internet, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the "Beginner's Guide to Vision" public account backend to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to assist in quickly learning computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the "Beginner's Guide to Vision" public account backend to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the reader group of the public account to exchange ideas with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, you will not be approved. Once added successfully, invitations will be sent to the relevant WeChat group based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~