

Produced by Machine Learning Algorithms and Natural Language Processing
Original Column Author: Don.hub
Organization | JD Algorithm Engineer
School | Imperial College London
-
Outline
-
Intuition
-
Analysis
-
Pros
-
Cons
-
From Seq2Seq To Attention Model
-
Seq2Seq is important, but its drawbacks are also evident
-
Attention was born
-
Write the encoder and decoder model
-
Taxonomy of Attention
-
Number of Sequence
-
Distinctive
-
Co-attention
-
Self
-
Number of Abstraction
-
Single-level
-
Multi-level
-
Number of Positions
-
Soft/Global
-
Hard
-
Local
-
Number of Representations
-
Multi-representational
-
Multi-dimensional
-
Summary
-
Networks with Attention
-
Encoder-Decoder
-
CNN/RNN + RNN
-
Pointer Networks
-
Transformer
-
Memory Networks
-
Applications
-
NLG
-
Classification
-
Recommendation Systems
-
References
1. Outline
2. Intuition
The term “attention” is representative; when we look at an image, we are easily attracted by more important or prominent elements, thus we focus more on specific parts. In computer vision (CV), this can be seen as giving more weight to local parts of the image, for example, when generating titles for images, the words in the title will primarily focus on local elements.

In the field of NLP, we can imagine that when we are doing reading comprehension, we often look for answers with specific questions in mind, meaning that different parts of the article require different levels of attention. For instance, in sentiment analysis of reviews, certain emotional words like “amazing” require special attention because they are critical in determining the sentiment of the reviewer. As shown in the figure (Yang et al., He’s Team HAN).

Simply put, attention is a vector of weights.
3. Analysis
3.1 Pros
The benefits of attention mainly lie in its excellent interpretability and significant improvement in model performance; it has become an essential module in many SOTA models, especially with the advent of transformers (which utilize self/global/multi-level/multi-head attention), greatly changing the landscape of NLP.
3.2 Cons
It cannot capture positional information, requiring the addition of positional information. Of course, different attention mechanisms have their unique characteristics. If we talk about the drawbacks of transformers, the most significant one is the high spatial consumption due to the necessity of storing attention scores (N*N) dimensions, meaning the sequence length (N) cannot be too long, which leads to a lack of correlation between sequences (refer to XLNET and its solutions).
3.3 From Seq2Seq To Attention Model
Why was attention created? Attention was born primarily for translation tasks (but eventually not limited to translation tasks), let’s take a look at its specific evolution.
3.3.1 Seq2Seq is important, but its drawbacks are also evident
The Seq2Seq model consists of an encoder and a decoder, mainly aimed at translating input text into target text. Both the encoder and decoder can be RNNs (RNN/LSTM/GRU or Bi-directional RNN). The model encodes the source text into a fixed-length context vector, then uses this encoding to decode the specific output target via the decoder. This conversion task can be applied to translation, speech transformation, dialogue generation, and other sequence-to-sequence tasks.
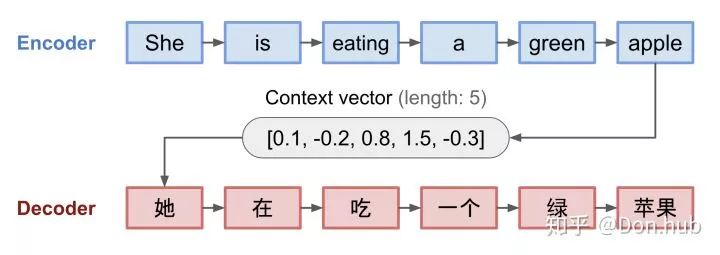
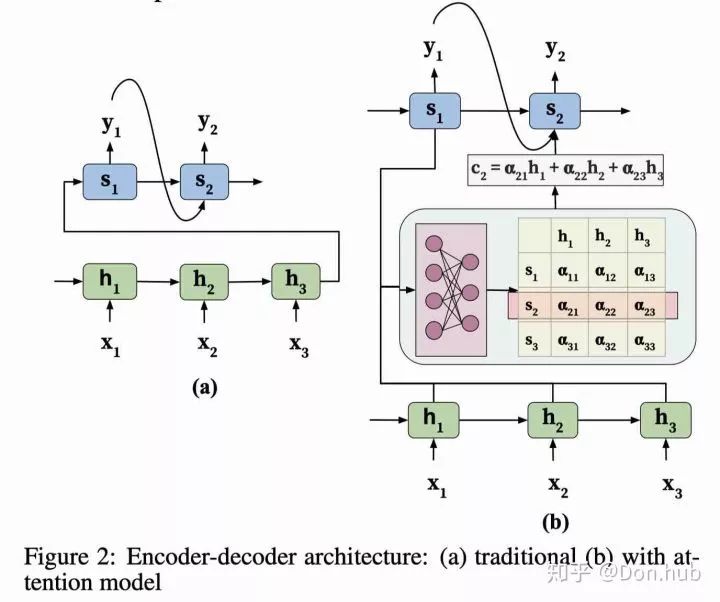
However, the drawbacks of this model are also evident: – First, all inputs are encoded into a fixed-length context vector; what is the appropriate length? It is difficult to have a precise answer, as a fixed-length vector cannot encode all contextual information, leading to the loss of many long-distance dependency relationships. – The decoder lacks a matching mechanism with the encoder’s input when generating output, failing to focus on different weights for different inputs. – Second, it is unable to model alignment between input and output sequences, which is crucial for structured output tasks like translation or summarization [Young et al., 2018]. Intuitively, in sequence-to-sequence tasks, each output token is expected to be influenced more by specific parts of the input sequence. However, the decoder lacks any mechanism to selectively focus on relevant input tokens while generating each output token.
3.3.2 Attention was born
NMT [paper] [code] first proposed adding an attention block between the encoder and decoder, primarily to address the matching issue between the encoder and decoder.
-
Where
is the decoder’s initialization hidden state, randomly initialized. Compared to Seq2Seq (which uses the context vector as the decoder’s hidden initialization),
is the decoder’s hidden states.
-
represents the output hidden states of the j-th encoder position.
-
-
is the output of the i-th decoder position, which is the output after passing through the hidden state and then through a fully connected layer.
-
represents the context vector of the i-th decoder, which is essentially a weighted sum of the output hidden states.
-
The input to the decoder is a concatenation of its own hidden state and
.
3.3.3 Write the Encoder and Decoder Model
For detailed implementation, refer to TensorFlow’s repo, which uses tf1.x Neural Machine Translation (seq2seq) tutorial. The code here uses the latest 2.x code.
The shape of the hidden states obtained after the input goes through the encoder is (batch_size, max_length, hidden_size), while the shape of the decoder’s hidden state is (batch_size, hidden_size).
The following is the implemented equation:

This tutorial uses Bahdanau attention for the encoder. Let’s decide on notation before writing the simplified form:
-
FC = Fully connected (dense) layer
-
EO = Encoder output
-
H = hidden state
-
X = input to the decoder
And the pseudo-code:
-
score = FC(tanh(FC(EO) + FC(H))) -
attention weights = softmax(score, axis = 1). Softmax by default is applied on the last axis but here we want to apply it on the 1st axis, since the shape of score is (batch_size, max_length, hidden_size).Max_lengthis the length of our input. Since we are trying to assign a weight to each input, softmax should be applied on that axis. -
context vector = sum(attention weights * EO, axis = 1). Same reason as above for choosing axis as 1. -
embedding output= The input to the decoder X is passed through an embedding layer. -
merged vector = concat(embedding output, context vector) -
This merged vector is then given to the GRU
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# we are doing this to perform addition to calculate the score
hidden_with_time_axis = tf.expand_dims(query, 1)
# score shape == (batch_size, max_length, 1)
# we get 1 at the last axis because we are applying score to self.V
# the shape of the tensor before applying self.V is (batch_size, max_length, units)
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc = tf.keras.layers.Dense(vocab_size)
# used for attention
self.attention = BahdanauAttention(self.dec_units)
def call(self, x, hidden, enc_output):
# enc_output shape == (batch_size, max_length, hidden_size)
context_vector, attention_weights = self.attention(hidden, enc_output)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
# output shape == (batch_size * 1, hidden_size)
output = tf.reshape(output, (-1, output.shape[2]))
# output shape == (batch_size, vocab)
x = self.fc(output)
return x, state, attention_weights4. Taxonomy of Attention
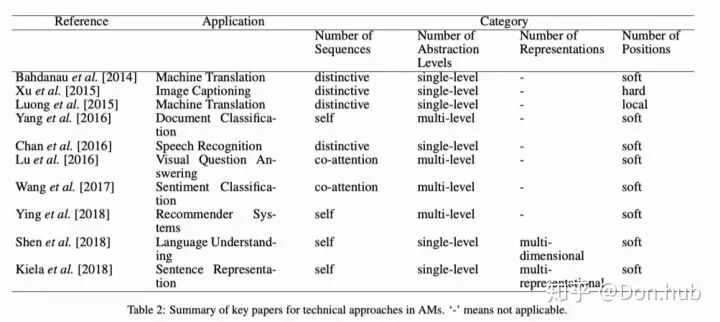
According to different classification criteria, attention can be divided into several categories, but specifically, it involves the interaction between q (query), k (key), and v (value). The calculation of score through q and k varies, as shown in the table below, followed by normalization through softmax. Finally, the calculated score is multiplied and summed with v (or argmax in the case of pointer networks).
Below is a summary table of several popular attention mechanisms and corresponding alignment score functions:

(*) Referred to as “concat” in Luong, et al., 2015 and as “additive attention” in Vaswani, et al., 2017. (^) It adds a scaling factor 1/n‾√1/n, motivated by the concern that when the input is large, the softmax function may have an extremely small gradient, making efficient learning difficult.
The following classifications are not mutually exclusive; for instance, the HAN model is a multi-level, soft attention model (AM).
4.1 Number of Sequence
Classified based on the source of our query and value.
4.1.1 Distinctive
In this case, the query and value come from two different input and output sequences, such as in NMT, where the query comes from the decoder’s hidden state and the value comes from the encoder’s hidden state.
4.1.2 Co-attention
The co-attention model jointly learns weights from multiple input sequences and captures the interactions among these inputs. For example, in visual question answering tasks, the authors argue that attention on the image is important, but attention on the question text is equally important, hence they adopt a joint learning approach to enable the model to simultaneously capture essential information from the question and the corresponding image.
4.1.3 Self
For example, in text classification or recommendation systems, our input is a sequence, and the output is not a sequence. In this scenario, each word in the text looks at the importance of related words within its own sequence. As shown in the figure.

We can take a look at the function description of BERT’s self-attention implementation, where if from tensor = to tensor, it is self-attention.
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
This is an implementation of multi-headed attention based on "Attention
is all you Need". If `from_tensor` and `to_tensor` are the **same**, then
this is self-attention. Each timestep in `from_tensor` attends to the
corresponding sequence in `to_tensor`, and returns a fixed-width vector
"""4.2 Number of Abstraction
This is classified based on the hierarchy of attention weight calculations.
4.2.1 Single-level
In the most common case, attention is calculated on the input sequence, which is ordinary single-level attention.
4.2.2 Multi-level
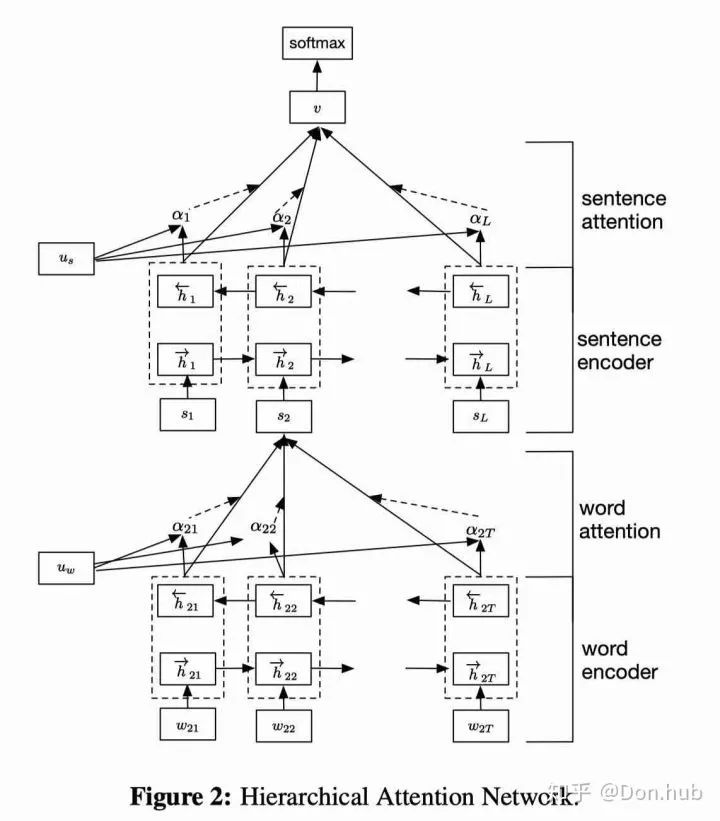
However, many models, such as HAN, have a hierarchical structure. The model primarily addresses document classification problems by proposing that documents consist of sentences, and sentences consist of words. Therefore, it builds a two-level encoder (bi-directional GRU) representation, where the lower encoder encodes words and the upper encoder encodes sentences. An attention layer is connected between the two encoders, focusing on the attention at the word level. Finally, when outputting for document classification, it also uses an attention layer at the sentence level, leading to a Dense output for sentence classification. Notably, the two queries and
are both randomly initialized and trained alongside the model, using the Dense method for the score calculation. However, unlike NMT, this is self-attention.
4.3 Number of Positions
Attention can be divided into three categories based on the positions of attention layers: global/soft (almost the same), local, and hard attention. Effective Approaches to Attention-based Neural Machine Translation proposed local global attention, while Show, Attend and Tell: Neural Image Caption Generation with Visual Attention proposed hard soft attention.
4.3.1 Soft/Global
Global/soft attention refers to attention being focused on all positions in the input sequence, which is beneficial for smooth differentiability but has the downside of high computational cost.
4.3.2 Hard
Hard attention calculates the context vector from sampled hidden states of the input sequence, effectively randomly selecting hidden states for attention calculation. This reduces computational cost but introduces the drawback of being non-differentiable, requiring reinforcement learning or other techniques like variational learning methods.
4.3.3 Local
Local attention is a compromise between hard and soft: it first identifies a point or position in the input sequence that requires attention, then selects a window size to create a local soft attention. This approach is beneficial as it is differentiable and reduces computational cost.
4.4 Number of Representations
Generally, single-representation is the most common scenario, meaning one input has only one feature representation. However, in other scenarios, one input may have multiple representations, which can be classified based on the representation method of the input.
4.4.1 Multi-representational
In some cases, a single feature representation is insufficient to capture all information of the input; input features can have multiple representations. For example, the paper Show, Attend and Tell: Neural Image Caption Generation with Visual Attention employed multiple word embedding representations for text input and finally summed the weights of these representations through attention. Similarly, a text input can have embeddings across dimensions of words, grammar, vision, and categories, with the final attention weights summing these representations.
4.4.2 Multi-dimensional
As the name implies, this type of attention relates to dimensions. The attention weights can determine the correlations between different dimensions in the input embedding vector. Essentially, the dimensions in embeddings can be seen as implicit feature representations (unlike explicit representations like one-hot, which are intuitive but lack interpretability), thus calculating the correlations between different dimensions can help identify the most influential feature dimensions. This method is particularly effective in resolving polysemy issues and is useful in sentence-level embedding representations and NLU.
5. Summary
6. Networks with Attention
Having introduced so many categories of attention, what networks are usually utilized with attention? Here we summarize two types of networks: one is encoder-decoder based, and the other is memory networks.
6.1 Encoder-Decoder
The encoder-decoder network with attention is the most common type of attention network, with NMT being the first to propose the concept of attention. The encoder and decoder can be flexibly altered and are not necessarily RNN structures.
6.1.1 CNN/RNN + RNN
For tasks like image-to-text, the encoder can be replaced with a CNN, while text-to-text tasks can use RNN + RNN.
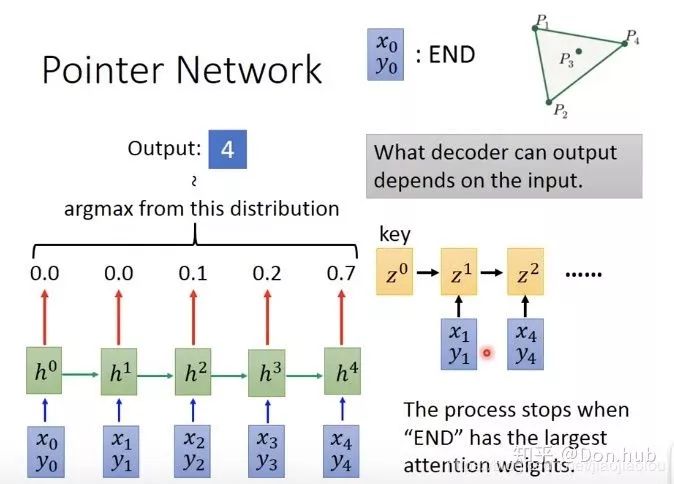
6.1.2 Pointer Networks
Not all sequence input and output problems can be solved using the encoder-decoder model (e.g., sorting or the traveling salesman problem). For instance, in the following problem: we want to find a set of points that can enclose all points in the figure. The expected outcome is to input all points and output
.
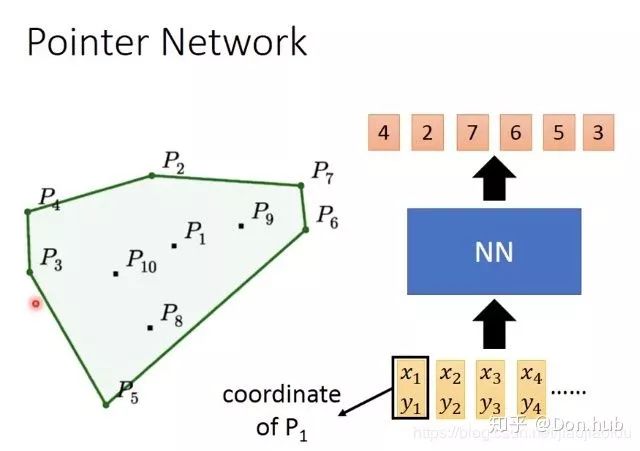
If we train directly, as shown in the figure: input the coordinates of 4 data points, obtain a red vector, then place the vector into the decoder to get a distribution, then sample (e.g., perform argmax to decide to output token 1…), and finally check if it works; the result is that it does not work. For example, during training, there are 50 points numbered 1-50, but during testing, there are 100 points, and it can only select points numbered 1-50, leaving the latter points unselectable.
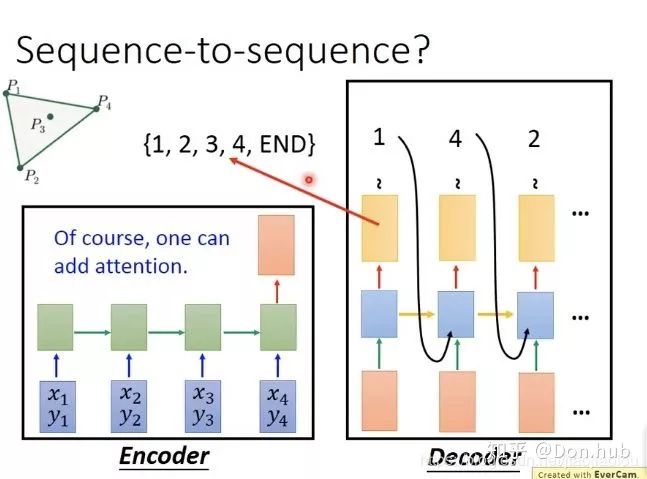
Improvements: Attention allows the network to dynamically decide how large the output set can be.
x0, y0 represent END words, and each input will receive an attention weight = output distribution.
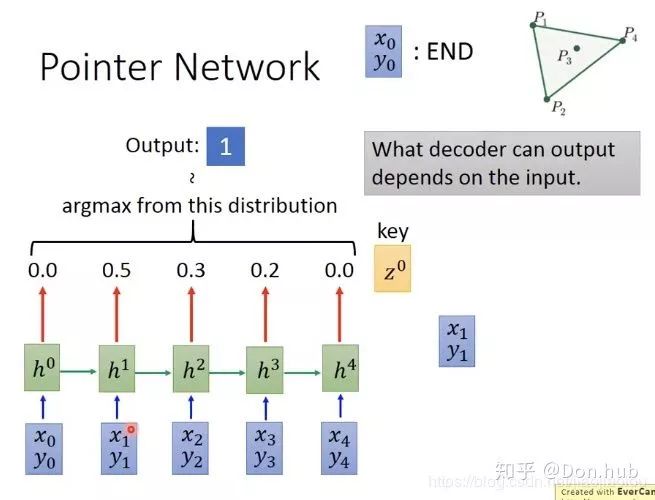
The final model’s termination condition is when has the highest probability.
6.1.3 Transformer
The transformer network employs an encoder + decoder architecture, primarily addressing the slow computation speed of RNNs by enhancing computational efficiency through parallel self-attention mechanisms. However, it also introduces the problem of high computational cost and space consumption, leading to limitations on sequence length; solutions can be found in transformerXL. (I will write an article about transformers later) – The role of multihead attention is akin to CNN kernels, mainly capturing different feature information.
6.2 Memory Networks
Applications such as question answering or chatbots require inputting a query and knowledge database. End-to-end memory networks store a knowledge database through an array of memory blocks, then use attention to match queries and answers. Memory networks consist of four components: the vector of the query (input), a series of trainable mapping matrices, attention weights, and multi-hop reasoning. This enables the use of facts from the knowledge base, key information from history, and essential information from the query for reasoning, which is crucial in QA and dialogue.
7. Applications
7.1 NLG
-
MT: Machine Translation
-
QA: Problems have utilized attention to (i) better understand questions by focusing on relevant parts of the question [Hermann et al., 2015], (ii) store large amounts of information using memory networks to assist in finding answers [Sukhbaatar et al., 2015], and (iii) improve performance in visual QA tasks by modeling multi-modality in input using co-attention [Lu et al., 2016].
-
Multimedia Description (MD): This task involves generating a natural language text description of a multimedia input sequence, which can be speech, image, or video [Cho et al., 2015]. Similar to QA, in this case, attention performs the function of finding relevant acoustic signals in speech input [Chorowski et al., 2015] or relevant parts of the input image [Xu et al., 2015] to predict the next word in the caption. Furthermore, Li et al. [2017] exploit the temporal and spatial structures of videos using multi-level attention for video captioning tasks. The lower abstraction level extracts specific regions within a frame, while the higher abstraction level focuses on a small subset of frames selectively.
7.2 Classification
-
Document Classification: HAN
-
Sentiment Analysis: Similarly, in sentiment analysis tasks, self-attention helps to focus on the words that are important for determining the sentiment of the input. Several approaches for aspect-based sentiment classification by Wang et al. [2016] and Ma et al. [2018] incorporate additional knowledge of aspect-related concepts into the model and use attention to appropriately weigh these concepts apart from the content itself. Sentiment analysis applications have also seen multiple architectures used with attention, such as memory networks [Tang et al., 2016] and Transformer [Ambartsoumian and Popowich, 2018; Song et al., 2019].
7.3 Recommendation Systems
Multiple papers utilize self-attention mechanisms to identify the most relevant items in a user’s history to enhance item recommendations, either within collaborative filtering frameworks [He et al., 2018; Shuai Yu, 2019] or in an encoder-decoder architecture for sequential recommendations [Kang and McAuley, 2018; Zhou et al., 2018].
Recently, attention has been employed in novel ways, opening new avenues for research. Some interesting directions include smoother incorporation of external knowledge bases, pre-training embeddings, multi-task learning, unsupervised representational learning, sparsity learning, and prototypical learning, i.e., sample selection.
8. References
-
The writing style is excellent; the section on the final model could be further elaborated in this article.
-
A very good overview: An Attentive Survey of Attention Models
-
wildml.com/2016/01/atte
-
A detailed graphical explanation of NMT (there’s a slight error in the decoder section as the embedding initialization is likely defined differently, and the initialized context vector is used as the attention score’s key, actually concatenating context and embedding as input).
-
NMT Code
-
Pointer Network
-
Pointer Slides
-
All Attention You Need is not yet finished.
Recommended Reading:
In-depth Analysis of LSTM Neural Network Design Principles
Complete Guide for Beginners on Graph Convolutional Networks (GCN)
Paper Review [ACL18] Component-based Syntactic Parsing Based on Self-Attentive Mechanisms
