Click the “AI Park” above to follow the public account and choose to add “Star Mark” or “Top”.
Author: Raimi Karim
Translator: ronghuaiyang
Previously, I shared several articles on attention, feeling unsatisfied. This time, I will explain the Attention mechanism using GIFs, making it easy to understand, and explain how it is used in machine translation scenarios like Google Translate.
For decades, statistical machine translation has been the dominant translation model until the advent of Neural Machine Translation (NMT). NMT is an emerging machine translation method that attempts to build and train a single large neural network to read input text and output the corresponding translation.
The pioneers of NMT are Kalchbrenner and Blunsom (2013), Sutskever et. al (2014), and Cho. et. al (2014b), among which the most familiar framework is the sequence-to-sequence (seq2seq) model from Sutskever et. al. This article will be based on the seq2seq framework and describe how to build the attention mechanism on this basis.
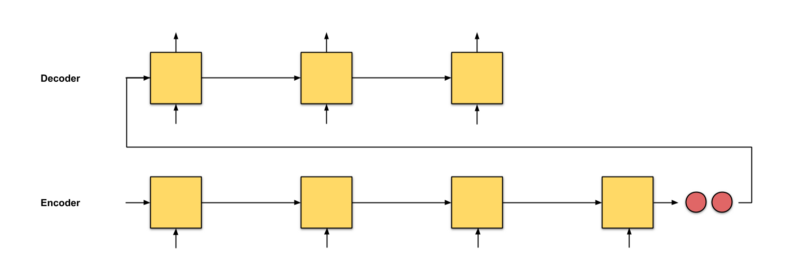
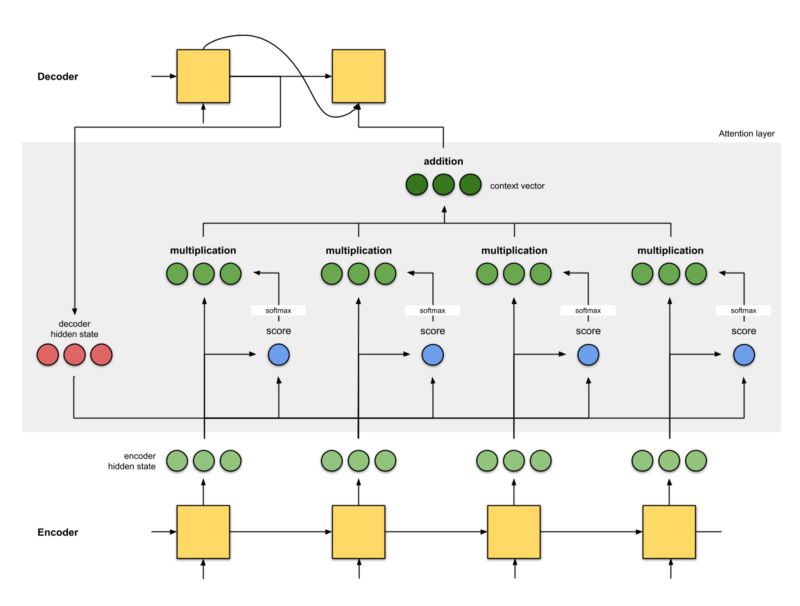
The idea of seq2seq is to have two recurrent neural networks (RNNs) using an encoder-decoder architecture: one reads the input words one by one to get a fixed-dimensional vector representation (encoder), and using these inputs as conditions, the other RNN decoder outputs the words one by one.

The problem with seq2seq is that the only information the decoder receives from the encoder is the final hidden state of the encoder (the two red nodes in Fig 0.1), which is a vector representation, similar to a numerical summary of the input sequence. Therefore, expecting the decoder to use this one vector representation (hoping it “sufficiently describes the input sequence”) to output the translation for long input texts (Fig 0.2) is unrealistic. This can lead to catastrophic forgetting. This section has 100 words. Can you translate this paragraph into another language you know after the question mark?
If we cannot do this, then we should not be so cruel to the decoder. So, what if we not only provide one vector representation but also give the decoder a vector representation from each encoder time step, allowing it to make translations with sufficient information? What do you think of this idea? Let’s move on to the attention mechanism.
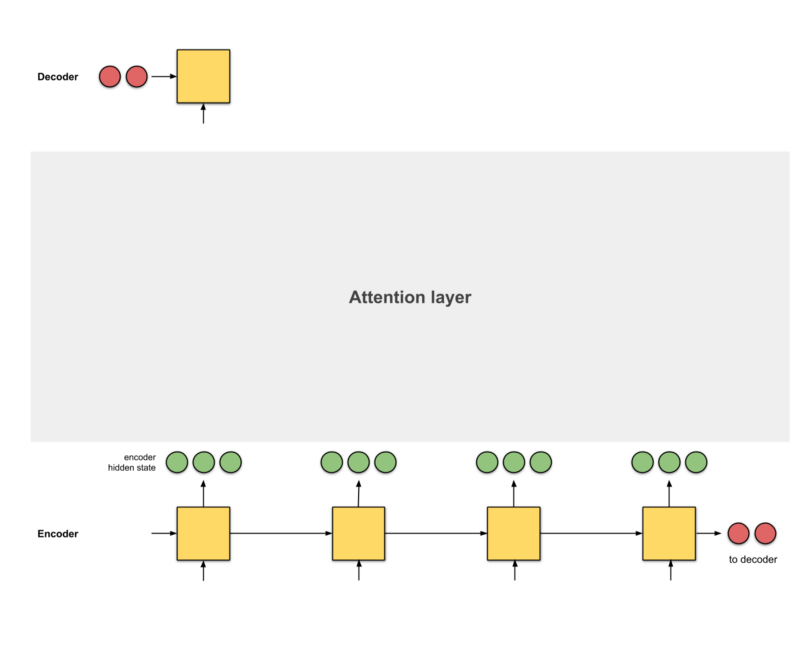
The attention mechanism is the interface between the encoder and decoder, providing the decoder with information from each encoder hidden state (excluding the red hidden states in Fig 0.3). With this setup, the model can selectively focus on useful parts of the input sequence, learning the “alignment” between them. This helps the model effectively handle long input sentences.
Definition: Alignment
Alignment refers to matching segments of the original text with their corresponding segments in the translation.
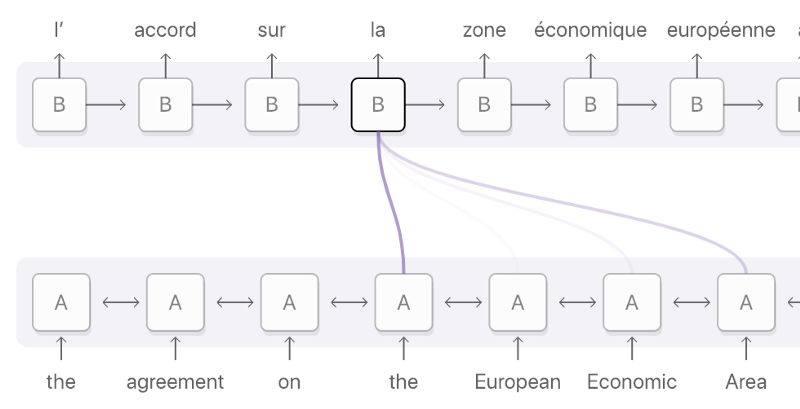
There are two types of attention, the type that uses all encoder hidden states is also known as “global attention”. In contrast, “local attention” only uses a subset of encoder hidden states. Since the scope of this article is global attention, the term “attention” mentioned in this article is considered as “global attention”.
This article uses animations to describe how attention works, so we can understand without mathematical symbols. For example, I will share four NMT architectures designed in the past five years. I will also include some intuitions about certain concepts in this article, so please pay attention to them!
1. Attention: Overview
Before we understand how attention is used, allow me to share with you the intuition behind using the seq2seq model for translation tasks.
Intuition: seq2seq
The translator reads the German text from start to finish. Once done, he begins to translate it word by word into English. If the sentence is very long, he is likely to have forgotten what he read earlier.
This is a simple seq2seq model. The attention layer’s step-by-step computation I will perform is a seq2seq + attention model. Here is a quick intuition about this model.
Intuition: seq2seq + attention
The translator writes down keywords while reading the German text from start to finish, then begins to translate it into English. When translating each German word, he uses the keywords he wrote down.
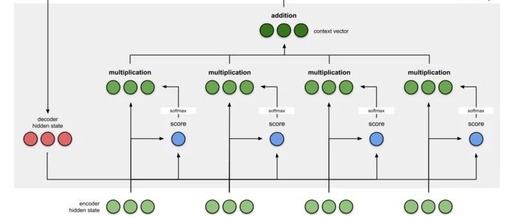
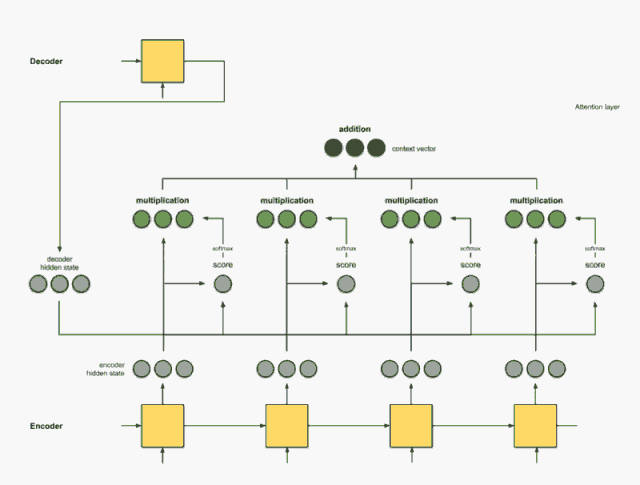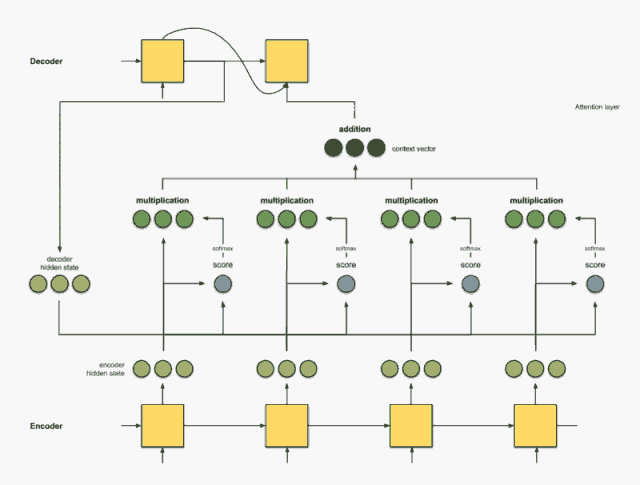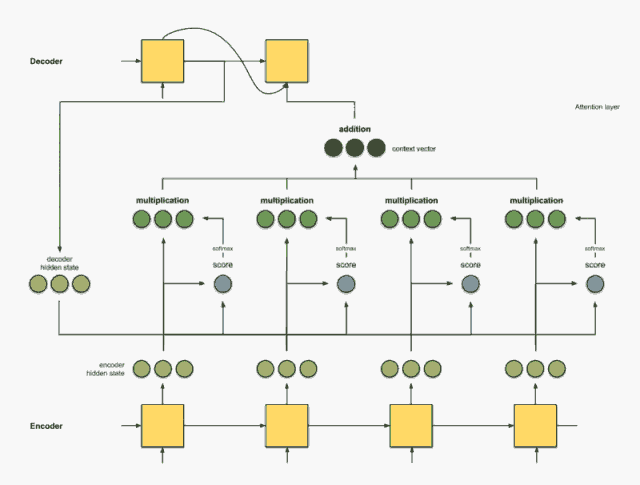
Attention focuses on different words, scoring each word. Then, after using softmax on the scores, we aggregate the encoder hidden states using a weighted sum to obtain the context vector. The implementation of the attention layer can be divided into four steps.
Step 0: Prepare hidden states.
We first prepare the hidden state of the first decoder (red) and all available encoder hidden states (green). In our example, we have four encoder hidden states and the current decoder hidden state.

Step 1: Get the score for each encoder hidden state.
The score (scalar) is obtained by the score function (also known as the alignment score function or alignment model). In this case, the score function is the dot product between the decoder and encoder hidden states.
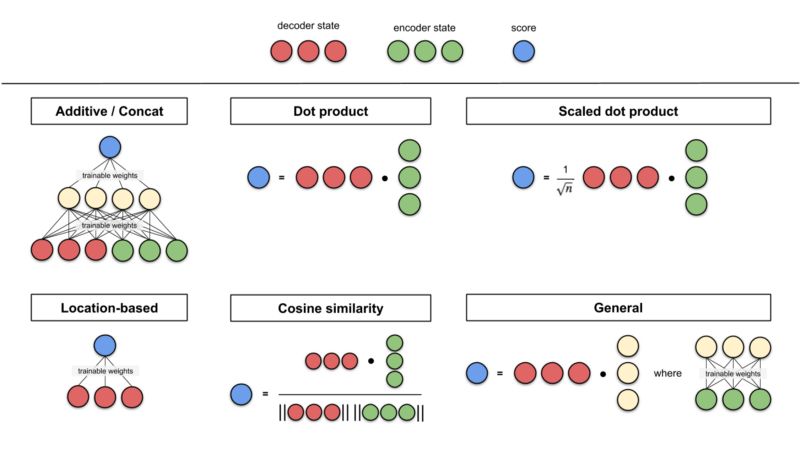
Please refer to Appendix A for various score functions.
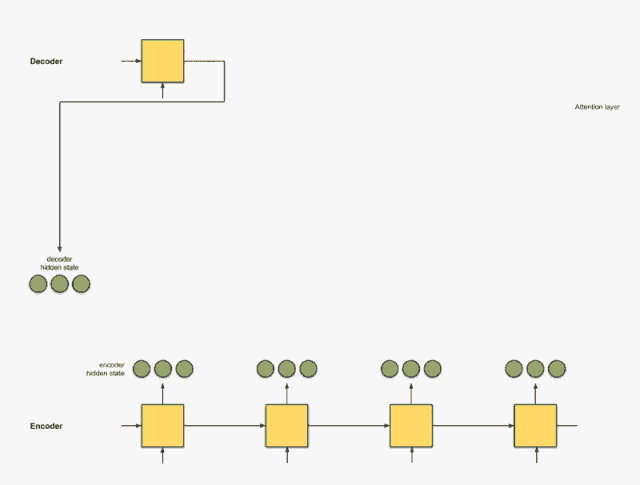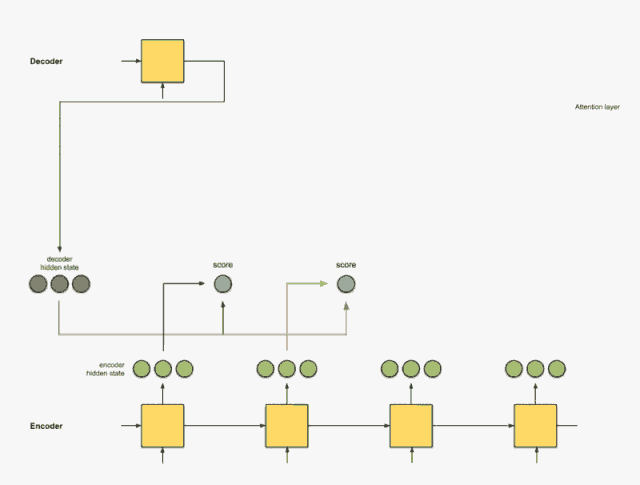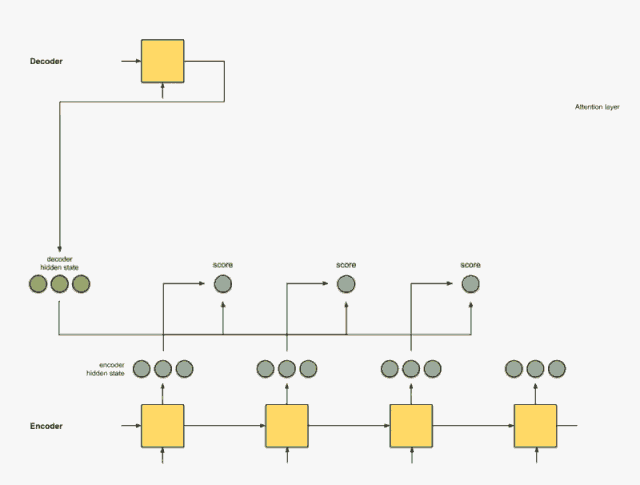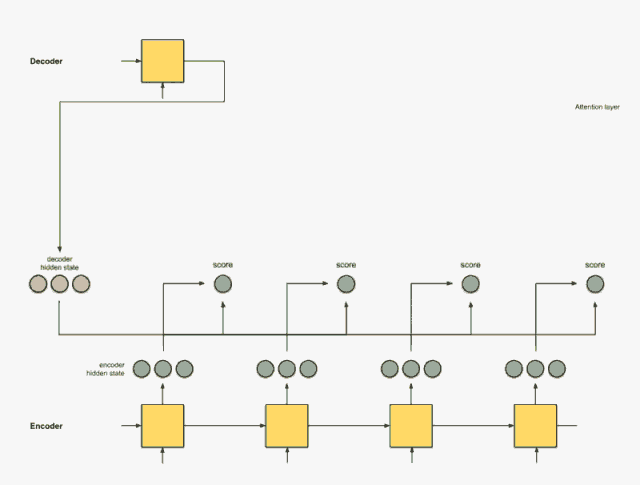
decoder_hidden = [10, 5, 10] encoder_hidden score --------------------- [0, 1, 1] 15 (= 10×0 + 5×1 + 10×1, the dot product) [5, 0, 1] 60 [1, 1, 0] 15 [0, 5, 1] 35In the above example, for the encoder hidden state [5, 0, 1], we obtained a high attention score of 60. This means the next word to be translated will be greatly influenced by this encoder hidden state.
Step 2: Send all scores to the softmax layer.
We send the scores to the softmax layer, so that the scores after softmax (scalar) sum to 1. These softmax scores represent the attention distribution.
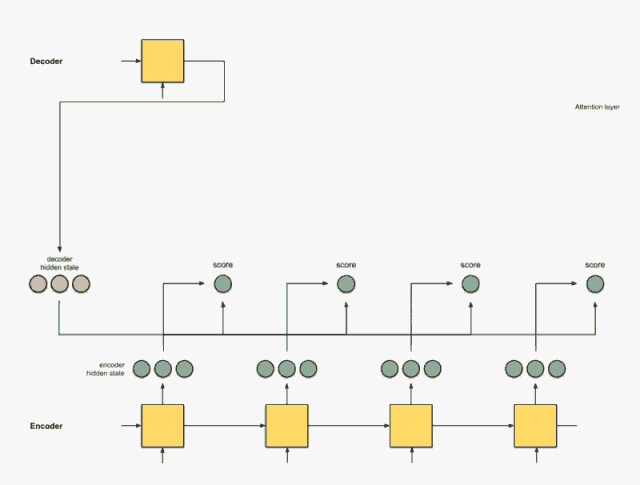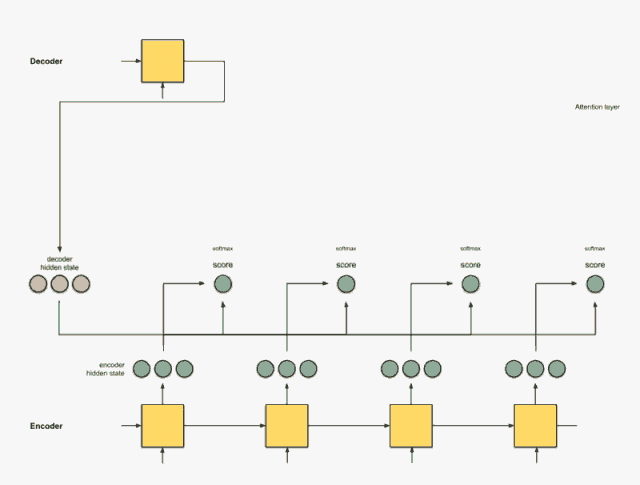
encoder_hidden score score^ ----------------------------- [0, 1, 1] 15 0 [5, 0, 1] 60 1 [1, 1, 0] 15 0 [0, 5, 1] 35 0Note that based on the scores after softmax score^, the attention distribution is placed as expected on [5, 0, 1]. In fact, these numbers are not binary but a floating-point number between 0 and 1.
Step 3: Multiply each encoder hidden state by the scores after softmax.
By multiplying each encoder hidden state by its softmax score (scalar), we obtain the alignment vector or annotation vector. This is the mechanism produced by alignment.
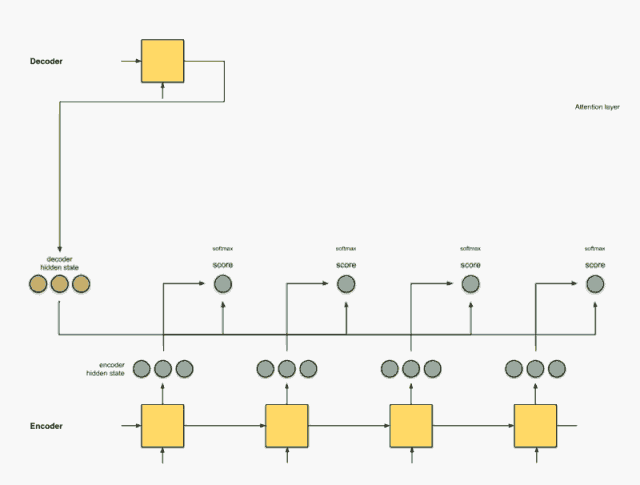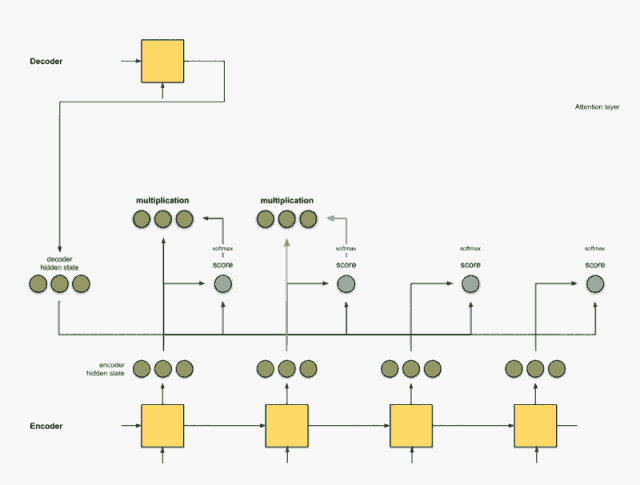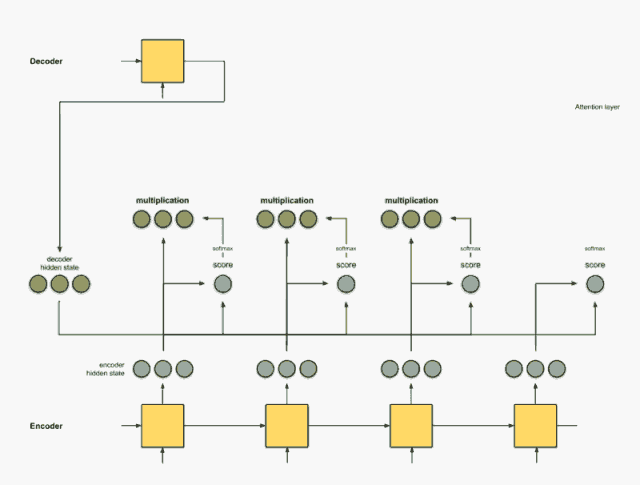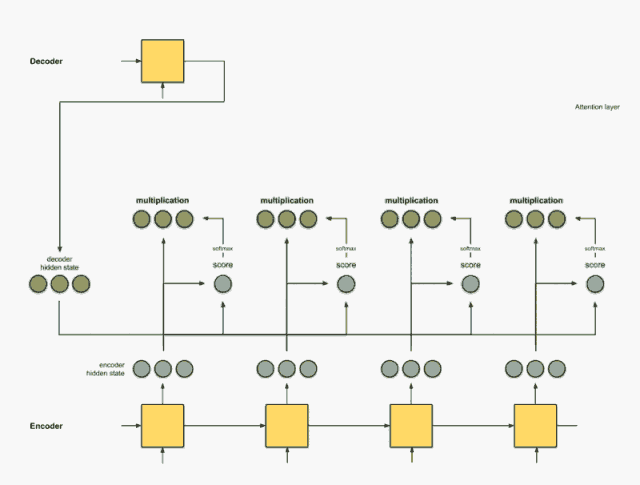
encoder score score^ alignment ---------------------------------[0, 1, 1] 15 0 [0, 0, 0] [5, 0, 1] 60 1 [5, 0, 1] [1, 1, 0] 15 0 [0, 0, 0] [0, 5, 1] 35 0 [0, 0, 0]Here, we see that all encoder hidden states’ alignments are reduced to 0 except for [5, 0, 1], due to the low attention score. This means we can expect that the first word to be translated should match the word represented by the embedding of [5, 0, 1].
Step 4: Add all alignment vectors together.
Summing the alignment vectors generates the context vector. The context vector is the aggregated information from the alignment vectors from the previous step.
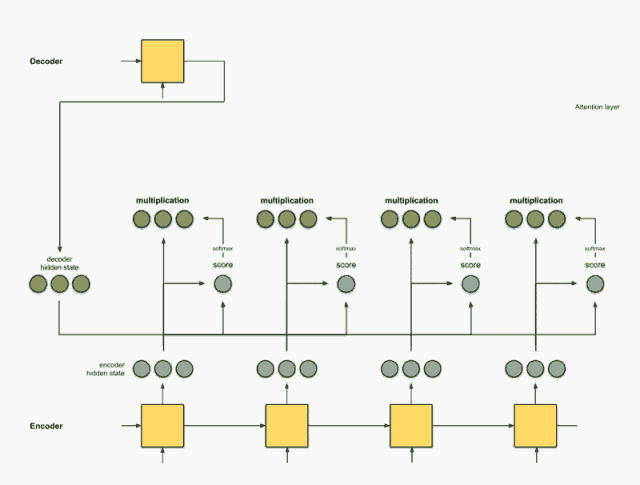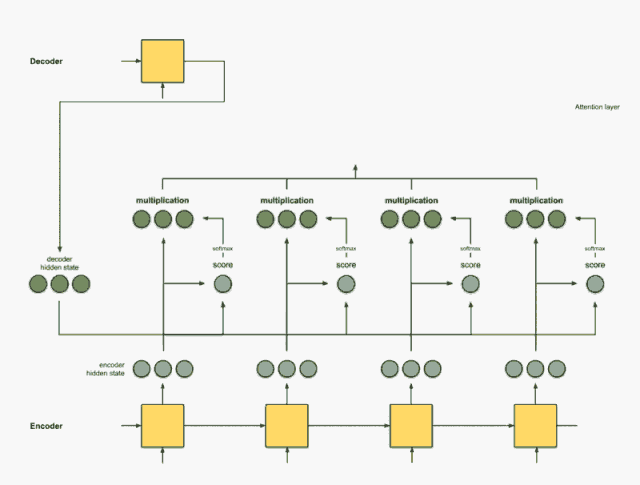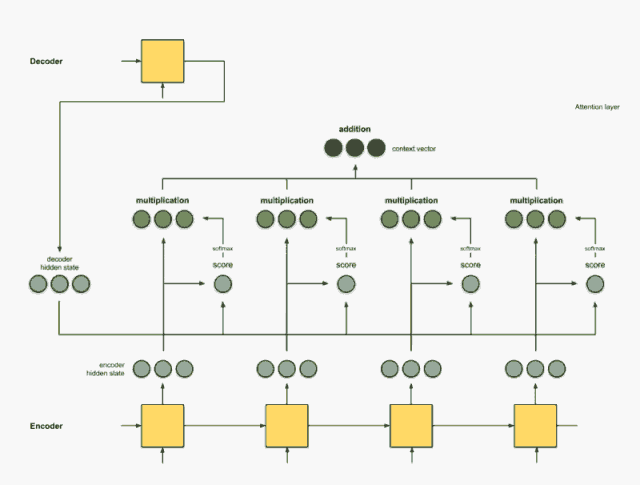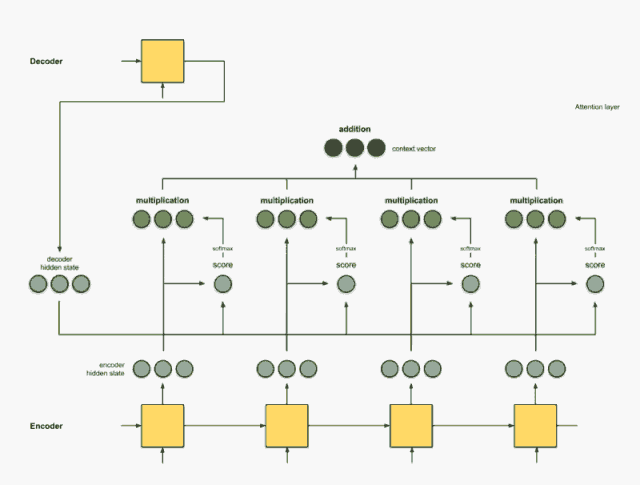
encoder score score^ alignment ---------------------------------[0, 1, 1] 15 0 [0, 0, 0] [5, 0, 1] 60 1 [5, 0, 1] [1, 1, 0] 15 0 [0, 0, 0] [0, 5, 1] 35 0 [0, 0, 0] context = [0+5+0+0, 0+0+0+0, 0+1+0+0] = [5, 0, 1]Step 5: Send the context vector to the decoder.
This depends on the architectural design. Later, we will see how the architecture uses the context vector as the decoder in examples in sections 2a, 2b, and 2c.
That’s it, this is the complete animation:

Intuition: How does attention work?
The answer: Backpropagation, surprising, right? Backpropagation will do everything possible to ensure the output is close to the ground truth. This is achieved by changing the weights in the RNNs and the score function (if any). These weights will affect the encoder hidden states and the decoder hidden states, thereby affecting the attention scores.
2. Attention: Examples
In the previous section, we have seen the seq2seq and seq2seq + attention architectures. In the next subsection, let’s examine three other seq2seq-based NMT architectures that implement attention. For completeness, I have also attached their Bilingual Evaluation Understudy (BLEU) scores, which are a standard measure of the quality of generated sentences compared to reference sentences.
2a. Bahdanau et. al (2015)
Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et. al, 2015)
This implementation of attention is one of the founders of attention. The authors used the word align in the title of their paper “Neural Machine Translation by Learning to Jointly Align and Translate”, meaning adjusting the weights directly responsible for the scores while training the model. Here are some points to note about this architecture:
-
The encoder is a bidirectional (forward + backward) gated recurrent unit (BiGRU). The decoder is a GRU whose initial hidden state is derived from the last hidden state of the backward encoder GRU (not shown in the figure below).
-
The score function in the attention layer is additive/concat.
-
The input to the next decoder time step is the concatenation of the output from the previous decoder time step (pink) and the context vector for the current time step (dark green).
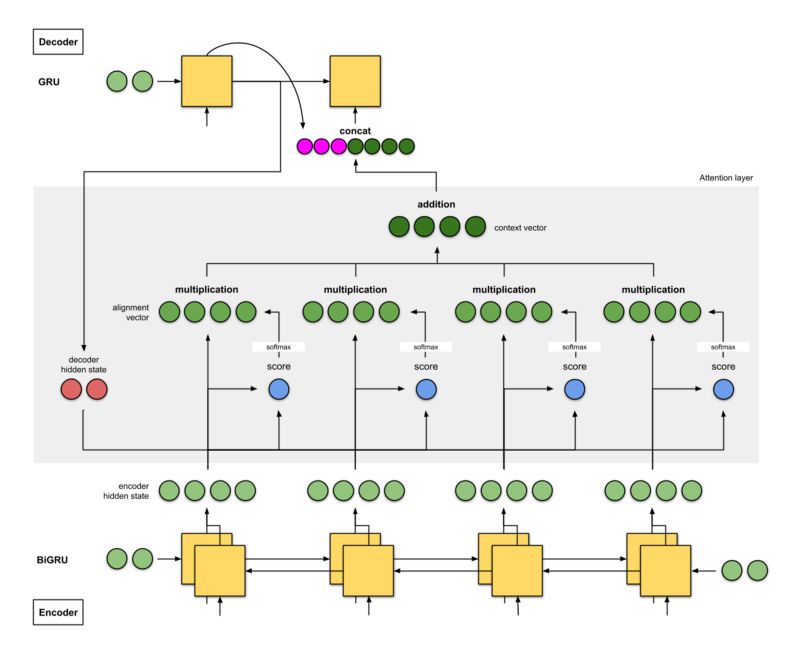
The authors achieved a 26.75 BLEU score on the WMT ’14 English-to-French dataset.
Intuition: seq2seq with bidirectional encoder + attention
Translator A writes down keywords while reading the German text. Translator B (who holds a senior position due to his extra ability to read a sentence from back to front) reads the same German text from the last word to the first while noting down keywords. These two regularly discuss every word they have read so far. After reading the German text, Translator B’s task is to translate the German sentence word by word into English based on the keywords selected by both.
Translator A is the forward RNN, Translator B is the backward RNN.
2b. Luong et. al (2015)
Effective Approaches to Attention-based Neural Machine Translation (Luong et. al, 2015)
The authors of “Effective Approaches to Attention-based Neural Machine Translation” point out that it is crucial to simplify and generalize the architecture of Bahdanau et. al. The approaches are as follows:
-
The encoder is a two-layer long short-term memory (LSTM) network. The decoder also has the same structure, with its initial hidden state being the last hidden state of the encoder.
-
The score functions they experimented with are (i) additive/concat, (ii) dot product, (iii) location-based, and (iv) “general”.
-
The output of the current decoder time step is concatenated with the context vector for the current time step and fed into the forward neural network to obtain the final output of the current decoder time step (pink).
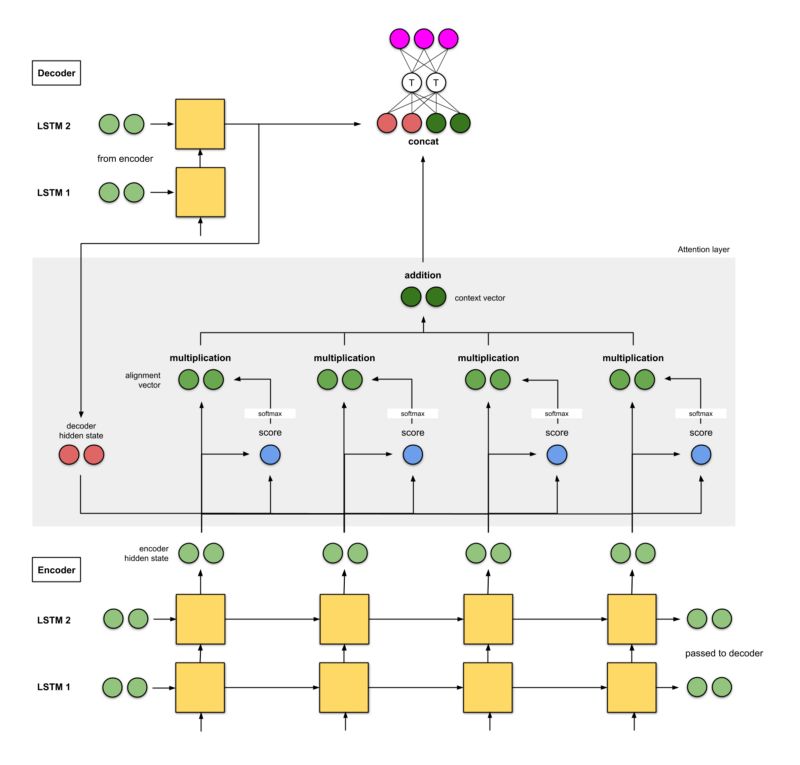
They achieved a 25.9 BLEU score on the WMT ’15 English-to-German dataset.
Intuition: seq2seq with 2-layer encoder + attention
Translator A writes down keywords while reading the German text. Similarly, Translator B (more experienced than Translator A) also notes down keywords while reading the same German text. Note that the junior translator A must report every word they read to Translator B. Once they finish reading, they translate the sentence into English word by word based on the keywords they have gathered.
2c. Google’s Neural Machine Translation (GNMT)
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation (Wu et. al, 2016)
Since most of us have certainly used Google Translate in one way or another, I feel it is necessary to talk about the NMT that Google achieved in 2016. GNMT is a combination of the previous two examples (heavily inspired by the first example).
-
The encoder consists of 8 LSTMs, where the first LSTM is bidirectional (its output is concatenated), and there are residual connections between the outputs from consecutive layers (starting from the 3rd layer). The decoder is a stack of 8 unidirectional LSTMs.
-
The score function used is additive/concat, similar to the first example.
-
Similarly, as in the first example, the input to the next decoder time step is the concatenation of the output from the previous decoder time step (pink) and the context vector for the current time step (dark green).
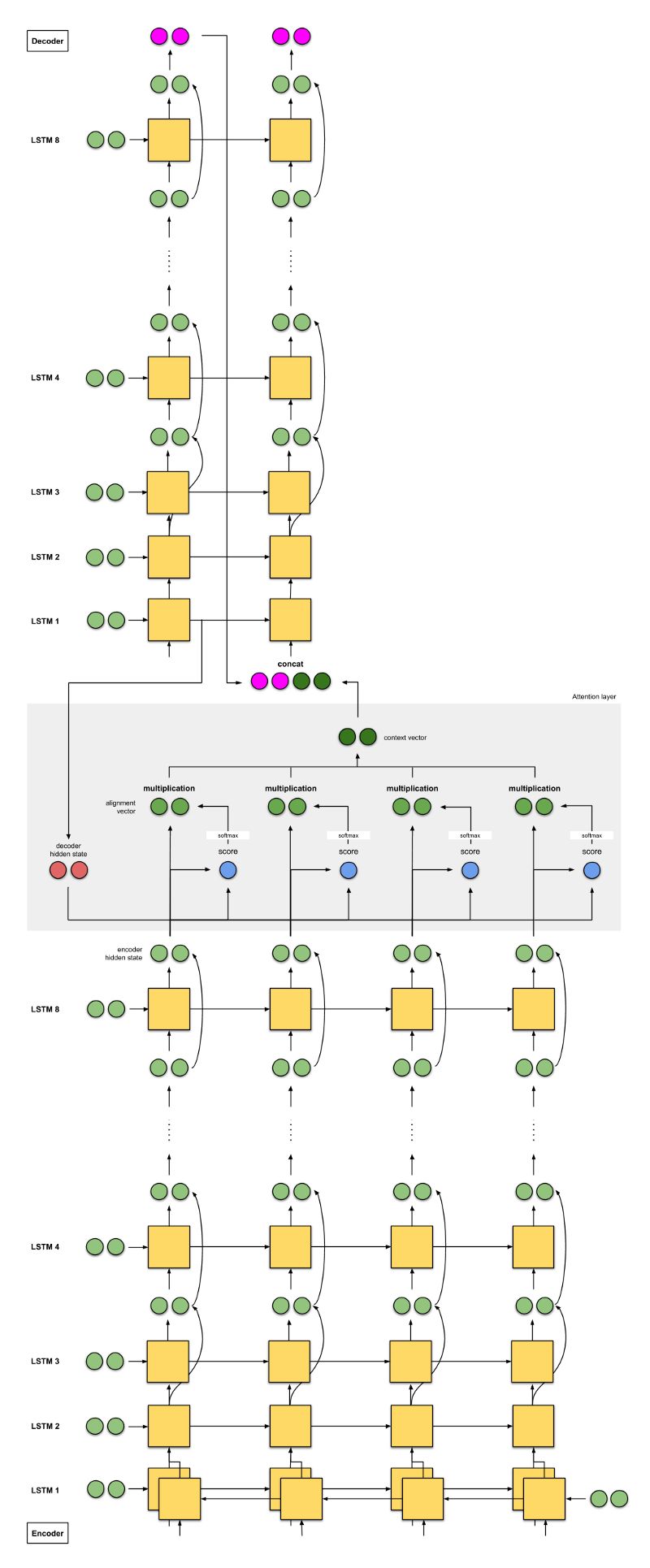
The model achieved a 38.95 BLEU score on WMT ’14 English-to-French and a 24.17 BLEU score on WMT ’14 English-to-German.
Intuition: GNMT — seq2seq with 8-stacked encoder (+bidirection + residual connections) + attention
8 translators sit in a column from bottom to top, starting with Translator A, B, …, H. Each translator reads the same German text. For each word, Translator A and Translator B share their findings, then Translator B improves this finding and shares it with Translator C, repeating this process until it reaches Translator H. Additionally, while reading the German text, Translator H writes down relevant keywords based on what he knows and the information he receives.
Once everyone has finished reading the German text, Translator A is asked to translate the first word. He first tries to recall, then shares his answer with Translator B, who improves the answer and shares it with Translator C—repeating this process until it reaches Translator H. Translator H writes down the first translated word based on the keywords he has written and the answers he has received. This step is repeated until we get the translation.
3. Summary
Here is a quick summary of all architectures you have seen in this article:
-
seq2seq + attention
-
seq2seq with bidirectional encoder + attention
-
seq2seq with 2-stacked encoder + attention
-
GNMT — seq2seq with 8-stacked encoder (+bidirection + residual connections) + attention
That’s all! In the next article, I will introduce the concept of self-attention and its application in Google’s Transformer and Self-Attention Generative Adversarial Networks (SAGAN).
Appendix: Score Functions
Below are some score functions edited by Lilian Weng. In this article, Additive/concat and dot product are mentioned. The score functions involve dot product operations (dot product, cosine similarity, etc.), where the idea is to measure the similarity between two vectors. For feedforward neural network score functions, the idea is to allow the model to learn alignment weights while transforming.


Original English text:https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3

Please long press or scan the QR code to follow this public account