

Author | Litchi Boy
Editor | Panshi
Produced by | Panshi AI Technology Team
[Panshi AI Introduction]: In previous articles, we introduced some machine learning, deep learning beginner resource collections. This article continues the principles and practical applications of training word vectors based on Word2Vec, also by the expert Litchi Boy. If you like our articles, please follow our official account: Panshi AI. Additionally, if you have any feedback or shortcomings in our articles, feel free to leave a comment at the end.
Table of Contents
-
Disadvantages of Word2Vec Model Based on Hierarchical Softmax
-
Negative Sampling Model
-
Principle of Negative Sampling Optimization
-
Principle of Selecting Negative Example Words in Negative Sampling
-
Code Implementation
-
Conclusion
1. Disadvantages of Word2Vec Model Based on Hierarchical Softmax
In the previous article, we discussed Hierarchical Softmax, which uses a Huffman tree structure instead of a traditional neural network to improve model training efficiency. However, in a model based on Hierarchical Softmax, the positions of all words are placed in a Huffman tree structure based on word frequency, with higher frequency words closer to the root node and lower frequency words farther away. This means that when the model trains on rare words, it must traverse a deeper path through more nodes to reach the leaf node of the rare word, resulting in more θ_i vectors needing to be updated during training. For example, as shown in Figure 1:
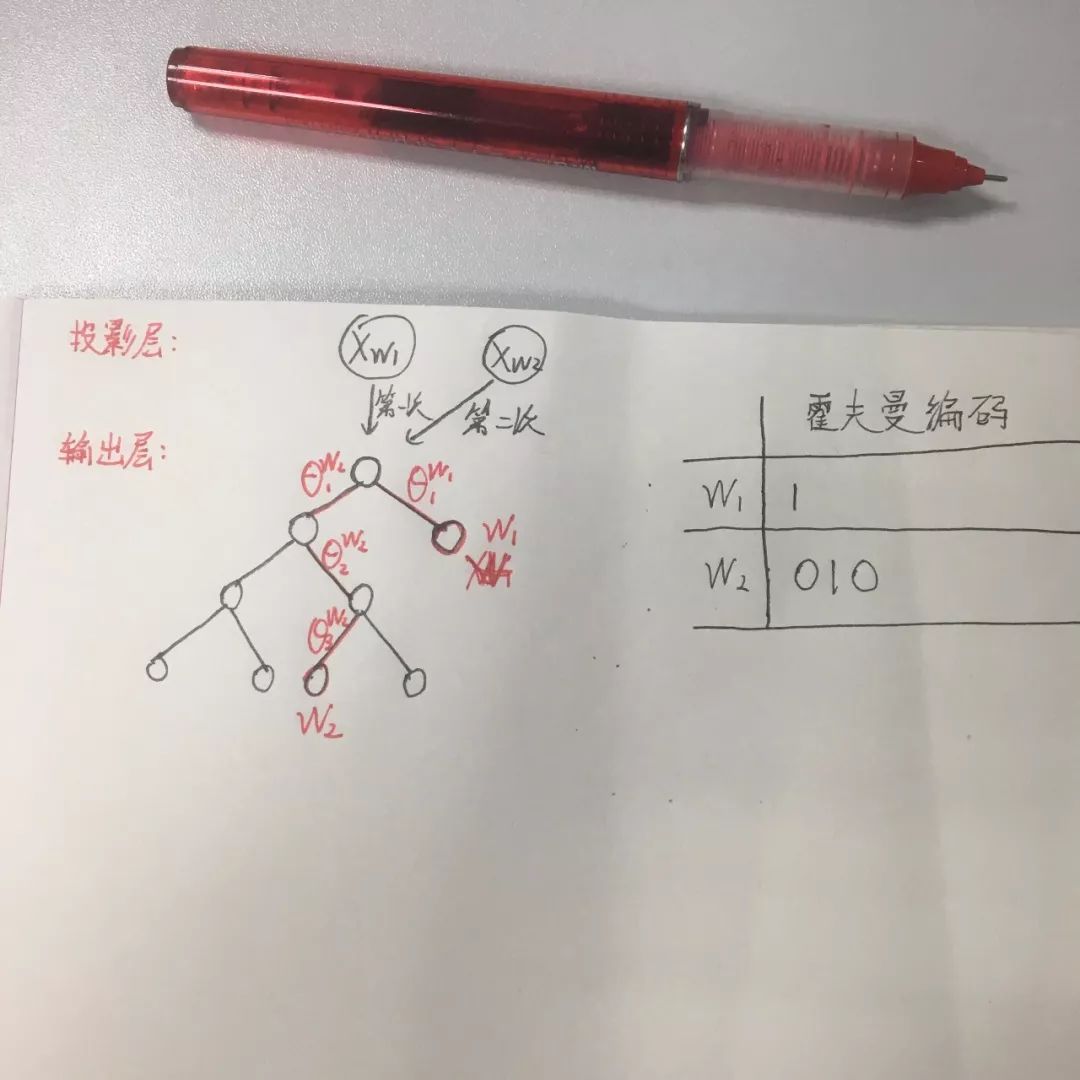
Figure 1
Suppose the Huffman tree encoding is defined such that left subtree encoding is 0 and right subtree encoding is 1. If there is a Huffman tree where the first layer right subtree is a leaf node word w_1, whose Huffman encoding is 1, then during training, only θ_1 needs to be updated, requiring minimal computational effort. However, if there is a deeply nested leaf node at the fifth layer, word w_2 (root node at layer 0), with Huffman encoding 010, training to this leaf node requires calculating and updating three θ_i parameters. Thus, this is not friendly for training rare words.
2. Negative Sampling Model
Negative Sampling is another method for the Word2Vec model, utilizing Negative Sampling to solve the problem.
The network structure of Negative Sampling (trained using CBOW) is shown in Figure 2:
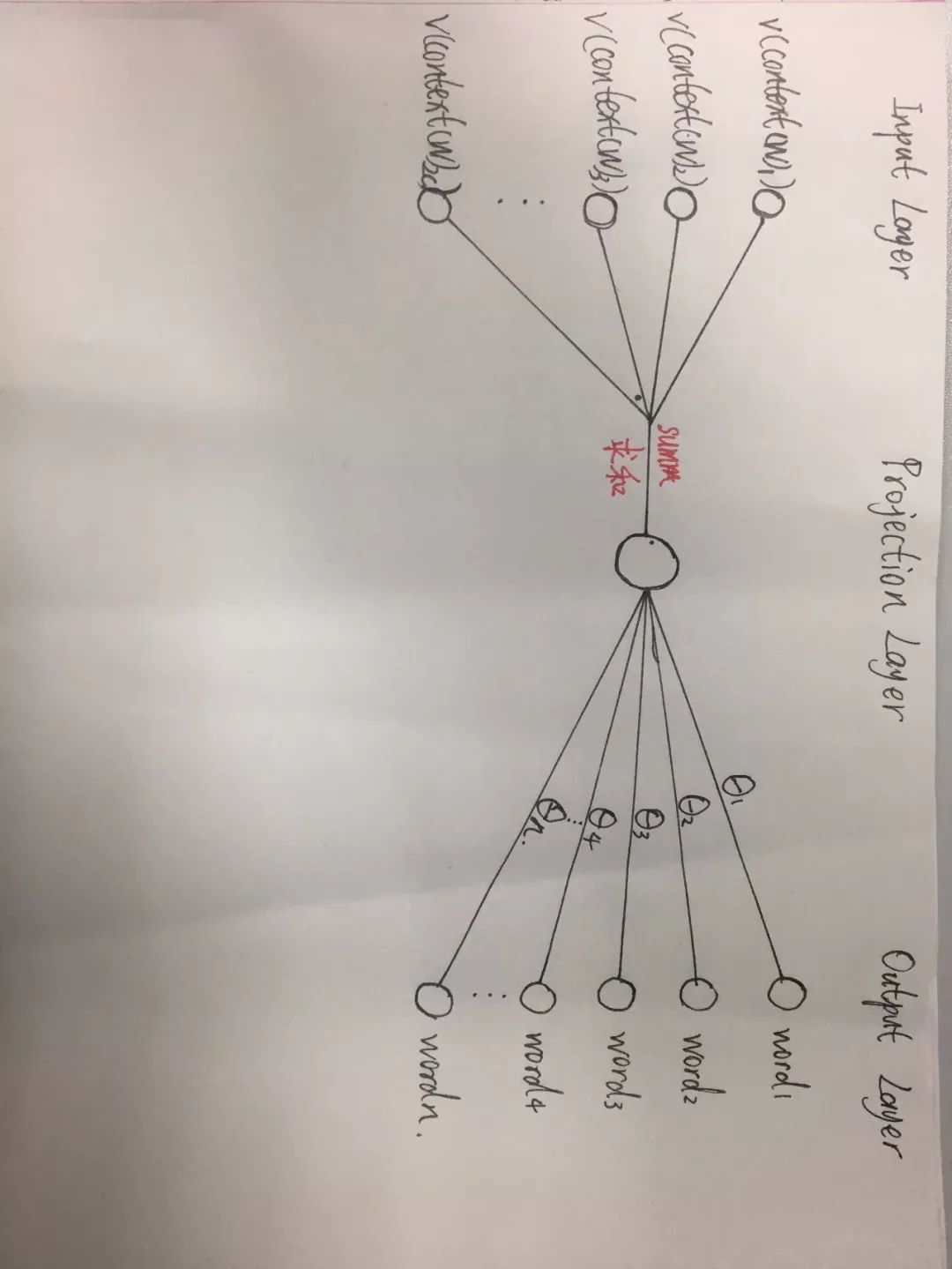
Figure 2
The main difference between Negative Sampling and Hierarchical Softmax is that it abandons the Huffman tree structure from the projection layer to the output layer. Taking the CBOW model training as an example, Negative Sampling selects a center word w_0 each time, and if neg other words w_i, i=1,2,3…neg (generally, neg is a small value, not exceeding 10), along with the 2c context words, denoted as context(W). The center word is related to context (w_0), so using context (w_0) as input, the center word w as output is a positive example. Meanwhile, context (w_0) as input, along with each w_i that is not genuinely related to the input, forms neg negative examples. A total of neg+1 training samples are used for training, and this training method is called Negative Sampling. By using one positive example and neg negative examples for binary logistic regression, each iteration updates θ_i (i=0,1,2…neg) and context(w), resulting in each word’s corresponding θ_i vector and word vector.
Negative Sampling selects the center word based on the center word’s context and negative example words:
Assuming we have a vocabulary that includes: Beijing Shanghai Guangzhou Shenzhen Chaoshan beef meatball is delicious windy sunshine computer … and so on, where “Chaoshan beef meatball is delicious” is a sentence. We select “meatball” as the center word w_0, then the context context(w_0) is [Chaoshan, beef, is, delicious]. Assuming we select two negative example words, Shanghai and sunshine as w_1, w_2. Then (context(w_0), w_0) is a positive example, while (context(w_0), w_1) and (context(w_0), w_2) are the two negative examples.Training this one positive example and two negative examples, updatesw_0, w_1, w_2 corresponding parameters θ_w and context(w_0) with the context word vectors. As shown in Figure 3:

Figure 3
The training process in the example is shown in Figure 4:
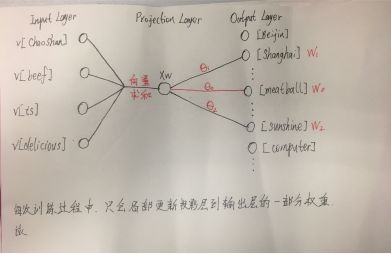
Figure 4
During one iteration of training, the input isContext(w_0), output isw_0 (positive example), w_1, w_2. Gradually update θ_1, θ_2, θ_3 and the word vectors corresponding to [Chaoshan], [beef], [is], [delicious] using gradient ascent method. Note that here, θ_i is similar to that in Hierarchical Softmax, only representing the weights from the projection layer to the output layer, not the word vectors.
3. Principle of Negative Sampling Optimization
Given a training sample, a word w and its context Context(w), (Context(w), w) serves as a positive example. By negative sampling, we select other words from the vocabulary as negative outputs, (Context(w), w_i) as neg negative examples, forming the negative example set NEG(w). For positive and negative samples, we assign a label to each:
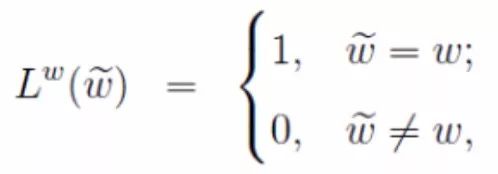
Formula 1
For the given positive sample (Context(w), w), we aim to maximize the likelihood function for the current positive sample {w} and neg negative samples NEG(w):
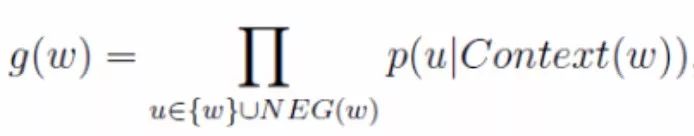
Formula 2
Where p(u|Context(w)) represents the probability of the positive word w + one of the negative words NEG(W):
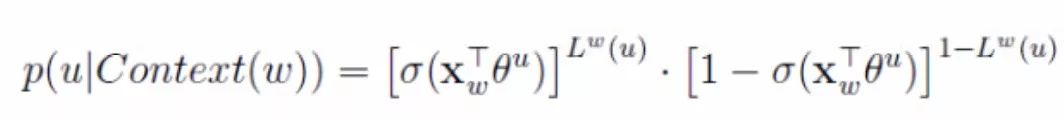
Formula 3
In other words, by using the sigmoid function to calculate the probability of each sample, we aim to maximize the probability of the positive example w while minimizing that of the negative examples. Transforming g(w) into a log-likelihood function, and using gradient ascent method, each iteration updates the word vectors corresponding to the context words in context(w) and θ_i. The update principle is the same as that of the previous article’s Hierarchical Softmax principle, so we will not repeat the derivation here.
The pseudocode for training based on CBOW using Negative Sampling is shown in Figure 5:

Figure 5
First, randomly initialize the word vectors for all vocabulary and θ_i. In one iteration, after summing and averaging the context word vectors context(w), we start updating θ_i and the context word vectors corresponding to context(w) using gradient ascent method for the center word w and negative example words NEG(w).
4. Principle of Selecting Negative Example Words in Negative Sampling
Now that we have discussed the reasoning behind the Negative Sampling training process, let’s address the final question: how to select negative example words to obtain neg negative examples. We believe that words with higher frequency should have a higher probability of being sampled. Therefore, we randomly select words based on their frequency, placing all words on a line segment of length 1 according to their frequency:
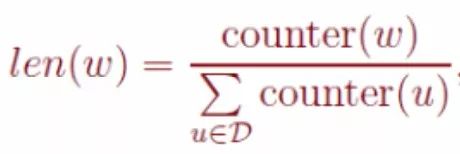
Formula 4
Where counter(w) is the word frequency of w.
Thus, we fairly place words of different frequencies on a line segment of length 1, as shown in Figure 5:
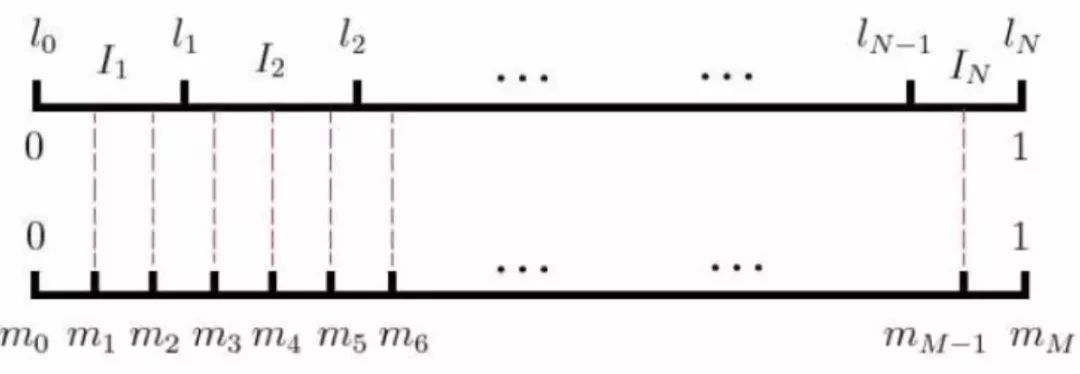
Figure 6
In Word2Vec, we extend this line segment of length 1 to length M, where the segments between the scales are evenly spaced, i.e., 1/M:

Figure 7
Now, by generating a random integer between 0 and M, we can select the corresponding I_i word. Each time we select neg words, if the negative example word happens to be the center word w itself, we skip it and generate a new random number between 0 and M to find a new negative example word.
5. Code Implementation
Using the gensim package in Python to call Word2Vec is convenient and quick. Below is a brief demonstration; detailed parameters of gensim’s Word2Vec are not elaborated here. The data used this time is from a publicly available tourism dataset from a previous competition. The specific steps for Word2Vec training of word vectors are as follows:
1) Import necessary packages, where jieba is used for text segmentation.
2) Import the dataset:

3) Extract the required data, collecting data from 100,000 user reviews:
 4) Segment the extracted data using jieba and save it in a new file:
4) Segment the extracted data using jieba and save it in a new file:

5) Load the segmented file and train it using Word2Vec:

6) After training the word vectors with Word2Vec, check the results, for example, to find similar words for a specific word:

6. Conclusion
Compared to Hierarchical Softmax, Negative Sampling discards the Huffman tree structure from the projection layer to the output layer, replacing it with a fully connected structure. Although the projection layer to the output layer is fully connected, each time it only takes the center word and a few words used as negative examples for gradient ascent updates of θ_i and context(w) corresponding word vectors, rather than calculating all positions as in DNN.Thus, compared to Hierarchical Softmax, when training rare words, the number of negative example words sought during training remains unchanged, so the number of θ_i parameters updated during each training remains unchanged, and the time spent on training remains unchanged. This results in a more stable training speed, not being affected by rare words, leading to a faster and more stable training of the word vectors for rare words.
There are two training methods for Word2Vec: CBOW and Skip-gram. The acceleration methods for training word vectors in Word2Vec are Hierarchical Softmax and Negative Sampling. The word vectors trained by Word2Vec are quite effective, as they can measure the proximity between different words. However, Word2Vec also has its drawbacks, as it does not consider the order of words in context(w), which results in all words in the input layer being treated as equivalent during training, causing the trained word vectors to primarily contain semantic information with little syntactic information. Therefore, to obtain better word vectors, one should ideally train them within a goal-oriented neural network, such as for sentiment analysis, to derive the first embedding layer as word vectors, which should perform significantly better than those trained with Word2Vec. Of course, we may not always require highly precise word vectors, so using Word2Vec for quick and efficient training of word vectors remains a viable option.
That concludes the content related to training word vectors with Word2Vec. If you have any questions, feel free to leave comments for discussion.
In conclusion: We welcome everyone to click the QR code below to follow our official account, clickResource Column or reply with the keyword “resources” to get more resource recommendations. Follow our historical articles and explore the world of deep learning with the editor.
