01
Network Initialization Parameters
1. InitNet
void InitNet() { long long a, b; unsigned long long next_random = 1; a = posix_memalign((void **)&syn0, 128, (long long)vocab_size * layer1_size * sizeof(real)); if (syn0 == NULL) {printf("Memory allocation failed\n"); exit(1);} if (hs) { a = posix_memalign((void **)&syn1, 128, (long long)vocab_size * layer1_size * sizeof(real)); if (syn1 == NULL) {printf("Memory allocation failed\n"); exit(1);} for (a = 0; a < vocab_size; a++) for (b = 0; b < layer1_size; b++) syn1[a * layer1_size + b] = 0; } if (negative>0) { a = posix_memalign((void **)&syn1neg, 128, (long long)vocab_size * layer1_size * sizeof(real)); if (syn1neg == NULL) {printf("Memory allocation failed\n"); exit(1);} for (a = 0; a < vocab_size; a++) for (b = 0; b < layer1_size; b++) syn1neg[a * layer1_size + b] = 0; } for (a = 0; a < vocab_size; a++) for (b = 0; b < layer1_size; b++) { next_random = next_random * (unsigned long long)25214903917 + 11; syn0[a * layer1_size + b] = (((next_random & 0xFFFF) / (real)65536) - 0.5) / layer1_size; }}2. CreateBinaryTree
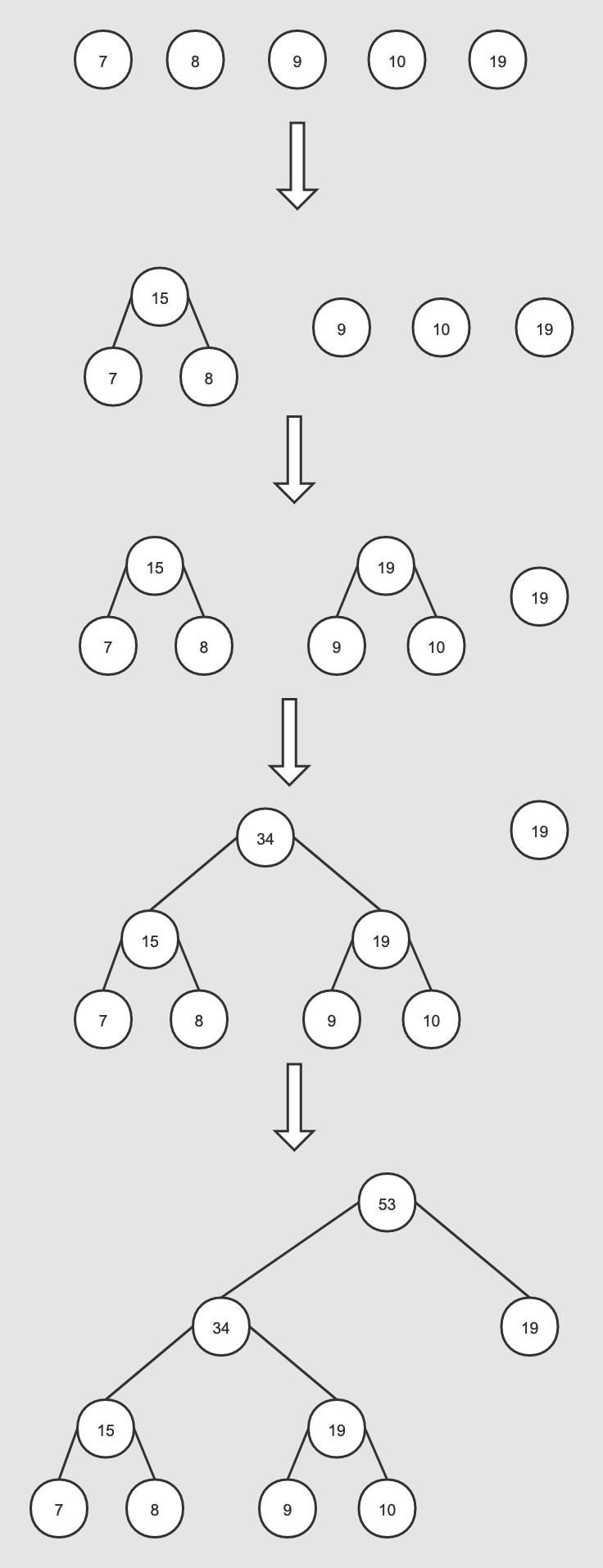
void CreateBinaryTree() { long long a, b, i, min1i, min2i, pos1, pos2, point[MAX_CODE_LENGTH]; char code[MAX_CODE_LENGTH]; long long *count = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); long long *binary = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); long long *parent_node = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long)); for (a = 0; a < vocab_size; a++) count[a] = vocab[a].cn; for (a = vocab_size; a < vocab_size * 2; a++) count[a] = 1e15; pos1 = vocab_size - 1; pos2 = vocab_size; for (a = 0; a < vocab_size - 1; a++) { if (pos1 >= 0) { if (count[pos1] < count[pos2]) { min1i = pos1; pos1--; } else { min1i = pos2; pos2++; } } else { min1i = pos2; pos2++; } if (pos1 >= 0) { if (count[pos1] < count[pos2]) { min2i = pos1; pos1--; } else { min2i = pos2; pos2++; } } else { min2i = pos2; pos2++; } count[vocab_size + a] = count[min1i] + count[min2i]; parent_node[min1i] = vocab_size + a; parent_node[min2i] = vocab_size + a; binary[min2i] = 1; } for (a = 0; a < vocab_size; a++) { b = a; i = 0; while (1) { code[i] = binary[b]; point[i] = b; i++; b = parent_node[b]; if (b == vocab_size * 2 - 2) break; } vocab[a].codelen = i; vocab[a].point[0] = vocab_size - 2; for (b = 0; b < i; b++) { vocab[a].code[i - b - 1] = code[b]; vocab[a].point[i - b] = point[b] - vocab_size; } } free(count); free(binary); free(parent_node);}-
In the first iteration, a=0, pos1=4, pos2=5, count[pos1]=7, count[pos2]=1e15. At this point, count[pos1] < count[pos2], so min1i=4, pos1 decreases to 3, count[pos1]=8, count[pos2]=1e15, count[pos1] < count[pos2], min2i=3, pos1 decreases to 2, count[5+0] is assigned count[3]+count[4]=15.
-
In the second iteration, a=1, pos1=2, pos2=5, count[pos1]=9, count[pos2]=15. At this point, count[pos1] < count[pos2], so min1i=2, pos1 decreases to 1, count[pos1]=10, count[pos2]=1e15, count[pos1] < count[pos2], min2i=1, pos1 decreases to 0, count[5+1] is assigned count[1]+count[2]=19.
-
In the third iteration, a=2, pos1=0, pos2=5, count[pos1]=19, count[pos2]=15. At this point, count[pos1] > count[pos2], so min1i=5, pos2 increases to 6, count[pos1]=19, count[pos2]=19, count[pos1] = count[pos2], min2i=6, pos2 increases to 7, count[5+2] is assigned count[5]+count[6]=34.
-
In the fourth iteration, a=3, pos1=0, pos2=7, count[pos1]=19, count[pos2]=34. At this point, count[pos1] < count[pos2], so min1i=0, pos1 decreases to -1, at this point, pos1 is less than 0, min2i=7, pos2 increases to 8, count[5+3] is assigned count[0]+count[7]=53.
-
Establish a temporary variable b, mainly to obtain the current word’s path in parent_node, which also directly corresponds to the index in binary;
-
Since the Huffman tree has a total of vocab_size*2-1 nodes, vocab_size*2-2 is the root node. The code uses this as the termination condition for the loop, meaning the path has reached the root node;
-
Since the Huffman encoding and path go from the root node to the leaf node, we need to reverse the previously obtained code and point, and the path should also have vocab_size subtracted.
3. InitUnigramTable
void InitUnigramTable() { int a, i; double train_words_pow = 0; double d1, power = 0.75; table = (int *)malloc(table_size * sizeof(int)); for (a = 0; a < vocab_size; a++) train_words_pow += pow(vocab[a].cn, power); i = 0; d1 = pow(vocab[i].cn, power) / train_words_pow; for (a = 0; a < table_size; a++) { table[a] = i; if (a / (double)table_size > d1) { i++; d1 += pow(vocab[i].cn, power) / train_words_pow; } if (i >= vocab_size) i = vocab_size - 1; }}
02
Training Module
-
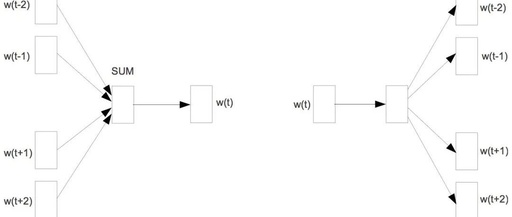
neu1: Input word vector [in CBOW, it is the sum of the vectors of words in the window; in Skip-gram, it is the vector of the center word], length is layer1_size, initialized to 0, used to update syn1;
-
neu1e: Length is layer1_size, initialized to 0, used to update syn0;
-
alpha: Learning rate;
-
last_word: Records the index of the current context word being scanned.
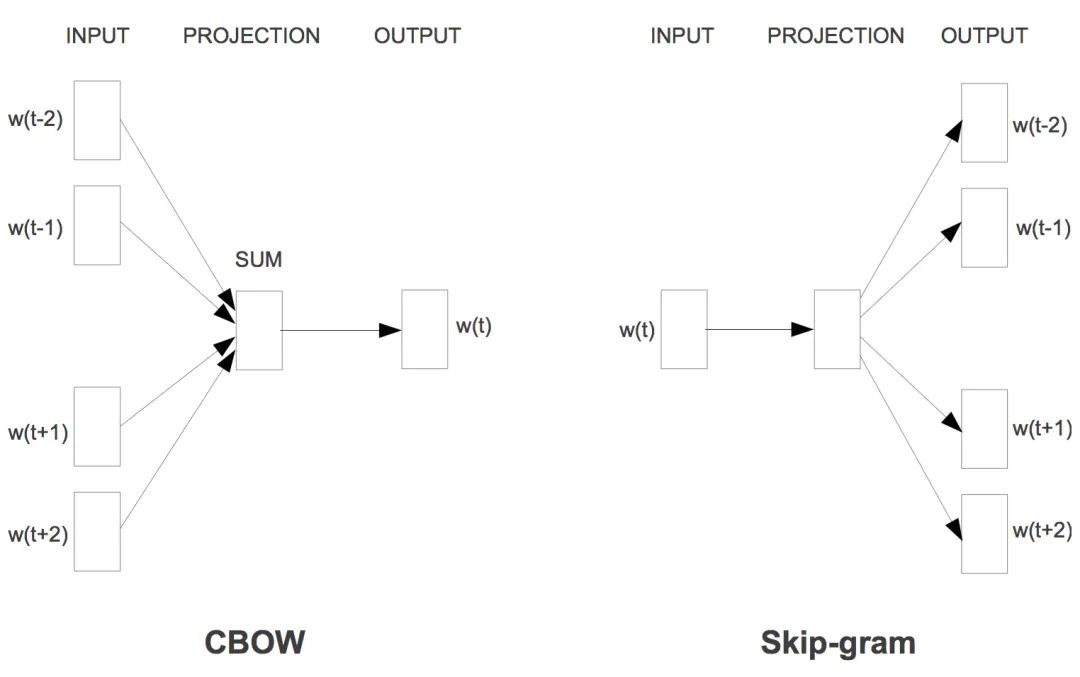
1. CBOW
for (c = 0; c < layer1_size; c++) neu1[c] += syn0[c + last_word * layer1_size];for (c = 0; c < layer1_size; c++) neu1[c] /= cw;1.1 Training Using Hierarchical Softmax
for (d = 0; d < vocab[word].codelen; d++) { f = 0; l2 = vocab[word].point[d] * layer1_size; for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2]; if (f <= -MAX_EXP) continue; else if (f >= MAX_EXP) continue; else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]; g = (1 - vocab[word].code[d] - f) * alpha; for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2]; for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c]; }1.2 Training Using Negative Sampling
for (d = 0; d < negative + 1; d++) { if (d == 0) { target = word; label = 1; } else { next_random = next_random * (unsigned long long)25214903917 + 11; target = table[(next_random >> 16) % table_size]; if (target == 0) target = next_random % (vocab_size - 1) + 1; if (target == word) continue; label = 0; } l2 = target * layer1_size; f = 0; for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1neg[c + l2]; if (f > MAX_EXP) g = (label - 1) * alpha; else if (f < -MAX_EXP) g = (label - 0) * alpha; else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha; for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2]; for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * neu1[c]; }for (a = b; a < window * 2 + 1 - b; a++) if (a != window) { c = sentence_position - window + a; if (c < 0) continue; if (c >= sentence_length) continue; last_word = sen[c]; if (last_word == -1) continue; for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c]; }2. Skip-gram
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) { c = sentence_position - window + a; if (c < 0) continue; if (c >= sentence_length) continue; last_word = sen[c]; if (last_word == -1) continue; l1 = last_word * layer1_size; for (c = 0; c < layer1_size; c++) neu1e[c] = 0; if (hs) for (d = 0; d < vocab[word].codelen; d++) { f = 0; l2 = vocab[word].point[d] * layer1_size; for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1[c + l2]; if (f <= -MAX_EXP) continue; else if (f >= MAX_EXP) continue; else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]; g = (1 - vocab[word].code[d] - f) * alpha; for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2]; for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * syn0[c + l1]; } if (negative > 0) for (d = 0; d < negative + 1; d++) { if (d == 0) { target = word; label = 1; } else { next_random = next_random * (unsigned long long)25214903917 + 11; target = table[(next_random >> 16) % table_size]; if (target == 0) target = next_random % (vocab_size - 1) + 1; if (target == word) continue; label = 0; } l2 = target * layer1_size; f = 0; for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1neg[c + l2]; if (f > MAX_EXP) g = (label - 1) * alpha; else if (f < -MAX_EXP) g = (label - 0) * alpha; else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha; for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2]; for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * syn0[c + l1]; } for (c = 0; c < layer1_size; c++) syn0[c + l1] += neu1e[c]; }


-
When reading files, a “</s>” is added to the end of each line for easier training.
-
If the vocabulary size exceeds the limit, a vocabulary reduction operation is performed, deleting current words with frequencies less than min_reduce (initially set to 1). This deletion operation is done in a while(1) loop, where min_reduce increments by 1, ensuring that the maximum number of words does not exceed vocab_hash_size * 0.7. The code sets vocab_hash_size = 30000000, meaning the vocabulary can have a maximum of 21 million words. Otherwise, it will keep deleting low-frequency words until this condition is met. The size of expTable is 1e8, which is far more than 21 million, so there is no need to worry about Negative Sampling being unable to train.
-
The initial learning rate is gradually reduced as the actual number of training words increases, ensuring that the learning rate does not drop below starting_alpha * 0.0001.
-
High-frequency words are randomly downsampled, discarding some high-frequency words, similar to a smoothing process, which can also speed up training.
-
If the sentence length exceeds MAX_SENTENCE_LENGTH, truncation is performed.
-
https://github.com/tmikolov/word2vec/blob/master/word2vec.c
-
https://github.com/deborausujono/word2vecpy
-
https://blog.csdn.net/EnochX/article/details/52847696
-
https://blog.csdn.net/EnochX/article/details/52852271
-
http://www.hankcs.com/nlp/word2vec.html
-
https://www.cnblogs.com/pinard/p/7160330.html