
MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and researchers in enterprises. The vision of the community is to promote communication and progress between the academic and industrial communities of natural language processing and machine learning, especially for beginners. Reprinted from | Li rumor Author | rumor
Hello, fellow readers, I am rumor.
Recently, ChatGPT has become incredibly popular, making it hard to calm down. On one hand, there is anxiety about its capabilities; various NLP sub-tasks may unify, and the paradigm may shift to pre-training + Prompt, eliminating the need for so many fine-tuned models. On the other hand, there is pessimism about replicating ChatGPT domestically; such a large model truly requires strong determination and sufficient manpower, financial resources, and time to create.
After adjusting for a few weeks, I finally returned to an open-minded state, reviewing what I believe are the difficulties in replicating ChatGPT and alternative solutions. Due to personal limitations, there are certainly gaps in the following research, and everyone is welcome to discuss and complete it.
Difficulties 1: Efficient Algorithm Framework
Training large models is not as easy as imagined; it requires a powerful engineering framework for support. Once the parameter count increases, the model and data need to be distributed across multiple GPUs. How to communicate and schedule between the cards, and how to efficiently perform backpropagation, all have many pitfalls waiting for everyone to step into. Just like a few years ago, even with Alibaba’s strong technology, when the traffic surged on Double Eleven, it still crashed for a while. Moreover, once a bug appears in the algorithm framework, the model may not converge or perform well. At the same time, training efficiency is very important; it can greatly reduce trial and error costs.
Knowing the importance of the training framework, let’s look at what OpenAI has achieved:
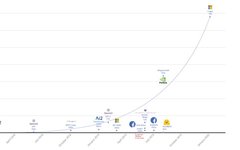
Early practitioners must remember this image; at that time, Megatron-LM and DeepSpeed had already pushed the model to a size we dared not imagine (ordinary algorithm teams were very happy with 2 V100s each), yet in 2020, OpenAI released the 175B GPT-3. Since then, the capacity of OpenAI’s algorithm framework has been ahead by one to two orders of magnitude.
Fortunately, major companies have iterated their own frameworks in the large model competition over the past two years; however, this time, the addition of the reinforcement learning paradigm RLHF has brought new challenges to the training framework. Last year, I spent about 4 months of my spare time working on reinforcement learning projects and competitions, and two points made me very painful:
-
It often collapses during training; in cases of sparse rewards or when modifying rewards, the model often takes shortcuts and develops in unexpected directions.
-
Different frameworks often yield different results; there are many open-source frameworks that are not necessarily reliable. I personally switched between three. After communicating with three RL colleagues in the industry, their companies chose to develop their own rather than use open-source, unlike NLP where everyone uses transformers.
Fortunately, this time the rewards are continuous, the loss function is clearly defined, and the basic PPO’s replication threshold is not that high.
The good news is that a replacement solution, ColossalAI[1], has recently been developed by Chinese creators, and from some introductions, its efficiency exceeds Megatron-LM and DeepSpeed, and it has already implemented part of ChatGPT (although it does not support PPO-ptx yet). Next, we will see how well it performs when used.
Difficulties 2: Catching Up with GPT3 First
From Master Fuyou’s tracing of the origins of ChatGPT’s capabilities, a good pre-trained model will exhibit numerous abilities:
-
In-Context Learning: the ability to understand input instructions and examples directly without fine-tuning
-
Long-distance understanding: the basis for multi-turn conversations
-
Common sense knowledge and reasoning abilities
-
Cross-language abilities
-
Code generation abilities
Moreover, from another study by Master Fuyou on large model capabilities, it appears that models must be at least 62B to achieve a certain level of few-shot performance. Truly catching up with these capabilities requires substantial financial, human, and time investments; it is estimated that various companies are currently bulk purchasing A100s, at least a thousand units, with budgets exceeding a hundred million.
Fortunately, there are also some alternative solutions; those supporting Chinese include mT5 (176B), GLM (130B), and BLOOM (176B), but only BLOOM is based on the GPT architecture. Additionally, there are mT0 and BLOOMZ, which are versions after instruction tuning.
Difficulties 3: Obtaining Real User Input
From GPT3 to ChatGPT, the main advancement was based on real user inputs for labeling, followed by fine-tuning the model to fit human preferences (referred to as Alignment).
This is why I was most anxious recently about its Matthew effect or data flywheel; the better it performs, the more users it attracts, continuously improving its fitting effect. Technical issues have alternatives, but where can we find a continuous source of prompts from over a hundred million users?
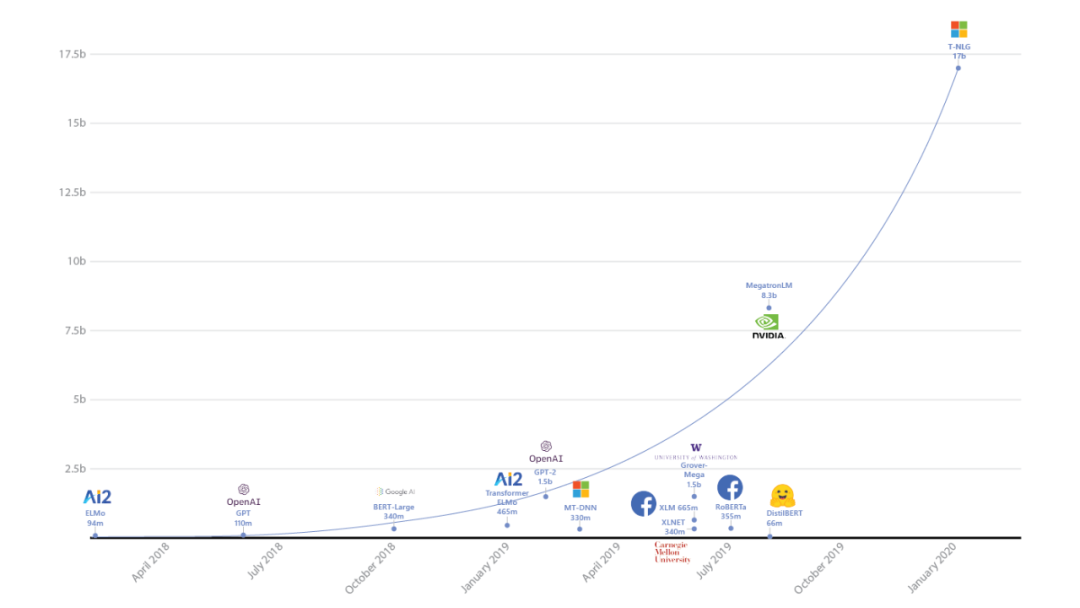
The first alternative solution is to refer to the instruction tuning papers and construct prompts using various NLP datasets. However, this is not the optimal solution, as InstructGPT also conducted this experiment, fine-tuning with FLAN and T0 data, and the results are as follows:
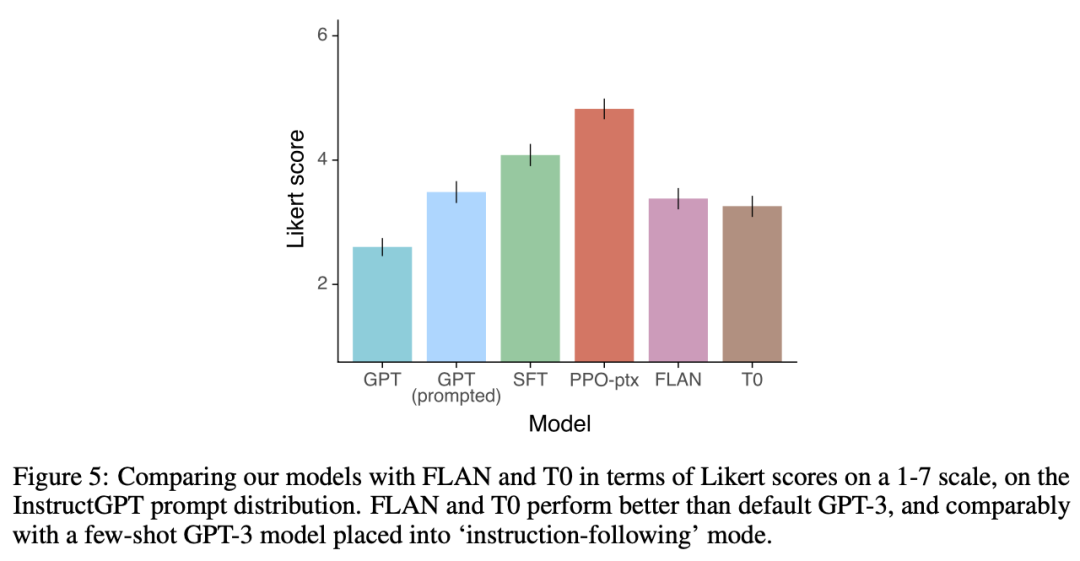
If we want to create a general model, it is best to align with the user distribution. We can see the distribution statistics of InstructGPT:
After seeing the real distribution, my anxiety eased a bit, feeling that we can still find a cold start alternative. First, for the highest proportion of generation tasks, many pre-trained models can handle them, such as writing poetry and stories, which many of you may have seen before; initially, there is no need for special optimization. Secondly, OpenQA has plenty of data available for scraping, such as Baidu Encyclopedia and Zhihu. Brainstorming can filter through the scraped Q&A data using keywords. The remaining tasks are traditional NLP tasks, and there are also open-source datasets.
Difficulties 4: Navigating the Pitfalls of Fine-tuning
For fine-tuning, OpenAI divided it into two steps: supervised fine-tuning (SFT, shown in step 1 below) and reinforcement learning training (RLHF, shown in steps 2+3 below).
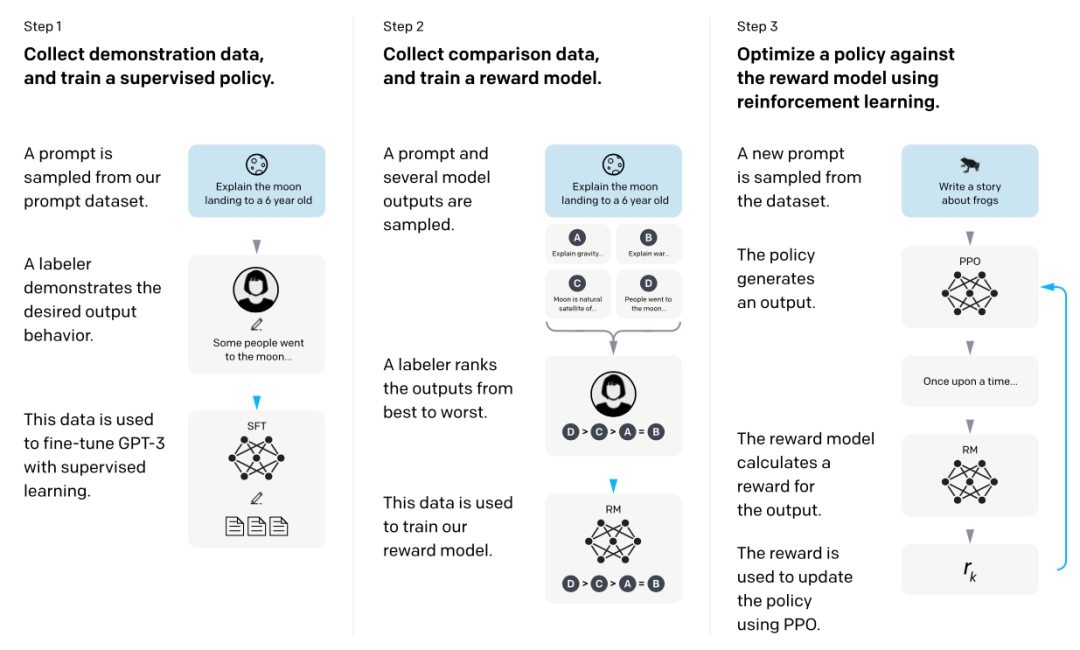
Although some viewpoints suggest that RL is not necessary and that better supervised data can also produce ChatGPT, and RL + NLP has not been favored in recent years[2], after reviewing OpenAI’s RLHF articles from 2020 and 2022, I personally believe the key to ChatGPT’s fine-tuning lies in the RLHF stage.
For example, let’s assume we treat training a model like raising a child:
-
Pretrain: During the child’s first 0-3 years, we can’t explain too much; they can’t understand, and more is about letting them observe the world and learn freely.
-
Instruction Tuning: Once the child learns to speak and has a basic understanding of the world, we can start teaching them through demonstrations, such as how to dress and how to brush their teeth.
-
RLHF: As the child grows older and knows many things, they won’t completely imitate their parents; instead, they will have their own behaviors. At this point, parents need to provide feedback on these unpredictable behaviors, rewarding them for good performance and punishing them for misbehavior.
Returning to the generation task itself, the paradigm in NLP has long been to maximize likelihood, fitting the sentences written by labeled students using teacher forcing. But what if the labeled students are lazy?
For the question of “what constitutes a good response,” everyone has different answers, but it is essential to define the goals clearly so that the model knows where to optimize. When Google trained the LaMDA dialogue model, they provided five dimensions of definitions, and then fitted towards these five directions. However, human language is vast and profound; can five dimensions truly evaluate the quality of a statement?
The key to the RLHF paradigm is that it can genuinely allow the model to fit human preferences while granting the model a certain degree of freedom, enabling it to first imitate and then surpass, rather than just repeating some patterns from instruction tuning.
The aforementioned statements may be somewhat subjective; let’s look at the experimental data provided by OpenAI:
In the summarization task, the model fine-tuned with RLHF significantly outperformed the SFT results. Additionally, other experiments in the paper also confirmed that RLHF models possess better cross-domain generalization capabilities:
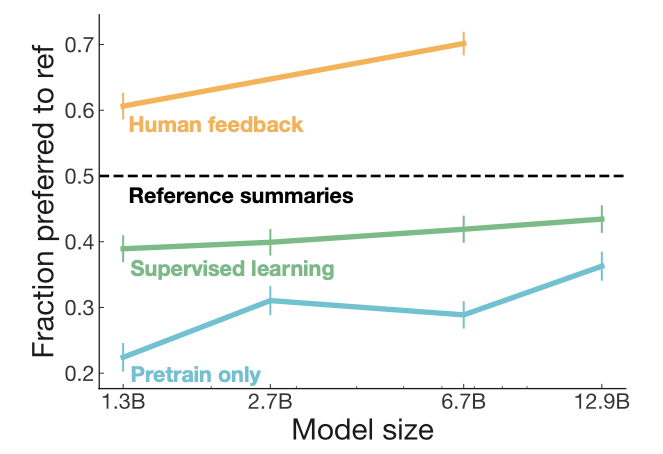
In the InstructGPT paper, a 1.3B model fine-tuned with RLHF can outperform the 175B model with SFT:
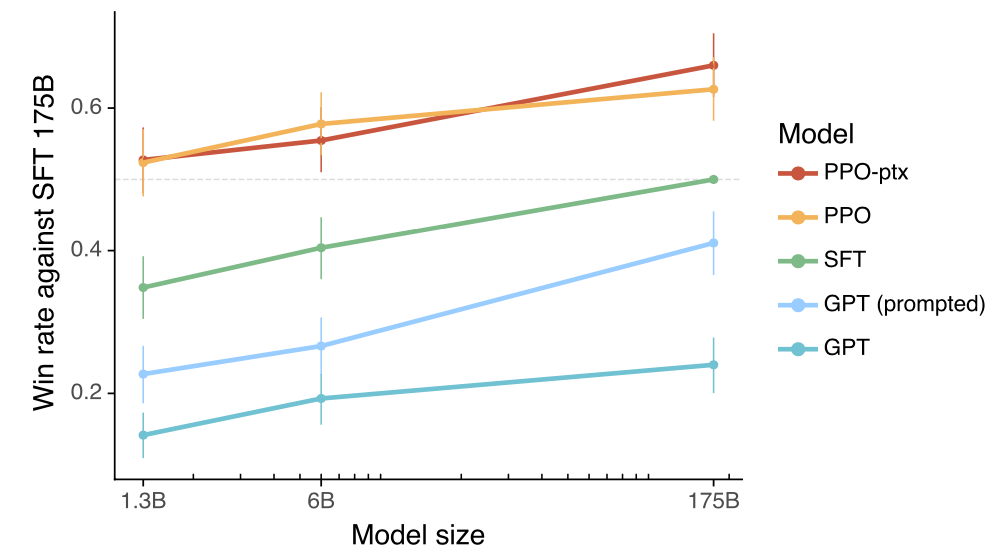
From the above results, it can be inferred that in situations with limited manpower, computational power, and time, the most efficient path is to iterate directly on the 1.3B model, using about 100,000 labeled data to replicate a low-spec small ChatGPT, validating the effectiveness of the entire process before moving on to a 175B model.
Unfortunately, too few people have navigated the pitfalls of the RLHF part, making it hard to find alternatives. I can only think of a solution to iterate quickly with a small model; the next pitfalls will depend on everyone.
Additionally, regarding why some previous RLHF works did not succeed, I believe the key points are:
-
This work[3] had labelers who preferred extractive answers, causing the model to learn incorrectly, while OpenAI has put significant effort into labeling. Additionally, this work used humans as RM, which is less efficient.
-
DeepMind Sparrow[4] was actually only trained on a specific dialogue dataset, which differs from the real distribution. Additionally, the Rule Reward they added may also have had an impact. Currently, I believe the core issue lies in not putting enough effort into the data, simply following OpenAI’s approach. However, this paper is over 70 pages long, and I find it hard to digest; I will revisit it periodically to refresh my understanding.
Conclusion
In the above text, I listed four difficulties I believe exist in replicating ChatGPT, along with some alternative solutions. If each solution is discounted, it indeed replicates about 60% of the original, consistent with the optimistic predictions in the industry.
Moreover, I have not mentioned the importance of labeled data, as there are many alternatives available; just request a budget from your boss to adjust the OpenAI interface. However, there is a sentence in OpenAI’s paper that I particularly like and hope to remember when creating models in the future:
We train all labelers to ensure high agreement with our judgments, and continuously monitor labeler-researcher agreement over the course of the project.
We must first train the labelers well before we can train the model; please everyone repeat this three times with me (dog head).
Finally, I would like to share two points that have alleviated my anxiety:
-
OpenAI’s latest blog post shows[5] that one of their future directions is to create customized models on general models. I estimate I won’t be unemployed; I can wash data again.
-
Since discovering that a 1.3B model + RLHF can be quite strong, I feel that in real-world applications, training a customized ChatGPT for a single generation task is no longer so unattainable; one or two A100s and a dataset of around 100,000 can suffice (perhaps overly optimistic, but I often oscillate between enthusiasm and anxiety).
References
[1]ColossalAI: https://github.com/hpcaitech/ColossalAI
[2] Zhihu: What are some particularly tricky research directions in machine learning as of 2020?: https://www.zhihu.com/question/299068775/answer/647698748
[3] Fine-tuning language models from human preferences: https://arxiv.org/abs/1909.08593
[4] Sparrow: https://www.deepmind.com/blog/building-safer-dialogue-agents
[5] How should AI systems behave, and who should decide?: https://openai.com/blog/how-should-ai-systems-behave/
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply for joining technical groups such as Natural Language Processing/Pytorch
About Us
MLNLP Community is a grassroots academic community jointly established by machine learning and natural language processing scholars from both domestic and international backgrounds. It has developed into a well-known community in the field of machine learning and natural language processing, aiming to promote progress among the academic and industrial communities of machine learning and natural language processing as well as enthusiasts.The community can provide an open platform for communication regarding further studies, employment, and research for related practitioners. Everyone is welcome to follow and join us.
