As students entering the field of machine learning, many commonly used algorithms might not be very familiar to you. No worries!
This article will definitely provide you with a complete overview~
Like and save it for slow learning~
Basic Machine Learning Algorithms:
·Linear Regression
·Support Vector Machine
·K-Nearest Neighbors
·Logistic Regression
·Decision Tree
·K-Means
·Random Forest
·Naive Bayes
·Dimensional Reduction
·Gradient Boosting
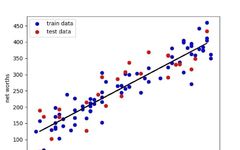
1. Linear Regression
The modeling process of the Linear Regression algorithm is to use data points to find the best fit line. The formula is y=mx + c, where y is the dependent variable, x is the independent variable, and m and c are calculated using the given dataset.
Linear regression is divided into two types: simple linear regression (with one independent variable) and multiple regression (with at least two independent variables).
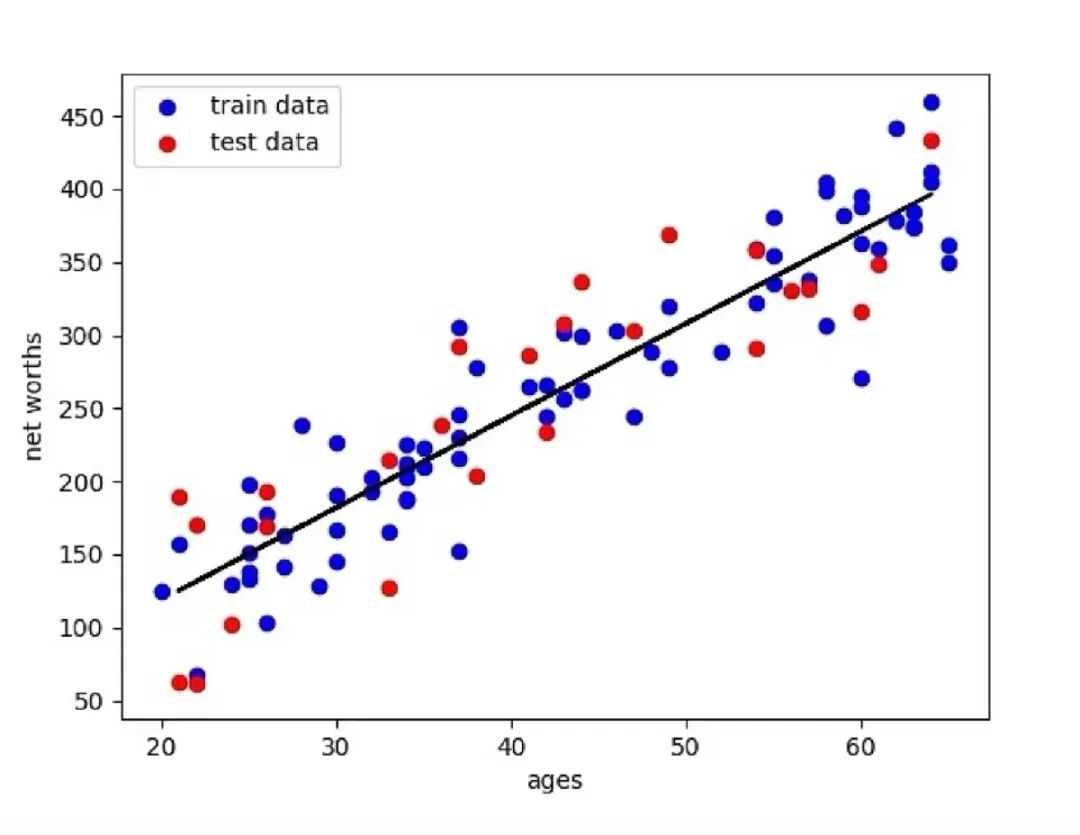
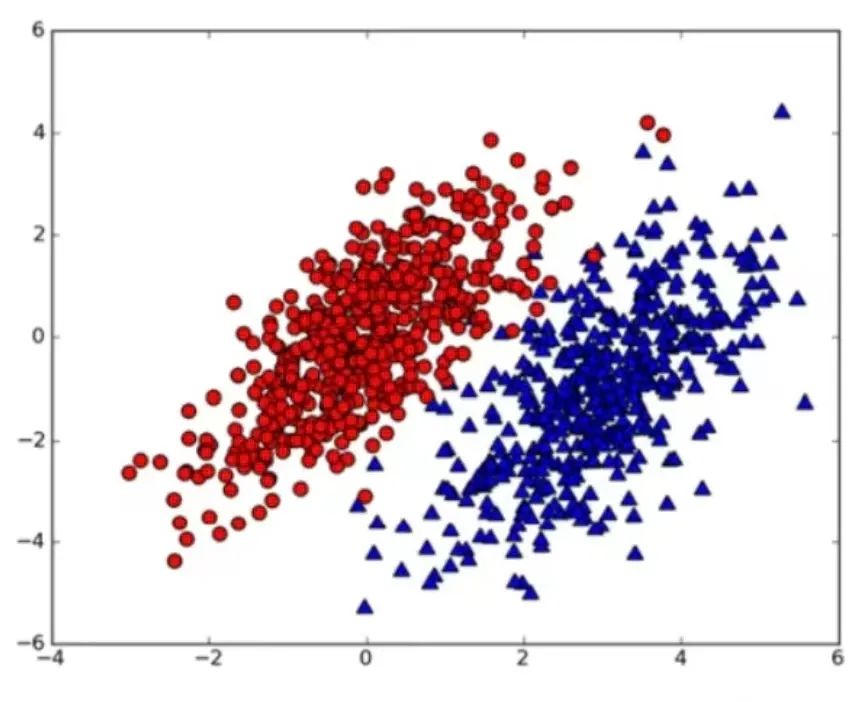
2. Support Vector Machine
The Support Vector Machine (SVM) is a classification algorithm. The SVM model represents instances as points in space and separates data points using a line. It is important to note that the support vector machine requires fully labeled input data and is directly applicable only to binary tasks, while multi-class tasks need to be reduced to several binary problems.
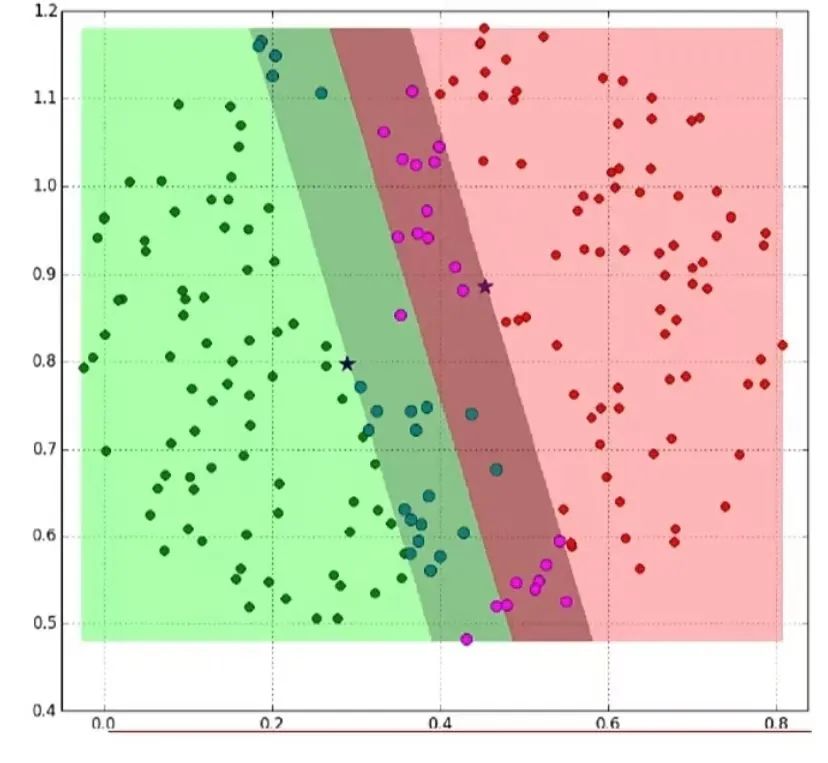
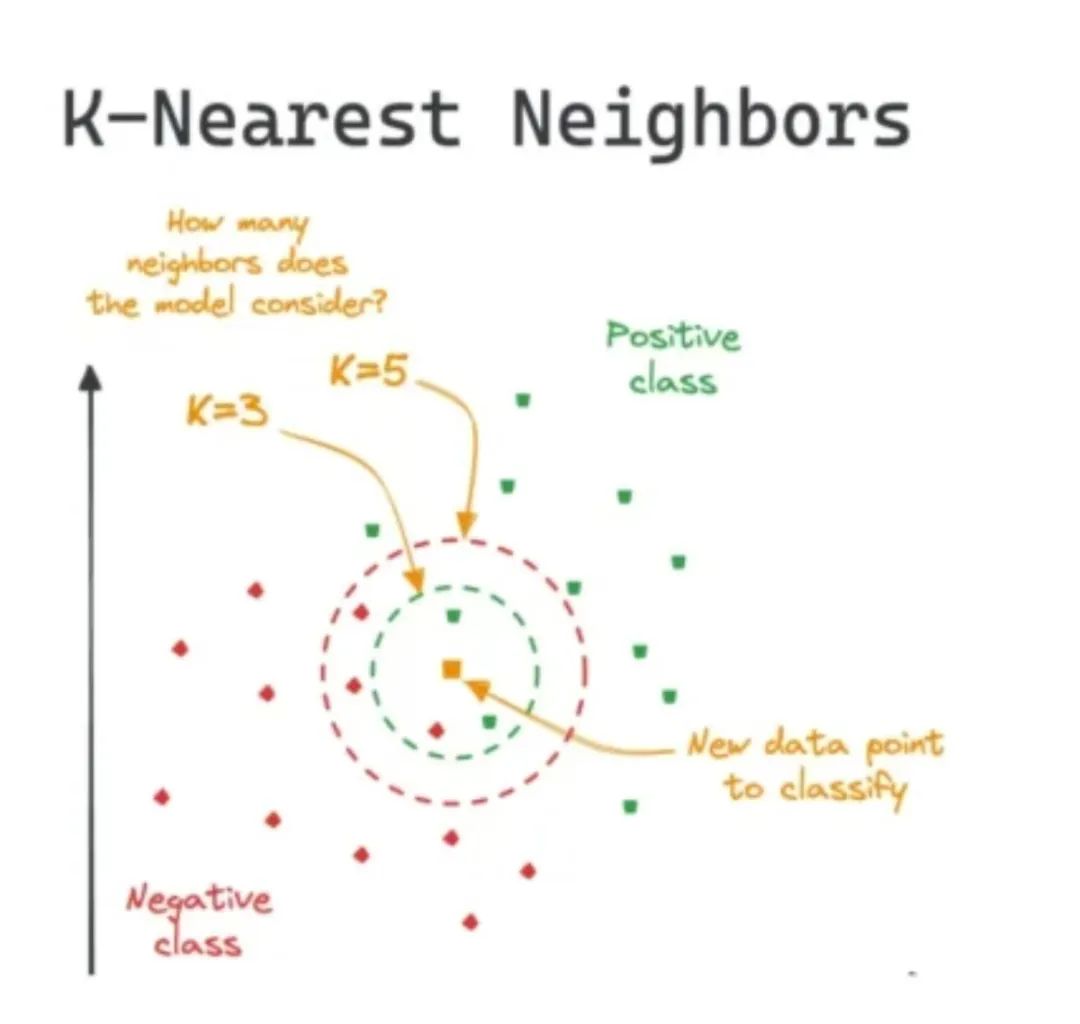
3. K-Nearest Neighbors
The KNN algorithm is an instance-based learning algorithm, or lazy learning that postpones all computations until classification. It uses the nearest neighbors (k) to predict unknown data points. The value of k is a key factor in prediction accuracy, whether for classification or regression, and measuring the weight of neighbors is very useful, with closer neighbors having more weight than distant ones.
The disadvantage of the KNN algorithm is its sensitivity to the local structure of the data. It requires normalization of data, ensuring that every data point is within the same range.
Extension: A drawback of KNN is its dependence on the entire training dataset. Learning Vector Quantization (LVQ) is a supervised learning neural network algorithm that allows you to select training instances. LVQ is data-driven, searching for the two nearest neurons, attracting similar neurons and repelling dissimilar ones, ultimately obtaining the distribution pattern of the data. If KNN achieves good classification results, using LVQ can reduce the storage size of the training dataset. Typical learning vector quantization algorithms include LVQ1, LVQ2, and LVQ3, with LVQ2 being the most widely used.
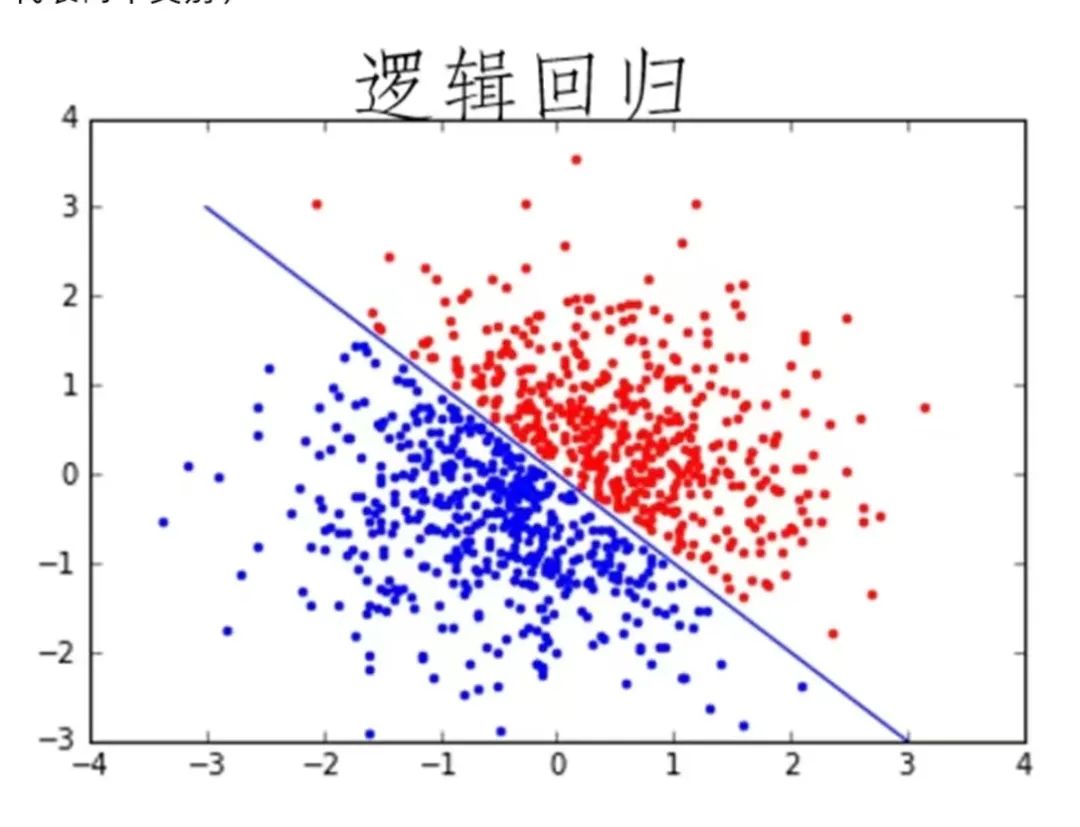
4. Logistic Regression
The Logistic Regression algorithm is generally used in scenarios where a clear output is needed, such as predicting whether an event will occur (e.g., predicting rain). Typically, logistic regression uses a certain function to compress probability values into a specific range.
5. Decision Tree
A Decision Tree is a special tree structure composed of a decision graph and possible outcomes (such as costs and risks) to assist in decision-making. In machine learning, a decision tree is a predictive model where each node represents an object, each branch represents a possible attribute value, and each leaf node corresponds to the value of the object represented by the path from the root node to that leaf node. Decision trees have a single output and are typically used to solve classification problems.
A simple decision tree algorithm example is to determine who in a population prefers to use credit cards. Considering the age and marital status of individuals, if they are over 30 or married, they are more likely to choose a credit card; otherwise, they are less likely.
By identifying appropriate attributes to define more categories, this decision tree can be further expanded. In this example, if a person is married and over 30, they are more likely to have a credit card (100% preference). Test data is used to generate the decision tree.
Note: For data with inconsistent sample sizes across categories, the information gain in decision trees tends to favor features with more values.
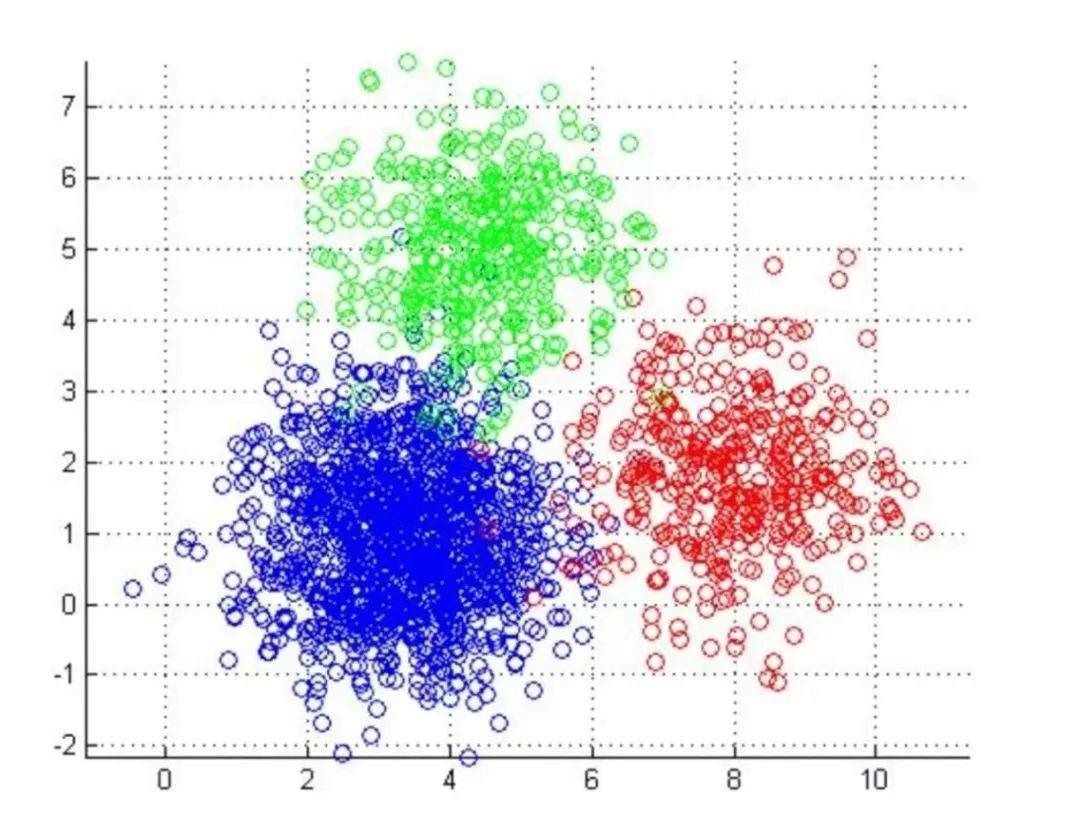
6. K-Means
The K-Means algorithm is an unsupervised learning algorithm that provides a solution for clustering problems.
K-Means algorithm partitions n points (which can be a single observation of a sample or an instance) into k clusters, ensuring that each point belongs to the nearest mean (i.e., the cluster center, centroid). This process repeats until the centroids do not change.
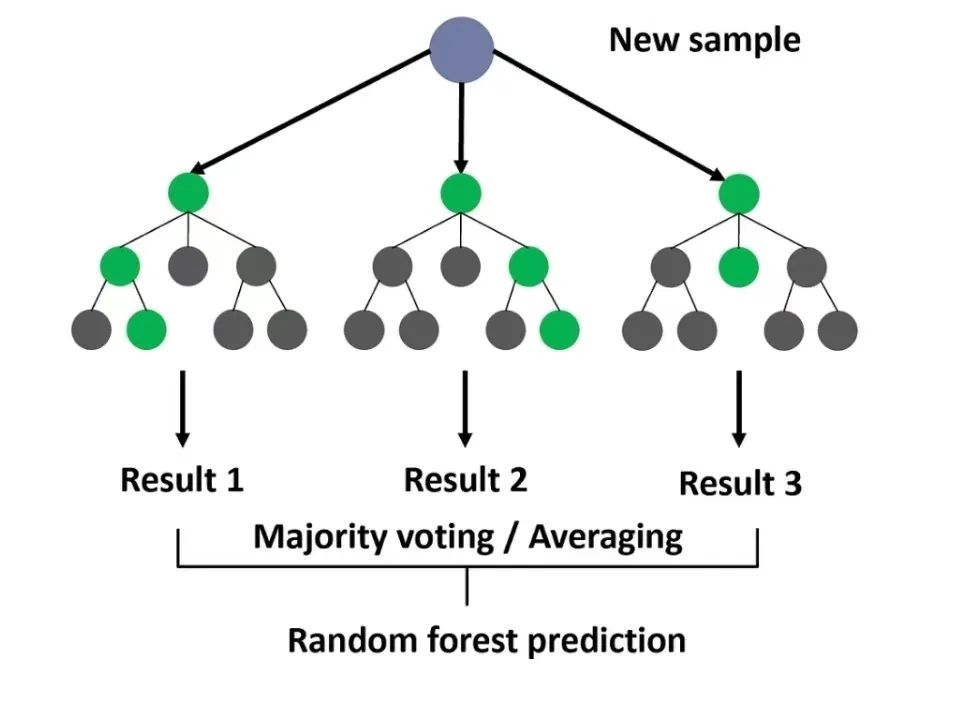
7. Random Forest
In a Random Forest, each decision tree estimates a classification, a process known as “voting.” Ideally, we select the classification with the most votes based on each decision tree’s votes.
8. Naive Bayes
The Naive Bayes algorithm is based on the probability theory of Bayes’ theorem and is widely applied in various fields such as text classification, spam filtering, and medical diagnosis. Naive Bayes is suitable for scenarios where features are mutually independent, such as predicting flower types based on petal length and width. The term “naive” reflects the strong independence between features.
A closely related concept to Naive Bayes is Maximum Likelihood Estimation, which historically has seen significant development within Bayesian statistics. For example, building a population height model is challenging due to the difficulty in measuring the height of every individual nationwide. However, sampling can provide heights for a subset of individuals, and then Maximum Likelihood Estimation can be used to obtain the mean and variance of the distribution.
9. Dimensional Reduction
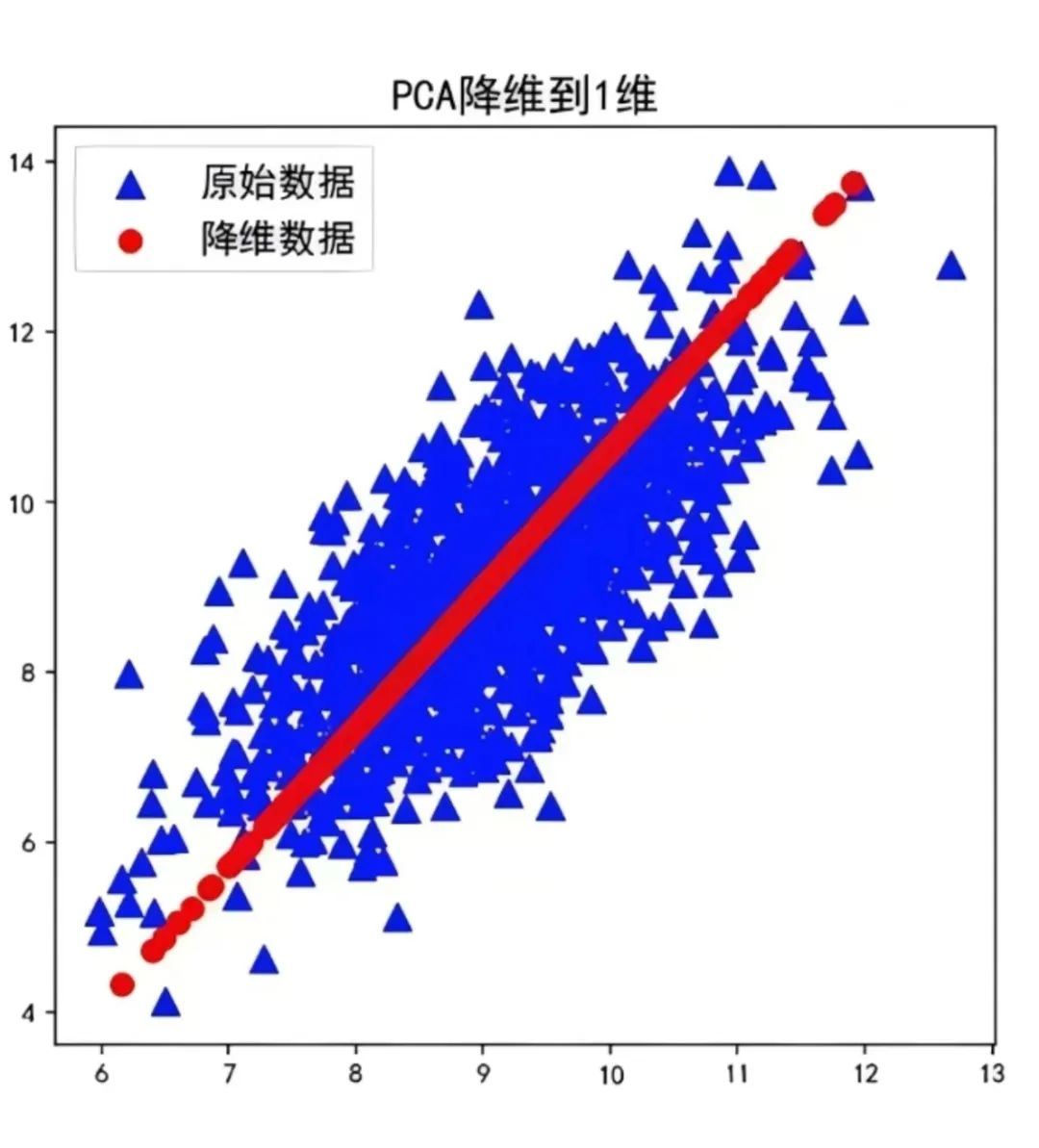
In the fields of machine learning and statistics, Dimensional Reduction refers to the process of reducing the number of random variables under certain conditions to obtain a set of “uncorrelated” main variables, which can be further divided into feature selection and feature extraction methods.
Some datasets may contain numerous difficult-to-handle variables. Especially in resource-rich environments, the data within the system can be very detailed. In such cases, the dataset may contain thousands of variables, most of which may be unnecessary. It becomes nearly impossible to identify the variables that most significantly impact our predictions. At this point, we need to use dimensional reduction algorithms, and during the reduction process, we may also need to employ other algorithms, such as using random forests and decision trees to identify the most important variables.
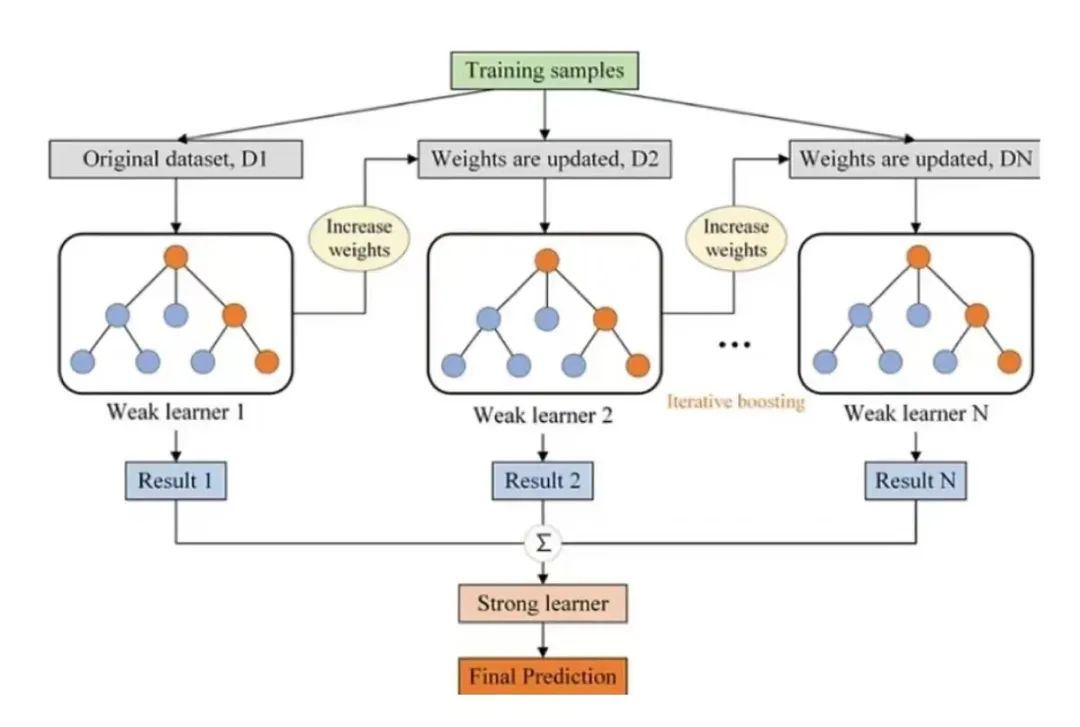
10. Gradient Boosting
The Gradient Boosting algorithm is a cutting-edge technique that serially trains a series of weak learners, with each round aiming to reduce the overall loss function, thereby accumulating to form a strong predictive model.
👇👇👇👇👇
Scan the code to add the editor teacher
To learn more about artificial intelligence resources
