
Domestic AI Products
As we all know, the AI and large model field has been extremely hot this past year. In August, with the official implementation of the “Interim Measures for the Management of Generative Artificial Intelligence Services,” China has established requirements and affirmations for its own path in generative artificial intelligence, providing clarity for the AIGC industry.
In November, I felt that domestic AI had already met the basic conditions for industrial application scenarios (mainly referring to B-end). For those who want to integrate AI with their company’s products, it’s time to take action. However, due to work reasons, I have been paying less attention to domestic commercial/enterprise applications, and various meetings have also gone unnoticed. I truly don’t know if we B-end players are working hard. Today, I will start from myself, abandon OpenAI, and use our domestic AI platform to demonstrate how to use the LlamaIndex framework in conjunction with Zhipu AI to handle common application scenarios.
What Are the Major Models in China?
Whether open-source or closed-source, here are a few common large models (not ranked):
| Organization/Company | Model Name |
| Baidu | Wenxin Large Model |
| Douyin | Yunque Large Model |
| Zhipu | GLM Large Model |
| Chinese Academy of Sciences | Zidong Taichu Large Model |
| Baichuan Intelligence | Baichuan Large Model |
| SenseTime | Riri New Large Model |
| MiniMax | ABAB Large Model |
| Shanghai AI Lab | Shusheng General Large Model |
| iFLYTEK | Xinghuo Cognitive Large Model |
| Tencent | Hunyu Large Model |
| Alibaba | Tongyi Qianwen Large Model |
What Products Are Available?
Similarly, let’s take a look at domestic generative AI products similar to ChatGPT:
| Baidu | Wenxin Yiyan |
| Douyin | Doubao |
| iFLYTEK | Xunfei Xinghuo |
| Baichuan Intelligence | Baichuan Large Model |
| Zhipu AI | Zhipu Qingyan |
| Alibaba | Tongyi Qianwen |
Of course, the above list is not exhaustive; it is just a few that I am familiar with.
Choosing and Using Large Models
When choosing domestic large models or platforms, you can do so based on your own needs. After all, each of the above has strong capabilities and is developing rapidly.
These AI vendors generally provide services in three ways:
-
• Private model deployment: Directly deploy open-source or closed-source models (requires a GPU);
-
• AI development platform: Many platforms provide LLM services, allowing online model testing, development, deployment, fine-tuning, etc. (just pay directly);
-
• API calls: This is similar to OpenAI’s early service model, providing API calls.
For convenience, this article directly uses the API method, choosing Zhipu AI as the representative for this demonstration.
Zhipu AI
Zhipu AI[1] is a company transformed from the technical achievements of the Department of Computer Science at Tsinghua University, dedicated to creating a new generation of cognitive intelligence general models. You can visit their official website for more information:

Of course, the main focus today is their open platform[2]:
After registering and logging in, you can see modules such as models, documentation, billing, etc. in the console:
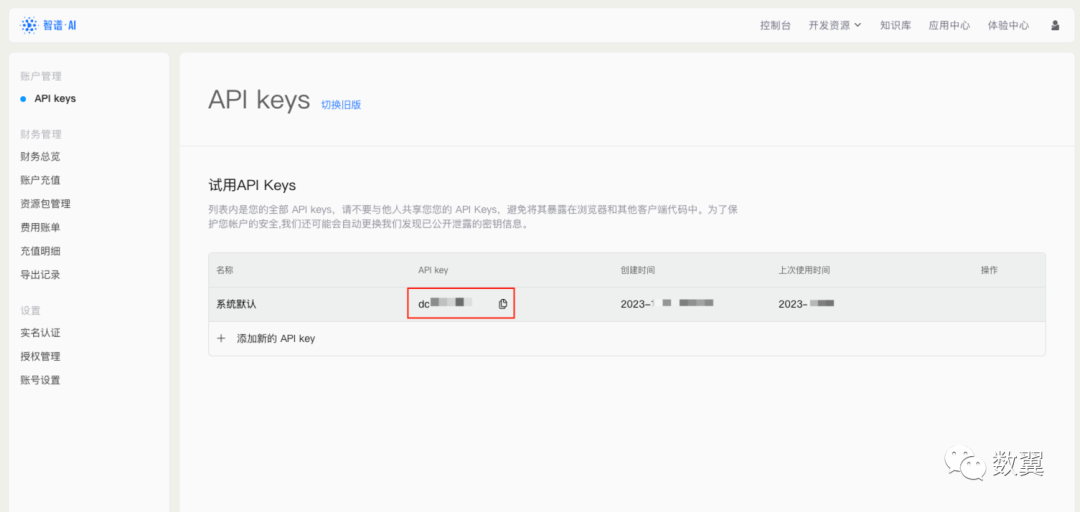
Checking the API Key shows the default API Key, which you can directly copy for use, or create a new API Key:
Using the API
From the homepage of the console, click on the API documentation to enter the API usage guide[3]:
Quick installation:
pip install zhipuaiThen, let’s write an example to test it:
import zhipuai
zhipuai.api_key = "xxx" # Your API key
def invoke_prompt(prompt):
response = zhipuai.model_api.invoke(
model="chatglm_turbo",
prompt=[
{"role": "user", "content": prompt},
],
top_p=0.7,
temperature=0.9,
)
if response['code'] == 200:
return response['data']['choices'][0]['content']
return 'LLM not worked'
if __name__ == '__main__':
response = invoke_prompt('Briefly introduce what artificial intelligence is')
print(response)The response is as follows:
Artificial Intelligence (AI) is an emerging technology that studies and develops theories, methods, technologies, and application systems that simulate, extend, and enhance human intelligence. Research in the field of artificial intelligence covers multiple aspects, such as robotics, language recognition, image recognition, natural language processing, and expert systems. Its goal is to enable computers to simulate and realize the functions of human intelligence, thus achieving or even surpassing human intelligence levels in certain areas.
Artificial Intelligence is a multidisciplinary emerging discipline aimed at cultivating talents who master the basic theories, methods, and application technologies of artificial intelligence. The courses include an introduction to artificial intelligence, cognitive science, machine learning, pattern recognition, deep learning, knowledge engineering, data mining, the Internet of Things, and other series of courses.
The development of artificial intelligence includes several stages, such as enlightenment, prosperity, and trough. Starting from the 1950s, artificial intelligence gradually became an independent discipline. With the rapid development of computer technology, network technology, and big data technology, artificial intelligence has entered a new golden age. In our country, the development of artificial intelligence has also received strong support from the government and enterprises, being regarded as an important driving force for future technological innovation.
Prompt Parameters for Zhipu AI
In the above code, we note that the prompt parameter is an array, designed naturally for dialogue and few-shot prompting.
For example:
prompt = [
{"role": "user", "content": 'Question 1'},
{"role": "assistant", "content": 'Answer 1'},
{"role": "user", "content": 'Question 2'},
{"role": "assistant", "content": 'Answer 2'},
{"role": "user", "content": prompt},
]The AI will follow the previous dialogue history and respond to the last prompt.
Alright, now the basic invocation is ready. Let’s implement a common AI scenario, knowledge base retrieval.
Llama Index
This time we will implement a knowledge base using LlamaIndex[4]. LlamaIndex is a simple, flexible, and powerful data framework for connecting custom data sources to large language models. Interested friends can check the LlamaIndex documentation[5] or visit my LlamaIndex collection for more information.

Installation
First, let’s install Llama Index using Pip:
pip install llama-indexThen we import it to test if the installation was successful:
import llama_index
print(llama_index.__version__)
# 0.9.10Next, let’s have Llama Index use Zhipu AI as the large model.
Supported LLMs
We can check the LlamaIndex documentation “Available LLM integrations[6]” to see which large models it currently supports.
The rise of domestic AI is indeed a long and arduous journey.
As mentioned earlier, Llama Index is a simple flexible data framework. Since the official integration is not available yet, let’s integrate it ourselves.
Integrating Zhipu AI
LlamaIndex provides an abstract class called CustomLLM to facilitate the integration of our own large model products:
class CustomLLM(LLM):
"""Simple abstract base class for custom LLMs.
Subclasses must implement the `__init__`, `complete`,
`stream_complete`, and `metadata` methods.
"""From the comments, we can see that implementing our own LLM is actually quite simple; we just need to implement the __init__, complete, stream_complete, and metadata methods.
Metadata Method
Among the four methods, the one we might be less familiar with is metadata. The metadata of an LLM generally includes the following:
-
•
model_name: str = "chatglm_turbo" -
•
top_p = 0.7 -
•
temperature = 0.9 -
•
num_output: int = 256 -
•
context_window: int = 3900
Parameters like “model name,” “temperature,” and “top p” are likely already familiar to everyone. Let’s implement it simply:
class ZhipuLLM(CustomLLM):
model_name: str = "chatglm_turbo"
top_p = 0.7
temperature = 0.9
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
context_window=self.context_window,
num_output=self.num_output,
model_name=self.model_name,
)Since Zhipu AI’s API doesn’t have too many parameters, we can directly use reasonable values for top_p and temperature in the calling program. In fact, we could even implement an empty method for metadata:
class ZhipuLLM(CustomLLM):
@property
def metadata(self) -> LLMMetadata:
return LLMMetadata()Complete Method
Next, we implement the complete method. Previously, we had an invoke_prompt method to implement the call to Zhipu AI. Here, we can use it directly without instantiating or setting too many parameters; the simpler, the better:
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
response = invoke_prompt(prompt)
return CompletionResponse(text=response)Text Embedding
Zhipu AI also provides a text embedding interface, so we will also use it directly, thus completely freeing ourselves from OpenAI and the need to build our own model.
The embedding in LlamaIndex is based on BaseEmbedding, so we will also write an implementation for Zhipu AI. There isn’t enough time for extensive explanations, so let’s look at the code directly:
class ZhipuEmbedding(BaseEmbedding):
_model: str = PrivateAttr()
_instruction: str = PrivateAttr()
def __init__(
self,
instructor_model_name: str = "text_embedding",
instruction: str = "Represent a document for semantic search:",
**kwargs: Any,
) -> None:
self._model = 'text_embedding'
self._instruction = instruction
super().__init__(**kwargs)
@classmethod
def class_name(cls) -> str:
return "zhipu_embeddings"
async def _aget_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
async def _aget_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
def _get_query_embedding(self, query: str) -> List[float]:
embeddings = invoke_embedding(query)
return embeddings
def _get_text_embedding(self, text: str) -> List[float]:
embeddings = invoke_embedding(text)
return embeddings
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
return [self._get_text_embedding(text) for text in texts]LlamaIndex Combined with Zhipu AI
Now let’s put together the results from earlier and write a simple program to see if it works:
First, we need to place a text file in the directory. PDF, Excel, Docx files are all acceptable. Here, I will use the previous design document for the Asian Games medals:

Then, we can directly run the program:
# define our LLM
llm = ZhipuLLM()
embed_model = ZhipuEmbedding()
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model
)
# Load your data
documents = SimpleDirectoryReader(doc_path).load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
# Query and print response
query_engine = index.as_query_engine()
response = query_engine.query("What are the processes and design concepts for the medals of the Hangzhou Asian Games? Please answer in Chinese.")
print(response)Let’s look at the answer:
The processes and design concepts for the medals of the Hangzhou Asian Games are as follows:
1. Process: The medals use a series of complex processes, including stamping, milling shapes and grooves, finishing and polishing, gold and silver plating, and surface protection. The ribbon adopts jacquard weaving technology and environmentally friendly printing technology, with double-sided hand stitching. Additionally, the front of the medal features a traditional Jiangnan craft—copper engraving, combining the four calligraphic styles (regular, cursive, clerical, and seal) with the English abbreviation of the Hangzhou Asian Games.
2. Design Concept: The medal design integrates Hangzhou's three world cultural heritage sites—West Lake, Grand Canal, and Liangzhu Ancient City Ruins, showcasing Hangzhou's landscape and Jiangnan culture. The front of the medal outlines the painting of Hangzhou city, while the back resembles a square seal, symbolizing the beautiful mark left by athletes at the Hangzhou Asian Games. The overall design is unique and highly recognizable, embodying the meaning of harmony and diversity.
In addition, the medal design also reflects Hangzhou's character as a city of ecological civilization, with beautiful lakes and mountains, green waters and hills, creating a golden mountain and silver mountain, while embodying the spirit of striving for excellence in sports. The medal has a diameter of 70mm and a thickness of 6mm, with a gradient color on the front and a seal pattern presented in Hangzhou Jiangnan embroidery technology on the back. The overall design of the medal is full of Eastern aesthetic beauty, combining the rich heritage of Southern Song culture with the regional characteristics of Hangzhou, expressing a unique aesthetic philosophy.The answers are all sourced from the document but have been reorganized. I just want to say that the expression is so fluent in Chinese! Far surpassing my own.
Conclusion
The use of large models in Llama Index mainly occurs in the two areas mentioned above. Once these two points are connected, the remaining various applications will be no different from using OpenAI. I will share more scenarios and practical AI applications later.
References
[1] Zhipu AI: https://www.zhipuai.cn/[2] Open Platform: https://open.bigmodel.cn/[3] API Usage Guide: https://open.bigmodel.cn/dev/api[4] LlamaIndex: https://www.llamaindex.ai/[5] LlamaIndex Documentation: https://docs.llamaindex.ai/en/stable/[6] Available LLM integrations: https://docs.llamaindex.ai/en/stable/module_guides/models/llms/modules.html
— END —