Big Data Digest authorized reprint from Data Practitioners
Born out of the Nuremberg Code in 1947 during World War II and the horrific Nazi regime, followed by the Helsinki Declaration in 1964, these documents helped establish the principle of informed consent, based on human dignity and control over the dissemination of one’s own information.
In the following decades, the principle of informed consent guided the way disciplines like medicine and psychology collected data from experimental subjects.
Although this principle is not perfect, it still offers some degree of protection for personal privacy in the age of big data.
However, in this era of big data, the foundations of informed consent, privacy, or personal agency have been gradually eroded. Government agencies, academia, and industry have amassed millions of human images without consent, often for undisclosed purposes.
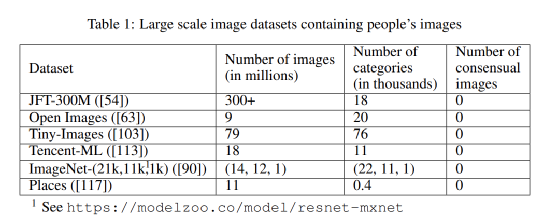
These claims are misleading because, overall, the anonymity and privacy of aggregated data are weak. More importantly, facial images are not a type of data that can be aggregated. As shown in Table 1, millions of images of individuals have been found in peer-reviewed literature, obtained without individual consent or knowledge, and without approval from an IRB (Institutional Review Board).
Table 1. Large Datasets Containing Human Images
In this context, Vinay Uday Prabhu from UnifyID AI Labs and Abeba Birhane from the Irish Software Research Centre focus on one of the most famous and standardized large-scale image datasets: the ImageNet dataset.
From the problematic sources of images to the human labels in the images, and the downstream effects of using these images to train AI models, ImageNet and large-scale visual datasets (hereafter referred to as “LSVD”) constitute a costly victory for computer vision.
In their paper titled LARGE DATASETS: A PYRRHIC WIN FOR COMPUTER VISION?, the authors point out that this victory has come at the expense of marginalized groups (data practitioners can reply with “ImageNet” to obtain the paper download link).
This high-quality yet low-privacy new starting point in the computer vision industry has indirectly fueled the erosion of technology against personal and collective privacy and consent rights in the years that followed.
The emergence of the ImageNet dataset is widely regarded as a pivotal moment in the deep learning revolution, which fundamentally changed computer vision (CV) and artificial intelligence (AI).
Before ImageNet, computer vision and image processing researchers trained image classification models on small datasets like CalTech101 (9k images), PASCAL-VOC (30k images), LabelMe (37k images), and SUN (131k images).
ImageNet boasts over 14 million images, distributed across 21,841 synsets, containing 1,034,908 bounding box annotations, filling the previous gap in scale, and dominating the former Computer Vision Olympics, where convolutional neural networks (CNN) with 60 million parameters shone in this dataset.
Created over a decade ago, ImageNet remains one of the most influential and powerful image databases today. Retrospectively judging it many years after its creation may seem redundant, but ImageNet indeed played a key role in the sustainability of other large-scale datasets and the cultural cultivation in the field of computer vision.
Starting from ImageNet, this paper summarizes the potential harms and threats of data management practices that lack careful ethical considerations and the anticipation of negative social consequences.
-
The Rise of Reverse Image Search Engines, Loss of Privacy, and Extortion Threats
If the social impact is not carefully considered when constructing large image datasets, it poses a threat to individual welfare and well-being.
The most common situation is that vulnerable and marginalized groups pay a disproportionately high price.
In the past year, the efficiency of reverse image search engines, which allow functionalities like facial searches, has significantly improved. For a small fee, anyone can use their portal or API to run an automated process to reveal the “real-world” identity corresponding to a face in the ImageNet dataset.
For example, in societies where sex work is socially condemned or legally classified as a crime, re-identifying sex workers through image searches poses a real danger to individual victims. Images of individuals in tight clothing, bras, bikinis, and others that include beach voyeurism and other non-consensual captures can easily be linked back to these individuals through image searches, with these victims often being women.
-
The Emergence of Larger and More Opaque Datasets
Efforts to build computer vision have been gradual, tracing back to Papert’s Summer Vision Project in 1966.
However, ImageNet, with its massive data, not only established an authoritative milestone in the history of artificial intelligence but also paved the way for larger, more powerful, and suspiciously opaque datasets.
The lack of scrutiny over the ImageNet dataset in the computer vision community only encourages academic and commercial institutions to build larger datasets without review.
For instance, many highly cited papers in recent years have utilized a large visual dataset known as JFT-300M.
This dataset operates “in the dark.” There is no official explanation of what JFT-300M actually represents. What is known in the industry is that it contains over 300 million images spread across 18,000 categories.
The open-source Open Images V4-5-6 contains a subset of over 3 million images covering 20,000 categories (it also has an extended dataset with 500,000 crowd-sourced images covering over 6,000 categories). However, it has been found to contain 11 images of children captured without mutual consent, which were downloaded from Flickr.
Benchmarking any downstream algorithms on such opaque and biased (semi-)synthetic datasets will only lead to controversial situations.
Thus, it is necessary to emphasize again that the existence and use of these datasets have direct and indirect impacts on people, as societal decision-making increasingly relies on systems trained on such data.
However, despite such profound impacts, where do these data actually come from? Was consent obtained for the use of the images? Such critical questions are rarely considered part of the LSVD management process.
The culture fostered by ImageNet in the broader AI community is more subtle, perhaps indirectly impactful, in which treating real human images as freely accessible raw materials has been normalized. This norm poses a threat not only to the vulnerable groups we often speak of, but also to the true meaning of privacy as we know it.
-
The Myth of Knowledge Sharing
Knowledge sharing licenses only address copyright issues, without addressing privacy rights or consent for using images for training. However, many efforts outside of ImageNet, including open image datasets, are built on this premise, with large dataset management agencies treating “free access for everyone” as a green light.
The two authors argue that this is fundamentally wrong, as evidenced by the point made by the Creative Commons organization: “CC licenses are designed to address a specific constraint, and they do so well: lifting restrictive copyright. But copyright is not a good tool for protecting personal privacy, addressing research ethics issues in AI development, or regulating the use of online surveillance tools.”
Decades of work in the fields of technological research and social sciences have shown that there is almost no single direct solution to most broader social and ethical challenges.
These challenges are deeply rooted in social and cultural structures and constitute a part of the fundamental social fabric. It is a fantasy to expect AI systems, which are infused with the world’s beauty, ugliness, and cruelty, to reflect only beauty.
Given the breadth of the challenges we face, any attempt at a quick fix may obscure the problems and potentially provide a false solution.
For example, the idea of completely eliminating bias in reality may simply hide those biases deeply. Furthermore, many challenges (bias, discrimination, injustice) change with context, history, and location; they are evolving concepts that amount to a moving target.
-
Remove, Replace, and Open
In the ImageNet dataset, among the 2832 categories of characters, 1593 have potentially offensive labels, and plans are in place to remove all these labels from ImageNet. The authors strongly advocate for similar actions regarding offensive noun categories in the Tiny Images dataset and images belonging to verifiable pornographic, non-consensual scene capturing, beach voyeurism, and exposed genitalia categories in the ImageNet-ILSVRC-2012 dataset.
In cases where image categories are retained but images are not, it is possible to replace them with images taken with mutual consent and economic compensation. Some individuals in these photos may come forward to agree and contribute their photos in exchange for fair economic compensation, credit, or purely altruistically.
However, this solution raises further questions: Will we end up with an image pool primarily composed of economically disadvantaged participants?
-
Allow Image Removal Requests
The authors of the paper found that some reverse image search engines do indeed allow users to remove specific images from their index through their “report abuse” portals. This helps mitigate some aspects of direct harm.
-
Personalized Face Blurring
This approach requires the use of techniques like DP-Blur to blur human identities in images with quantifiable privacy guarantees.
The basic idea is to use (or augment) synthetic images instead of real images during model training.
Methods include using hand-drawn sketch images, images generated by GANs, and dataset distillation techniques, where a dataset or a subset of the dataset is distilled into several representative synthetic samples. This is an emerging field, with some promising results already appearing in areas like unsupervised domain adaptation across visual domains.
-
Ethics-Enhanced Filtering
When conducting a longitudinal analysis of ImageNet, the authors found that if clear instructions are provided to crowd workers during the dataset filtering phase, specific ethical violations can be avoided from the outset. The authors hope that ethical checks will become an integral part of future dataset management work.
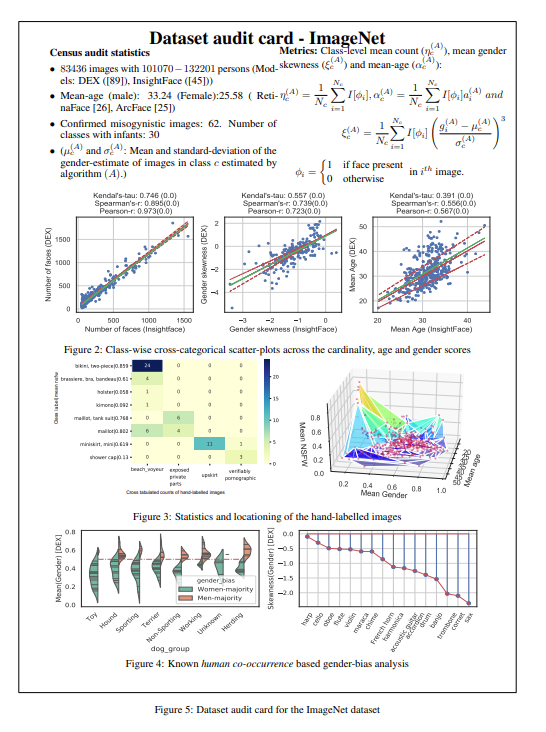
Context is crucial for determining whether a specific dataset is ethical or problematic, as it provides important background information, and data tables are an effective way to provide context. Therefore, the authors propose the use of dataset audit cards. This allows large image dataset managers to publish not only the datasets but also the objectives, management processes, known shortcomings, and caveats. As illustrated below, a sample dataset audit card for the ImageNet dataset is planned using the quantitative analyses performed.
In the article, the authors conduct cross-category quantitative analysis of ImageNet to assess the degree of ethical violations and the feasibility of model annotation methods, including image-level and class-level analyses, counting, age and gender (CAG), NSFW ratings, semantic class labels, and accuracy of classification using pre-trained models. Details can be found in the paper, which will not be elaborated here.
In summary, this research urges the machine learning community to closely monitor the direct and indirect social impacts of its work, especially on vulnerable groups.
In this regard, awareness of the historical context, background, and political dimensions of current work is necessary, thereby promoting updates in AI dataset management practices, such as establishing Institutional Review Boards (IRBs) in the management process of large-scale datasets, and so on.

People who hit ‘like’ become more attractive!