New Intelligence Column
Author: Zhang Hao
[New Intelligence Guide] The author of this article comes from the Machine Learning and Data Mining Institute (LAMDA) of the Computer Science Department of Nanjing University. This article systematically summarizes the applications of deep learning in four fundamental tasks in the field of computer vision, including image classification, localization, detection, semantic segmentation, and instance segmentation.

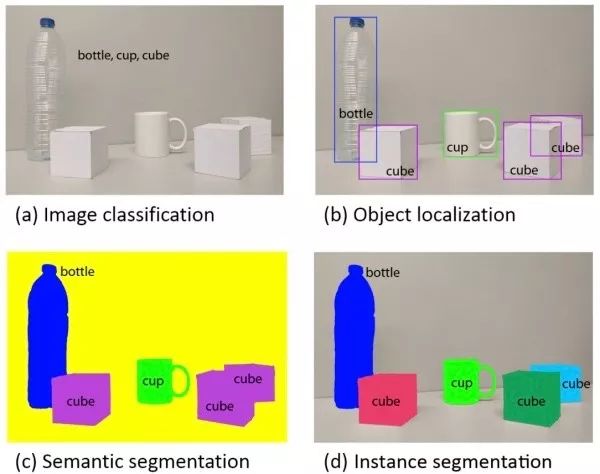
This article aims to introduce the applications of deep learning in the four fundamental tasks of computer vision, including classification (Figure a), localization, detection (Figure b), semantic segmentation (Figure c), and instance segmentation (Figure d).
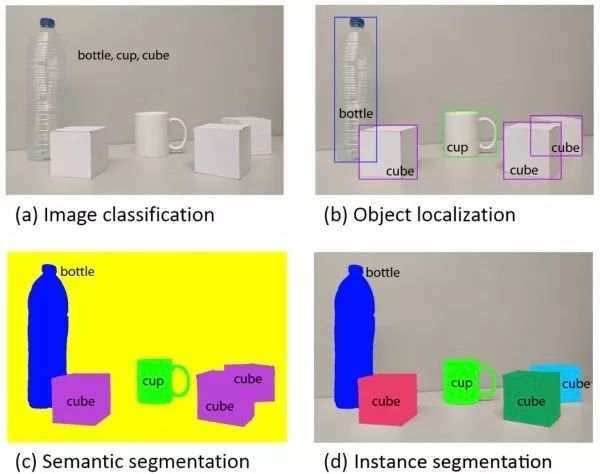
Given an input image, the task of image classification aims to determine the category to which the image belongs.
(1) Commonly Used Datasets for Image Classification
The following are several commonly used classification datasets, with increasing difficulty. http://rodrigob.github.io/are_we_there_yet/build/ lists the performance rankings of various algorithms on each dataset.
-
MNIST 60k training images, 10k testing images, 10 categories, image size 1×28×28, content is handwritten digits 0-9.
-
CIFAR-10 50k training images, 10k testing images, 10 categories, image size 3×32×32.
-
CIFAR-100 50k training images, 10k testing images, 100 categories, image size 3×32×32.
-
ImageNet 1.2M training images, 50k validation images, 1k categories. From 2017 and earlier, there was an annual ILSVRC competition based on the ImageNet dataset, which is equivalent to the Olympics in the field of computer vision.
(2) Classic Network Structures for Image Classification
Basic Architecture We use conv to represent convolutional layers, bn to represent batch normalization layers, and pool to represent pooling layers. The most common network structure sequence is conv -> bn -> relu -> pool, where the convolutional layer is used for feature extraction, and the pooling layer is used to reduce spatial size. As the depth of the network increases, the spatial size of the image will become smaller, while the number of channels will increase.
How to Design a Network for Your Task? When facing your actual task, if your goal is to solve that task rather than invent a new algorithm, do not try to design a completely new network structure yourself, nor try to reproduce existing network structures from scratch. Find publicly available implementations and pretrained models for fine-tuning. Remove the last fully connected layer and corresponding softmax, add a fully connected layer and softmax corresponding to your task, and then freeze the preceding layers, only training the parts you added. If you have a lot of training data, you can fine-tune several layers or even fine-tune all layers.
-
LeNet-5 60k parameters. The basic architecture of the network is: conv1 (6) -> pool1 -> conv2 (16) -> pool2 -> fc3 (120) -> fc4 (84) -> fc5 (10) -> softmax. The number in parentheses represents the number of channels, and the number 5 in the network name indicates that it has 5 layers of conv/fc layers. At that time, LeNet-5 was successfully used in ATMs to recognize handwritten digits in checks. LeNet is named after its author, LeCun.
-
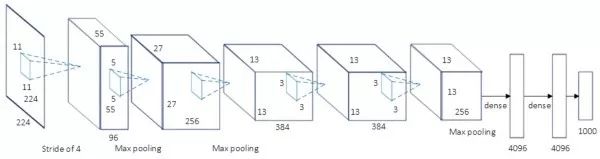
AlexNet 60M parameters, the champion network of ILSVRC 2012. The basic architecture of the network is: conv1 (96) -> pool1 -> conv2 (256) -> pool2 -> conv3 (384) -> conv4 (384) -> conv5 (256) -> pool5 -> fc6 (4096) -> fc7 (4096) -> fc8 (1000) -> softmax. AlexNet has a similar network structure to LeNet-5 but is deeper and has more parameters. Conv1 uses an 11×11 filter with a stride of 4 to rapidly reduce spatial size (227×227 -> 55×55). The key points of AlexNet are: (1) uses the ReLU activation function, which allows for better gradient characteristics and faster training; (2) uses dropout; (3) extensively uses data augmentation techniques. AlexNet is significant because it won that year’s ILSVRC competition with a 10% higher performance than the second place, making people realize the advantages of convolutional neural networks. Additionally, AlexNet also made people aware that GPUs can be used to accelerate the training of convolutional neural networks. AlexNet is named after its author, Alex.
-
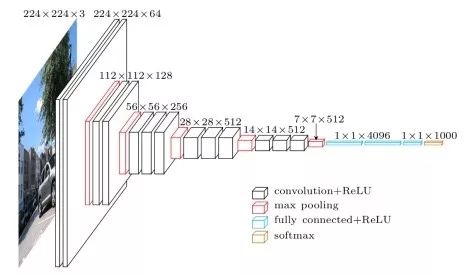
VGG-16/VGG-19 138M parameters, the runner-up network of ILSVRC 2014. The basic architecture of VGG-16 is: conv1^2 (64) -> pool1 -> conv2^2 (128) -> pool2 -> conv3^3 (256) -> pool3 -> conv4^3 (512) -> pool4 -> conv5^3 (512) -> pool5 -> fc6 (4096) -> fc7 (4096) -> fc8 (1000) -> softmax. ^3 indicates it is repeated 3 times. The key points of the VGG network are: (1) simple structure, only two configurations of 3×3 convolution and 2×2 pooling, and the same module combinations are stacked repeatedly. The convolutional layer does not change the spatial size, and each pooling layer halves the spatial size; (2) large number of parameters, most of which are concentrated in the fully connected layers. The number 16 in the network name indicates it has 16 layers of conv/fc layers; (3) appropriate network initialization and the use of batch normalization layers are important for training deep networks. VGG-19 has a similar structure to VGG-16, with slightly better performance than VGG-16, but VGG-19 consumes more resources, so VGG-16 is used more in practice. Due to the simplicity of the VGG-16 network structure and its suitability for transfer learning, VGG-16 is still widely used today. VGG-16 and VGG-19 are named after the research group to which the authors belong (Visual Geometry Group).
-
GoogLeNet 5M parameters, the champion network of ILSVRC 2014. GoogLeNet attempts to answer the question of what size of convolution to choose when designing a network or whether to choose pooling layers. It proposes the Inception module, which simultaneously uses 1×1, 3×3, 5×5 convolutions and 3×3 pooling while retaining all results. The basic architecture of the network is: conv1 (64) -> pool1 -> conv2^2 (64, 192) -> pool2 -> inc3 (256, 480) -> pool3 -> inc4^5 (512, 512, 512, 528, 832) -> pool4 -> inc5^2 (832, 1024) -> pool5 -> fc (1000). The key points of GoogLeNet are: (1) multi-branch processing and cascading results; (2) to reduce computation, it uses 1×1 convolutions for dimensionality reduction. GoogLeNet uses global average pooling instead of fully connected layers, significantly reducing the number of network parameters. GoogLeNet is named after the author’s institution (Google), with the capital