
Follow the official account “ML_NLP“ and set it as a “Starred“, delivering heavy content to you at the first time!

Author丨Gemfield@@ZhihuSource丨https://zhuanlan.zhihu.com/p/61765561、https://zhuanlan.zhihu.com/p/65822256Editor丨Jishi PlatformThis article is for academic sharing only, and copyright belongs to the author. If there is any infringement, please contact the backend for deletion.PyTorch Dynamic Graph (Part 1)
Background
The dynamic graph framework of PyTorch is primarily implemented by the code under torch/csrc/autograd. This directory defines three main base classes: Variable, Function, Engine, which together form the foundation of the PyTorch dynamic graph. Why is it called a dynamic graph? The graph is easy to understand, where Function represents nodes/vertices, and (Function, input_nr) represents edges. Where is the dynamism reflected? A graph is constructed during each forward pass and destroyed during the backward pass. This article will delve into the PyTorch dynamic graph system based on the code under torch/csrc/autograd—this may be the most comprehensive article about PyTorch dynamic graphs on the internet. In the column article “Initialization of PyTorch” (https://zhuanlan.zhihu.com/p/57571317), Gemfield described the initialization process of PyTorch and mentioned the call to THPAutograd_initFunctions(): “The final THPAutograd_initFunctions() initializes the automatic differentiation system of torch, which is the foundation of the PyTorch dynamic graph framework.” This article will start with THPAutograd_initFunctions and take you into the world of PyTorch dynamic graphs. This is the first part, mainly introducing the inheritance system of the classes Function, Variable, Engine.
Autograd Initialization
The function THPAutograd_initFunctions is implemented as follows:
void THPAutograd_initFunctions()
{
THPObjectPtr module(PyModule_New("torch._C._functions"));
......
generated::initialize_autogenerated_functions();
auto c_module = THPObjectPtr(PyImport_ImportModule("torch._C"));
}
This function is used to initialize the cpp_function_types table, which maintains the mapping from C++ function types to Python types:
static std::unordered_map<std::type_index, thpobjectptr=""> cpp_function_types
</std::type_index,>This table stores the mapping relationships of functions related to autograd. What is its purpose? For example, if I print a Variable’s grad_fn in Python:
>>> gemfield = torch.empty([2,2],requires_grad=True)
>>> syszux = gemfield * gemfield
>>> syszux.grad_fn
<ThMulBackward object at 0x7f111621c350>
grad_fn is an instance of Function. We have defined so many backward functions in C++, but how can we access them in Python? It relies on the mapping provided by the above table. In fact, the cpp_function_types mapping table is designed to serve the purpose of printing grad_fn in Python.
Variable
Reference: https://zhuanlan.zhihu.com/p/64135058 Using the following code snippet as an example:
gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
It should be noted that the dynamic graph is established during the forward pass. The gemfieldout as the final output during the forward pass is, however, the initial input during the backward propagation—in the dynamic graph, we refer to it as the root. In the subsequent introduction of Engine, you will see that we will use this gemfieldout root to construct a GraphRoot instance, which serves as the input to the graph.
Function
Before introducing Function, let’s use the above code as an example. During a single forward pass, we will create the following instances of Variable and Function:
#Variable instances
gemfield --> grad_fn_ (Function instance) = None
--> grad_accumulator_ (Function instance) = AccumulateGrad instance 0x55ca7f304500
--> output_nr_ = 0
#Function instance, 0x55ca7f872e90
AddBackward0 instance --> sequence_nr_ (uint64_t) = 0
--> next_edges_ (edge_list) --> std::vector<edge> = [(AccumulateGrad instance, 0),(0, 0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu)]
--> alpha (Scalar) = 1
--> apply() --> uses AddBackward0's apply
#Variable instance
syszux --> grad_fn_ (Function instance) = AddBackward0 instance 0x55ca7f872e90
--> output_nr_ = 0
#Function instance, 0x55ca7f872e90
MulBackward0 --> sequence_nr_ (uint64_t) = 1
--> next_edges_ (edge_list) = [(AddBackward0 instance 0x55ca7f872e90,0),(AddBackward0 instance 0x55ca7f872e90,0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu)]
--> alpha (Scalar) = 1
--> apply() --> uses MulBackward0's apply
# #Variable instance, tmp obtained from syszux * syszux
tmp --> grad_fn_ (Function instance) = MulBackward0 instance 0x55ca7fada2f0
--> output_nr_ = 0
#Function instance, 0x55ca7fada2f0
MulBackward0 --> sequence_nr_ (uint64_t) = 2 (incremented within each thread)
--> next_edges_ (edge_list) = [(MulBackward0 instance 0x55ca7fada2f0,0),(0,0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu)]
--> self_ (SavedVariable) = shallow copy of tmp
--> other_ (SavedVariable) = shallow copy of 3
--> apply() --> uses MulBackward0's apply
#Variable instance
civilnet --> grad_fn_ (Function instance) = MulBackward0 instance 0x55ca7fada2f0 -
#Function instance, 0x55ca7feb358b0
MeanBackward0 --> sequence_nr_ (uint64_t) = 3 (incremented within each thread)
--> next_edges_ (edge_list) = [(MulBackward0 instance 0x55ca7fada2f0,0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType|[]|cpu)]
--> self_sizes (std::vector<int64_t>) = (2, 2)
--> self_numel = 4
--> apply() --> uses MulBackward0's apply
#Variable instance
gemfieldout --> grad_fn_ (Function instance) = MeanBackward0 instance 0x55ca7feb358b0
--> output_nr_ = 0
</int64_t></edge>These Function instances for backward computation are interconnected through next_edges_. Since the actual execution of these Functions occurs during the backward pass, the output relationships are exactly the reverse of those during the forward pass. They are connected through next_edges_. To summarize with a diagram, it looks like this:
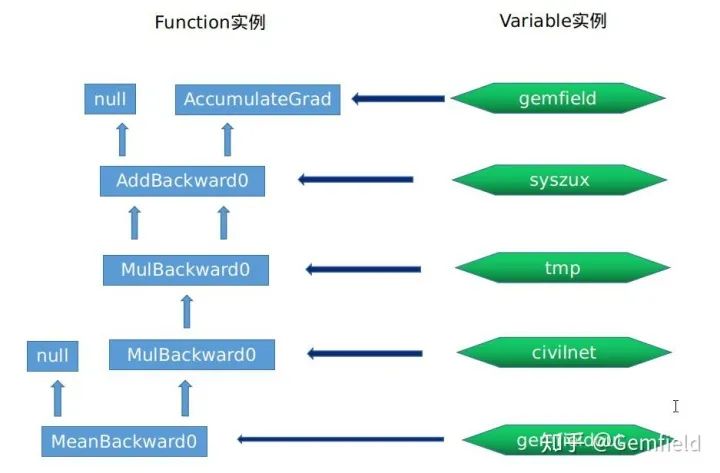
This introduces a new topic—how the Function class is abstracted. Function Base Class DefinitionThe data members of Function are as follows:
using edge_list = std::vector<edge>;
using variable_list = std::vector<variable>;
struct TORCH_API Function {
...
virtual variable_list apply(variable_list&& inputs) = 0;
...
const uint64_t sequence_nr_;
edge_list next_edges_;
PyObject* pyobj_ = nullptr; // weak reference
std::unique_ptr<anomalymetadata> anomaly_metadata_ = nullptr;
std::vector<std::unique_ptr<functionprehook>> pre_hooks_;
std::vector<std::unique_ptr<functionposthook>> post_hooks_;
at::SmallVector<inputmetadata, 2=""> input_metadata_;
};
</inputmetadata,></std::unique_ptr<functionposthook></std::unique_ptr<functionprehook></anomalymetadata></variable></edge>Function CallThe Function class is an abstract base class representing an operation (op), which can accept zero, one, or multiple Variable instances as parameters (encapsulated using std::vector) and simultaneously output zero, one, or multiple Variable instances. All functions used for backward propagation in PyTorch inherit from the Function class and override the pure virtual function apply in the Function class. Because the Function class implements the call function:
variable_list operator()(variable_list&& inputs) {
return apply(std::move(inputs));
}
Thus, relying on C++ polymorphism, the call of an op will translate into the apply call of itself (the subclass). The most important method in the Function class is the call function, which invokes apply. The call function receives multiple Variable instances encapsulated in a vector and outputs multiple Variable instances encapsulated in a vector. The length of the input parameters vector can be obtained by calling num_inputs(), and correspondingly, the length of the output vector can be obtained by num_outputs(). Function’s InputThe member input_metadata_ of Function represents the metadata of input data, defining the input of a Function:
struct InputMetadata {
...
const at::Type* type_ = nullptr;
at::DimVector shape_;
at::Device device_ = at::kCPU;
};
Edges and Vertices of the Autograd GraphIf we view PyTorch’s autograd system as a graph, then each Function instance is a node (nodes/vertices) in the graph, and the various Function instances are connected by Edges. An Edge is a structure that represents an edge in the graph through the pairing of (Function, input_nr):
struct Edge {
...
std::shared_ptr<function> function;
uint32_t input_nr;
};
</function>The member next_edges_ of Function is precisely a set of such Edge instances, representing the return values of this function instance that need to be output to (another) function, thus next_edges_ is the link between functions. The inputs and outputs of Function are all Variable instances, so when a graph is executed, Variable instances flow between these edges. When two or more Edges point to the same Function (the in-degree of this node is greater than 1), the outputs of these edges will be implicitly summed before being sent to the target Function. Functions are connected through the next_edge interface. You can use add_next_edge() to add an edge to a Function, retrieve the corresponding edge using next_edge(index), and obtain an iterator over edges using the next_edges() method. Each Function has a sequence number that monotonically increases as Function instances are constructed. You can obtain the sequence number of a Function using the sequence_nr() method.
Function Inheritance System
The base class Function directly derives from TraceableFunction and the following Functions:
CopySlices : public Function
DelayedError : public Function
Error : public Function
Gather : public Function
GraphRoot : public Function
Scatter : public Function
AccumulateGrad : public Function
AliasBackward : public Function
AsStridedBackward : public Function
CopyBackwards : public Function
DiagonalBackward : public Function
ExpandBackward : public Function
IndicesBackward0 : public Function
IndicesBackward1 : public Function
PermuteBackward : public Function
SelectBackward : public Function
SliceBackward : public Function
SqueezeBackward0 : public Function
SqueezeBackward1 : public Function
TBackward : public Function
TransposeBackward0 : public Function
UnbindBackward : public Function
UnfoldBackward : public Function
UnsqueezeBackward0 : public Function
ValuesBackward0 : public Function
ValuesBackward1 : public Function
ViewBackward : public Function
PyFunction : public Function
Among these, the classes derived from the base class Function, such as AccumulateGrad, TraceableFunction, and GraphRoot, are particularly crucial. Derived Class AccumulateGrad Let’s talk about AccumulateGrad, which is precisely the type of the grad_accumulator_ member of Variable:
struct AccumulateGrad : public Function {
explicit AccumulateGrad(Variable variable_);
variable_list apply(variable_list&& grads) override;
Variable variable;
};
It can be seen that an instance of AccumulateGrad must be constructed with a Variable, and the apply call receives a list of Variable instances—this is all related to the grad_accumulator_ of Variable. Derived Class GraphRoot For GraphRoot, the final output during the forward pass—as the initial input during the backward pass—is encapsulated by GraphRoot:
struct GraphRoot : public Function {
GraphRoot(edge_list functions, variable_list inputs)
: Function(std::move(functions)),
outputs(std::move(inputs)) {}
variable_list apply(variable_list&& inputs) override {
return outputs;
}
variable_list outputs;
};
GraphRoot—just as the soul of Function lies in apply—its apply function merely returns its inputs! Derived Class TraceableFunction Now let’s discuss TraceableFunction:
struct TraceableFunction : public Function {
using Function::Function;
bool is_traceable() final {
return true;
}
};
TraceableFunction will further derive 372 subclasses (as of April 2019), all of which contain a common part in their names: Backward. What does this indicate? These functions will only be used in backward propagation:
AbsBackward : public TraceableFunction
AcosBackward : public TraceableFunction
AdaptiveAvgPool2DBackwardBackward : public TraceableFunction
AdaptiveAvgPool2DBackward : public TraceableFunction
AdaptiveAvgPool3DBackwardBackward : public TraceableFunction
AdaptiveAvgPool3DBackward : public TraceableFunction
AdaptiveMaxPool2DBackwardBackward : public TraceableFunction
AdaptiveMaxPool2DBackward : public TraceableFunction
AdaptiveMaxPool3DBackwardBackward : public TraceableFunction
AdaptiveMaxPool3DBackward : public TraceableFunction
AddBackward0 : public TraceableFunction
AddBackward1 : public TraceableFunction
AddbmmBackward : public TraceableFunction
AddcdivBackward : public TraceableFunction
AddcmulBackward : public TraceableFunction
AddmmBackward : public TraceableFunction
AddmvBackward : public TraceableFunction
AddrBackward : public TraceableFunction
......
SoftmaxBackwardDataBackward : public TraceableFunction
SoftmaxBackward : public TraceableFunction
......
UpsampleBicubic2DBackwardBackward : public TraceableFunction
UpsampleBicubic2DBackward : public TraceableFunction
UpsampleBilinear2DBackwardBackward : public TraceableFunction
UpsampleBilinear2DBackward : public TraceableFunction
UpsampleLinear1DBackwardBackward : public TraceableFunction
UpsampleLinear1DBackward : public TraceableFunction
UpsampleNearest1DBackwardBackward : public TraceableFunction
UpsampleNearest1DBackward : public TraceableFunction
UpsampleNearest2DBackwardBackward : public TraceableFunction
UpsampleNearest2DBackward : public TraceableFunction
UpsampleNearest3DBackwardBackward : public TraceableFunction
UpsampleNearest3DBackward : public TraceableFunction
UpsampleTrilinear3DBackwardBackward : public TraceableFunction
UpsampleTrilinear3DBackward : public TraceableFunction
......
These 300+ Backward functions all override the apply function to implement their own backward differentiation algorithms, such as the backward function for addition AddBackward0:
struct AddBackward0 : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
Scalar alpha;
};
These apply functions are the soul of Function, representing the core execution logic during backward propagation.
Engine
The Engine class implements the backward propagation from the output variable (and its gradients) to the root variables (user-created and requires_grad=True).
gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
Using the above code snippet as an example, the Engine implements the backward propagation from gemfieldout to gemfield: 1. How to construct GraphRoot from gemfieldout; 2. How to construct the graph based on these Function instances and their metadata; 3. How to implement a Queue to complete the backward computation using multiple threads. Engine Class DefinitionThe definition of the Engine class is as follows:
struct Engine {
using ready_queue_type = std::deque<std::pair<std::shared_ptr<function>, InputBuffer>>;
using dependencies_type = std::unordered_map<function*, int="">;
virtual variable_list execute(const edge_list& roots,const variable_list& inputs,...const edge_list& outputs = {});
void queue_callback(std::function<void()> callback);
protected:
void compute_dependencies(Function* root, GraphTask& task);
void evaluate_function(FunctionTask& task);
void start_threads();
virtual void thread_init(int device);
virtual void thread_main(GraphTask *graph_task);
std::vector<std::shared_ptr<readyqueue>> ready_queues;
};
</std::shared_ptr<readyqueue></void()></function*,></std::pair<std::shared_ptr<function>The core of this class is the execute function, which accepts a set of Edges—(Function, input number) pairs—as the input to the function, and then finds the next Edge through next_edge to ultimately complete the computation of the entire Graph. Derived Class PythonEngine However, the one we actually use is the derived class of the Engine: PythonEngine. The PythonEngine subclass overrides the execute function of the parent class, but merely provides the functionality of translating C++ exceptions into Python exceptions; the core work is still done by the Engine base class:
struct PythonEngine : public Engine
The entire PyTorch program maintains only one Engine instance, which is the PythonEngine instance.
BP Call Stack
Since the Engine is used to compute the backward propagation of the network, let’s take a look at how the call stack reaches the Engine class. If we perform backward computation on gemfieldout, the call stack is as follows:
#torch/tensor.py, self is gemfieldout
def backward(self, gradient=None, retain_graph=None, create_graph=False)
|
V
#torch.autograd.backward(self, gradient, retain_graph, create_graph)
#torch/autograd/__init__.py
def backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)
|
V
Variable._execution_engine.run_backward(tensors, grad_tensors, retain_graph, create_graph,allow_unreachable=True)
# Translated to Variable._execution_engine.run_backward((gemfieldout,), (tensor(1.),), False, False,True)
|
V
#torch/csrc/autograd/python_engine.cpp
PyObject *THPEngine_run_backward(THPEngine *self, PyObject *args, PyObject *kwargs)
|
V
#torch/csrc/autograd/python_engine.cpp
variable_list PythonEngine::execute(const edge_list& roots, const variable_list& inputs, bool keep_graph, bool create_graph, const edge_list& outputs)
|
V
#torch/csrc/autograd/engine.cpp
Engine::execute(roots, inputs, keep_graph, create_graph, outputs)
Summary
In the next article, Gemfield will mainly introduce how the Engine class operates the PyTorch dynamic graph in gemfieldout.backward(). PyTorch Dynamic Graph (Part 2)
Background
In the previous article, we introduced the three cornerstones of the PyTorch autograd system: Variable, Function, Engine. To summarize in a simple sentence, the Engine uses a Graph constructed by Functions to compute the gradients on Variables. In this article, Gemfield will take the following code snippet as an example to detail how the Engine constructs the Graph for backward propagation calculations:
gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
BP Engine
BP Engine is a class used for dynamically generating computation graphs during backward propagation calculations, and currently, there is only one implementation of BP Engine defined in PyTorch. 1. Engine Class Definition The definition of the Engine class used for dynamically generating backward propagation computation graphs is as follows:
struct Engine {
using ready_queue_type = std::deque<std::pair<std::shared_ptr<function>, InputBuffer>>;
using dependencies_type = std::unordered_map<function*, int="">;
virtual variable_list execute(const edge_list& roots,const variable_list& inputs,...const edge_list& outputs = {});
void queue_callback(std::function<void()> callback);
protected:
void compute_dependencies(Function* root, GraphTask& task);
void evaluate_function(FunctionTask& task);
void start_threads();
virtual void thread_init(int device);
virtual void thread_main(GraphTask *graph_task);
std::vector<std::shared_ptr<readyqueue>> ready_queues;
};
</std::shared_ptr<readyqueue></void()></function*,></std::pair<std::shared_ptr<function>After the forward pass ends with the output gemfieldout, we use gemfieldout as the input for backward propagation. 2. Engine Class’s start_threads Member As the name suggests, start_threads is used to start threads, determining the number of threads to be started based on the number of devices. This function is invoked using std::call_once(start_threads_flag, &Engine::start_threads, this) to ensure that the start_threads member function is only called once throughout the entire process lifecycle. The main purposes of this function are: 1. To create multiple instances of ReadyQueue, managed using the ready_queues vector. The number of ReadyQueues is the same as the number of threads to be newly created:
ready_queues = std::vector<std::shared_ptr<readyqueue>>(num_threads);
for (auto& queue : ready_queues){
queue.reset(new ReadyQueue());
}
</std::shared_ptr<readyqueue>2. To create multiple new threads, with the number of threads depending on the number of devices. Each CPU counts as one device, and each GPU card counts as one device, plus one. For instance, if there are four RTX 2080ti graphics cards on the system, five threads will be started here; if there is only a CPU without a GPU, then two threads will be started. This member function uses std::thread to start and manage threads. An important point is that the this pointer is passed when creating threads:
for (int i = 0; i < num_threads; ++i) {
std::thread t(&Engine::thread_init, this, i - 1);
t.detach();
}
The this pointer is the current instance of Engine, and throughout the lifecycle of the entire process, there is only this Engine instance. The sharing of this brings a surprise: the current process and the newly started threads can share the same Engine instance—both data members and function members. In the following sections, you will see that our Queue relies on this sharing to achieve object transfer between threads. 3. Engine Class’s ready_queues The definition of ready_queues is as follows:
std::vector<std::shared_ptr<readyqueue>> ready_queues;
</std::shared_ptr<readyqueue>It can be seen that ready_queues manages several instances of ReadyQueue using a vector. This allows us to index each device’s dedicated ReadyQueue using the device index. ReadyQueue is used to transfer FunctionTask objects (which will be introduced later), and its definition is as follows:
struct ReadyQueue {
std::priority_queue<functiontask, std::vector<functiontask="">, CompareFunctionTaskTime> heap;
std::condition_variable not_empty;
std::mutex mutex;
void push(FunctionTask item);
FunctionTask pop();
};
</functiontask,>ReadyQueue using priority_queue as its backend indicates that the order of consumption does not equal the order of production—based on the definition of CompareFunctionTaskTime—the smaller the sequence_nr(), the sooner it will be consumed. ReadyQueue employs C++11’s condition_variable for inter-thread synchronization, using condition_variable‘s notify_one to notify a consuming thread, which is equivalent to unblocking one of the consuming threads (while notify_all would notify all consuming threads). Correspondingly, the consuming thread uses condition_variable‘s wait to receive synchronization information. The ReadyQueue class defines push and pop methods, representing the production and consumption behaviors respectively:
auto ReadyQueue::push(FunctionTask item) -> void {
{
std::lock_guard<std::mutex> lock(mutex);
++item.base->outstanding_tasks;
heap.push(std::move(item));
}
not_empty.notify_one();
}
auto ReadyQueue::pop() -> FunctionTask {
std::unique_lock<std::mutex> lock(mutex);
not_empty.wait(lock, [this]{ return !heap.empty(); });
auto task = std::move(const_cast<functiontask&>(heap.top()));
heap.pop();
return task;
}
//wait equivalent to the following, to prevent exceptional exit
while(heap.empty()){
not_empty.wait(lock);
}
</functiontask&></std::mutex></std::mutex>4. Engine Class’s thread_init MemberThe thread_init function will execute the initialization work for threads started by start_threads:
auto Engine::thread_init(int device) -> void {
at::init_num_threads();
std::array<c10::optionaldeviceguard,static_cast<size_t>(c10::DeviceType::COMPILE_TIME_MAX_DEVICE_TYPES)> guards;
if (device != -1) {
for (size_t i = 0; i < static_cast<size_t>(c10::DeviceType::COMPILE_TIME_MAX_DEVICE_TYPES); i++) {
auto* impl = c10::impl::device_guard_impl_registry[i].load();
if (impl && device < impl->deviceCount()) {
guards[i].reset_device(at::Device(static_cast<c10::devicetype>(i), device));
}
}
}
worker_device = device;
thread_main(nullptr);
}
</c10::devicetype></size_t></c10::optionaldeviceguard,static_cast<size_t>This sets the value of each thread’s worker_device to be the device number minus one, hence starting from -1. For instance, if there is only one CPU device, then start_threads will start two threads. The values for worker_device will be -1 and 0 respectively. Additionally, the value for worker_device in the main process is NO_DEVICE (-2). Apart from setting this worker_device value, the initialization work mainly involves setting the devices in the guards array starting from the second worker thread. After the thread initialization is complete, the actual thread execution logic will be called. 5. GraphTask in the Engine ClassThe GraphTask used in the Engine class is defined as follows:
struct GraphTask {
std::atomic<uint64_t> outstanding_tasks;
bool keep_graph;
bool grad_mode;
std::mutex mutex;
std::condition_variable not_done;
std::unordered_map<function*, inputbuffer=""> not_ready;
std::unordered_map<function*, int=""> dependencies;
struct ExecInfo {
bool needed = false;
};
std::unordered_map<function*, execinfo=""> exec_info;
int owner;
GraphTask(bool keep_graph, bool grad_mode): has_error(false), \
outstanding_tasks(0), keep_graph(keep_graph), grad_mode(grad_mode), owner(NO_DEVICE) {}
};
</function*,></function*,></function*,></uint64_t>In the execution of the Engine’s execute function, we will define an instance of graph_task:
GraphTask graph_task(keep_graph, create_graph);
The important members of GraphTask are: Member 1: outstanding_tasks, which is a number that, when a GraphTask instance is created, is initialized to 0; when it is subsequently sent to the ReadyQueue, outstanding_tasks is incremented by 1; then, each time a Function is executed in the evaluate_function(task), its value decreases by 1. In the main process, there will be a thread synchronization logic depending on this value:
while(graph_task.outstanding_tasks.load() != 0){
graph_task.not_done.wait(lock);
}
It can be seen that the main process will wait here until the functions on this graph_task instance are evaluated. Member 2: keep_graph, which is a boolean value that indicates whether to release resources after a backward computation. What resources? The resources established during the forward process. If keep_graph is false, then resources will be released after the function execution is completed:
if (!task.base->keep_graph) {
fn.release_variables();
}
As mentioned earlier, the hundreds of backward computation Functions all have a soul function—apply; in fact, there is also a soul function for resource recovery—release_variables. For example:
struct MulBackward0 : public TraceableFunction {
void release_variables() override {
self_.reset_data();
self_.reset_grad_function();
other_.reset_data();
other_.reset_grad_function();
}
SavedVariable self_;
SavedVariable other_;
};
Member 3: grad_mode, this is a boolean value used to indicate whether the current context is to calculate gradients.
bool GradMode::is_enabled() {
return GradMode_enabled;
}
void GradMode::set_enabled(bool enabled) {
GradMode_enabled = enabled;
}
During the entire backward calculation, the code logic executed relies on GradMode::is_enabled() to determine whether gradients should be computed. Member 4: mutex, of type std::mutex. This is a synchronization primitive between threads, where only one can hold the same mutex at a time, while others must wait. To prevent deadlocks and other situations, we use RAII to manage the mutex intelligently, with typical representatives being std::lock_guard and std::unique_lock. By default, std::lock_guard is used, which automatically releases the mutex once the function execution is completed (essentially at the end of a block scope); however, std::lock_guard can only acquire and release the mutex through its constructor and destructor. On the other hand, std::unique_lock provides more fine-grained control, allowing for manual locking and unlocking through its lock and unlock methods, increasing the parallelism of the code. Member 5: not_done, of type std::condition_variable. This is for inter-thread communication. Remember that in the main process, once we send a FunctionTask object to the Queue, the main process begins to wait:
while(graph_task.outstanding_tasks.load() != 0){
graph_task.not_done.wait(lock);
}
The while loop is to prevent exceptional exit, and the core is the not_done condition. not_done.wait(lock) blocks here—waiting for the worker thread to signal not_done.notify_all(). Member 6: not_ready, of type std::unordered_map<Function*, InputBuffer>. This is used to temporarily store not-ready functions and their inputs. Member 7: dependencies, of type std::unordered_map<Function*, int>. This instance’s dependencies member is initialized in the compute_dependencies call; as long as a grad_fn function appears once in another’s next_edges(), then dependencies[this_grad_fn] increases by 1. Member 8: exec_info, of type std::unordered_map<Function*, ExecInfo>. If this map is empty, it indicates that the task is in default mode—all functions encountered in next_edges will be executed. If exec_info is not empty, only Functions containing entries with needed == true will be executed. Member 9: owner, of type int. This indicates which thread created the GraphTask, and its value corresponds to the worker_device value in that thread. 6. FunctionTask in the Engine Class The FunctionTask used in the Engine class is defined as:
struct FunctionTask {
GraphTask* base;
std::shared_ptr<function> fn;
InputBuffer inputs;
FunctionTask(GraphTask* base, std::shared_ptr<function> fn, InputBuffer inputs): \
base(base), fn(std::move(fn)), inputs(std::move(inputs)) {}
};
</function></function>This class instance is what is transferred in the queue. From the above definition, we can see that we build a FunctionTask instance using GraphTask, Function, and InputBuffer:
# In the main process
FunctionTask(&graph_task, std::move(graph_root), InputBuffer(0)
Initializing graph_root is straightforward, constructed from roots and inputs, where roots are derived from the gradient_edge() of gemfieldout—i.e., grad_fn—specifically, the instance of MeanBackward0 and output_nr—i.e., (MeanBackward0 instance, 0); while inputs are tensor(1.). After sending a FunctionTask instance to the queue in the main process, in the worker thread, we access the GraphTask instance through task.base, access the roots instance through task.fn, and access the InputBuffer instance through task.inputs. In the worker thread, we may also construct new FunctionTask instances and add them to the queue like this:
# In the work thread
FunctionTask(task.base, nullptr, InputBuffer(0)
# evaluate function
FunctionTask(task.base, next.function, std::move(input_buffer))
7. compute_dependencies in the Engine Class Remember the graph_task instance defined in 5? Recall that graph_task has a member called dependencies? Remember that dependencies is of type std::unordered_map<Function*, int>? Yes, this function only does one thing: as long as a grad_fn function appears once in another’s next_edges(), then dependencies[this_grad_fn] increases by 1. 8. execute in the Engine Class This is the soul function of the Engine, and it is the main body of the execution logic of the Engine. During a backward pass, this function will be executed once. It primarily performs the following tasks: 1. Calls Engine::start_threads to start multiple worker threads; note that start_threads will only be executed once throughout the entire process cycle; 2. Instantiates a graph_task instance; 3. Initializes a local mutex in the execute function using the mutex of the aforementioned graph_task; 4. Constructs GraphRoot; 5. Executes compute_dependencies; 6. Sends a FunctionTask instance to the queue; 7. Waits for the worker thread to complete the computation before finishing. 9. thread_main Member of the Engine Class The thread_main function serves as the execution entity for the threads started by start_threads:
auto Engine::thread_main(GraphTask *graph_task) -> void {
auto queue = ready_queues[worker_device + 1];
while (!graph_task || graph_task->outstanding_tasks > 0) {
FunctionTask task = queue->pop();
if (task.fn && !task.base->has_error.load()) {
GradMode::set_enabled(task.base->grad_mode);
evaluate_function(task);
}
auto base_owner = task.base->owner;
if (base_owner == NO_DEVICE) {
if (--task.base->outstanding_tasks == 0) {
std::lock_guard<std::mutex> lock(task.base->mutex);
task.base->not_done.notify_all();
}
} else {
if (base_owner == worker_device) {
--task.base->outstanding_tasks;
} else if (base_owner != worker_device) {
if (--task.base->outstanding_tasks == 0) {
std::atomic_thread_fence(std::memory_order_release);
ready_queue_by_index(base_owner).push(FunctionTask(task.base, nullptr, InputBuffer(0)));
}
}
}
}
}
</std::mutex>The main body is a while loop that continuously retrieves FunctionTask instances from the dedicated queue and executes evaluate_function—this is the main logic. After the evaluate_function is completed, if: 1. This task comes from the main process and the outstanding_tasks of the task has dropped to 0 (note that outstanding_tasks will continue to change in evaluate_function), then it notifies the main process’s waiting synchronization primitive to prepare for ending backward computation; 2. If this task comes from the current work thread, then outstanding_tasks decreases by 1; 3. If this task comes from another work thread, then outstanding_tasks decreases by 1, and if it drops to 0, a dummy function task is sent to the queue of that worker thread. 10. evaluate_function in the Engine Class The core of this function is to check whether the count of a function in the GraphTask dependencies has decreased to 0—i.e., whether it is ready (usually because it has multiple inputs). If it is ready, the task will be sent to the queue for computation; if not, it will be placed in GraphTask‘s not_ready and the corresponding InputBuffer input will be prepared. The task sent to the queue is different from the previous GraphRoot because its owner is not the main process—it’s created in the worker thread. 1. If the device of the input variable of a node is known, then the FunctionTask object composed of that node will be sent to the queue of the corresponding worker thread; 2. When preparing a node, if is_ready is true, it indicates that this node will no longer be dependent on future computations, and the FunctionTask composed of this node will be sent to the queue, and the information will be removed from the Graph (GraphTask)—removed from the dependencies of GraphTask and removed from not_ready of GraphTask; 3. When preparing a node, if is_ready is false, this usually indicates that this node has multiple inputs (connected by more nodes, the number can be obtained using num_inputs()), so the first time this node is encountered, it will not be sent to the queue, but placed in GraphTask‘s not_ready, while setting the first input for that node:
input_buffer.add(next.input_nr, std::move(output))
not_ready.emplace(next.function.get(), std::move(input_buffer));
When this node is encountered a second time, the second input for that node will be set:
auto &input_buffer = not_ready_it->second;
input_buffer.add(next.input_nr, std::move(output));
And so on, until the count in dependencies drops to 0—is_ready changes from false to true—this node will no longer be dependent on future computations. At this point, the FunctionTask composed of this node will finally be sent to the queue, and the information will be removed from the Graph (GraphTask)—removed from the dependencies of GraphTask and removed from not_ready of GraphTask. Additionally, the construction of the input_buffer is quite interesting; when adding an input to a node:
input_buffer.add(next.input_nr, std::move(output));
the input_nr clearly indicates which input of the node is to be flowed to the node during backward propagation! 11. call_function in the Engine Class The logic of this function is relatively simple; it calls the various backward computation functions and the hooks registered above. Note the inputs and outputs of fn; as Gemfield mentioned in “PyTorch’s Tensor“, the inputs are a set of Variable instances—InputBuffer::variables(std::move(task.inputs)), and the outputs are also a set of Variable instances, after all, outputs serve as inputs for the next function/node. The relevant code is as follows:
static variable_list call_function(FunctionTask& task) {
auto& fn = *task.fn;
auto inputs = call_pre_hooks(fn, InputBuffer::variables(std::move(task.inputs)));
const auto has_post_hooks = !fn.post_hooks().empty();
variable_list outputs = fn(std::move(inputs));
if(has_post_hooks){
return call_post_hooks(fn, std::move(outputs), inputs);
}
return outputs;
}
1. Call the pre_hooks registered on the node; 2. Call the node itself, such as MeanBackward0, MulBackward0, etc.; 3. Call the post hooks registered on the node.
Summary
In this article, Gemfield further introduced the PyTorch dynamic graph, mainly focusing on the Engine class. Now you are familiar with the fact that during backward propagation calculations, multiple threads will be started based on the number of devices, with each thread associated with a Queue. Each worker thread has an associated device, and the main process, worker threads, and worker threads communicate through the queue to transfer inputs and computation results. Tasks are sent to the corresponding Queue based on the device of the input—thus, the computation will occur in the worker thread associated with that device. The data flows through each fn/node, obtaining outputs that serve as inputs for the next fn/node, all of which are a set of Variable instances.
Download 1: Four Essentials
Reply "Four Essentials" in the backend of the Machine Learning Algorithms and Natural Language Processing official account to obtain learning materials for TensorFlow, PyTorch, machine learning, and deep learning!
Download 2: Repository Sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing official account to access 195 NAACL papers and 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Exciting! The Machine Learning Algorithms and Natural Language Processing exchange group has officially been established! The group contains a wealth of resources, and everyone is welcome to join and learn!
Additional welfare resources! Deep Learning and Neural Networks by Qiu Xipeng, official Chinese tutorial for PyTorch, data analysis with Python, machine learning notes, official documentation of pandas in Chinese, Effective Java (Chinese version), and 20 other welfare resources.
Access method: After entering the group, click on the group announcement to get the download link. Please modify the remarks when adding as [School/Company + Name + Direction] For example —— Harbin Institute of Technology + Zhang San + Dialogue System. The account owner and micro-businesses please consciously avoid. Thank you!
Recommended Reading:
A Review of Open-Domain Knowledge Base Question Answering Research
Automatically Train Your Deep Neural Network Using PyTorch Lightning
Collection of Commonly Used PyTorch Code Snippets