Click the “MLNLP” above to select the “Starred” public account.
Heavyweight content delivered promptly.
Author: Tian Yu Su
https://zhuanlan.zhihu.com/p/27087310
Introduction
Recently, I finished reading some foreign materials on LSTM, mainly referencing Colah’s blog and Andrej Karpathy’s blog on RNN and LSTM, and I am preparing to implement an LSTM model. The basic framework of the code comes from a demo in the paid course of the Deep Learning Nanodegree on Udacity. When I first looked at the code, I was really confused and didn’t understand many things. Later, after repeatedly reviewing the materials, I re-studied and modified the code, further analyzing the steps. Below, I will step by step build an LSTM model using TensorFlow for text learning and attempt to generate new text. This article is suitable for beginners to operate, and the LSTM layer uses BasicLSTMCell.
This article does not introduce RNN and LSTM models; for details, please refer to the above blog link, which explains it very clearly. This article is mainly practical, aimed at constructing the LSTM model by hand.
The dataset comes from the text document of the foreign version of “Anna Karenina” (the entire project’s Git link will be provided later in this article).
Tool Introduction
-
Language: Python 3
-
Packages: TensorFlow and other data processing packages (see in the code)
-
Editor: Jupyter Notebook
-
Online GPU: Floyd
———————————————————————————————————-
Main Content
The main content includes the following four parts:
– Data Preprocessing: Loading data, converting data, splitting data mini-batches.
– Model Construction: Input layer, LSTM layer, output layer, training error, loss, optimizer.
– Model Training: Setting model parameters to train the model.
– Generating New Text: Training new text.
Theme: The entire text will be based on the English text of “Anna Karenina” as the training data for the LSTM model, with input as single characters. By learning the characters (including letters and punctuation) of the entire English document, we will generate text. Before starting modeling, we must clarify our input and output. The input is characters, and the output is the predicted new characters.
1. Data Preprocessing
Before starting the model, we first need to import the required packages:
import time
import numpy as np
import tensorflow as tfThis part mainly includes data conversion and mini-batch splitting steps.
First, let’s load the data and convert the encoding. Since we are building the model based on characters (individual strings like letters and punctuation, collectively referred to as characters), it means our input and output are both characters. For example, if we have a word “hello”, we want to build an LSTM based on this word, the expected result is that when inputting “h”, the next predicted letter is “e”; when inputting “e”, the next predicted letter is “l”, and so on.
Thus, our input consists of individual letters, and we will convert the text.

The code above mainly accomplishes the following three tasks:
– Obtains the set of all characters in the text vocab.
– Obtains a character-number mapping vocab_to_int.
– Obtains a number-character mapping int_to_vocab.
– Creates a list encoded after transcoding the original text.
After completing the previous data preprocessing operations, the next step is to split our dataset. Here we use mini-batches for model training. So how do we split the dataset? Before performing mini-batch splitting, let’s first understand a few concepts.
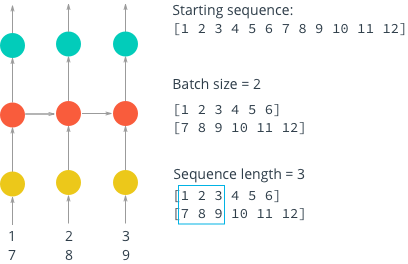
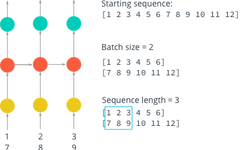
If we currently have a sequence from 1 to 12, we will use this sequence as an example to explain several concepts in mini-batch partitioning. First, let’s review that in DNN and CNN, we will input data in batches to the neural network. Suppose we have 100 samples and set our batch_size=10, then it means we will input 10 samples to the neural network for training to adjust parameters each time. Similarly, in LSTM, batch_size means how many samples are input to the network at a time. In the above figure, when we set batch_size=2, we will divide the entire sequence into 6 batches, each containing two numbers.
However, due to the “memory” in RNN, i.e., the recurrence. In fact, a recurrent neural network can be viewed as a stacking of multiple identical neural networks. In this system, each network passes information to the next. In the above figure, we can see that the entire RNN network consists of a sequence of three identical neural network units stacked. Thus, we have the second concept, sequence_length (also called steps), which refers to the length of the sequence. In the above figure, the sequence length is 3, indicating that three characters form a sequence.
With the above two concepts, let’s standardize the definitions for the following. We define the number of sequences in a batch as N (i.e., batch_size), and the length of a single sequence as M (which is our num_steps). So in fact, each batch is an N*M array, which means we have N*M characters in each batch. In the above figure, when we set N=2 and M=3, we can get the size of each batch as 2 x 3 = 6 characters, and the entire sequence can be divided into 12 / 6 = 2 batches.
Based on the above analysis, let’s proceed to split the mini-batch:

The code above defines a generator, and calling the function will return a generator object from which we can obtain a batch.
After the above steps, we have completed the preprocessing of the dataset. Next, we will start building the model.
2. Model Construction
The model construction part mainly includes the input layer, LSTM layer, output layer, loss, optimizer, and other parts, which we will implement piece by piece.
1. Input Layer
In the data preprocessing stage, we defined the mini-batch splitting function. The size of the input layer depends on the batch size we set (n_seqs X n_steps). Below, we will first construct the input layer.

Similarly, the shape of the output layer is N*M (because inputting one character will also output one character). In addition to input and output, we also define the keep_prob parameter to control the number of retained nodes in the dropout layer later. For more on dropout regularization, please refer to the link.
2. LSTM Layer
The LSTM layer is the key part of the entire neural network. In TensorFlow, the tf.contrib.rnn module has BasicLSTMCell and LSTMCell packages, and their differences are:
BasicLSTMCell does not allow cell clipping, a projection layer, and does not use peep-hole connections: it is the basic baseline. (From TensorFlow official website)
Here we only use the basic module BasicLSTMCell.

In the code above, I did not use the tf.contrib.rnn module because when I ran the code on the remote Floyd GPU, it told me that this module could not be found. I can use tf.nn.rnn_cell.BasicLSTMCell instead. After constructing the LSTM cell, to prevent overfitting, I added dropout regularization to its hidden layer.
The subsequent MultiRNNCell implements the sequential stacking of the basic LSTM cell, which receives a list of cell objects. Finally, initial_state defines the initial cell state.


After reshaping the data, we connect the LSTM layer and the softmax layer and calculate the logits and the probability distribution after softmax.
4. Training Error Calculation
At this point, we have completed the entire network construction. Next, we need to define the train loss and optimizer. We know that the output from the softmax layer is a probability distribution, so we need to one-hot encode the targets. We use softmax_cross_entropy_with_logits to calculate the loss.

5. Optimizer
We know that RNN will encounter the problems of gradient exploding and gradient vanishing. LSTM solves the problem of gradient vanishing, but gradients may still explode. Therefore, we adopt gradient clipping to prevent gradient explosion. That is, by setting a threshold, when gradients exceed this threshold, they are reset to the threshold size, ensuring that the gradients do not become too large.

tf.clip_by_global_norm will return the clipped gradients and global_norm. The entire learning process uses AdamOptimizer.
6. Model Combination
After the above five steps, we have completed all module settings. Now let’s combine these parts to build a class.
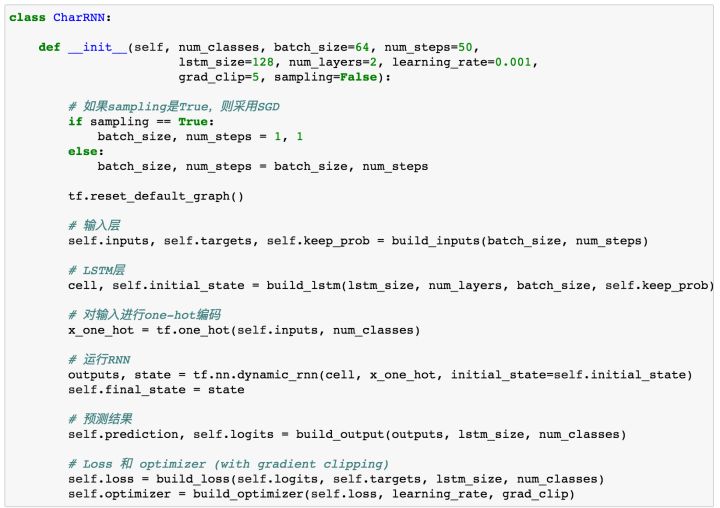
We use tf.nn.dynamic_rnn to run the RNN sequence.
3. Model Training
Before model training, we first need to initialize some parameters. Our parameters mainly include:
-
batch_size: Number of sequences in a single batch
-
num_steps: Number of characters in a single sequence
-
lstm_size: Number of hidden layer nodes
-
num_layers: Number of LSTM layers
-
learning_rate: Learning rate
-
keep_prob: Proportion of retained nodes in the dropout layer during training

These are some parameters I set myself. Specific tuning experiences can refer to Andrej Karpathy’s suggestions on GitHub.
After setting the parameters, we are just one step away from running the entire LSTM. Next, we will run the entire model.

I set the number of iterations to 20, and in the code execution, we set the node saving, and every 200 iterations, we save the variables. This is beneficial for us to visually observe how the text generation results evolve step by step during the training process.
4. Text Generation
After a long model training, we obtain a series of parameters saved during the training process, which can be used for text generation. When we input a character, it will predict the next one. We can continuously input this new character into the model to generate characters, thereby forming text.

The code encapsulates two functions for text generation; please refer to the source code in the Git link at the end of the article for details.
Training Steps: 200
When the training steps are 200, the text generated by LSTM looks something like this:

It looks like a random combination of characters, but we can see that some words such as hat, her, etc., have already appeared, and paired quotes have been generated.
Training Steps: 1000
When the training steps reach 1000, simple sentences have begun to appear, and the words do not seem so chaotic.

Training Steps: 2000

When the training steps reach 2000, the words and sentences appear to be somewhat standardized.
Training Steps: 3960

When the training ends (this article only trained for 3960 steps), the generated text is already somewhat readable and has very few spelling errors.
5. Summary
This entire article completed the learning of the text of “Anna Karenina” by constructing an LSTM model and generated new text based on the learning results.
By observing the generated text above, we can see that as the training steps increase, the training error of the model continues to decrease. This article only set 20 iterations; trying a larger number of iterations may yield better results.
I personally feel that LSTM has a strong learning ability for text. In the future, I may construct some learning models for Chinese text, which should be more interesting!
I am also continuously exploring and learning about RNN, and there may be some errors and inaccuracies in this article, so please correct me. Thank you very much!
The entire project has been uploaded to my personal GitHub.
See the original text for the GitHub address!
Recommended Reading:
“Li Hongyi’s Complete Notes on Machine Learning” published, Datawhale open-source project LeeML-Notes.
From Word2Vec to Bert, discussing the past and present of word vectors (Part 1).
Chen Lijie, a doctoral student born in 1995 from Tsinghua Yao Class, won the best student paper at the top conference in theoretical computer science.
