
Source: Deephub Imba
This article is about 1400 words long and is recommended to be read in 5 minutes.
This article will delve into the architectural design, theoretical basis, and experimental performance of DeepSeekMoE from a technical perspective, exploring its application value in scenarios with limited computational resources.
DeepSeekMoE is an innovative large-scale language model architecture that achieves a new balance between model efficiency and computational capability by integrating a Mixture of Experts (MoE) system, an improved attention mechanism, and optimized normalization strategies.
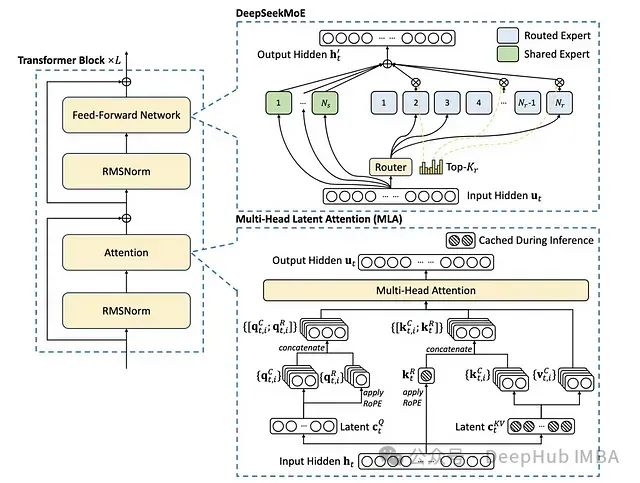
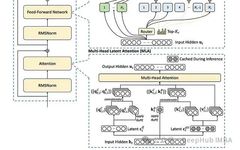
The DeepSeekMoE architecture integrates three core components: the Mixture of Experts (MoE), Multi-Head Latent Attention (MLA), and RMSNorm. Through expert sharing mechanisms, dynamic routing algorithms, and latent variable caching techniques, the model achieves a 40% reduction in computational overhead compared to traditional MoE models while maintaining performance levels.
This article will delve into the architectural design, theoretical basis, and experimental performance of DeepSeekMoE from a technical perspective, exploring its application value in scenarios with limited computational resources.
Architectural Design
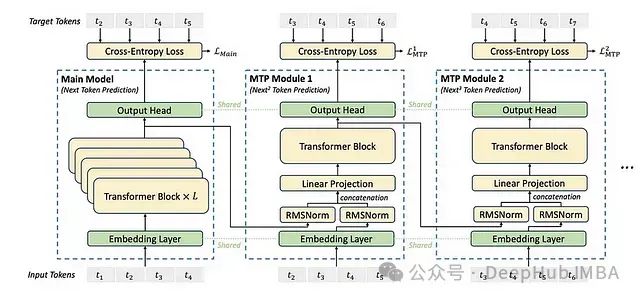
DeepSeekMoE adopts a stacked architecture consisting of L Transformer modules, each composed of the following components:
- Multi-Head Latent Attention Layer (MLA)
- Mixture of Experts Layer (MoE)
-
RMSNorm Normalization Layer
1. Mixture of Experts (MoE) Layer
Dynamic Routing Mechanism: For the input token embedding ut, the router selects k most relevant experts (k≤4) from Ns experts through a gating network:
g(ut)=Softmax(Wgut), select Top-k experts
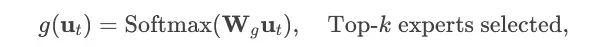
Here, Wg represents the trainable routing weight matrix.
Expert Sharing Mechanism: DeepSeekMoE innovatively introduces an expert sharing design, where some experts share parameters across different tokens or layers, and the final output computation formula is:
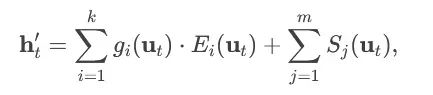
In this formula, Ei represents task-specific experts, and Sj represents shared experts.
2. Multi-Head Latent Attention (MLA) Mechanism
The MLA mechanism introduces latent vectors ctQ, ctK to cache intermediate computation results during autoregressive inference:
Query/Key Concatenation Calculation: For the i-th attention head:
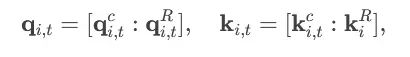
- qi, tc, ki, tc are derived from latent vectors, while qi,tR and kiR are the routable parts
-
Key-Value Caching Optimization: During the inference stage, by precomputing and reusing static key-values kiR, the floating-point operations in generation tasks are reduced by 25%
3. RMSNorm Normalization
DeepSeekMoE adopts RMSNorm instead of traditional LayerNorm, using only root mean square statistics for input scaling:
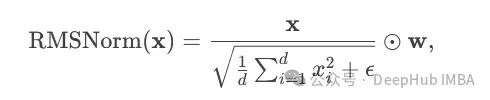
Where w is a learnable parameter. This simplified design not only reduces the computational load but also enhances training stability.
Performance Evaluation
1. Computational Efficiency
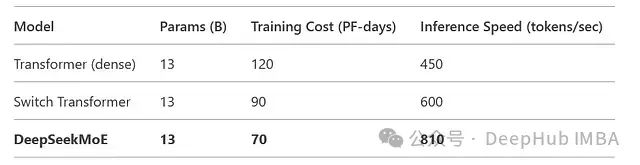
Parameter Efficiency: With 64 experts (of which 8 are shared), DeepSeekMoE achieves a 1.8x throughput improvement compared to the Switch Transformer (64 experts), while reducing the parameter count by 30%.
Training Efficiency: Compared to a dense Transformer with a similar parameter scale (13B), the training speed is improved by 2.1 times.
Inference Performance: The MLA caching mechanism reduces latency for autoregressive tasks by 35%.
2. Model Performance
Language Modeling: Achieved a perplexity of 12.3 on the WikiText-103 test set, outperforming the Switch Transformer at 14.1.
Machine Translation: Achieved a BLEU score of 44.7 on the WMT’14 EN-DE test set, improving by 2.1 points over Transformer++.
Long Text Processing: Achieved an accuracy of 89% on the 10k token document question-answering task, significantly higher than the standard Transformer at 82%.
Theoretical Analysis
Expert Sharing Mechanism: Research shows that sharing experts can effectively capture cross-task general features, reducing model redundancy.
Latent Attention Convergence: Theoretical analysis proves that the MLA mechanism controls gradient variance to 85% of that of standard attention mechanisms, which is beneficial for improving training stability.
Scalability Analysis: DeepSeekMoE follows a computational optimal scaling rate of L(N)∝N−0.27, which is better than the Chinchilla law (N−0.22).
Application Value
Cost-Effectiveness: The training cost of the 13B scale DeepSeekMoE model is approximately $900,000, saving 30% compared to dense models of the same scale.
Practical Application Scenarios:
- Dialogue Systems: Achieving a processing speed of 810 tokens/second, supporting real-time interaction;
- Document Processing: The MLA-based caching mechanism performs exceptionally well in long text processing;
-
Lightweight Deployment: Through expert sharing and RMSNorm optimization, memory usage is reduced by 40%.
Conclusion
DeepSeekMoE finds a new balance between model scale and computational efficiency through an innovative mixture of experts architecture, latent attention caching, and optimized normalization strategies. It maintains leading performance levels while reducing computational costs, providing new insights for the sustainable development of large-scale AI systems. Future research will explore the application of this architecture in multimodal tasks and further optimization of routing algorithms.
Paper:
https://arxiv.org/abs/2401.06066
Editor: Huang Jiyan
About Us
Data Hub THU, as a public account focused on data science, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a platform for gathering data talent, creating the strongest group in China’s big data.

Sina Weibo: @Data Hub THU
WeChat Video Account: Data Hub THU
Today’s Headlines: Data Hub THU