Important content delivered at the first moment
1. Brief Overview of Various Optimization Algorithms
Stochastic Gradient Update:
For standard SGD, I won’t elaborate.
The main point to note is that mini-batch gradient descent is commonly used in deep learning.
Momentum Update:
This method can be seen as an inspiration from physics for optimization problems. It suggests that the gradient only affects the speed, and then the speed affects the position. The loss value can be understood as the height of a mountain (thus the potential energy is 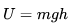 , so there is
, so there is 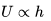 ). Initializing parameters with random numbers is equivalent to setting the initial speed of a particle to zero at a certain position. Thus, the optimization process can be viewed as simulating the parameter vector (i.e., particle) rolling on the terrain. The code is as follows:
). Initializing parameters with random numbers is equivalent to setting the initial speed of a particle to zero at a certain position. Thus, the optimization process can be viewed as simulating the parameter vector (i.e., particle) rolling on the terrain. The code is as follows:
<span># Momentum Update</span><span>v = mu * v - learning_rate * dx # Merging with speed (1)</span><span>x += v # Merging with position</span>
Note: Here, a variable v initialized to 0 and a hyperparameter mu are introduced, suggesting that the gradient only affects speed, and speed then affects position. From the formula, we can see that we construct speed by repeatedly adding the gradient term, so as the number of iterations increases, the speed will get faster, ensuring that the momentum technique runs faster than standard gradient descent; at the same time, the introduction of μ typically starts with a momentum of 0.5 and gradually increases to 0.99 over subsequent epochs. This ensures that the speed will gradually decrease as it approaches the bottom, ultimately stopping at the bottom, rather than oscillating back and forth at the bottom. Therefore, due to the changes in both terms in formula (1), the consequence is that V first increases and then decreases.
Nesterov Momentum Update:
This is similar to the above momentum update, but the difference is that when the parameter vector is at some position x, the momentum part (ignoring the second part with the gradient) slightly alters the parameter vector through mu * v. Therefore, when calculating the gradient, it makes sense to consider the future approximate position x + mu * v as “looking ahead”, which is near where we will stop later. Thus, calculating the gradient at x + mu * v rather than the “old” position x is meaningful.
The code implementation is as follows:
<span>x_ahead = x + mu * v</span><span># Calculate dx_ahead (the gradient at x_ahead, not at x)</span><span>v = mu * v - learning_rate * dx_ahead</span><span>x += v</span>
Equivalent to:
<span>v_prev = v # Backup storage</span><span>v = mu * v - learning_rate * dx # Speed update remains unchanged</span><span>x += -mu * v_prev + (1 + mu) * v # Position update changes form</span>
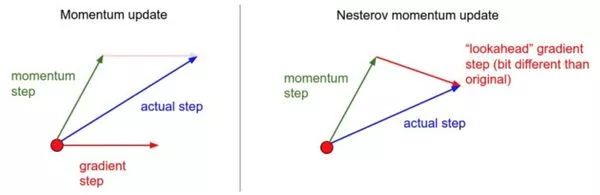
The above image illustrates Nesterov momentum; since we know that momentum will take us to the point indicated by the green arrow, we do not need to compute the gradient at the origin (red point). By using Nesterov momentum, we calculate the gradient at this “looking ahead” point, which allows for faster convergence than the momentum method.
Adaptive Algorithms
The previous methods perform global operations on the learning rate and apply the same to all parameters. Tuning the learning rate is a computationally expensive process, so much effort has been put into inventing methods that can adaptively tune the learning rate, even tuning the learning rate parameter by parameter. Many of these methods still require other hyperparameter settings, but the idea is that these methods perform better over a wider range of hyperparameters than the original learning rate methods. Below are some commonly encountered adaptive algorithms in practice:
Adagrad:
Adagrad is an adaptive learning rate algorithm proposed by Duchi et al., where the main approach is that weight updates from high gradient values are diminished, while updates from low gradient values are enhanced. The implementation code is as follows:
# Assume gradients and parameter vector xcache += dx**2x += – learning_rate * dx / (np.sqrt(cache) + eps)
The variable cache has the same dimensions as the gradient matrix, tracking the sum of squares of gradients for each parameter. This will be used to normalize the parameter update step, normalized element-wise. It is important to note that the square root operation is crucial; removing it would significantly degrade the algorithm’s performance. The smoothing term eps (generally set between 1e-4 and 1e-8) is to prevent division by zero. One drawback of Adagrad is that in deep learning, the monotonically decreasing learning rate is often too aggressive and stops learning too early.
RMSprop:
This is a very efficient adaptive learning rate method that has not been publicly published. Most people cite it from the 6th lesson, page 29 of the PPT of Geoff Hinton’s Coursera course. This method modifies the Adagrad method in a very simple way to make it less aggressive, monotonically decreasing the learning rate. Specifically, it uses a moving average of the gradient square:
<span>cache = decay_rate * cache + (1 - decay_rate) * dx**2</span><span>x += - learning_rate * dx / (np.sqrt(cache) + eps)</span>
In the above code, decay_rate is a hyperparameter, commonly set to values like [0.9, 0.99, 0.999]. The operation x+= is the same as in Adagrad, but the cache variable is different. Therefore, RMSProp still modifies the learning rate for each weight based on the size of the gradient, which works well. However, unlike Adagrad, its updates do not force the learning rate to monotonically decrease.
Adam:
This is somewhat like RMSProp + momentum, performing slightly better than RMSProp, and its simplified code is as follows:
<span>m = beta1*m + (1-beta1)*dx</span><span>v = beta2*v + (1-beta2)*(dx**2)</span><span>x += - learning_rate * m / (np.sqrt(v) + eps)</span>
Note that this update method looks very similar to RMSProp, except it uses the smoothed version of the gradient m instead of the original gradient vector dx. The recommended parameter values in the paper are eps=1e-8, beta1=0.9, beta2=0.999. In practice, we recommend Adam as the default algorithm, which generally runs slightly better than RMSProp. However, you can also try SGD + Nesterov momentum. Also, note that the complete Adam update algorithm includes a bias correction mechanism since m and v matrices are initialized to 0, leading to bias before fully accurate updates.
Readers are encouraged to read the papers for details. For example, the Adam algorithm has many details that are explained very clearly in its paper!
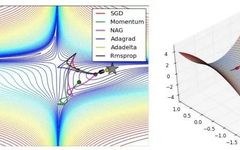
Below is a comparison of various optimization algorithms: From CS231n, originally a GIF, see CS231n Convolutional Neural Networks for Visual Recognition for details.
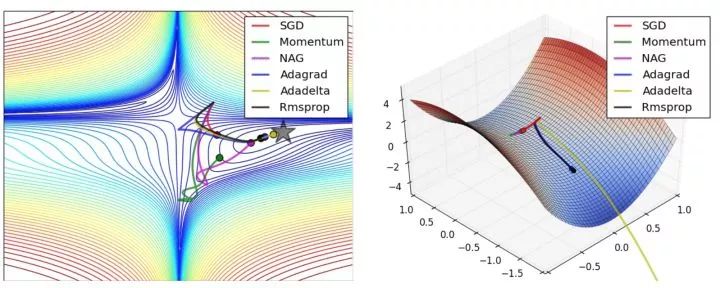
2. Summary of Neural Networks:
Briefly summarize neural networks:
-
For data processing and initialization: Preprocessing is essential, especially in image processing, using a Gaussian distribution with standard deviation
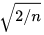 to initialize weights, do not initialize all to zero.
to initialize weights, do not initialize all to zero. -
For neural network architecture selection: It is recommended to initially use ReLU as the activation function; of course, other activation functions should also be tried. Neural networks should not be too wide, with appropriate depth, and appropriate use of BN, Dropout, and other tricks.
-
For neural network optimization: The update method falls under the category of hyperparameter tuning, requiring experience. For adaptive methods, Adam is still a good choice. If implementing backpropagation yourself, be sure to use mini-batch data for gradient checking.
-
Finally, neural networks have various tricks and require various tuning experiences; practice more, summarize more, and we need to explore and learn. Keep it up!
Good News!
Visual Learning for Beginners Knowledge Planet
Is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of the "Visual Learning for Beginners" public account to download the first Chinese version of the OpenCV extension module tutorial available online, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Projects 52 Lectures
Reply "Python Visual Practical Projects" in the backend of the "Visual Learning for Beginners" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the backend of the "Visual Learning for Beginners" public account to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Community Group
Welcome to join the public account reader group to exchange with peers. There are currently WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format; otherwise, you will not be approved. After successfully adding, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~