
Hello everyone, I am Peter~
Today I am sharing an article about deep learning algorithms, mainly introducing 10 deep learning algorithms such as CNN, LSTM, RNN, GAN, MLP, etc.
Introduction
Deep learning is a subset of machine learning, based on artificial neural networks. The learning process is considered deep because the structure of artificial neural networks consists of multiple input, output, and hidden layers.
Each layer contains units that transform input data into information for the next layer to use for specific prediction tasks. Thanks to this structure, machines can learn through their own data processing.

Deep learning has been widely applied in scientific computing, and its algorithms are extensively used in industries solving complex problems. All deep learning algorithms use different types of neural networks to perform specific tasks. This article presents the basic concepts of artificial neural networks and deep learning algorithms, and briefly explains how they simulate the functioning of the human brain.
How to Define Neural Networks?
Neural Networks, abbreviated as NN. To address the problem that machine learning algorithms require domain experts for feature engineering and have poor model generalization performance, it is proposed that NN can learn feature representations from the raw features of data without complex feature processing.
The structure of neural networks is similar to that of the human brain, consisting of artificial neurons, also known as nodes. These nodes are divided into three layers stacked side by side:
-
Input Layer -
Hidden Layer -
Output Layer
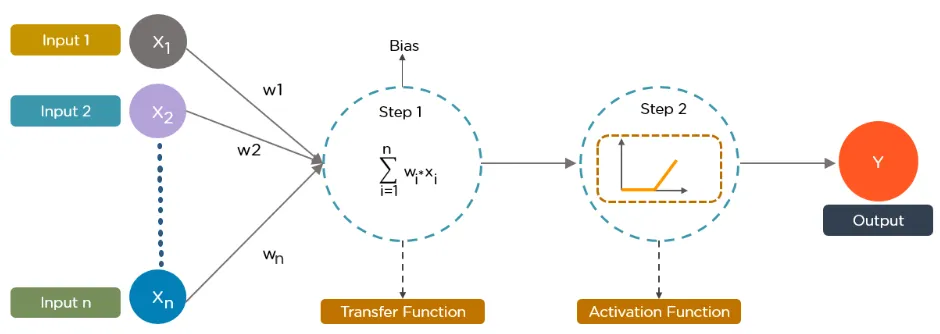
Data is provided to each node in the form of input. The node multiplies the input by random weights, calculates them, and adds a bias. Finally, a non-linear function, also known as the activation function, is used to determine which neuron is activated.
This principle can be understood using linear regression:
How Do Deep Learning Algorithms Work?
Although the characteristic of deep learning algorithms is self-learning representation, they rely on neural networks that reflect the way the brain computes information. During training, the algorithm uses unknown elements in the input distribution to extract features, group objects, and discover useful data patterns. Just like a self-learning training machine, this occurs at multiple levels, using algorithms to build models.
Deep learning models utilize various algorithms. Although no single network is considered perfect, some algorithms are suitable for performing specific tasks. To choose the right algorithm, it is best to have a solid understanding of all the major algorithms.
The Ten Most Popular Deep Learning Algorithms
-
Convolutional Neural Networks (CNNs) -
Long Short Term Memory Networks (LSTMs) -
Recurrent Neural Networks (RNNs) -
Generative Adversarial Networks (GANs) -
Radial Basis Function Networks (RBFNs) -
Multilayer Perceptrons (MLPs) -
Self Organizing Maps (SOMs) -
Deep Belief Networks (DBNs) -
Restricted Boltzmann Machines (RBMs) -
Autoencoders
Deep learning algorithms can handle almost any type of data and require a lot of computational power and information to solve complex problems. Now, let’s delve into some popular deep learning algorithms.
1. Convolutional Neural Networks (CNN)
Convolutional Neural Networks, abbreviated as CNN.
CNN, also known as ConvNet, consists of multiple layers and is mainly used for image processing and object detection. The first CNN was invented by Yann LeCun in 1988, and it was called LeNet. It was used to recognize characters such as postal codes and digits.
CNNs are widely used for recognizing satellite images, processing medical images, predicting time series, and detecting anomalies.
How Does CNN Work?
CNN has multiple layers that process and extract features from the data:
1. Convolutional Layer
CNN has a convolutional layer with several filters performing the convolution operation.
2. Rectified Linear Unit
CNN has a ReLU layer to perform element-wise operations. The output is a rectified feature map.
3. Pooling Layer
The rectified feature map is then provided to a pooling layer. Pooling is a down-sampling operation that reduces the dimensionality of the feature map.
Then, the pooling layer flattens the pooled feature map into a single, long, continuous linear vector.
4. Fully Connected Layer
When the flattened matrix from the pooling layer is used as input, it forms a fully connected layer that classifies and recognizes the image.
Below is an example of an image processed by CNN.
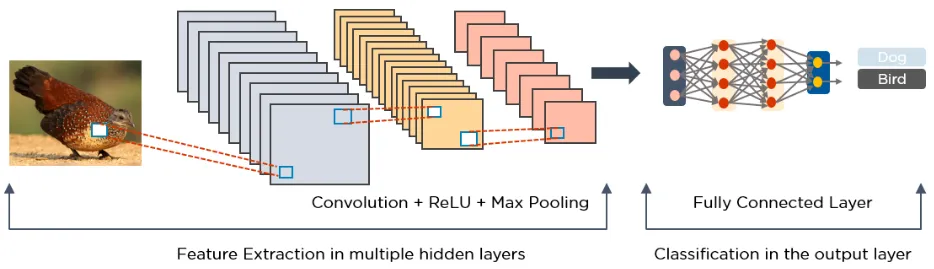
2. Long Short-Term Memory Networks (LSTMs)
LSTM is a type of Recurrent Neural Network (RNN) that can learn and remember long-term dependencies. Remembering information from the past for a long time is the default behavior.
LSTMs retain information over time. They are useful in time series prediction because they remember previous inputs. LSTM has a chain-like structure where four interacting layers communicate in a unique way. Besides time series prediction, LSTMs are commonly used in speech recognition, music composition, and drug development.
How Does LSTM Work?
-
First, they forget irrelevant parts of the previous state -
Next, they selectively update the cell state value -
Finally, output certain parts of the cell state
Below is a diagram showing how LSTM operates:
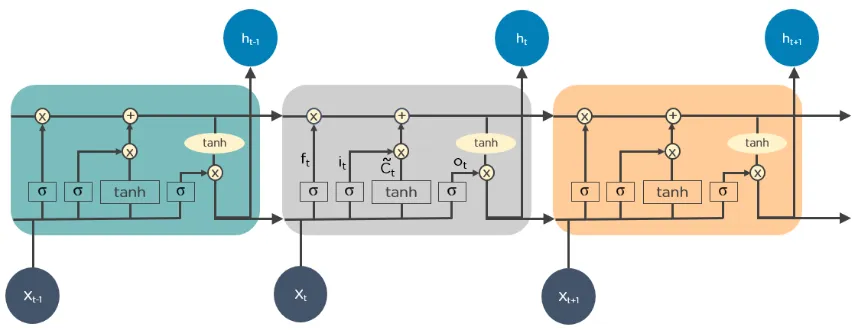
3. Recurrent Neural Networks (RNNs)
RNNs have connections that form directed cycles, allowing the output of LSTM to be fed back as input to the current stage.
The output of LSTM becomes the input for the current stage, and due to its internal memory, it can remember previous inputs. RNNs are commonly used in image captioning, time series analysis, natural language processing, handwriting recognition, and machine translation.
The unfolded RNN looks like this:
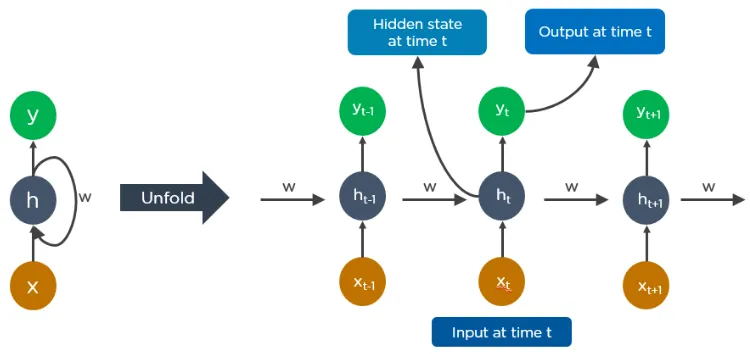
How Does RNN Work?
-
The output at time t-1 is input at time t. -
Similarly, the output at time t is input at time t + 1. -
RNN can handle inputs of arbitrary length. -
The computation takes historical information into account, and the model size does not increase with the size of the input.
Below is an example of Google’s autocomplete feature:
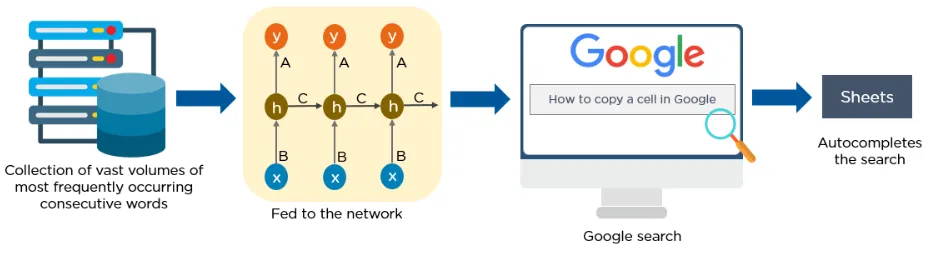
4. Generative Adversarial Networks (GAN)
GAN is a generative deep learning algorithm that creates new data instances similar to the training data. GAN consists of two components: a generator that learns to generate fake data and a discriminator that learns to distinguish between fake and real data.
The use of GANs has increased over time. They can be used to improve astronomical images and simulate gravitational lensing effects in dark matter research. Video game developers use GANs to enhance the resolution of old video games with low-resolution, 2D textures to 4K or higher resolution.
GANs help generate realistic images and cartoons, create facial photos, and render 3D objects.
How Does GAN Work?
-
The discriminator learns to distinguish between the fake data generated by the generator and real sample data. -
During the initial training process, the generator produces fake data, and the discriminator quickly learns to identify this fake data. -
GAN sends results to both the generator and discriminator to update the model.
Below is a diagram showing how GAN operates:
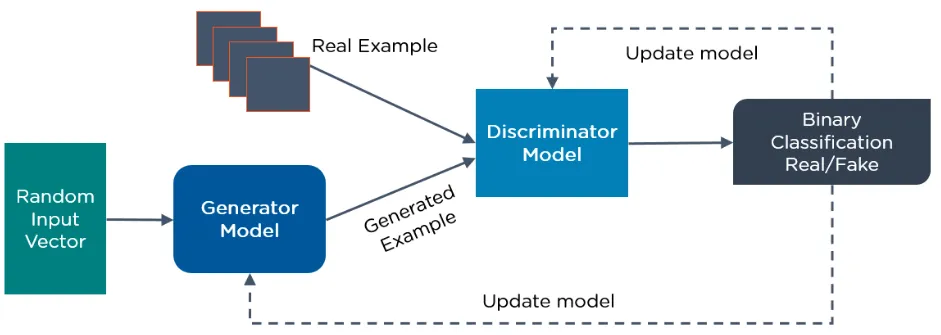
5. Radial Basis Function Networks (RBFNs)
RBFN is a special type of feedforward neural network that uses radial basis functions as activation functions. They have an input layer, a hidden layer, and an output layer, mainly used for classification, regression, and time series prediction.
How Does RBFN Work?
-
RBFN classifies by measuring the similarity of inputs to examples in the training set. -
RBF neurons have an input vector supplied to the input layer, and they have a layer of RBF neurons. -
The function finds the weighted sum of the input, and the output layer has a node for each class or category of data. -
The neurons in the hidden layer contain Gaussian transfer functions whose output is inversely proportional to the distance to the neuron center. -
The output of the network is a linear combination of the radial basis functions of the input and the neuron parameters.
Take a look at this example of RBFN:
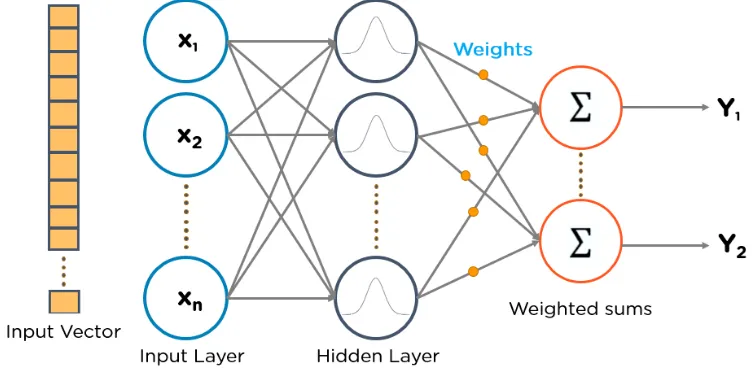
6. Multilayer Perceptrons (MLPs)
MLP is an excellent place to start learning deep learning techniques.
MLP belongs to feedforward neural networks with multiple layers and activation functions. MLP consists of a fully connected input layer and output layer. They have the same number of input and output layers, but may have multiple hidden layers, which can be used to build speech recognition, image recognition, and machine translation software.
How Does MLP Work?
-
MLP provides data to the input layer of the network. The layers of neurons are connected in a graph so that signals are transmitted in one direction. -
MLP uses weights that exist between the input layer and hidden layers to compute the input. -
MLP uses activation functions to decide which nodes to activate. Activation functions include ReLU, sigmoid functions, and tanh. -
MLP trains the model to understand correlations and learns the dependencies between independent variables and target variables from the training dataset.
Below is an example of MLP. This diagram calculates weights and biases and applies the appropriate activation function to classify images of cats and dogs.
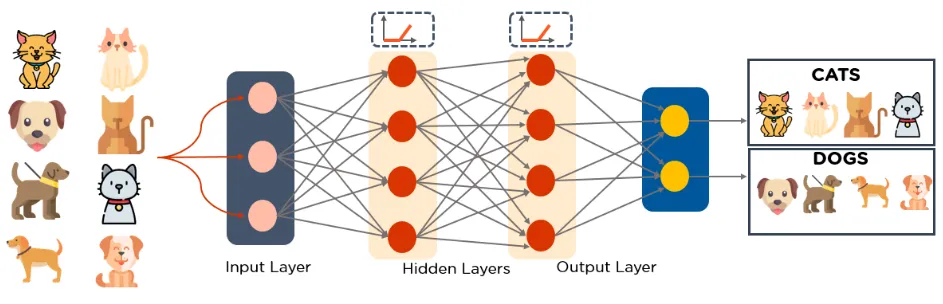
7. Self-Organizing Maps (SOMs)
Professor Teuvo Kohonen invented Self-Organizing Maps to enable data visualization through self-organizing artificial neural networks to reduce the dimensionality of data.
Data visualization attempts to solve the problem of humans not easily visualizing high-dimensional data. SOM was created to help users understand this high-dimensional information.
How Does SOM Work?
-
SOM initializes weights for each node and randomly selects a vector from the training data. -
SOM checks each node to find which weights are most likely to match the input vector. The winning node is called the Best Matching Unit (BMU). -
SOM discovers the neighbors of the BMU, and over time, the number of neighbors decreases. -
SOMs assign a winning weight to the sample vector. The closer a node is to the BMU, the more its weight changes. -
The farther neighbors are from the BMU, the less they learn. SOMs repeat the second step for N iterations.
Below, please see a diagram showing different colored input vectors. These data are provided to SOM, which then transforms the data into 2D RGB values. Finally, it separates and classifies different colors.
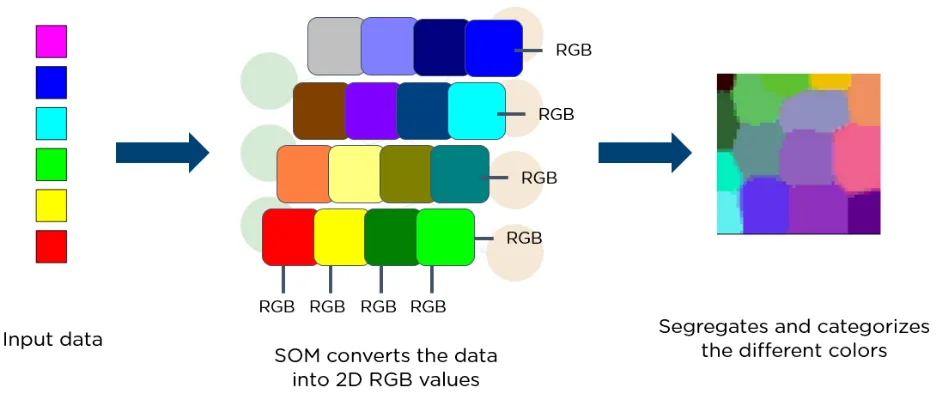
8. Deep Belief Networks (DBNs)
DBN is a generative model composed of multiple layers of latent variables. The latent variables have binary values, commonly referred to as hidden units.
DBN is a set of Boltzmann machines that establish connections between layers, with each RBM layer communicating with the previous and subsequent layers. Deep Belief Networks (DBNs) are used for image recognition, video recognition, and motion capture data.
How Does DBN Work?
-
A greedy learning algorithm trains the DBN. The greedy learning algorithm uses a layer-by-layer approach to learn generative weights from top to bottom. -
DBN runs Gibbs sampling steps on the top two hidden layers. This stage extracts a sample from the RBM defined by the top two hidden layers. -
DBN uses ancestral sampling through the rest of the model to extract samples from visible units. -
The values of latent variables in each layer can be inferred through a bottom-up pass.
Below is an example of the DBN architecture:
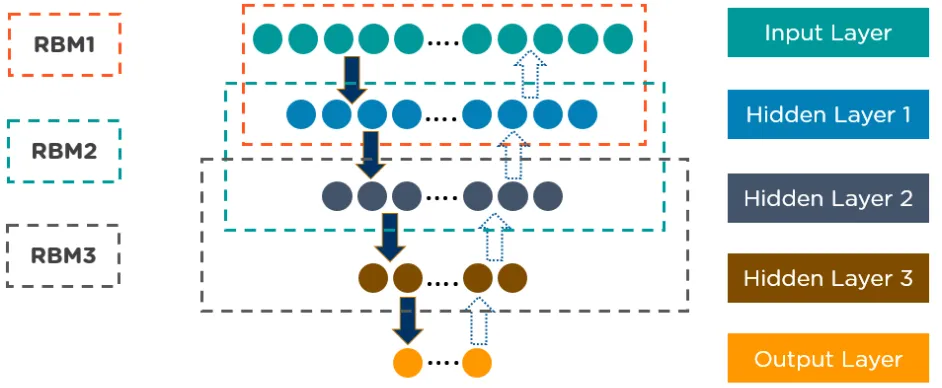
9. Restricted Boltzmann Machines (RBMs)
Developed by Geoffrey Hinton, RBM is a stochastic neural network that learns from the probability distribution of a set of inputs.
This deep learning algorithm is used for dimensionality reduction, classification, regression, collaborative filtering, feature learning, and topic modeling. RBMs are components of DBNs.
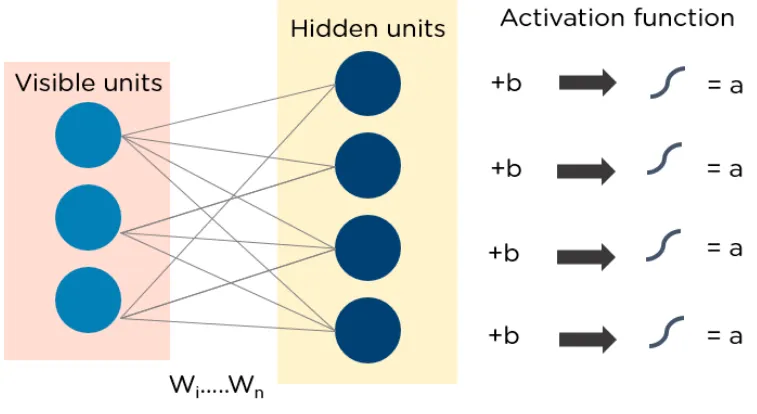
RBM consists of two layers:
-
Visible Units -
Hidden Units
Each visible unit is connected to all hidden units. RBM has a bias unit connected to all visible and hidden units, which does not have output nodes.
How Does RBM Work?
RBM has two phases: forward pass and backward pass.
-
RBM accepts input and converts it into a set of numbers, encoding the input during the forward pass. -
The RBM algorithm combines each input with a single weight and a total bias to pass the output to the hidden layer. -
During the backward pass, RBM takes this set of numbers and converts them back into reconstructed input. -
RBM combines each activation with individual weights and overall bias to pass the output to the visible layer for reconstruction. -
In the visible layer, RBM compares the reconstructed results with the original input to analyze the quality of the results.
Below is a diagram showing how RBM operates:
10. Autoencoders
Autoencoders are a special type of feedforward neural network where the input and output are the same. Geoffrey Hinton designed autoencoders in the 1980s to address unsupervised learning problems. They are trained neural networks that copy data from the input layer to the output layer. Autoencoders are used for purposes such as drug discovery, epidemic prediction, and image processing (like the popular seq2seq model, the original Transformer model uses an encoder-decoder architecture).
How Do Autoencoders Work?
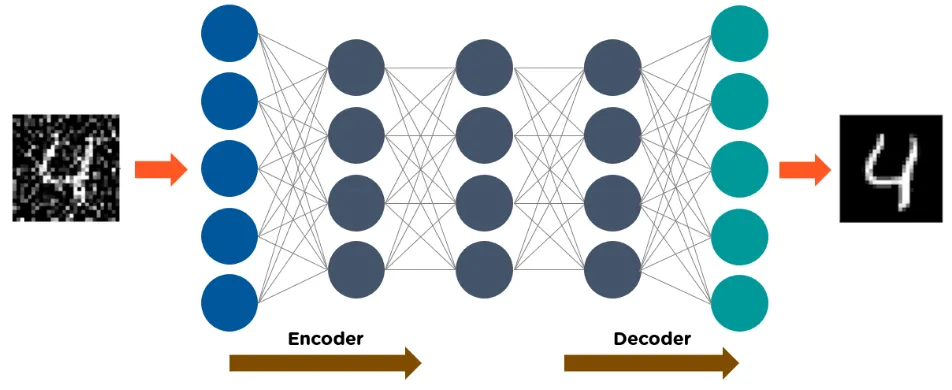
Autoencoders consist of three main parts: encoder, code, and decoder.
-
The structure of an autoencoder receives input and transforms it into a different representation. Then, they try to reconstruct the original input as accurately as possible. -
When an image of a digit is not clearly visible, it is fed into the autoencoder neural network. -
The autoencoder first encodes the image, reducing the size of the input to a smaller representation. -
Finally, the autoencoder decodes the image, generating a reconstructed image.
The following diagram illustrates how autoencoders work:
Conclusion
Deep learning has rapidly developed in recent years and is widely popular across many industries. Below are common Q&A exchanges.
Q1: Which algorithm is the best in deep learning?
Multilayer Perceptrons (MLPs) are the simplest and most user-friendly deep learning algorithms. CNNs are commonly used for image recognition, while RNNs and LSTMs are often used for processing text sequences.
Q2: Is CNN a deep learning algorithm?
Yes, CNN is a deep learning algorithm responsible for processing images in a grid pattern inspired by the animal visual cortex. They are designed to automatically detect and segment specific objects and learn features’ spatial hierarchy from low-level to high-level patterns.
Q3: What are the three layers of deep learning?
The neural network consists of three layers: input layer, hidden layer, and output layer. When input data is applied to the input layer, output data is obtained in the output layer. The hidden layer is responsible for performing all calculations and “hidden” tasks.
Q4: How do deep learning models work?
Deep learning models are trained using neural network structures or a set of labeled data that contains multiple layers. They sometimes perform beyond human levels. These architectures learn features directly from data without being hindered by manual feature extraction.
For academic sharing only, if there is any infringement, please contact to delete the article.
Editor /Fan Ruiqiang
Review / Fan Ruiqiang
Verification / Fan Ruiqiang
Click below
Follow us