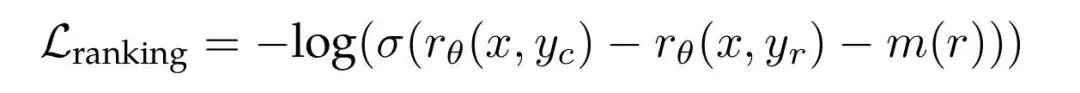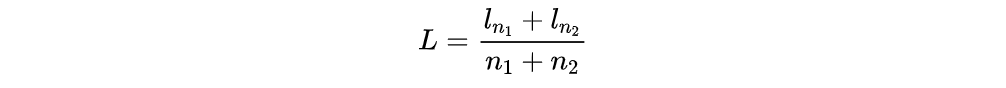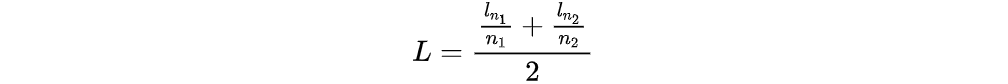On January 14,the Fourth Global Autonomous Driving Summit will be held in Beijing.The main venue will host the opening ceremony, an end-to-end autonomous driving innovation forum, and a city NOA special forum, while the sub-venues will hold technical seminars on autonomous driving visual language models and world models.All the speakers for the summit have been confirmed, and the final agenda can be found at the end of the poster.Please apply for a free ticket or purchase one to attend~
Today, I bring you an article by my friend @hadiii on Zhihu, summarizing the post-training techniques of Llama3.1, DeepSeek-V3, TÜLU 3, and Qwen2.5.
Zhihu: https://zhuanlan.zhihu.com/p/12862210431
This article summarizes the post-training sections reported by Llama3.1, DeepSeek-V3, TÜLU 3, and Qwen2.5, extracting the core details. Most involve data, SFT, RL (various RM training, DPO, GRPO, RLVR, etc.).
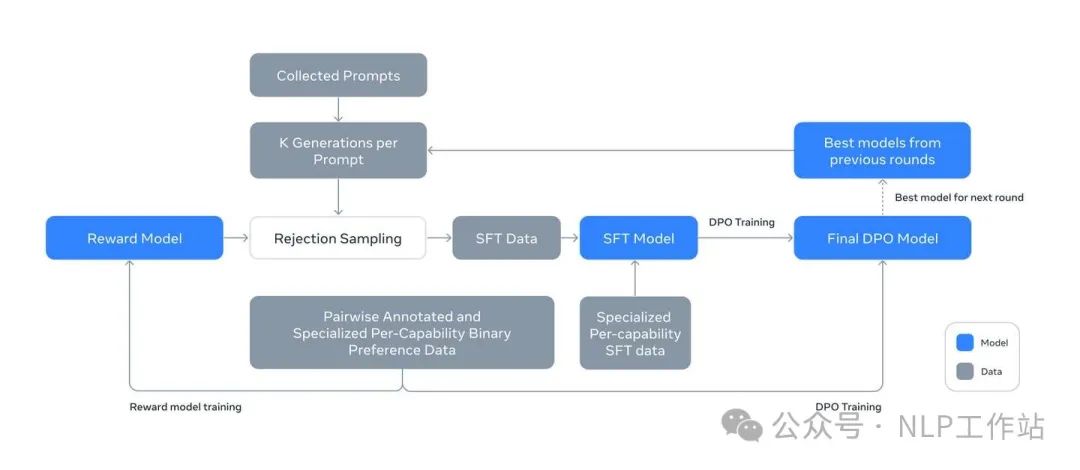
Illustration of the overall post-training approach for Llama 3.Overall, the post-training method for Llama 3 is iterative, conducted over a total of 6 rounds. The core operations in each round are: Reward Modeling, Rejection Sampling, SFT, DPO.The data composition mainly consists of SFT data and Preference data. Reward Modeling and DPO use Preference data in different ways.
SFT data: Results from each round of Rejection Sampling + synthetic data for specific capabilities + a small amount of manually annotated data.
Preference data: A new batch of Preference data is constructed in each training round, accumulating over time. The detailed process can be found in section 1.2 Preference data.
Model Averaging: Each RM, SFT, or DPO phase uses weighted averages of models obtained from experiments using different data mixes or hyperparameters.
1.1 SFT
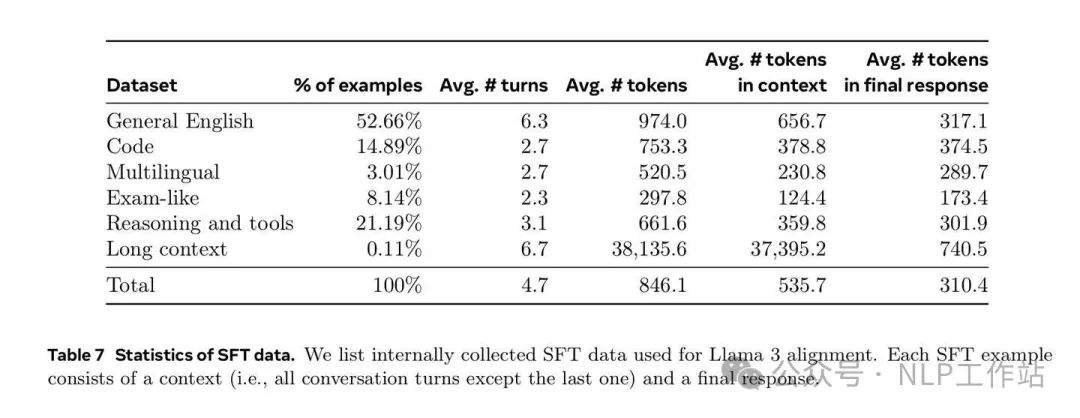
Composition of SFT dataRejection Sampling:Sample the model multiple times, allowing RM to select the best responses as part of SFT data. Some details are as follows:
What models to sample? Two cases: the model with the best Avg score during the iteration, or the model performing best on a particular capability.
How many times to sample? K=10~30, that is, generally sample 10-30 times.
Where do the prompts come from? Manually annotated prompts, with special system prompts introduced in the later stages of post-training iterations.
SFT Training Details:
For the 405B model, a learning rate of 1e-5 is used.
The number of training steps is between 8.5K to 9K steps.
High-quality data sources undergo multiple rounds of repeated training (epochs multiple times). For example, a particularly high-quality coding example may be trained 3-4 times.
Ordinary quality data undergo downsampling. Data of average quality may only be used once or randomly sampled.
Our final data mix epochs multiple times on some high-quality sources and downsamples others.
1.2 Preference Data
Composition of Preference data
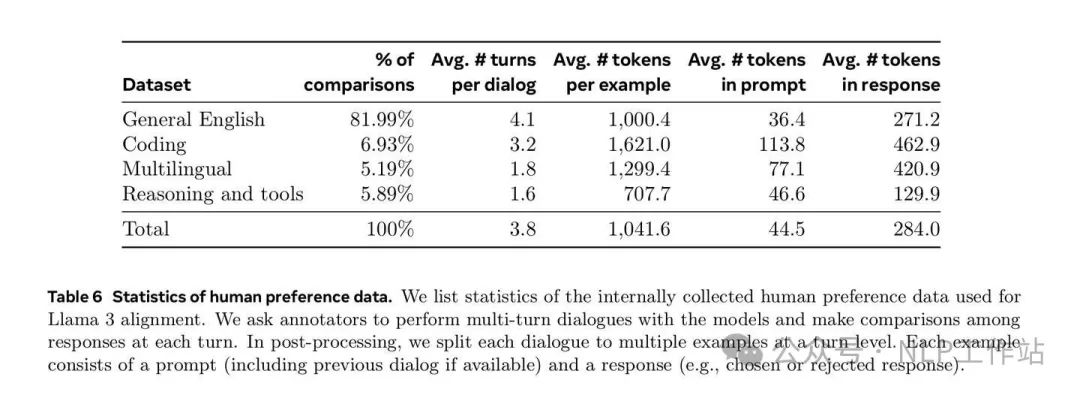
We deploy multiple models for annotation after each round and sample two responses from two different models for each user prompt. These models can be trained with different data mixes and alignment recipes, allowing for different capability strength and increased data diversity.
What models to sample? Deploy multiple models trained with different data mixes and alignment methods, selecting two different models for each prompt. The reason: different models can show differences in various capability dimensions, resulting in better data quality and diversity.
Preference levels? Four levels: significantly better, better, slightly better, and marginally better.
Allowed modifications: Annotators can further optimize the chosen response, leading to edited > chosen > rejected.
Iterative difficulty: As the models improve, the complexity of the prompts gradually increases.
1.3 RM & DPO
Reward Modeling: We train a reward model (RM) covering different capabilities on top of the pre-trained checkpoint. DPO: For training, we primarily use the most recent batches of preference data collected using the best performing models from the previous alignment rounds. Preference Data: In each round of post-training, we use all the preference data that is available at the time for reward modeling, while only using the latest batches from various capabilities for DPO training.
RM Iteration Details:RM also participates in post-training iterations. Each round of iteration retrains RM from scratch. The original text mentions that each training uses all the Preference data, starting training from the Pre-trained checkpoint, rather than performing incremental training using the RM trained in the t-th round during the t+1 round iteration.Llama2 RM ranking loss
Remove the margin loss used in Llama2, namely the m(r) in the above figure, as the margin becomes less meaningful once the data volume increases, reverting to the original ranking loss for “complexity management”:
Both RM and DPO only use pairs with preference levels of significantly better or better, filtering out similar responses.
DPO Iteration Details:DPO is conducted after each SFT. One detail here is that the Preference data used for DPO training is not sampled and annotated on the SFT model from this round, but primarily sampled from the best performing models from all previous iterations. Moreover, only the latest batch of Preference data is taken each time, excluding General English parts of the data, which is different from RM. Loss:
Simultaneously mask the loss of special formatting tokens from both chosen and rejected responses, such as header tokens & termination tokens, as they introduce conflicting learning objectives, optimizing the loss to increase and decrease the probabilities of these tokens.
Simultaneously optimize the SFT loss of the chosen response.
Learning rate is set to 1e-5, beta is set to 0.1, and SFT loss is set to 0.2.
Both RM and DPO only use pairs with preference levels of significantly better or better, filtering out similar responses.
DPO DiscussionThe DPO team observed that as long as the SFT model performs excellently on long context tasks, using only short context training data in DPO does not negatively affect long context performance.
1.4 Data Cleaning
Llama 3 provides very pragmatic data cleaning methods.First, some unwanted response patterns need to be deduplicated, such as excessive use of emojis or exclamation marks. Very classic AI language issues also need to be noted, such as the tone issue of “overly fond of kneeling” and the tendency to say “sorry” or “I apologize” when faced with indecision.Other various methods include:1. Topic Classification:First, train a Topic classifier, such as using a large amount of text classification task data to SFT Llama 3 8B. Then classify all training data into two levels, coarse-grained categories (e.g., “mathematical reasoning”) and fine-grained categories (e.g., “geometry and trigonometry”).2. Quality Scoring:Use Reward model and Llama-based scoring for the quality of each sample. For RM-based scoring, the top 1/4 of the scores are considered high-quality data. For Llama-based scoring, some scoring prompts are designed based on Llama 3, using three dimensions for General English data (accuracy, instruction compliance, and tone/expression), and two dimensions for coding data (error identification and user intent), finally considering the samples with the highest scores as high-quality data. The discrepancy rate between RM scoring and Llama scoring is high, but combining these two mechanisms achieves the best recall rate in meta’s internal test set.3. Difficulty Scoring:Instag and Llama-based scoring. For Instag, prompts Llama 3 70B to label the intentions of SFT prompts. The more intentions, the higher the complexity. The Llama-based approach is similar to Quality scoring, giving Llama 3 some prompts to score based on three dimensions.4. Semantic Deduplication:Finally, perform semantic deduplication. First, use RoBERTa to cluster the complete dialogues, then within each cluster, sort them by (quality score × difficulty score). Next, traverse all sorted samples for greedy selection, keeping only those with cosine similarity to previously seen samples in the current cluster below a threshold.
Instag is used to label SFT data’s intentions and semantic tags. See: https://arxiv.org/pdf/2308.07074
The post-training path of DeepSeek-V3 is SFT->GRPO. The post-training section also mentions some explorations distilled from DeepSeek-R1, attempts at Self-Rewarding, and the effects of Multi-Token Prediction. The exciting content of the full text is mainly in the pretrain section, but for now, I just want to organize the post-training part.
2.1 SFT
DeepSeek-V3 constructed a 1.5M (V2 also about 1.5M) instruction fine-tuning dataset, distinguishing between Reasoning Data and Non-Reasoning Data during data construction.Reasoning Related DataFor reasoning-related datasets (Math, Coding, logical reasoning), data is generated through DeepSeek-R1. Although the data generated by R1 shows high accuracy, it also has issues such as overthinking, poor formatting, and lengthy answers. Therefore, the goal is to combine the high accuracy of R1 generated data with the clarity and conciseness of conventional formatted reasoning data.Specifically, first train multiple expert models for specific domains. Then, the expert models are used as generators for the final SFT data. During the training of the expert models, two different types of SFT samples need to be generated for each data instance:
Pair the question with its original answer, formatted as <question, original answer>;
Based on the question and R1 answer, add system prompts, formatted as <system prompt, question, R1 answer>.
The system prompt guides the model to generate responses with reflection and verification mechanisms. In the RL phase, the model generates responses through high-temperature sampling, integrating patterns from R1 generated data and original data, even reflecting them without explicit system prompts. After hundreds of steps of reinforcement learning, the Expert model learns to integrate R1 patterns.After the RL training of the Expert model is completed, rejection sampling (RS) is used to filter high-quality SFT data for training the final model. At this point, since the expert model serves as the generator, it retains various advantages of DeepSeek-R1 while also generating concise and efficient responses.Non-Reasoning DataFor non-reasoning data (e.g., creative writing, role-playing, and simple Q&A), responses are generated by DeepSeek-V2.5 and verified for accuracy and correctness by human annotators.SFT Details
Training for two epochs, with a cosine decay learning rate, starting at 5×1e-6, gradually decaying to 1e-6.
During training, each sequence consists of multiple sample data (i.e., SFT packing). However, different samples require additional attention masks to ensure these samples are independent and invisible to each other. Notably, V3 did not apply cross-sample attention masks during pretraining.
Discussion: Distillation Effects of DeepSeek-R1The contribution of distillation from DeepSeek-R1The report studies the contributions of distillation from DeepSeek-V2.5. DeepSeek-R1 Distill achieved significant improvements in the LiveCodeBench and MATH-500 benchmark tests.Based on MATH-500, an interesting trade-off can be observed: distillation can lead to better performance (74.6->83.2), but it also significantly increases the average answer length (76.9->83.2).The report suggests that knowledge distillation from reasoning models provides a promising direction for post-training.
2.2 RM
The RL process of DeepSeek-V3 trained two types of RM: rule-based and model-based.Rule-Based RMFor problems that can be verified by specific rules, rewards are determined based on rules. For example, for certain mathematical problems, these problems have deterministic answers, requiring the model to provide the final answer in a specified format (e.g., highlighting the final answer), thus allowing for rule verification of its correctness. Similarly, for LeetCode problems, feedback can be generated through the compiler using test cases. This is a very classic approach, ensuring that the reward is very credible. TÜLU 3 also performed RLVR.Model-Based RMFor questions with free-form standard answers, RM is relied upon to judge whether the answer matches the expected standard answer. However, for questions without clear standard answers (e.g., those involving creative writing), RM needs to provide feedback based on the question and corresponding answer. Model-Based RM is trained based on the SFT checkpoint of DeepSeek-V3. To improve reliability, a training set containing preference data is constructed, which not only provides the final reward but also includes the reasoning chain leading to the reward. This approach reduces reward hacking that may occur in specific tasks.Discussion: Self-RewardingThis is the practice of constitutional AI, guiding the model through a series of text-described rules. The voting evaluation results of DeepSeek-V3 itself are also used as feedback, significantly improving DeepSeek-V3’s performance in subjective evaluations.Association: DeepSeekMathThe DeepSeekMath report mentioned the use of Process Supervision RL, but it was not mentioned in the DeepSeek-V3 report.
2.3 GRPO
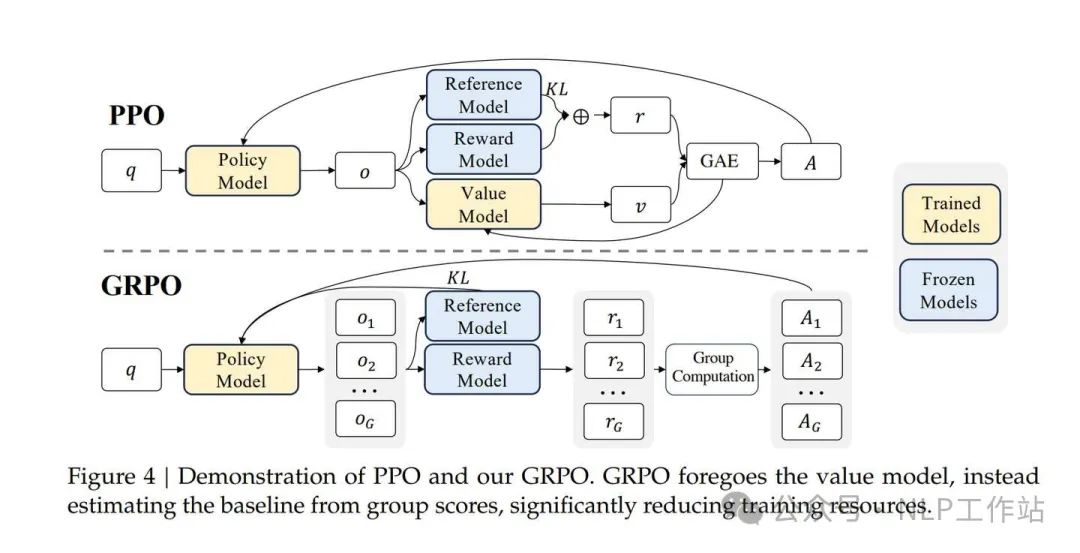
GRPO is a simplified version of PPO, with the core change being the removal of the Value Model, relying on multiple sampled rewards to derive the baseline score for advantage calculation. DeepSeek-V3 does not provide many details in the GRPO section. The advantage function of GRPO is:The optimization goal is:GRPO Diagram from DeepSeek-V2
For detailed algorithms of GRPO, refer to the DeepSeek-V2 report. GRPO is similar to RLOO, and the TRL rloo_trainer.py implements the RLOO training source code, which can be referenced. Understanding one helps understand the other. Thus, it can also be referenced: https://zhuanlan.zhihu.com/p/1073444997
03
TÜLU 3
paper: https://allenai.org/tulu
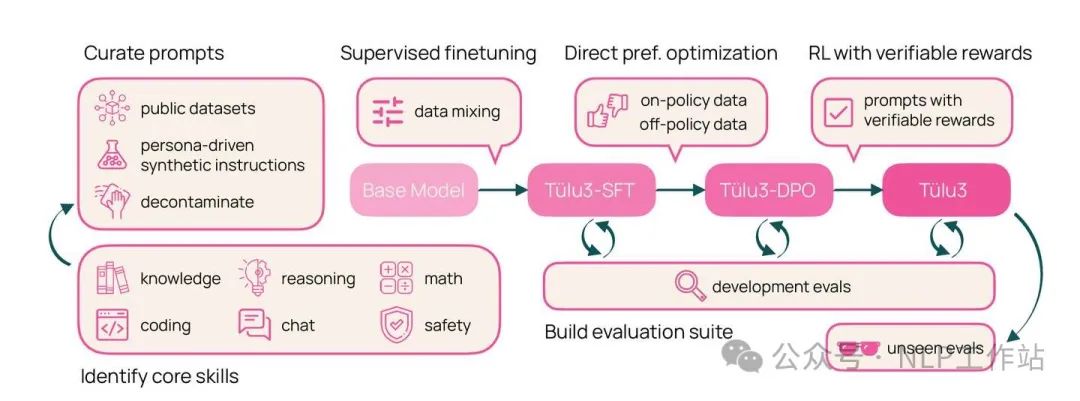
An overview of the TÜLU 3 recipe.The post-training path of TÜLU 3 is SFT->DPO->RLVR. The TÜLU 3 report is very sincere, providing quite a bit of detail for learning in the RL section. It is also one of the few reports that spends a considerable amount of space discussing RLVR.
3.1 SFT
Data CompositionVarious quality open-source data such as WildChat, OpenAssistant, NoRobots, FLAN v2, etc. Responses from human annotators or good closed-source models are retained, while those without responses are distilled.Data Experiments
Diverse dialogue data (WildChat) has a positive impact on most skills, especially improving Alpaca Eval performance.
Safety SFT data is usually orthogonal to other datasets.
… (there are other data experiments, such as chat templates… see the original text for details)
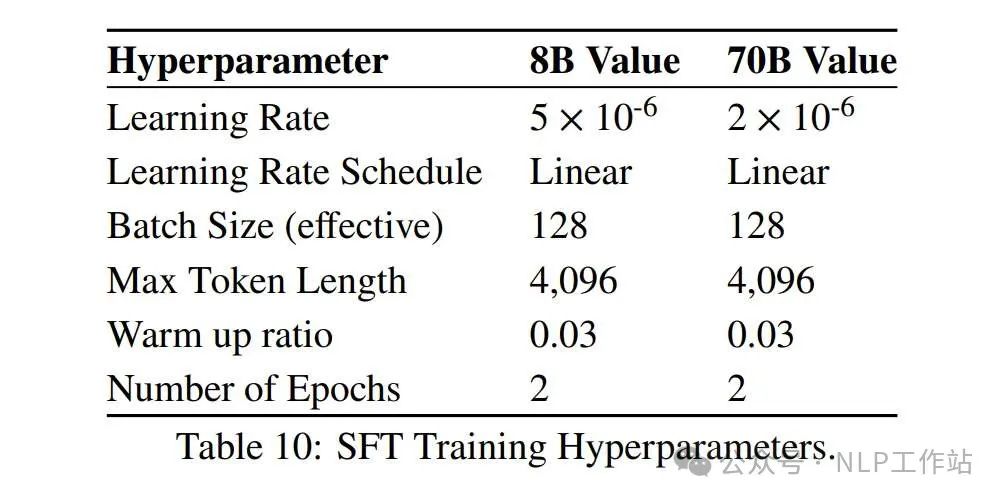
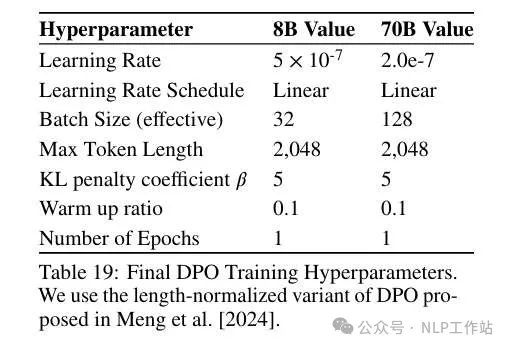
RecipeHyperparametersBatch size 128, Max Length 4096, Linear LR. For the 8B model, learning rate: 5e-6. For the 70B model, learning rate: 2e-6. Train for 2 epochs.Trick: Batch AggregationTÜLU 3 noticed performance discrepancies between SFT models trained in the Open-Instruct framework and those trained in other environments (such as TPU). This issue primarily arises from a loss aggregation problem in Transformers: averaging the loss of padding tokens without considering gradient accumulation or distributed training settings.The report illustrates this issue with an example. Suppose there are two samples in a batch, each with non-padding tokens and padding tokens. If both samples are input into the default Transformers forward pass:However, if gradient accumulation is applied by separately inputting the two samples, calculating the loss, and then dividing by 2:
In the second case, each sample is treated equally, while in the first case, each token is treated equally. Therefore, changing the gradient accumulation may significantly impact performance by effectively changing sample weights. Similar issues arise in distributed training due to cross-device averaging.
Thus, TÜLU 3 generally opts to use sum loss instead of mean loss during training. This is achieved by simply removing the denominator from the above equation while adjusting the learning rate. This ensures all tokens are given equal weight. TÜLU 3 verified the performance of various settings by fine-tuning Llama 3.0 on the TÜLU 2 SFT mixed dataset using various learning rates, training epochs, and loss types. Ultimately, it was found that using lr = 5e-6 with sum loss yielded the best results. TÜLU 3 also found that longer training did not lead to further improvements, thus determining to use 2 training epochs.
3.2 Preference Finetuning
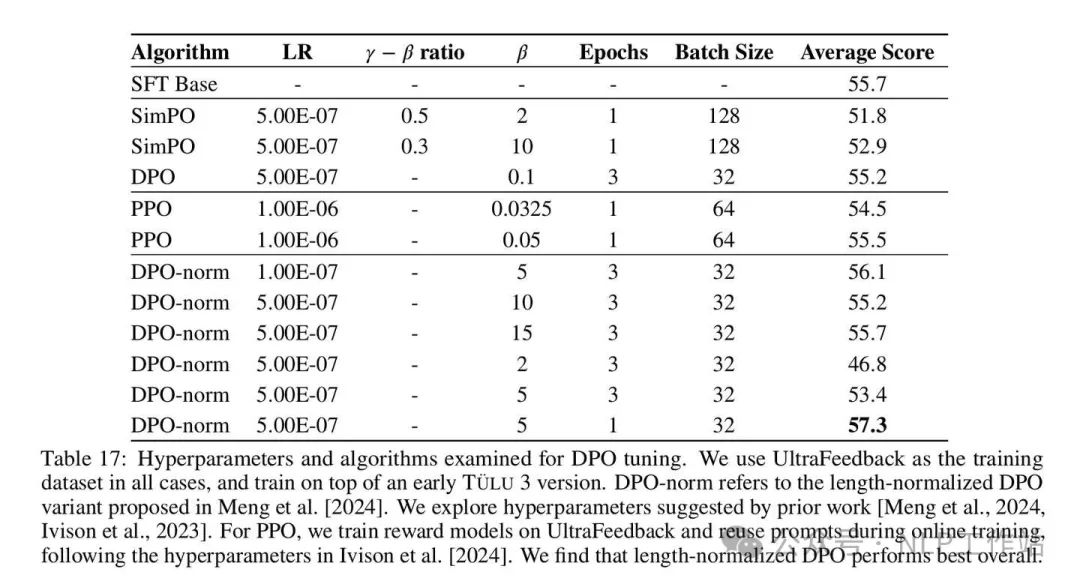
TÜLU 3 mentions numerous experiments in Preference Finetuning.Optimization Algorithm ExperimentsOptimization Algorithm ExperimentsStandard DPO:TÜLU 3 ultimately adopted length-normalized DPO after experiments:By the way, the optimization goal of SimPO (ref model free):The optimization goal of PPO:In the context of TÜLU 3, the experimental conclusion regarding different RL algorithms is that length-normalized DPO performs the best, while SimPO even performs worse than SFT-base.Preference Dataset
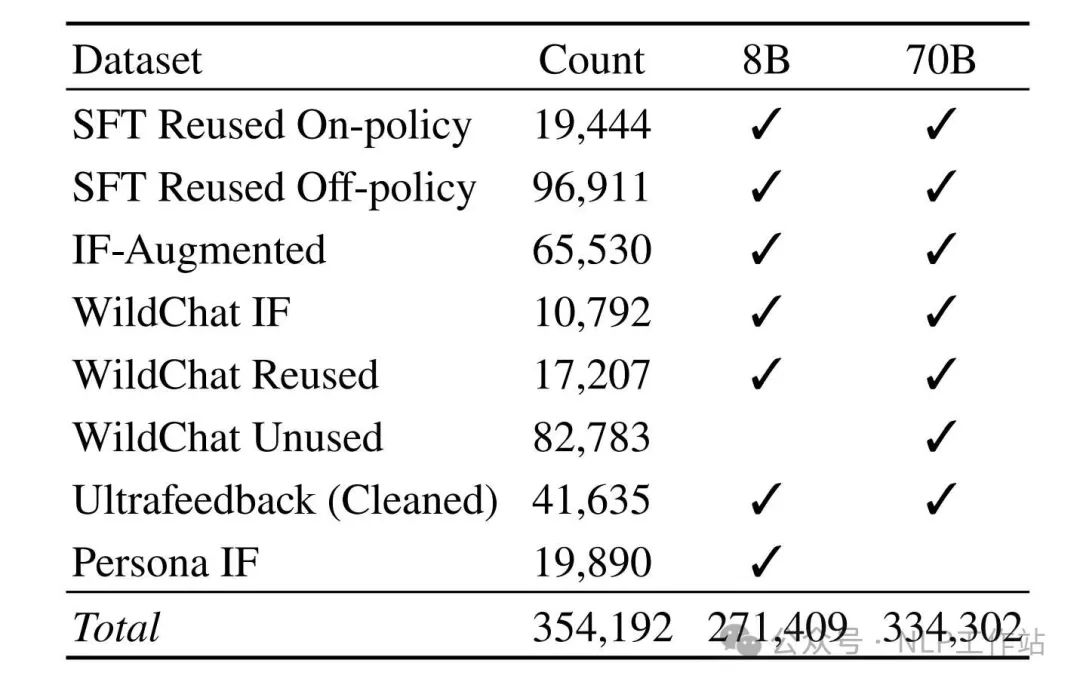
In summary, our preference mixes come from different prompt sources, such as SFT data, WildChat, and Persona IF. It includes prompts seen during SFT training but also new, unseen prompts. And lastly, it contains a mix of on-policy and off-policy completions.
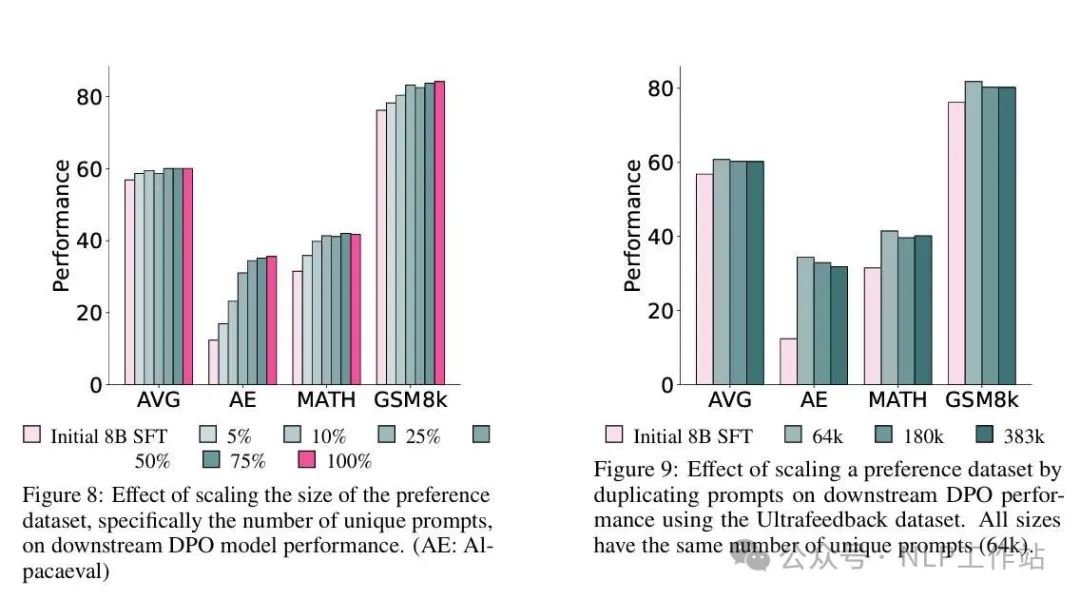
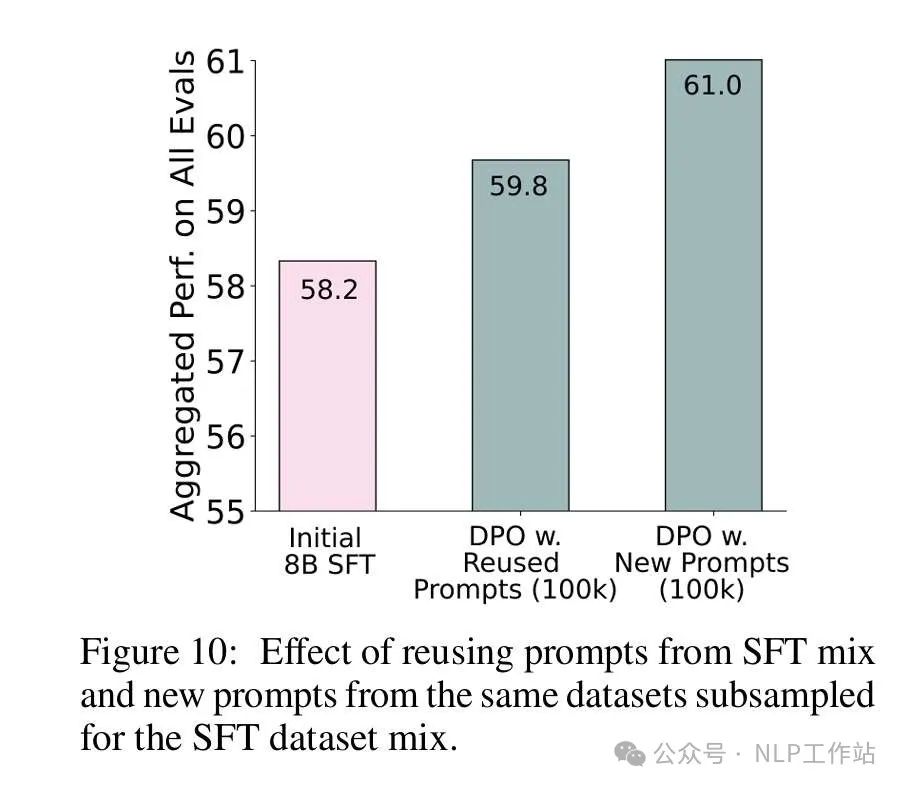
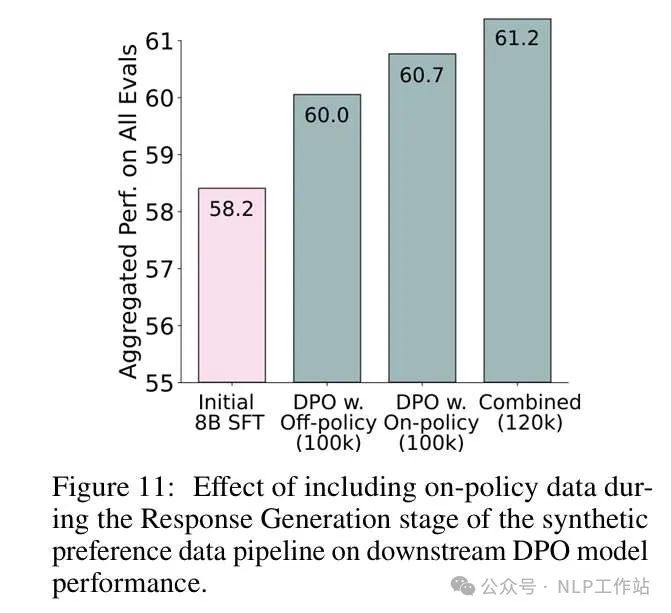
The preference data of TÜLU 3 includes both off-policy pairs and on-policy pairs. It contains prompts seen during the SFT phase as well as new prompts. Human + 4o as Judge. The report conducted numerous experiments on different data mixes, yielding some intuitive conclusions, and lists some:Scaling the Number of Unique Prompts Improves Downstream DPO Performance. Increasing prompt diversity can enhance DPO effectiveness, which is intuitive. However, TÜLU 3 conducted a clear experiment to verify whether duplicating some prompts (but using different response pairs) for data augmentation is feasible. Unfortunately, the result was performance degradation.Unused Prompts Lead to Higher Performance vs. Reusing Prompts From SFT Mix. In other words, prompts in the DPO phase should ideally be those that have not been seen during the SFT phase.On-policy Data Improves Downstream DPO Performance. In other words, on-policy data (pairs sampled by the model) performs better.Recipe
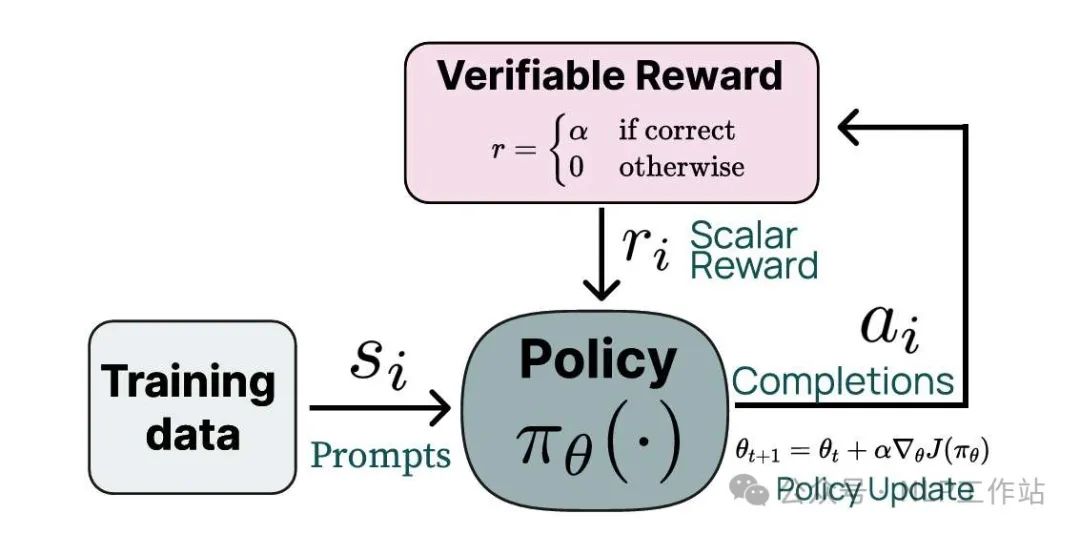
3.3 RLVR (RL with verifiable rewards)
RLVRThis is essentially another term for conducting RL based on Rule-Based RM. Unlike GRPO adopted by DeepSeek-V3 and Qwen2.5, the RLVR algorithm employs PPO. PPO requires a value model, but the reward model is currently a verifier, so TÜLU 3 uses General RM to initialize the value model.Do Not Use the Scores from RM. TÜLU 3 found that using both verifiable rewards and RM rewards simultaneously introduces extra noise, leading to performance degradation.
04
Qwen2.5
paper: https://arxiv.org/abs/2412.15115
The post-training path of Qwen2.5 is SFT + Two-stage Reinforcement Learning, i.e., SFT->DPO->GRPO. The report does not provide many details overall.
4.1 SFT
MathQwen2.5-Math’s CoT data + RS.CodingQwen2.5-Coder’s instruction fine-tuning data.… (no further details are listed)RecipeUltimately, SFT constructed a large-scale dataset containing 1M, trained using a sequence length of 32K, for 2 epochs, with lr decaying from 7×10⁻⁶ to 7×10⁻⁷, weight decay set to 0.1, and gradient norms clipped to a maximum of 1.
4.2 DPO
Rule-based dataRelying on strategies like execution feedback and answer matching, new prompts are sampled using SFT, detected by rules, as chosen, otherwise as rejected, and of course, manual review is also necessary.Data Volume150,000 training pairs.Training RecipeStandard DPO (not mentioned whether length-normalized DPO or variations like SimPO were used), Online Merging Optimizer, lr = 7e-7, trained for 1 epoch.
Related principles can be found in the GRPO section of DeepSeek-V3.RM Training DataWhat models to sample? Deploy multiple models trained with different data mixes and alignment methods, selecting different models for each prompt, with relatively high temperature. The reason: different models can show differences in various capability dimensions, resulting in better data quality and diversity.GRPO DataThe prompts for GRPO are the same as those for RM training.TrickThe order of processing prompt data during training is determined by the variance of the reward scores evaluated by RM. Prompts with higher variance are prioritized to ensure more effective learning.Hyperparameter SettingsSample 8 times for each query. 2048 global batch size and 2048 samples in each episode.
END
Fourth Global Autonomous Driving Summit Preview
On January 14,the Fourth Global Autonomous Driving Summit will be held in Beijing.The main venue will host the opening ceremony, an end-to-end autonomous driving innovation forum, and a city NOA special forum, while the sub-venues will hold technical seminars on autonomous driving visual language models and world models.All the speakers for the summit have been confirmed; scroll down to learn about the final agenda⬇️ Please apply for a free ticket or purchase one to attend~