Linux | Red Hat Certified | IT Technology | Operations Engineer
👇 Join the technical exchange QQ group of 1000 people. Note 【Official Account】 for faster approval.

1. Introduction to Ollama and Docker
(1) Ollama (Ollama)
Ollama is a powerful tool that provides convenience for managing and running models. It simplifies the process of downloading, configuring, and starting models, allowing users to quickly integrate different models into their workflows. For example, when dealing with multiple types of large language models, Ollama can easily manage the switching and invocation between these models, improving development efficiency.
(2) Docker
Docker is the representative of containerization technology, which can package applications and their dependencies into an independent container. In the deployment of DeepSeek, using Docker ensures that deepseek – r1 has a consistent running state across different environments. Whether in development, testing, or production environments, as long as Docker is installed, the same deepseek – r1 container can be run, avoiding compatibility issues caused by environmental differences.
2. Preparation for Configuring DeepSeek-r1 with Ollama and Docker
(1) Hardware Requirements
Similar to conventional DeepSeek deployment, a computer with good performance is required. It is recommended to have at least 16GB of RAM to ensure system smoothness when running containers and models. Additionally, equipping an NVIDIA GPU will significantly enhance the inference speed of the model, which is crucial for handling large-scale text tasks.
(2) Software Installation
Install Docker: You can obtain the installation package suitable for your operating system from the official Docker website and follow the official guidelines for installation. After installation, ensure that the Docker service is running properly, which can be verified through a simple command line test (enter docker in the shell).
Install Ollama: Depending on the operating system you are using, choose the appropriate installation method. For example, on Linux systems, you can install it via a specific script. After installation, configure the environment variables for Ollama to ensure it can be correctly recognized by the system.
3. Detailed Steps to Configure DeepSeek-r1
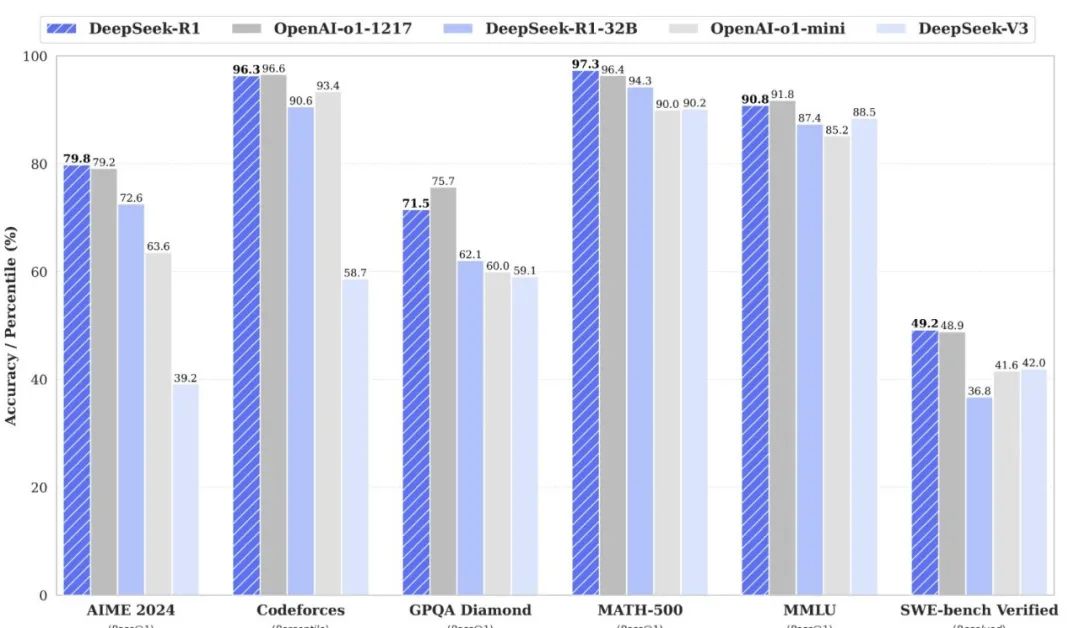
It can be seen that the DeepSeek-r1 full model outperforms OpenAI in various aspects, and in some evaluations, it is even stronger than OpenAI, with a parameter count suitable for local deployment for office use.
(1) Use Ollama to Obtain the DeepSeek-r1 Model
Use Ollama’s command line tool to input specific commands to search for and download the deepseek – r1 model. Ollama will automatically fetch the model files from the official or specified source and store them in the local model library.
(2) Use Docker to Create the DeepSeek-r1 Container
Based on the downloaded deepseek – r1 model, use the Docker command to create a new container. When creating the container, you need to specify the container name, the mounted directory (to interact with the local file system), and the environment variables required for the container to run.
View Model List
You can visit the official Ollama model repository to view the list of supported models. By clicking on a model, you can see detailed descriptions such as model parameters, size, running commands, and other information.
Download Model Command
Use the ollama pull command to download. For example, to download the deepseek – r1 7b model shown in the image, enter in the command line:
ollama pull deepseek-r1:7b (If you do not specify a specific version like 7b, the latest version will be downloaded by default. The first time you run this command to run the model, Ollama will also automatically download the model from the internet).
Notes
Download speed may be affected by network conditions. If the network is unstable, downloading the model may take longer. Some models have certain hardware resource requirements. For example, running larger models (like llama3 – 70b) may be slow or even result in insufficient hardware resources to run properly. It is advisable to understand the hardware requirements of the model before downloading (mainly the memory requirements).
Configure the network settings of the container to ensure that the container can communicate with the outside. Based on actual needs, set the port mapping of the container to allow local applications to access the deepseek – r1 service running inside the container.
(3) Start and Test the DeepSeek-r1 Service
After creating the container, use the Docker command to start the deepseek – r1 container. Once the container is started, Ollama will automatically load the deepseek – r1 model and start the related service processes.
By writing a simple test script, send requests to the deepseek – r1 service running inside the container to verify whether the model is functioning properly. For example, you can send a piece of text to request the model to generate a response and check whether the returned result meets expectations.
(4) Configuration of WebUI
Setting up and deploying Open WebUI
Docker method (recommended by the official website)
Open WebUI official website: GitHub – open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, …)

docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v D:devopen-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainThis command starts a Docker container
docker run: This is the basic command used by Docker to run a container. It creates and starts a new container instance based on the specified image. -d: Indicates that the container runs in detached mode, meaning it will run in the background and not occupy the current command line terminal's input/output stream, allowing other commands to be executed. -p 3000:8080: Port mapping parameter, mapping the container's internal port 8080 to the host's port 3000. This way, by accessing the host's port 3000, you can access the open-webui application running on port 8080 inside the container. --add-host=host.docker.internal:host-gateway: This parameter adds a host mapping record to the container's /etc/hosts file, mapping host.docker.internal to host-gateway. This is very useful when the container needs to communicate with the host, especially in some special network environments, allowing the container to access the host via the host.docker.internal domain name. -v D:devopen-webui:/app/backend/data: This is a volume mount parameter, mounting the host's D:devopen-webui directory to the container's /app/backend/data directory. This means that the host and container can share files in this directory, and any changes in the host directory will be reflected in the container in real-time and vice versa. It is commonly used for data persistence or transferring data between the container and the host. --name open-webui: Specifies a name for the running container as open-webui, making it easier to manage and operate the container later, such as using docker stop open-webui to stop the container or docker start open-webui to start it. --restart always: Indicates that regardless of why the container stops, Docker will automatically attempt to restart it, ensuring the container is always running. ghcr.io/open-webui/open-webui:main: This is the name and tag of the image used by the container, specifying to pull the main version of the open-webui/open-webui image from GitHub Container Registry (ghcr.io). If the local image does not exist, Docker will automatically download it from the specified image repository.Start the Ollama Container
1. Use this command to start the CPU version to run the local AI model
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama2. This command is used to start the GPU version to run the AI model
The prerequisite is that the notebook is configured with NVIDIA GPU drivers, which can be checked in the shell by entering nvidia-smi for details.
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Then you can access the open webui address provided by Docker to start the web interface, select the model, and you can start the Q&A dialogue. Congratulations on having your own AI assistant!
4. Advantages of This Configuration Method
(1) Quick Deployment
The combination of Ollama and Docker greatly shortens the deployment time of deepseek – r1. Through simple command line operations, you can complete model acquisition and container creation, which greatly improves efficiency compared to traditional manual configuration methods.
(2) Environment Isolation
Docker’s containerization technology achieves environment isolation, allowing deepseek – r1 to run in an independent environment without interference from other software on the local system. It also facilitates version management and maintenance of the model. When you need to update or switch model versions, you only need to recreate or update the container.
(3) Easy Expansion
In subsequent applications, if you need to increase the computational resources for the model or deploy multiple deepseek – r1 instances, you can easily expand through Docker’s cluster management features. Ollama can also conveniently manage the collaborative work between multiple models to meet the needs of different business scenarios.
5. Possible Issues and Solutions
(1) Network Issues
During model downloading or container communication, you may encounter unstable network situations. The solution is to check the network connection, try changing the network environment, or use a proxy server. At the same time, both Ollama and Docker provide relevant network configuration options that can be adjusted according to actual conditions.
(2) Resource Conflicts
If there are other services running in the local system that occupy ports or resources, conflicts may arise with the deepseek – r1 container. You can avoid resource conflicts by modifying the container’s port mapping or adjusting the configuration of local services.
Using Ollama and Docker to configure DeepSeek-r1 for local deployment provides an efficient, convenient, and stable deployment method. As artificial intelligence technology continues to develop, this deployment method based on containerization and model management tools will play an important role in more application scenarios, promoting the popularization of large language model technology in local development and applications.
For course inquiries, add: HCIE666CCIE
↓ Or scan the QR code below ↓
What technical points and content do you want to see?
You can leave a message below to let us know!