
Original by Machine Heart
Author: Zeng Xiangji
Editor:Hao Wang
At the 2019 ACM Turing Conference, Professor Zhu Songchun (UCLA) and Dr. Shen Xiangyang (Microsoft Global Executive Vice President) discussed the topic of “Path Choices in the Age of Artificial Intelligence“. Dr. Shen believes that the development of artificial intelligence will usher in a golden decade in the industry, and Professor Zhu also stated that the trend of AI development will move towards unification, from small tasks to large tasks, from six major AI disciplines to a unified approach.
The BERT model in the field of natural language processing perfectly exemplifies this rule. BERT attempts to use a unified model to handle classic tasks in natural language processing, such as reading comprehension, common sense reasoning, and machine translation. Since Google released BERT last October, it has embarked on a long journey of dominance, showing astonishing results in the top-level machine reading comprehension test SQuAD1.1, surpassing humans in all two evaluation metrics, and achieving best results in 11 different NLP tests, including pushing the GLUE benchmark to 80.4% (an absolute improvement of 7.6%) and achieving 86.7% accuracy in MultiNLI (an absolute improvement rate of 5.6%). Although recently some newcomers have surpassed this classic model in various metrics, this is merely a small modification in architecture. Undoubtedly, BERT has opened a new era in the field of natural language processing.
Recently released XLNet has surpassed BERT in several aspects, but the cross-application examples of the BERT language model with existing fields, such as legal documents and scientific papers, still hold significant meaning for the application of XLNet.
The author of this article is Zeng Xiangji, currently a master’s student at Zhejiang University, focusing on common sense reasoning and AutoML, hoping to learn and discuss research papers with everyone.
1. Introduction
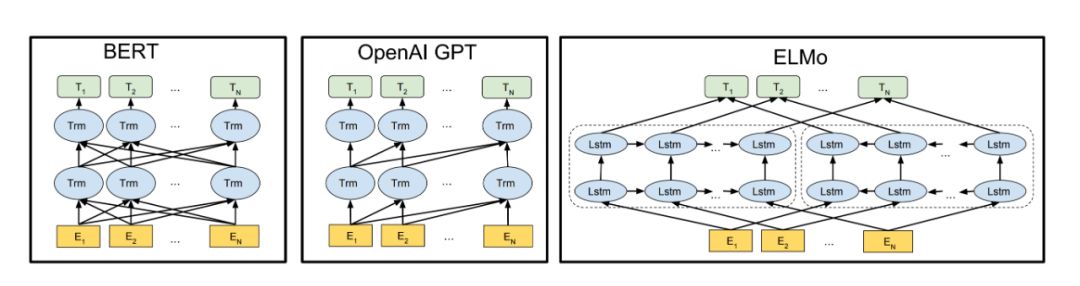
Architecture diagram of BERT, GPT, and ELMo models, source: https://arxiv.org/abs/1810.04805
In the past decade, the revival of deep learning has brought tremendous changes to the field of natural language processing, especially the introduction of the simplified word embedding model word2vec in 2013 laid the groundwork for the application of deep learning in natural language processing. Since neural networks are based on numerical calculations in tensor spaces, they cannot effectively represent natural language text. A bridge is needed to complete this transformation between natural language text and neural networks, and word embeddings serve as that bridge, converting natural language text into dense numerical vectors in a lower-dimensional semantic space. However, the sentence representations after word vector conversion still have significant deficiencies in the overall semantic level because word embeddings cannot effectively address the issue of polysemy.
Language pre-training models attempt to solve the problem of semantic representation in context from another perspective. The internet has a vast amount of text data, but most of this text is unlabeled data. The introduction of the AllenNLP ELMo model addresses the issue of obtaining contextual semantic representations from this vast amount of unmarked text data. However, limited by the capabilities of LSTM, the ELMo model is merely a network model using three layers of BiLSTM. According to traditional views, to capture more accurate semantic representations, deep learning models need to increase the depth of the model network.
The OpenAI GPT model solves this problem by using the Transformer encoding layer as the basic unit of the network. The Transformer discards the cyclical structure of RNN and models a piece of text entirely based on attention mechanisms, allowing the network model to be made deeper. Additionally, the Transformer addresses the issue of RNN’s inability to perform parallel computations, which reduces model training time and increases the possibility of enlarging training datasets.
BERT takes a further step on this basis. Compared to GPT’s left-to-right unidirectional scanning of sentences, each word in the BERT model can perceive the context on both sides, allowing it to capture more information. BERT is pre-trained using two massive datasets: BooksCorpus (800M words) and English Wikipedia (2500M words). Therefore, it can be said that BERT possesses a certain degree of language semantic understanding ability. BERT can serve as the upstream backbone of other task network models, effectively extracting the semantic representation vectors of task data, requiring only fine-tuning to achieve excellent results, giving rise to many amazing downstream applications.
2. Applications
2.1. Knowledge Extraction from Dream of the Red Chamber
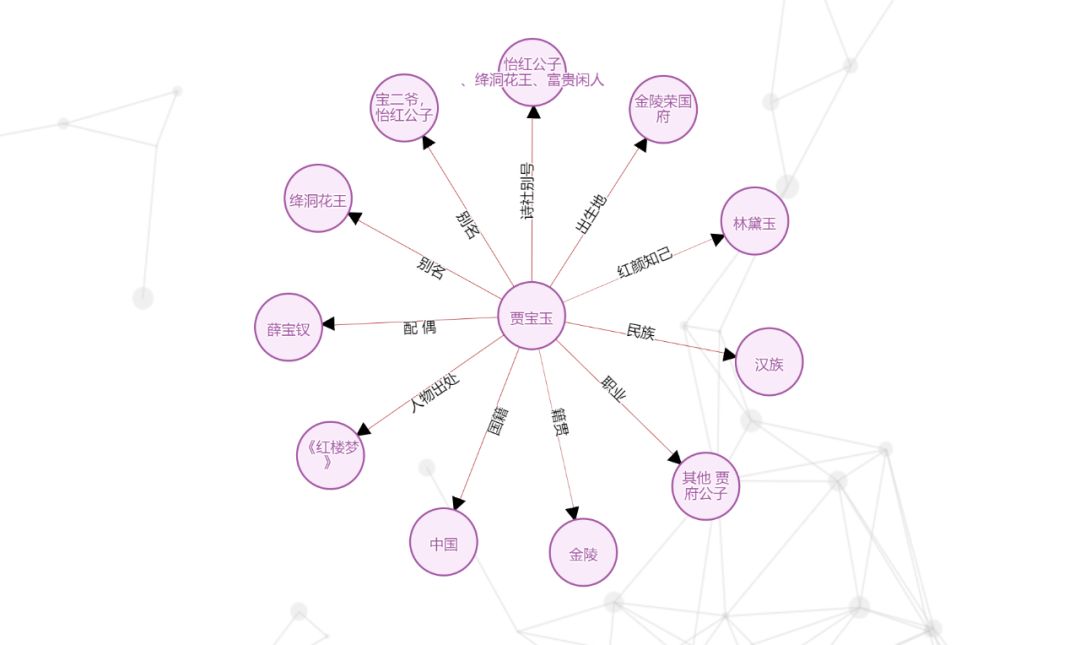
Knowledge graph of characters from Dream of the Red Chamber, source: http://kw.fudan.edu.cn/
The knowledge graph is a core issue in AI research, representing and understanding the world as humans do, enabling machines to perform precise querying, understanding, and logical reasoning. The technologies related to knowledge graphs can be divided into three parts: knowledge extraction, knowledge representation, and knowledge application. Knowledge extraction is primarily responsible for extracting entities and relationships from various structured and unstructured information to build knowledge graphs, knowledge representation studies how to better represent knowledge, and knowledge application utilizes the already constructed knowledge graphs to empower various downstream tasks, giving machines the ability to understand the world.
Knowledge graphs can also help us quickly understand the character relationships in novels. For those who have not read Dream of the Red Chamber carefully or have only partially understood it, we can use BERT to build a machine learning model for knowledge extraction to extract characters, i.e., entities, from Dream of the Red Chamber and analyze the relationships between characters, which is very helpful for quickly understanding the structure of novel characters. An author utilized BERT to create a simple character knowledge graph for Dream of the Red Chamber, and we will detail how the author extracted characters and relationships from the novel.
1) Data Preparation: The author first used regular expressions to extract dialogues from Dream of the Red Chamber. Assuming that the name of the person speaking appears in front of this dialogue, the preceding text can be used as the context containing the speaker. If the speaker is not present in this context, the label is an empty string. Currently, most effective entity extraction models are supervised learning models, so the BERT-based entity extraction model also adopts a supervised method for training. Therefore, the author annotated the previously extracted dialogues. Furthermore, since the technology for extracting relationships between entities is still immature, the author made a simple assumption that adjacent individuals are considered to be in dialogue, which is somewhat valid. The partial results of the annotated data are as follows:
{'uid': 1552, 'context': 'Daiyu said:', 'speaker': 'Daiyu', 'istart': 0, 'iend': 2}
{'uid': 1553, 'context': 'Because of the cloud:', 'speaker': None, 'istart': -1, 'iend': 0}
{'uid': 1554, 'context': 'Baochai said:', 'speaker': 'Baochai', 'istart': 0, 'iend': 2}
{'uid': 1555, 'context': 'The Fifth Patriarch passed on the robe to him. Today's verse is the same meaning. Only the previous sentence has not been completely concluded, how can one let go?" Daiyu laughed and said:', 'speaker': 'Daiyu', 'istart': 46, 'iend': 48}
{'uid': 1556, 'context': 'Baoyu thought he was enlightened, but unexpectedly, when asked by Daiyu, he could not answer. Baochai also pointed out the "Sayings", which they had never seen before. He thought for a moment:', 'speaker': 'Baoyu', 'istart': 0, 'iend': 2}
{'uid': 1557, 'context': 'After thinking, he smiled and said:', 'speaker': None, 'istart': -1, 'iend': 0}
{'uid': 1558, 'context': 'As they spoke, the four returned to their previous state. Suddenly someone reported that the lady sent out a riddle for everyone to guess. Whoever guesses it can also make one to go in. The four hurried out to Jia Mu’s room. They saw a little eunuch holding a four-cornered white gauze lamp made specifically for the riddle, with one already on top, and everyone scrambled to look and guess. The little eunuch also decreed:', 'speaker': 'Little Eunuch', 'istart': 103, 'iend': 106}
{'uid': 1559, 'context': 'The eunuch left, and later transmitted the decree:', 'speaker': 'Eunuch', 'istart': 0, 'iend': 2}
Although the author spent two hours annotating around 1500 pieces of data, this still seemed insufficient for training the model, so the author used data augmentation techniques to expand it to two million pieces of data.
2) Model: The author’s approach to constructing the entity extraction model is to view the entity extraction task as a QA problem, where the question is the dialogue statement and the answer is the extracted entity. Therefore, the author based the entity extraction model on BERT and mimicked the reading comprehension task model from SQuAD.
3) Prediction Results: Due to the power of the BERT model, the author found that the entity extraction effect was excellent through simple QA training, with only a small portion encountering issues. Below are some of the prediction results:

4) Character Relationships: As for the extraction of character entity relationships, the author analyzed relationships using rules based on the previous assumption. Among them, the dialogue between Baoyu and Xiren is the most (178+175), followed by Baoyu and Daiyu (177+174), and Baoyu and Baochai (65+61). Judging solely from the number of dialogues, Xiren and Daiyu occupy roughly the same space in Baoyu’s heart, while Baochai (65+61) occupies only about one-third of Daiyu’s space, slightly more than Qingwen (46+41).
Finally, the author uploaded the code to GitLab: https://gitlab.com/snowhitiger/speakerextraction.
2.2. Intelligence Detection

Hurricane, source: https://www.apnews.com/b4a51136559d44f589319ecfbf6f11a9
With the continuous increase in internet users, the amount of information on the internet has reached a level that cannot be processed by human effort alone, making intelligence information detection very important. Disaster information is a type of intelligence information, used in the preparation, mitigation, response, and recovery phases of disasters and other emergencies, such as explosion detection, sentiment analysis, and hazard assessment.
If disaster information on social media platforms like Facebook and Twitter is not effectively detected, it poses a significant security risk. Traditional disaster information detection relies on keyword filtering methods, but this approach has significant problems: first, the organizational forms of disaster information are constantly changing, and second, social companies have insufficient manpower to effectively maintain the keyword corpus.
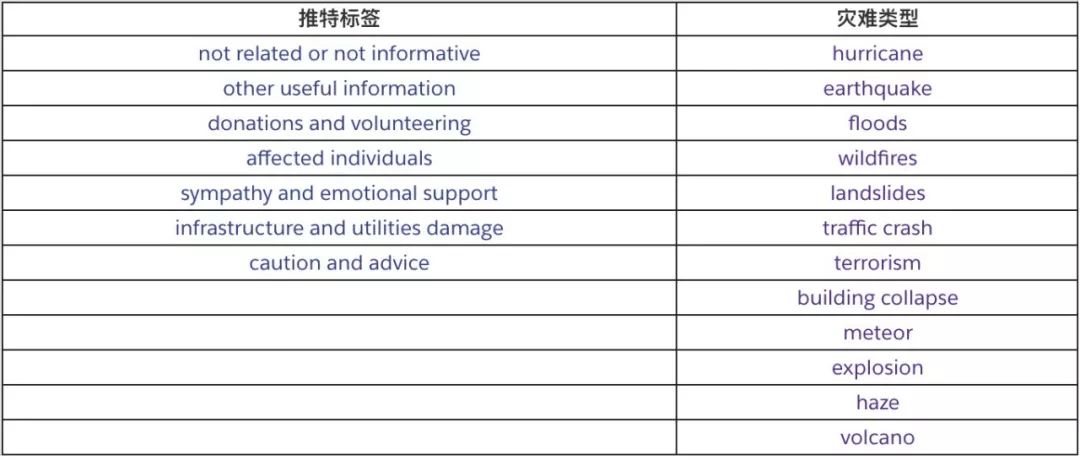
Guoqin Ma extracted a machine learning model based on BERT to process disaster information, treating disaster information on Twitter as a text classification problem. Therefore, in the dataset used by the author, the author categorized Twitter information and disaster types into the following categories:
The author used a single-layer bidirectional LSTM as a baseline, then derived four model variants on BERT: default BERT, BERT+NL, BERT+LSTM, and BERT+CNN.
Among them, default BERT only adds a single-layer fully connected network and softmax to BERT’s output layer, while BERT+NL uses a multi-layer fully connected network and softmax. BERT+LSTM, as the name suggests, inputs BERT’s output layer into an LSTM network, and finally outputs through softmax. BERT+CNN follows the same principle, only replacing LSTM with CNN.
The final experimental results are shown in the following figure, where we can see that the BERT-based models surpassed the baseline model based solely on LSTM in all metrics.

Finally, the author uploaded the code on GitHub: https://github.com/sebsk/CS224N-Project.
2.3. Article Writing
In natural language processing tasks, text generation can be accomplished using the classic sequence-to-sequence model, which consists of an Encoder and a Decoder, generally implemented using RNN. However, using BERT for text generation is typically a challenging problem because BERT uses a MASK method during pre-training, which is an autoencoding (AE) approach, training with context and trying to reproduce the original input. In contrast, general LSTMs use a left-context-to-right-context prediction approach, which is an autoregressive (AR) method naturally suited for text generation, as text generation involves generating one word at a time from left to right.
So, can BERT not be applied to text generation? Alex Wang addressed this question in his paper “BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model”, with the title directly answering the question: BERT has a mouth that can speak.
The author of this paper first proved that BERT is a Markov random field language model (MRF-LM) using pseudo-log likelihood, and a Markov random field can be represented by an undirected graph representing a joint probability distribution, where the next state only depends on the current state, making it a generative model. Additionally, since BERT learns the distribution of sentences to some extent, we can use BERT for text generation, such as news writing, novel writing, and other tasks.
However, unexpectedly, the author later declared in his blog that his derivation was incorrect, and BERT is not a Markov random field, link at the end of the section. Although the author clarified that BERT is not a Markov random field, it can still be used as a generative model.
Blog link: http://www.kyunghyuncho.me/home/blog/amistakeinwangchoberthasamouthanditmustspeakbertasamarkovrandomfieldlanguagemodel
We can see the generated effects as follows (left is the effect generated by BERT, right is the effect generated by GPT):

Finally, the author uploaded the code to GitHub: https://github.com/nyu-dl/bert-gen.
2.4. BERT for Legal Documents

Legal documents, source: https://tutorcruncher.com/business-growth/legal-implications-when-starting-a-tutoring-business/
In the field of natural language processing, the quality of training data text is crucial; high-quality text data allows models to learn faster and better. The legal industry is one of the few fields that possesses high-quality text data because the quality of legal documents, contracts, and other texts is closely related to the personal interests of the relevant parties, prompting them to repeatedly review the content to ensure text quality.
Recently, the Tsinghua University AI Research Institute and Power Law Intelligence released several pre-trained BERT models for the Chinese domain, including civil document BERT and criminal document BERT, which are pre-trained language models specifically for the legal field.
Civil document BERT is trained on 2654 civil documents, and tests show that it learns relevant legal tasks faster and significantly outperforms Google’s official Chinese BERT. Criminal BERT is trained on 6.63 million criminal documents and also performs better than the original Chinese BERT on related tasks. The following are the test results:

The pre-trained legal BERT model of this project is fully compatible with the famous open-source project https://github.com/huggingface/pytorch-pretrained-BERT, with only model parameters changed. Additionally, due to the comprehensive documentation of pytorch-pretrained-BERT, this model can be quickly grasped by those who want to try it and are familiar with PyTorch.
We can find the relevant project information and model links on GitHub: https://github.com/thunlp/OpenCLaP
2.5. Scientific Papers
Recently, a paper published by the Lawrence Berkeley National Laboratory of the U.S. Department of Energy in the journal Nature has attracted widespread attention. Researchers stated that their unsupervised pre-trained word embeddings discovered new scientific knowledge after automatically reading 3 million materials science papers. They trained the abstracts of these papers using the word2vec algorithm for word embedding, and by analyzing the relationships between words, they were able to predict new thermoelectric materials years in advance, identifying candidates with application potential among currently unknown materials.
In the field of paper text pre-training, there is also a model based on BERT. SciBERT is a BERT model pre-trained on scientific paper texts proposed by AllenNLP. According to the introduction of SciBERT, it has the following characteristics:
-
It is fully trained based on the full texts from semanticscholar.org (https://semanticscholar.org/), not just the abstracts, with a total of 1.14M papers and 3.1B text tokens;
-
SciBERT has its own vocabulary, scivocab, which completely matches the training corpus;
-
It has achieved state-of-the-art levels in all natural language processing tasks across scientific fields, as shown in the figure below;
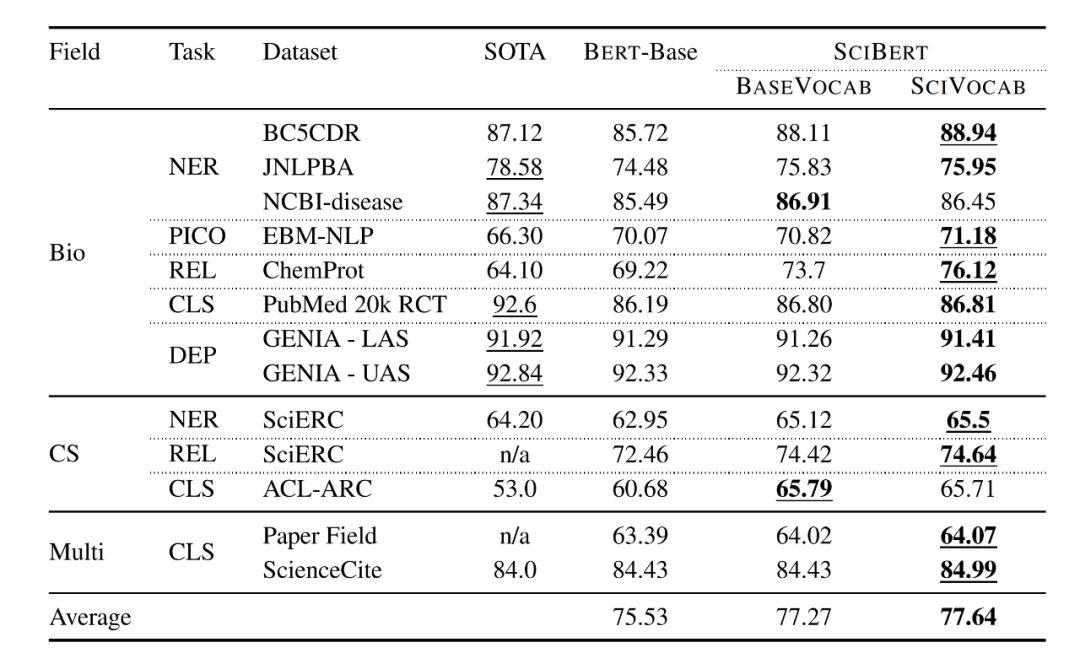
Finally, we can find the source code and pre-trained model for download on GitHub: https://github.com/allenai/scibert.
3. Conclusion
Since BERT has learned a vast amount of language feature prior knowledge from massive texts through the powerful feature extractor Transformer, it has shown excellent results for most natural language processing tasks. If BERT were compared to a person, its reading volume would reach levels unattainable in a lifetime, making it, in a sense, an erudite scholar. BERT has opened a new era in natural language processing, and standing on the shoulders of this giant, we believe that more interesting work will emerge in the future!
This article is original from Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time reporter / Intern): [email protected]
Submissions or seeking reports: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]