
Click the above “MLNLP” to select “Star” public account
Important content delivered at the first time
From | Zhihu
Author | Yao Shi
Column | The Path of Learning Non-Convex Optimization
Editor | Machine Learning Algorithms and Natural Language Processing
[TensorFlow] Source Code Analysis of AdamOptimizer
The optimizers in TensorFlow basically inherit from the “class Optimizer”, and AdamOptimizer is no exception. This article attempts to interpret the source code of this optimizer. Source code location: /tensorflow/python/training/adam.py
-
From the code block below, we can see that
<span>AdamOptimizer</span>inherits from<span>Optimizer</span>, so even though the<span>AdamOptimizer</span>class does not have a<span>minimize</span>method, it can still use the implementation of this method from the parent class. Additionally, the implementation of the Adam algorithm follows the paper published by [Kingma et al., 2014] at ICLR.
@tf_export(v1=["train.AdamOptimizer"])
class AdamOptimizer(optimizer.Optimizer):
"""Optimizer that implements the Adam algorithm.
See [Kingma et al., 2014](http://arxiv.org/abs/1412.6980)
([pdf](http://arxiv.org/pdf/1412.6980.pdf)).
"""-
Before introducing the code, let’s explain the calculation formula of the
<span>Adam</span>algorithm. The scheme given in the paper [Kingma et al., 2014] is that the learning rate at each step will change adaptively based on the initial learning rate
will change adaptively based on the initial learning rate  , while
, while  can effectively prevent the denominator from being zero.
can effectively prevent the denominator from being zero.
Initialize moment and timestep :
Iteration :





-
The
<span>__init__</span>function is used for initializing the<span>class AdamOptimizer</span>, with a default learning rate of0.001, and the values of and
and  default to
default to 0.9and0.999, respectively, while defaults to
defaults to 1e-8. Therefore, in practical use, even if the learning rate is not set, it can still be used normally because the optimizer will automatically use the default values to solve the optimization problem.
def __init__(self, learning_rate=0.001,
beta1=0.9, beta2=0.999, epsilon=1e-8,
use_locking=False, name="Adam"):
super(AdamOptimizer, self).__init__(use_locking, name)
self._lr = learning_rate
self._beta1 = beta1
self._beta2 = beta2
self._epsilon = epsilon
# Tensor versions of the constructor arguments, created in _prepare().
self._lr_t = None
self._beta1_t = None
self._beta2_t = None
self._epsilon_t = None-
From the above
<span>__init__</span>function, we can see that besides the parameters passed in during initialization, the optimizer itself also stores the Tensor versions of these parameters, and this conversion is done in the<span>_prepare</span>function using the<span>convert_to_tensor</span>method. This function is located at<span>/tensorflow/python/framework/ops.py#L1021</span>, and its function is to<span>Converts the given 'value' to a 'Tensor'</span>, which allows accepted values to be'Tensor' objects, numpy arrays, Python lists, and Python scalars.
def _prepare(self):
lr = self._call_if_callable(self._lr)
beta1 = self._call_if_callable(self._beta1)
beta2 = self._call_if_callable(self._beta2)
epsilon = self._call_if_callable(self._epsilon)
self._lr_t = ops.convert_to_tensor(lr, name="learning_rate")
self._beta1_t = ops.convert_to_tensor(beta1, name="beta1")
self._beta2_t = ops.convert_to_tensor(beta2, name="beta2")
self._epsilon_t = ops.convert_to_tensor(epsilon, name="epsilon")-
The
<span>_get_beta_accumulators</span>function and the<span>_create_slots</span>function can be viewed together. As the name suggests, the<span>_create_slots</span>function is used to create parameters, and from the code, we can see that the created parameters include ,
,  , and
, and  to the
to the  power (the
power (the beta1_power) and to the
to the  power (the
power (the beta2_power). The<span>_get_beta_accumulators</span>function is used to get the to the
to the  power (beta1_power) and
power (beta1_power) and  to the
to the  power (beta2_power) values.
power (beta2_power) values.
def _get_beta_accumulators(self):
with ops.init_scope():
if context.executing_eagerly():
graph = None
else:
graph = ops.get_default_graph()
return (self._get_non_slot_variable("beta1_power", graph=graph),
self._get_non_slot_variable("beta2_power", graph=graph))
def _create_slots(self, var_list):
first_var = min(var_list, key=lambda x: x.name)
self._create_non_slot_variable(initial_value=self._beta1,
name="beta1_power",
colocate_with=first_var)
self._create_non_slot_variable(initial_value=self._beta2,
name="beta2_power",
colocate_with=first_var)
# Create slots for the first and second moments.
for v in var_list:
self._zeros_slot(v, "m", self._name)
self._zeros_slot(v, "v", self._name)-
The
_apply_dense,_resource_apply_dense,_apply_sparse, and_resource_apply_sparsefunctions are all overrides of methods in the parent class. -
The
_apply_denseand_resource_apply_denseimplementations use thetraining_ops.apply_adamandtraining_ops.resource_apply_adammethods, respectively, so the specific implementation of the Adam algorithm’s iterative operation is not here. By carefully analyzing the code, it is found that it is defined in/tensorflow/core/kernels/training_ops.hand implemented in/tensorflow/core/kernels/training_ops.cc.
def _apply_dense(self, grad, var):
m = self.get_slot(var, "m")
v = self.get_slot(var, "v")
beta1_power, beta2_power = self._get_beta_accumulators()
return training_ops.apply_adam(
var,
m,
v,
math_ops.cast(beta1_power, var.dtype.base_dtype),
math_ops.cast(beta2_power, var.dtype.base_dtype),
math_ops.cast(self._lr_t, var.dtype.base_dtype),
math_ops.cast(self._beta1_t, var.dtype.base_dtype),
math_ops.cast(self._beta2_t, var.dtype.base_dtype),
math_ops.cast(self._epsilon_t, var.dtype.base_dtype),
grad,
use_locking=self._use_locking).op
def _resource_apply_dense(self, grad, var):
m = self.get_slot(var, "m")
v = self.get_slot(var, "v")
beta1_power, beta2_power = self._get_beta_accumulators()
return training_ops.resource_apply_adam(
var.handle,
m.handle,
v.handle,
math_ops.cast(beta1_power, grad.dtype.base_dtype),
math_ops.cast(beta2_power, grad.dtype.base_dtype),
math_ops.cast(self._lr_t, grad.dtype.base_dtype),
math_ops.cast(self._beta1_t, grad.dtype.base_dtype),
math_ops.cast(self._beta2_t, grad.dtype.base_dtype),
math_ops.cast(self._epsilon_t, grad.dtype.base_dtype),
grad,
use_locking=self._use_locking)// train_ops.h : 138 Line
template <typename Device, typename T>
struct ApplyAdam {
void operator()(const Device& d, typename TTypes<T>::Flat var,
typename TTypes<T>::Flat m, typename TTypes<T>::Flat v,
typename TTypes<T>::ConstScalar beta1_power,
typename TTypes<T>::ConstScalar beta2_power,
typename TTypes<T>::ConstScalar lr,
typename TTypes<T>::ConstScalar beta1,
typename TTypes<T>::ConstScalar beta2,
typename TTypes<T>::ConstScalar epsilon,
typename TTypes<T>::ConstFlat grad, bool use_nesterov);
};// train_ops.cc : 303 Line
template <typename Device, typename T>
struct ApplyAdamNonCuda {
void operator()(const Device& d, typename TTypes<T>::Flat var,
typename TTypes<T>::Flat m, typename TTypes<T>::Flat v,
typename TTypes<T>::ConstScalar beta1_power,
typename TTypes<T>::ConstScalar beta2_power,
typename TTypes<T>::ConstScalar lr,
typename TTypes<T>::ConstScalar beta1,
typename TTypes<T>::ConstScalar beta2,
typename TTypes<T>::ConstScalar epsilon,
typename TTypes<T>::ConstFlat grad, bool use_nesterov)
// ...
const T alpha = lr() * Eigen::numext::sqrt(T(1) - beta2_power()) / (T(1) - beta1_power());
// ...
if (use_nesterov) {
m += (g - m) * (T(1) - beta1());
v += (g.square() - v) * (T(1) - beta2());
var -= ((g * (T(1) - beta1()) + beta1() * m) * alpha) / (v.sqrt() + epsilon());
} else {
m += (g - m) * (T(1) - beta1());
v += (g.square() - v) * (T(1) - beta2());
var -= (m * alpha) / (v.sqrt() + epsilon());
}
// ...
// train_ops.cc : 392 Line
template <typename T>
struct ApplyAdam<CPUDevice, T> : ApplyAdamNonCuda<CPUDevice, T> {};-
In
<span>http://train_ops.cc</span>, the update formulas for and
and  seem to differ from what we mentioned earlier, but they are actually the same, i.e.,
seem to differ from what we mentioned earlier, but they are actually the same, i.e.,


-
The
_apply_sparseand_resource_apply_sparsefunctions are mainly used for updating sparse vectors, and the specific implementation is in the_apply_sparse_sharedfunction.
def _apply_sparse(self, grad, var):
return self._apply_sparse_shared(grad.values, var, grad.indices,
lambda x, i, v: state_ops.scatter_add(x, i, v, use_locking=self._use_locking))
def _resource_apply_sparse(self, grad, var, indices):
return self._apply_sparse_shared(grad, var, indices, self._resource_scatter_add)
def _resource_scatter_add(self, x, i, v):
with ops.control_dependencies([resource_variable_ops.resource_scatter_add(x.handle, i, v)]):
return x.value()-
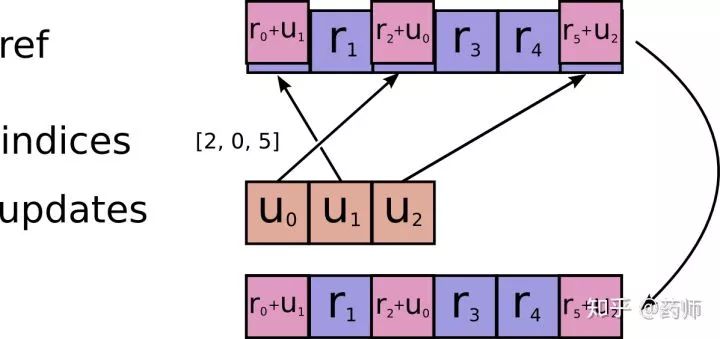
Before introducing the
_apply_sparse_sharedfunction, let’s introduce thestate_ops.scatter_addfunction, which is defined at/tensorflow/python/ops/state_ops.py#L372. Its function is toAdds sparse updates to the variable referenced by 'resource', i.e., it completes the addition operation of sparse Tensors, as shown in the figure below.
-
Now, let’s go back to the
_apply_sparse_sharedfunction. The code is simple; first, it retrieves the required parameter values and stores them in variables, then calculates the learning rate (i.e.,
(i.e., lr=...in the code), and then calculates the two Moments. Since it is an update of sparse Tensors, after calculating the update value, it usesscatter_addto complete the addition operation. Note that thisscatter_addis passed in as a function parameter, which allows for modification when specific addition operations are needed. Finally, thevar_updateandm_t,v_tupdate operations are placed incontrol_flow_ops.group.
def _apply_sparse_shared(self, grad, var, indices, scatter_add):
beta1_power, beta2_power = self._get_beta_accumulators()
beta1_power = math_ops.cast(beta1_power, var.dtype.base_dtype)
beta2_power = math_ops.cast(beta2_power, var.dtype.base_dtype)
lr_t = math_ops.cast(self._lr_t, var.dtype.base_dtype)
beta1_t = math_ops.cast(self._beta1_t, var.dtype.base_dtype)
beta2_t = math_ops.cast(self._beta2_t, var.dtype.base_dtype)
epsilon_t = math_ops.cast(self._epsilon_t, var.dtype.base_dtype)
lr = (lr_t * math_ops.sqrt(1 - beta2_power) / (1 - beta1_power))
# m_t = beta1 * m + (1 - beta1) * g_t
m = self.get_slot(var, "m")
m_scaled_g_values = grad * (1 - beta1_t)
m_t = state_ops.assign(m, m * beta1_t, use_locking=self._use_locking)
with ops.control_dependencies([m_t]):
m_t = scatter_add(m, indices, m_scaled_g_values)
# v_t = beta2 * v + (1 - beta2) * (g_t * g_t)
v = self.get_slot(var, "v")
v_scaled_g_values = (grad * grad) * (1 - beta2_t)
v_t = state_ops.assign(v, v * beta2_t, use_locking=self._use_locking)
with ops.control_dependencies([v_t]):
v_t = scatter_add(v, indices, v_scaled_g_values)
v_sqrt = math_ops.sqrt(v_t)
var_update = state_ops.assign_sub(var, lr * m_t / (v_sqrt + epsilon_t), use_locking=self._use_locking)
return control_flow_ops.group(*[var_update, m_t, v_t])-
Now, let’s talk about the last function
_finish. We have introduced so much, but we haven’t mentioned how ‘s
‘s  power (the
power (the beta1_power) and ‘s
‘s  power (the
power (the beta2_power) are calculated. In fact, TensorFlow places the updates for these two parameters in a separate function, which is the_finishfunction.
def _finish(self, update_ops, name_scope):
# Update the power accumulators.
with ops.control_dependencies(update_ops):
beta1_power, beta2_power = self._get_beta_accumulators()
with ops.colocate_with(beta1_power):
update_beta1 = beta1_power.assign(beta1_power * self._beta1_t, use_locking=self._use_locking)
update_beta2 = beta2_power.assign(beta2_power * self._beta2_t, use_locking=self._use_locking)
return control_flow_ops.group(*update_ops + [update_beta1, update_beta2], name=name_scope)-
We find that the update calculations for the Adam algorithm are put into
<span>control_flow_ops.group</span>, and the specific implementation of the<span>group</span>function is at<span>/tensorflow/python/ops/control_flow_ops.py#L3595</span>.
# TODO(touts): Accept "inputs" as a list.
@tf_export("group")
def group(*inputs, **kwargs):
"""Create an op that groups multiple operations.
When this op finishes, all ops in `inputs` have finished. This op has no output.
See also `tf.tuple` and `tf.control_dependencies`.
Args:
*inputs: Zero or more tensors to group.
name: A name for this operation (optional).
Returns:
An Operation that executes all its inputs.
Raises:
ValueError: If an unknown keyword argument is provided.
"""
Recommended Reading:
Research on Text Smoothing Based on Multi-Task Self-Supervised Learning
[PyTorch] Optimizer torch.optim.Optimizer
Text Classification Based on Transformers+CNN/LSTM/GRU
