
Author丨Tian Yu Su
Zhihu Column丨Machine Learning
Link丨https://zhuanlan.zhihu.com/p/27296712
Introduction
The second practical code is updated. The previous column introduced the Skip-Gram model in Word2Vec. If you have read it, you can directly start implementing your own Word2Vec model using TensorFlow. This article will use TensorFlow to complete the Skip-Gram model. If you are not familiar with the Skip-Gram concept, you can refer to the previous column. The purpose of this practical code is mainly to deepen the understanding of some ideas and tricks in the Skip-Gram model. Due to limitations in corpus size, quality, algorithm details, and training costs, the results obtained are obviously not comparable to the Word2Vec encapsulated by gensim. This code is suitable for beginners to understand and practice the ideas of the Skip-Gram model.
Tool Introduction
-
Language: Python 3
-
Packages: TensorFlow (version 1.0) and other data processing packages (see code)
-
Editor: Jupyter Notebook
-
Online GPU: Floyd
-
Dataset: Preprocessed Wikipedia articles (English)
Main Content
The article mainly includes the following four parts for code construction: – Data preprocessing – Training sample construction – Model construction – Model validation
1 Data Preprocessing
We will not write about importing packages and loading data here, as it is quite simple. Please refer to the code on Git.
The data preprocessing part mainly includes:
-
Replacing special symbols in text and removing low-frequency words
-
Tokenizing the text
-
Building the corpus
-
Word mapping table
First, we define a function to accomplish the first two steps, which are text cleaning and tokenization.

The above function implements the replacement of punctuation and the removal of low-frequency words, returning the tokenized text.
Next, let’s take a look at the cleaned data:

With the tokenized text, we can build our mapping table. The code will not be elaborated as everyone should be familiar with it.

We can also take a look at the size of the text and the dictionary:

The entire text contains approximately 16.6 million words, and the dictionary size is about 60,000. This scale is not sufficient for training quality word vectors, but it can train a somewhat decent model.
2 Training Sample Construction
We know that in skip-gram, the training sample format is (input word, output word), where the output word is the context of the input word. To reduce model noise and speed up training, we need to sample the training samples before constructing the batch, eliminating stop words and other noise factors.
Sampling
During the modeling process, many common words (also known as stop words) such as “the” and “a” appear in the training text, and these words introduce a lot of noise into our training. In the previous Word2Vec, we mentioned sampling the samples to eliminate high-frequency stop words to reduce noise and speed up training.
We use the following formula to calculate the probability of each word being deleted:

Where represents the occurrence frequency of the word.
represents the occurrence frequency of the word. is a threshold, usually between 1e-3 and 1e-5.
is a threshold, usually between 1e-3 and 1e-5.

The above code calculates the probability of each word being deleted in the sample and samples based on the probability. Now we have a sampled list of words.
Constructing the Batch
First, let’s analyze the sample format of skip-gram. Skip-gram differs from CBOW in that CBOW predicts the current input word based on the context. In contrast, skip-gram predicts the context based on an input word, so one input word corresponds to multiple contexts. For example, “The quick brown fox jumps over lazy dog”; if we fix skip_window=2, then the context of “fox” is [quick, brown, jumps, over]. If our batch_size=1, then there are actually four training samples in one batch.
The above analysis translates into code as two steps. The first is to find the context for each input word, and the second is to construct the batch based on the context.
First, find the list of context words for the input word:

We define a function called get_targets, which takes a word index and finds the corresponding context in the word table based on this index (with a default window_size=5). Note that there is a small trick here: when selecting the context for the input word, the window size used is a random number between [1, window_size]. The purpose here is to make the model pay more attention to words that are closer to the input word.
With the above function, we can easily find the context words for an input word. With these words, we can construct our batch for training:

Note the handling of the batch in the above code. We know that for each input word, there are multiple output words (contexts). For example, if our input is “fox” and the context is [quick, brown, jumps, over], then there are four training samples in this batch: [fox, quick], [fox, brown], [fox, jumps], [fox, over].
3 Model Construction
After data preprocessing, we need to construct our model. In the model, to accelerate training and improve the quality of word vectors, we use negative sampling for weight updates.
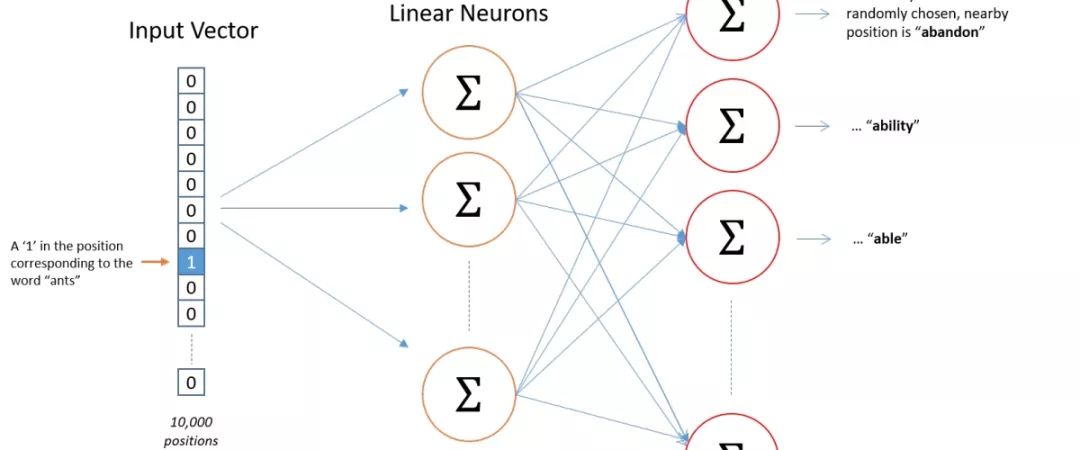
Input Layer to Embedding Layer
The weight matrix from the input layer to the hidden layer is set to the embedding layer, and the dimension is generally set between 50-300 for embedding_size.

The lookup of the embedding layer is implemented through embedding_lookup in TensorFlow.
Embedding Layer to Output Layer
In skip-gram, the multiple context words for each input word actually share a weight matrix. We treat each (input word, output word) training sample as our input. To accelerate training and improve the quality of word vectors, we use negative sampling for weight updates.
In TensorFlow, the sampled_softmax_loss is used, and due to negative sampling, we will actually underestimate the training loss of the model.

Please note that the dimension of softmax_w in the code is vocab_size x embedding_size, because the size of the parameter weights in TensorFlow’s sampled_softmax_loss is [num_classes, dim].
4 Model Validation
In the above steps, we have built the framework of the model. Next, let’s train the model. To observe the situation at each training stage more intuitively, we will select a few words and see how their similar words change during training.

Train the model:

Here, please note that you should avoid frequently printing the similar words from the validation set because it adds an extra calculation step, which is the similarity calculation, and will consume a lot of computational resources. The calculation process is also very slow. Therefore, I set the code to print the results every 1000 iterations.

From the final training results, the model has learned some common word semantics, such as counting words like “one” and metal words like “gold”. The similar words in “animals” are also relatively accurate.
To observe our training results more comprehensively, we use TSNE from sklearn to visualize the high-dimensional word vectors. (See Git for specific code)
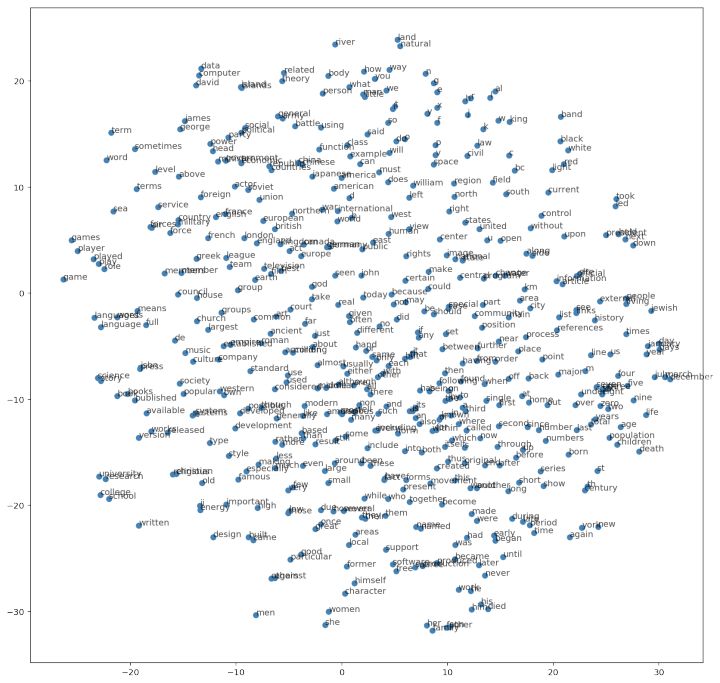
The above figure shows the high-dimensional word vectors displayed in a two-dimensional coordinate system according to the distance. This figure is already in the Git repository. If you want to see the original image, please check Git~
Let’s take a look at the details:

The above shows a local area of the whole large image, and the effect looks pretty good.
Tips for improving the effect:
Increase the training samples; the larger the corpus, the more learnable information the model will have.
Increase the window size to obtain more context information.
Increase the embedding size to reduce the dimensional loss of information, but it should not be too large. I generally use a scale of 50-300.
Appendix:
The Git code also provides code for calculating Chinese word vectors. It also provides a training corpus in Chinese, which I crawled from a recruitment website, performed tokenization, and removed stop words (available from Git), but the corpus scale is too small, and the training effect is not good.

Above is the Chinese data I trained with the model. It can be seen that some semantics have been mined out, such as the closeness of “word” to “excel”, “office”, and “ppt” to “project”, “text processing”, etc., as well as logical thinking and language expression, but overall the effect is still poor. On one hand, the corpus scale is too small (only 70MB of corpus), and on the other hand, the model has not been fine-tuned. If interested students can try it themselves to see if they can achieve better results.
Recommended Reading:
Practical | Pytorch BiLSTM + CRF for NER
How to evaluate the fastText algorithm proposed by the author of Word2Vec? Does deep learning have no advantage in simple tasks like text classification?
From Word2Vec to Bert, discussing the evolution of word vectors (Part 1)
