Machine Heart Column
This column is produced by Machine Heart SOTA! Model Resource Station, updated every Sunday on the Machine Heart public account. This column will review common tasks in natural language processing, computer vision, etc., and provide detailed explanations of classic models that have achieved SOTA in these tasks. Visit SOTA! Model Resource Station (sota.jiqizhixin.com) to obtain the model implementation code, pre-trained models, and API resources included in this article.
This article will be serialized in 3 issues, introducing a total of 20 classic models that have achieved SOTA in text classification tasks.
-
Issue 1: RAE, DAN, TextRCNN, Multi-task, DeepMoji, RNN-Capsule
-
Issue 2: TextCNN, dcnn, XML-CNN, textCapsule, Bao et al., AttentionXML
-
Issue 3: ELMo, GPT, BERT, ALBERT, X-Transformer, LightXML, TextGCN, TensorGCN
You are reading Issue 1. Visit SOTA! Model Resource Station (sota.jiqizhixin.com) to obtain the model implementation code, pre-trained models, and API resources included in this article.
Overview of Models Included in This Issue
| Model | SOTA! Model Resource Station Inclusion Status | Source Paper |
|---|---|---|
| RAE | Inclusion Count: 1 | Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions |
| DAN | Inclusion Count: 1 | Deep Unordered Composition Rivals Syntactic Methods for Text Classification |
| TextRCNN | Inclusion Count: 1 Supported Framework: TensorFlow | Recurrent Convolutional Neural Networks for Text Classification |
| Multi-task | Inclusion Count: 1 Supported Framework: PyTorch | Recurrent Neural Network for Text Classification with Multi-Task Learning |
| DeepMoji | Inclusion Count: 8 Supported Framework: TensorFlow, PyTorch, Keras | Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm |
| RNN-Capsule | Inclusion Count: 1 Supported Framework: TensorFlow | Investigating Capsule Networks with Dynamic Routing for Text Classification |
Text classification is one of the most fundamental and classic tasks in natural language processing, with most NLP tasks being considered classification tasks. In recent years, deep learning has achieved tremendous success in many research fields and has become a standard technology in the NLP field, widely permeating text classification tasks.
Unlike numerical and image data, text processing emphasizes refined processing capabilities. Traditional text classification methods generally require preprocessing the input text data for the model, as well as acquiring good sample features through manual labeling, followed by classification using classic machine learning algorithms. Such methods include Naive Bayes (NB), K-Nearest Neighbors (KNN), Support Vector Machines (SVM), etc. The level of feature extraction has an even greater impact on text classification performance than image classification, and feature engineering in text classification is often very time-consuming and computationally expensive. After 2010, text classification methods gradually transitioned to deep learning models. Deep learning applied to text classification directly maps feature engineering to output through learning a series of nonlinear transformation patterns, thereby integrating feature engineering into the model fitting process, achieving tremendous success upon application.
Unlike image classification models, text classification models generally do not improve by stacking modules or modifying deep model structures; rather, they often improve model performance by introducing other technical means, such as attention mechanisms, pre-training, graph neural networks, capsule networks, etc. Therefore, when introducing classic text classification models, we focus more on which specific problems in text classification they aim to solve, the specialized technical tricks introduced, and how these tricks integrate with the original classic architecture.
Furthermore, much work in the NLP field focuses on the front-end processing of words, sentences, and texts or semantic understanding, aiming to serve various downstream tasks, including text classification tasks. To focus more on text classification models, we will only introduce dedicated text classification models in this article, while other NLP models will be covered in subsequent reports. Lastly, the emergence of BERT has clearly shown two distinct development stages for text classification models; after BERT was proposed (after 2019), methods based purely on RNN and CNN improvements that achieved significant results have become relatively rare.
1. ReNN
Recursive Neural Networks (ReNN) can automatically learn the semantics of text and the syntactic tree structure without feature design. ReNN is one of the earliest deep learning models applied to text classification. Compared to traditional models, ReNN-based models improve performance and save labor costs by eliminating the need for feature design for different text classification tasks. We will specifically introduce the RAE model within ReNN.
1.1 RAE
Recursive AutoEncoders (RAE) are used to predict the sentiment label distribution of each input sentence and learn representations of multi-word phrases. During text analysis, the vector space of a certain segment of text is obtained based on word vectors, and then analyzed layer by layer, ultimately obtaining the vector representation of the entire segment of text, from which user sentiment can be inferred. The RAE-related paper was first published in EMNLP 2011. Figure 1 illustrates an RAE model, which learns vector representations of phrases and complete sentences and their hierarchical structure from unsupervised text. The authors expanded the model to learn the distribution of sentiment labels at each node of the hierarchy.
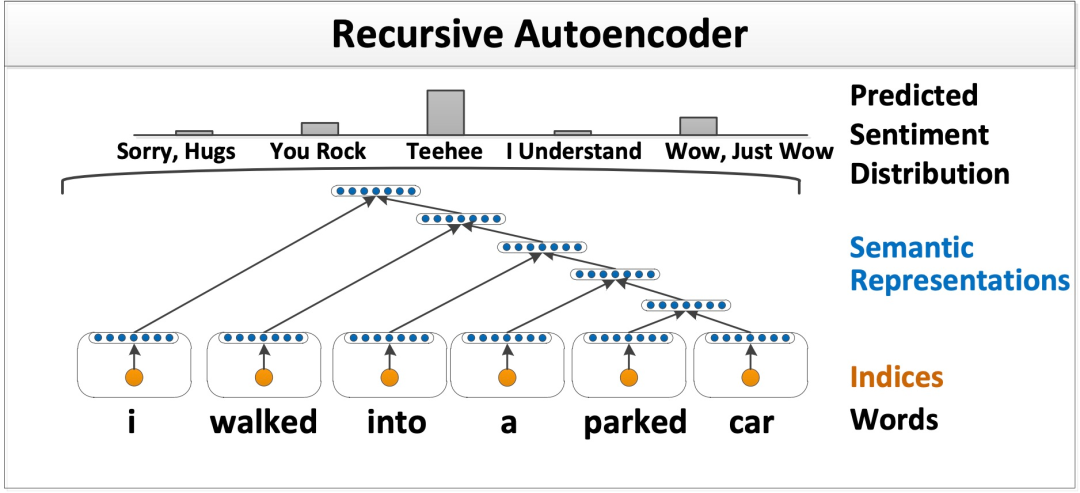
Figure 1. RAE architecture illustration, RAE learns semantic vector representations of phrases. Word indices (orange) are first mapped to semantic vector space (blue), and then recursively merged into a fixed-length sentence representation by the same autoencoder network. The vector of each node is used as a feature for predicting sentiment label distributions.
Semi-Supervised Recursive Autoencoders aim to find training mechanisms for variable-sized phrases in unsupervised & semi-supervised scenarios, which can be used in subsequent tasks. This article first introduces neural word representations, then proposes a recursive model based on autoencoders, and finally introduces the RAE model, explaining why RAE can learn joint representations of phrases, phrase structures, and sentiment distributions.
1) Neural Word Representations. Words are first represented as continuous vectors. There are two methods: the first method is to simply initialize each word vector by sampling from a Gaussian distribution; the second method is to pre-train word vectors using unsupervised methods, which can learn word representations in the vector space and capture grammatical and semantic information from their co-occurrence statistical features through gradient iteration.
2) Traditional Recursive Autoencoders. The role of traditional autoencoders is to learn representations of the input, usually for a predetermined tree structure, as shown in Figure 2:
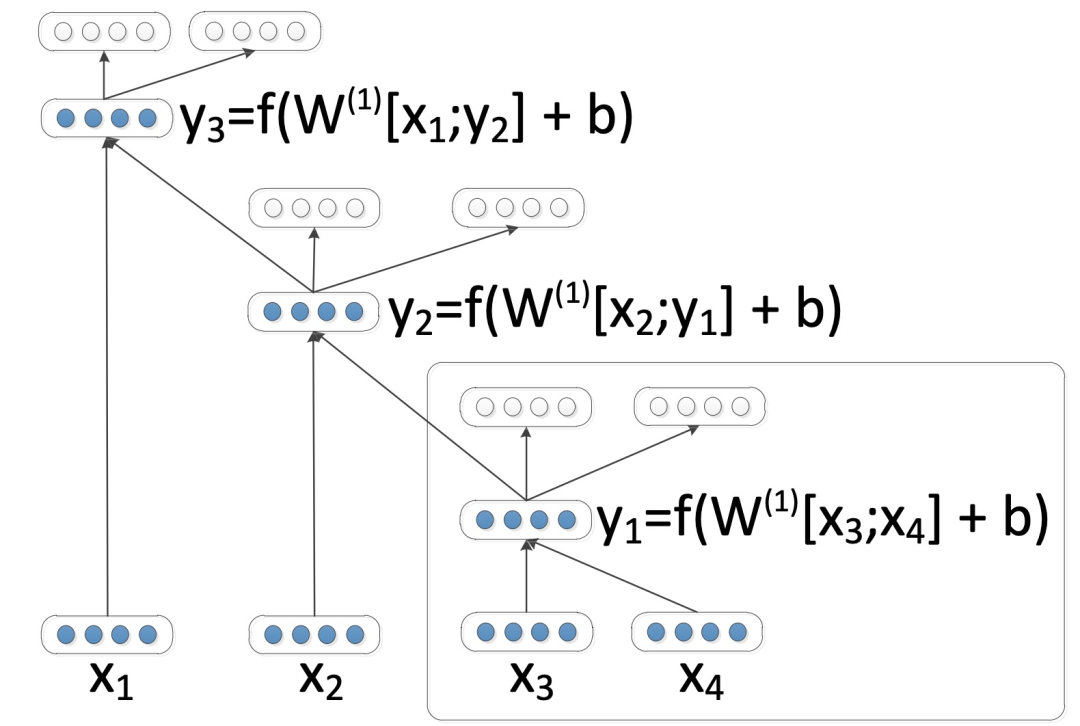
Figure 2. Explanation of Recursive Autoencoders applied on binary trees. Unfilled nodes are used only for calculating reconstruction errors. A standard autoencoder (inside the box) is reused at each node of the tree.
3) Unsupervised Recursive Autoencoders for Structure Prediction. Without a given input structure, the goal of RAE is to minimize the reconstruction error of pairs of sub-nodes in subtrees, and then reconstruct the tree structure through a greedy algorithm. Additionally, the authors introduced Weighted Reconstruction and Length Normalization to reduce reconstruction errors. 4) Semi-Supervised Recursive Autoencoders. The authors extended RAE for semi-supervised training to predict the current distribution at sentence & phrase levels. One of the advantages of RAE is that every node in the tree construction can be associated with distributed word vector representations, which can be used as feature representations of phrases. Figure 3 shows an illustration of a semi-supervised RAE unit.
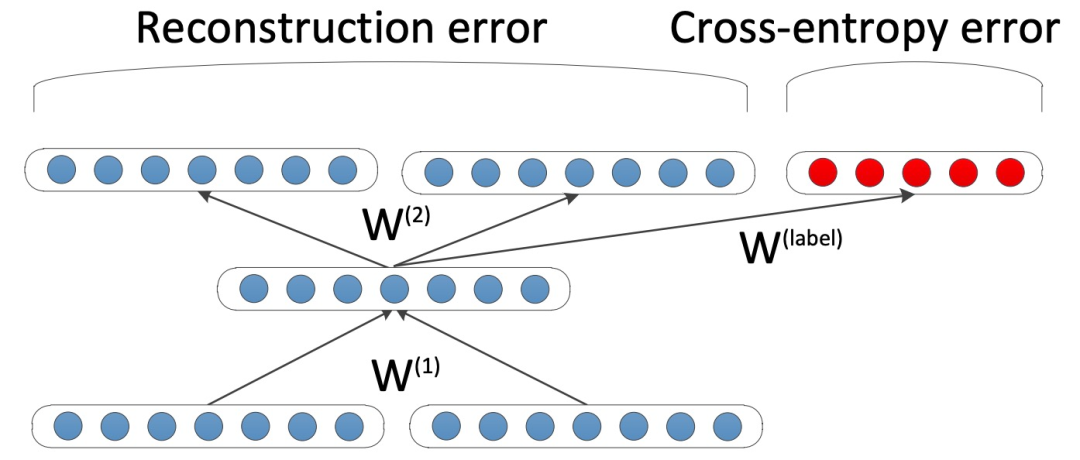
Figure 3. Illustration of a non-terminal tree node in the RAE unit. The red node shows the supervised softmax layer used for label distribution prediction.
The current SOTA! platform includes a total of 1 model implementation resource for RAE.
| Model | SOTA! Platform Model Detail Page |
|---|---|
| RAE | Visit SOTA! Model Platform to get implementation resources: https://sota.jiqizhixin.com/models/models/c4afbfa6-a47f-4f7c-85fa-8b7ba8382f65 |
2. MLP
Multi-Layer Perceptron (MLP), often colloquially known as the “vanilla” neural network, is a simple neural network structure used to automatically capture features. As shown in Figure 4, we present a three-layer MLP model. It includes an input layer, a hidden layer with activation functions for all nodes, and an output layer. Each node is connected by a certain weight 𝑤𝑖. It treats each input text as a bag of words, and compared to traditional models, MLP achieves better performance on many text classification benchmarks.
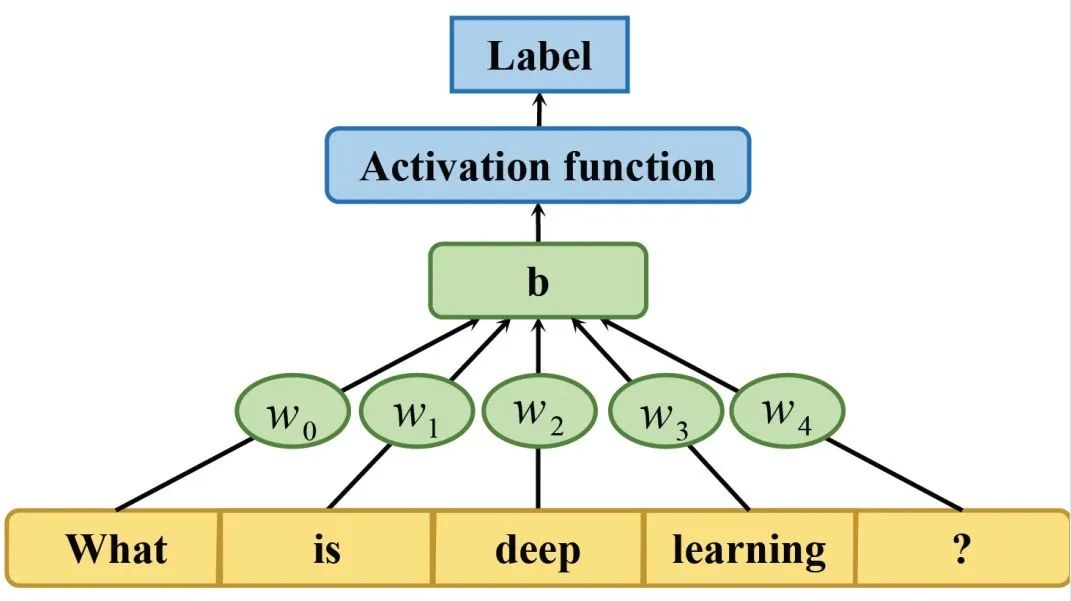
Figure 4. Three-layer MLP architecture
2.1 DAN
The paper “Deep Unordered Composition Rivals Syntactic Methods for Text Classification” proposed the NBOW (Neural Bag-of-Words) model and the DAN (Deep Averaging Networks) model. It compared the advantages and disadvantages of deep unordered composition methods and syntactic methods applied to text classification tasks, emphasizing the effectiveness, efficiency, and flexibility of deep unordered composition methods. The paper was published in ACL 2015. 1) Neural Bag-of-Words Models. The paper first proposed the simplest unordered model, the Neural Bag-of-Words Models (NBOW model). This model directly takes the average of all word vectors in the text as the representation of the text and then inputs it into the softmax layer. 2) Considering Syntax for Composition. It explores more complex syntactic functions to avoid many defects associated with the NBOW model. Specifically, these include Recursive Neural Networks (RecNNs); consideration of some complex linguistic phenomena such as negation, turn, etc. (advantages); performance depends on the syntactic tree of the input sequence (text) (may not be suitable for long texts and less standard texts); introduction of convolutional neural networks, etc. 3) The Deep Averaging Network (DAN) was proposed. This network adds non-linear layers on top of the traditional NBOW model, achieving performance comparable to or better than syntactic functions. 4) DropOut improves robustness (Word Dropout Improves Robustness). For the DAN model, the paper proposes a word dropout strategy: randomly invalidating certain words (tokens) in the text before averaging word vectors.
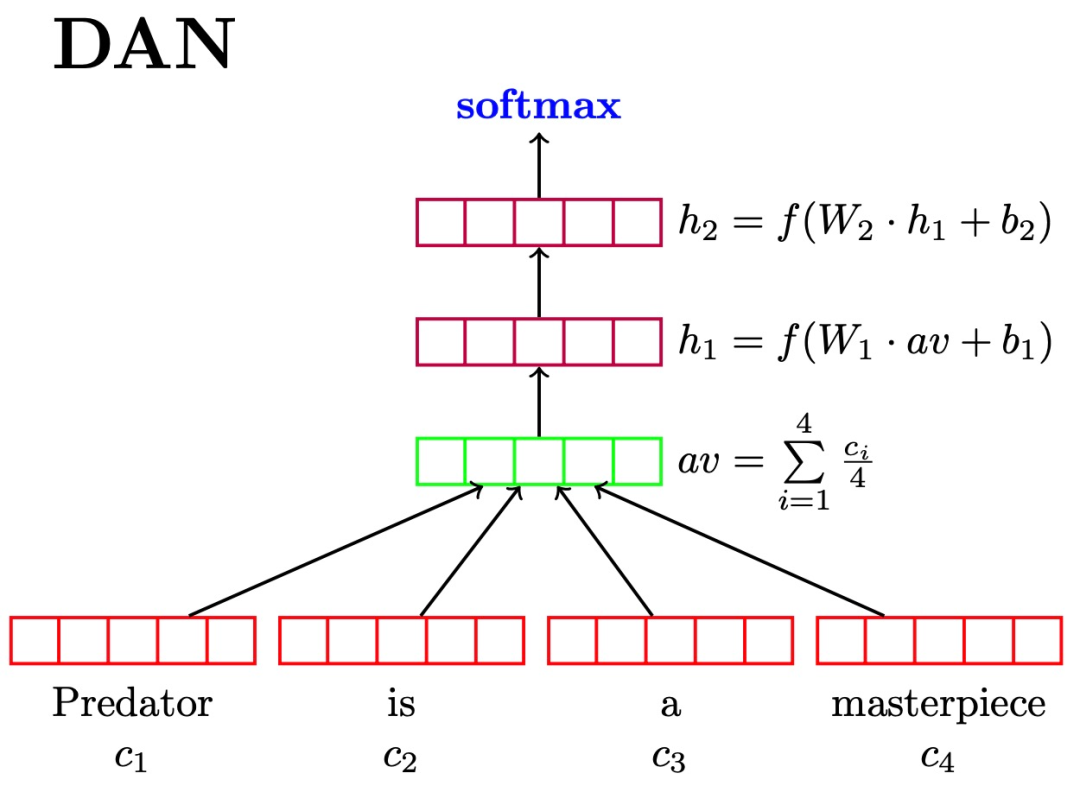
Figure 5. Two-layer DAN architecture
The current SOTA! platform includes a total of 1 model implementation resource for DAN.
| Model | SOTA! Platform Model Detail Page |
|---|---|
| DAN | Visit SOTA! Model Platform to get implementation resources: https://sota.jiqizhixin.com/models/models/b7189fbd-871f-4e13-b4fd-fc9747efde11 |
3. RNN
Recurrent Neural Networks (RNN) are widely used to capture long-distance dependencies through recursive calculations. RNN language models learn historical information, considering the positional information of all words suitable for text classification tasks. First, each input word is represented by a specific vector using word embedding techniques. Then, the embedded word vectors are fed into RNN units one by one. The output of the RNN unit has the same dimension as the input vector and is sent to the next hidden layer. RNN shares parameters across different parts of the model, with the same weight for each input word. Finally, the labels of the input text can be predicted from the output of the last hidden layer.
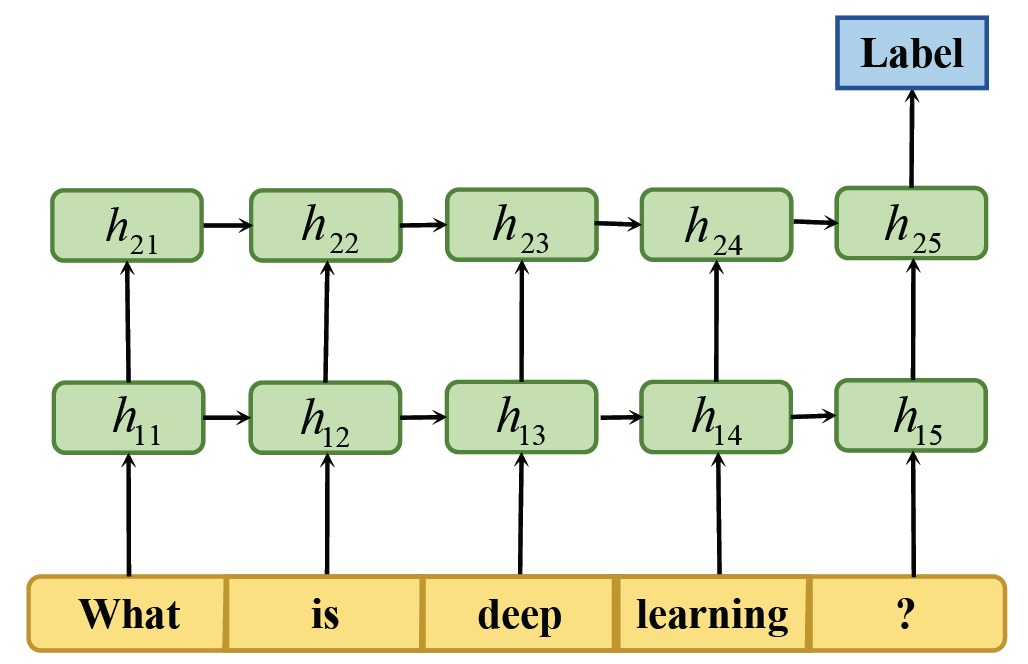
Figure 6. RNN architecture
3.1 TextRCNN
TextRCNN was first published in AAAI 2015. In the TextCNN network, the network structure adopts the form of “convolution layer + pooling layer,” where the convolution layer is used to extract n-gram type features. In RCNN (Recurrent Convolutional Neural Network), the feature extraction function of the convolution layer is replaced by RNN, which captures contextual information better and is advantageous for capturing the semantics of long texts. Therefore, the overall structure becomes RNN + pooling layer, hence the name RCNN. TextRCNN adds contextual information to word embeddings as new word representations. The left and right contexts are obtained from the outputs of the forward and backward RNN layers. These intermediate layer outputs are concatenated with the original word embeddings to form new word embeddings y, which are then sent into the pooling layer. The following figure shows the TextRCNN model framework, where the input is a text D, which can be seen as composed of a series of words (W_1, W_2, …). The output is a probability distribution, with the maximum position corresponding to the category K to which the article belongs.
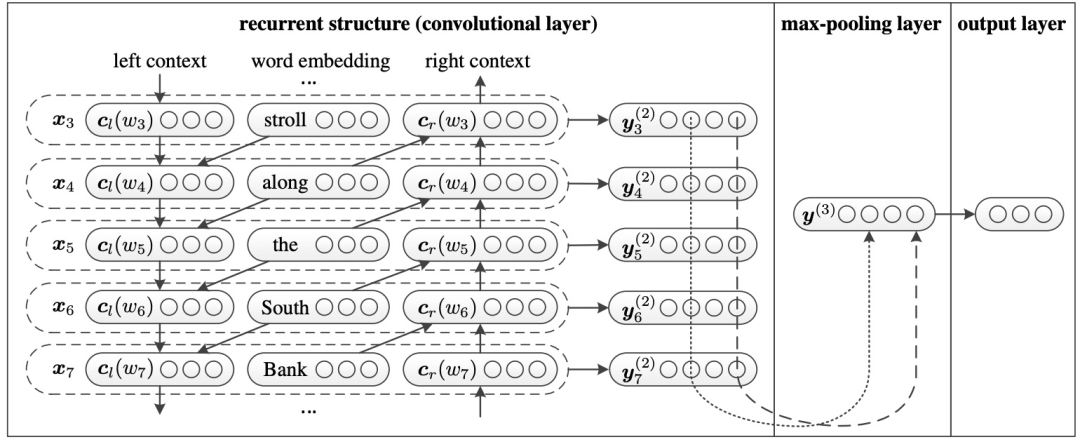
Figure 7. Structure of Recurrent Convolutional Neural Network. The figure is a partial example of the sentence “A sunset stroll along the South Bank affords an array of stunning vantage points,” where the subscript indicates the position of the corresponding word in the original sentence.
The overall model construction process of RCNN is as follows: 1) Use forward and backward RNN to obtain the forward and backward contextual representations of each word, changing the representation of words into a form that concatenates word vectors and forward and backward context vectors. 2) Non-linearly map the concatenated vector to a lower dimension. 3) Take the maximum value at each position in the vector across all time steps to obtain the final feature vector. 4) Use softmax classification to obtain the final scoring vector. Parameters are updated using stochastic gradient descent.
The current SOTA! platform includes a total of 1 model implementation resource for TextRCNN, supported framework: TensorFlow.
| Model | SOTA! Platform Model Detail Page |
|---|---|
| TextRCNN | Visit SOTA! Model Platform to get implementation resources: https://sota.jiqizhixin.com/models/models/a5a82cbe-98b7-4f3d-87ae-f9fd59caa55e |
3.2 Multi-task
The Multi-task article was published in IJCAI 2016. In this article, the authors use a multi-task learning framework to jointly learn multiple related tasks (as training data for multiple tasks can be shared) to address the problem of insufficient data. This article proposes three different information-sharing mechanisms based on recursive neural networks to model text for specific tasks and shared layers. The entire network is jointly trained on these tasks.
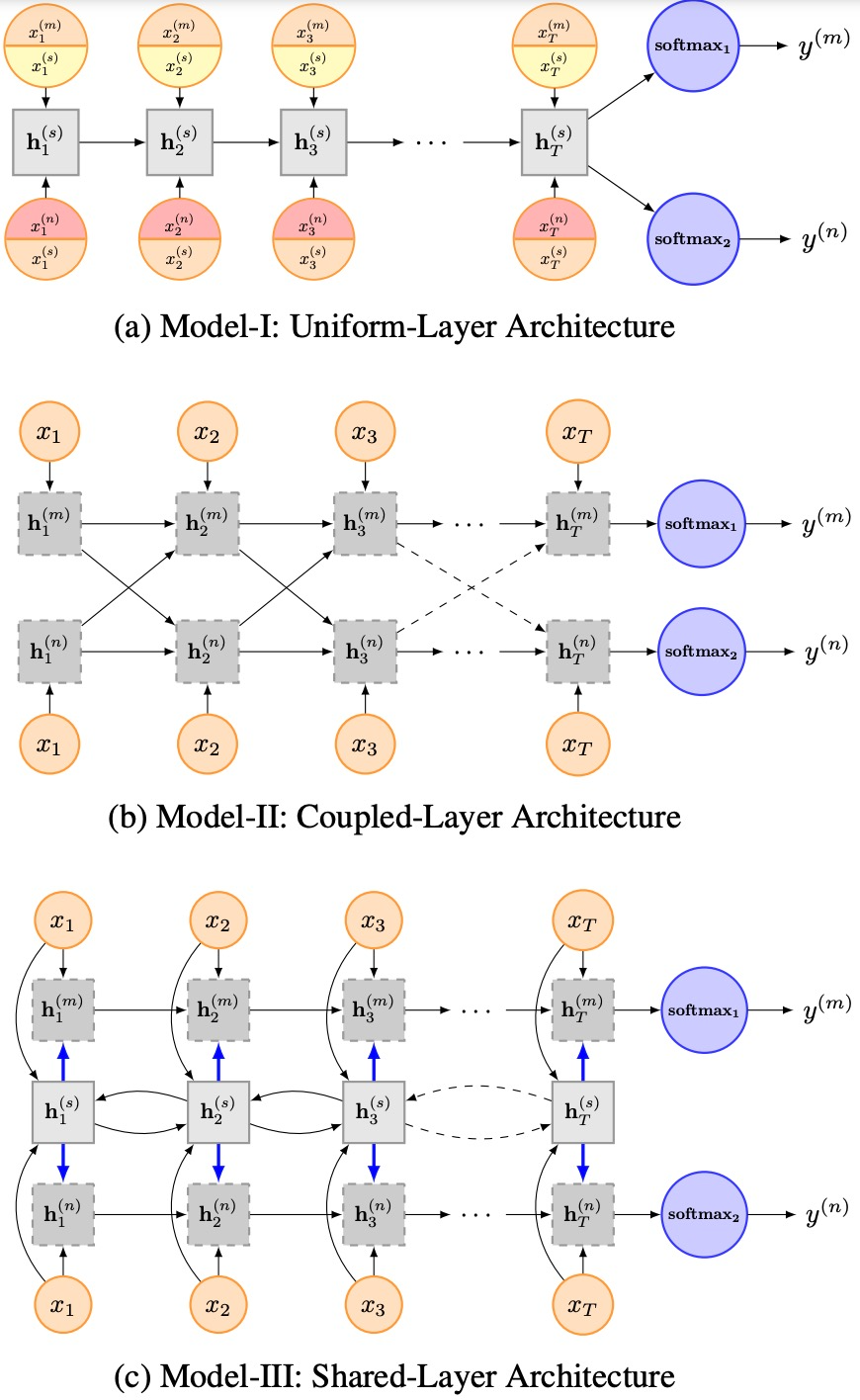
Figure 8. Three models of Multi-task
For Model I, each task shares an LSTM layer and an embedding layer, while each task has its own embedding layer. That is, for task m, the input x is defined in the following form:
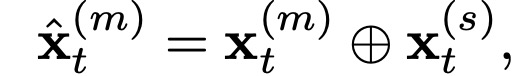
Where (x_t)^(m) and (x_t)^(s) represent specific task and shared word embeddings, respectively, and ⊕ denotes the concatenation operation. In Model II, each task has its own LSTM layer, but the input for the next time step includes the next character and all tasks’ hidden layer outputs at the current time step h. The authors modified the cell’s calculation formula to decide how much information to retain:
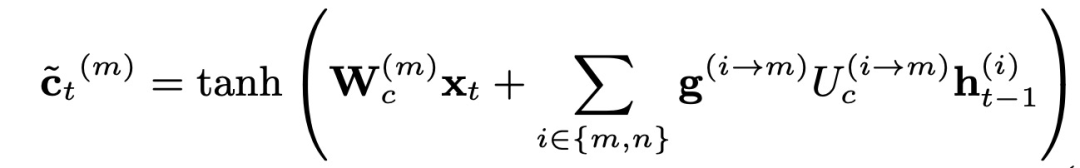
In Model III, each task has a shared BI-LSTM layer, while each has its own LSTM layer, where the LSTM input includes the character and the hidden layer output of the BI-LSTM at that moment. Similar to Model II, the authors also modified the cell’s calculation formula.
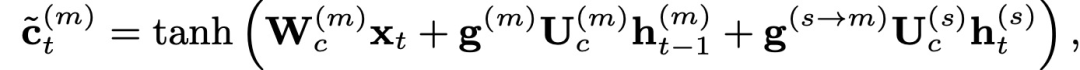
The current SOTA! platform includes a total of 1 model implementation resource for Multi-task, supported framework: PyTorch.
| Model | SOTA! Platform Model Detail Page |
|---|---|
| Multi-task | Visit SOTA! Model Platform to get implementation resources: https://sota.jiqizhixin.com/models/models/351b1aba-c543-437a-8cf8-9b027c5c42b7 |
3.3 DeepMoji
DeepMoji, published in EMNLP 2017, is a hybrid neural network that combines Bi-LSTM and Attention, achieving optimal results for emoji sentiment analysis and also performing well in text classification tasks. The structure of DeepMoji is shown in Figure 9, where the first layer is an embedding layer that allows each word to be embedded in the vector space, followed by a tanh activation function that compresses the embedding dimension to [-1, 1]; the second and third layers use a Bi-LSTM, each with 512 hidden units; the fourth layer is an attention layer, which concatenates the outputs from the previous three layers and inputs them into the attention; the fifth layer is a softmax layer. In summary, DeepMoji consists of an embedding layer followed by two Bi-LSTM layers, then concatenates the outputs of these three layers, feeds them into an attention layer, and finally connects to a softmax layer.

Figure 9. DeepMoji model, S is the text length, C is the number of categories
The current SOTA! platform includes a total of 8 model implementation resources for DeepMoji, supported frameworks: TensorFlow, PyTorch, Keras.
| Model | SOTA! Platform Model Detail Page |
|---|---|
| DeepMoji | Visit SOTA! Model Platform to get implementation resources: https://sota.jiqizhixin.com/models/models/9f50abc9-d67e-483a-bb44-e10c3baeb327 |
3.4 RNN-Capsule
RNN-Capsule is an application of capsule methods in text classification, with the related paper published in EMNLP 2018. Capsule Networks replace traditional single neuron nodes in neural networks with neuron vectors, training this new type of neural network using Dynamic Routing to enhance model efficiency and text expression capability. This model first uses standard convolutional networks to extract local semantic representations of sentences through multiple convolutional filters. It then replaces the scalar output of the CNN with vector output capsules, thus constructing the Primary Capsule layer. Next, it inputs into the authors’ proposed improved dynamic routing (dynamic routing with shared mechanisms and non-shared mechanisms) to obtain the convolutional capsule layer. Finally, the capsules of the convolutional capsule layer are flattened and sent to a fully connected capsule layer, where each capsule represents the probability of belonging to each category.
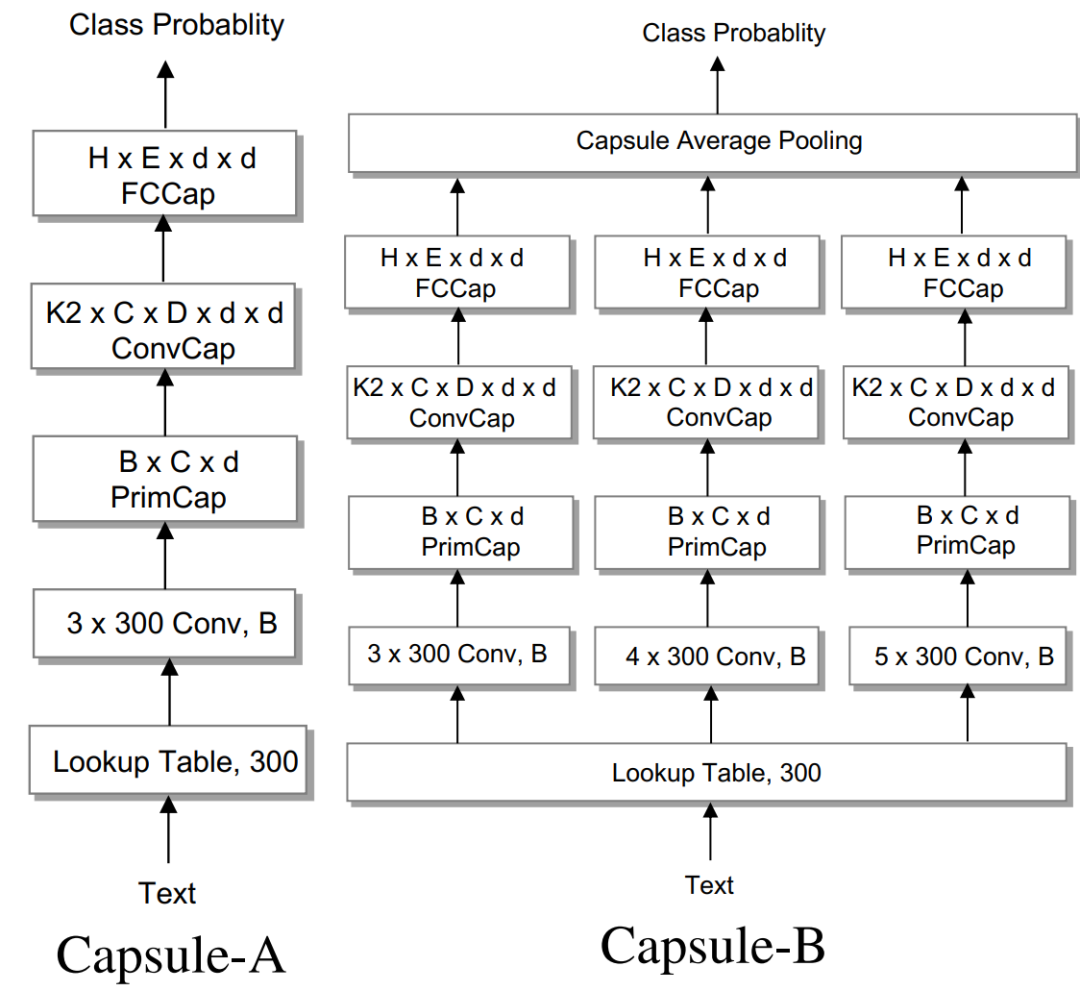 Figure 10. Structure of capsule networks for text classification. The dynamic routing process is shown at the bottom.
Figure 10. Structure of capsule networks for text classification. The dynamic routing process is shown at the bottom.
During the routing process, many capsules belong to background capsules, which are irrelevant to the final category capsule, such as stop words, category-irrelevant words, etc. The authors propose three strategies to reduce the impact of background or noisy capsules on the network:
-
Orphan Category: Introduce an Orphan category in the last layer of the capsule network, which can capture some background knowledge, such as stop words. In text tasks, stop words are quite consistent, such as predicates and pronouns, so the effect of introducing the Orphan category is quite good.
-
Leaky-Softmax: Introduce a denoising mechanism in the intermediate continuous convolution layers. Compared to the Orphan category, Leaky-Softmax is a lightweight denoising method that does not require additional parameters and computational load.
-
Routing Parameter Correction: Traditional routing parameters are usually initialized using uniform distributions, ignoring the probabilities of lower-layer capsules. Instead, the authors treat the probabilities of lower-layer capsules as a prior for routing parameters, improving the routing process.
To enhance text performance, the authors introduced two network structures, detailed as follows:
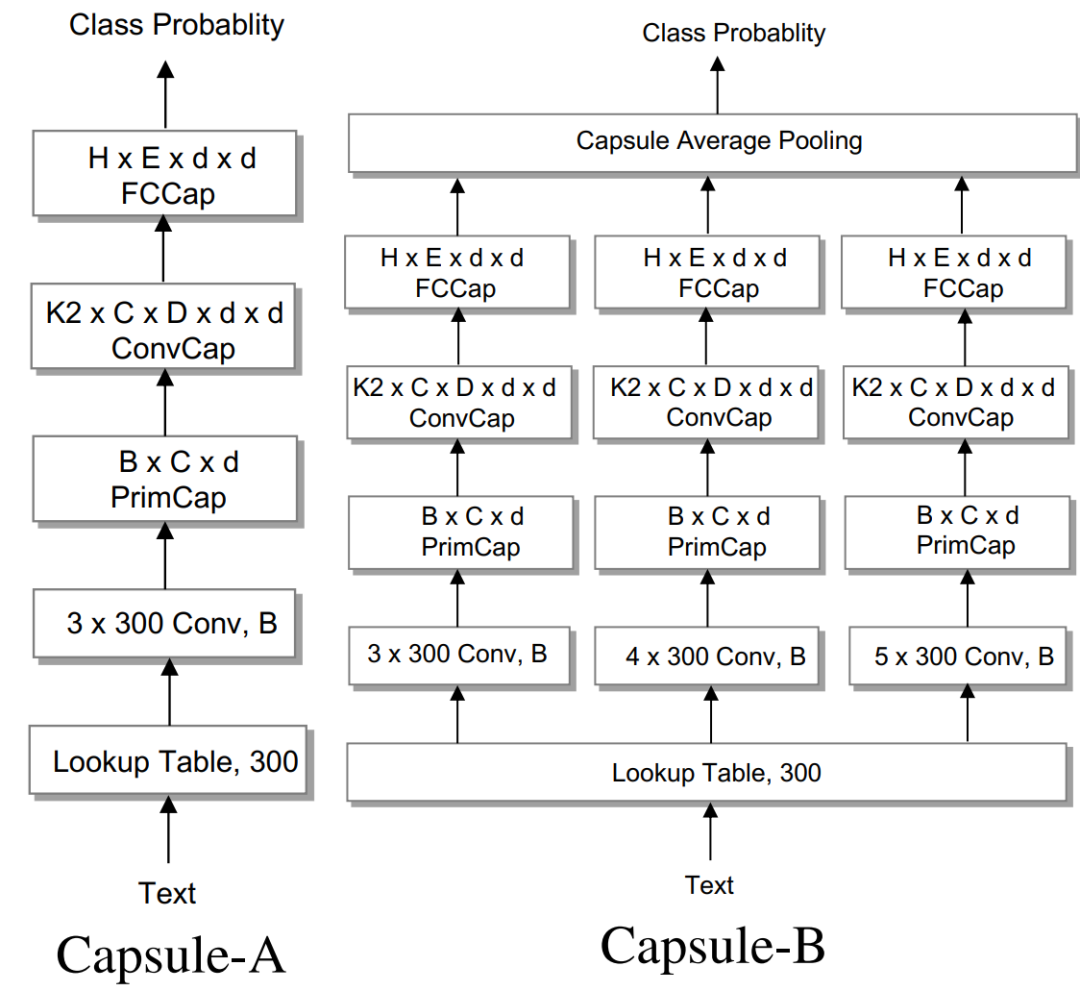
Figure 11. Two capsule network architectures
Capsule-A starts from the embedding layer, converting each word in the corpus into a 300-dimensional (V = 300) word vector, followed by a convolution layer with 32 filters (B = 32) and a ReLU nonlinearity with a stride of 1 and 3-grams (K1 = 3). All other layers are capsule layers, starting with a primary capsule layer with B×d capsules (where d is the dimension of capsules), followed by a 3×C×d×d (K2=3) convolution capsule layer and a fully connected capsule layer, proceeding in order. Each capsule has 16 dimensions (d=16) of instantiation parameters, the length (norm) can describe the probability of the existence of the capsule. The capsule layers are connected by transformation matrices, each connection also multiplied by routing coefficients, which are dynamically calculated through the routing protocol mechanism. Capsule-B has a basic structure similar to Capsule-A, except that it uses three parallel networks in the N-gram convolution layer, with filtering windows (N) of 3, 4, and 5 (see Figure 11). The final output of the fully connected capsule layer is sent to averaging pooling to produce the final result. In this way, Capsule-B can learn more meaningful and comprehensive text representations.
The current SOTA! platform includes a total of 1 model implementation resource for RNN-Capsule, supported framework: TensorFlow.
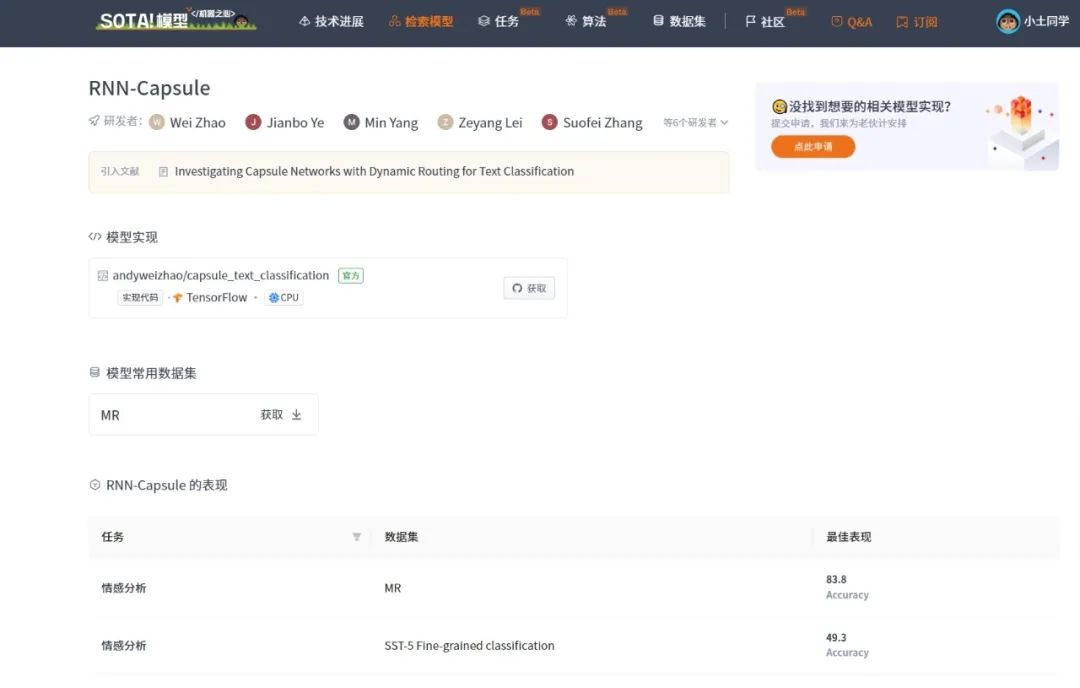
| Model | SOTA! Platform Model Detail Page |
|---|---|
| RNN-Capsule | Visit SOTA! Model Platform to get implementation resources: https://sota.jiqizhixin.com/models/models/f8cd1ed1-5ebe-42bf-8672-a1d2d9c1c97f |
Visit SOTA! Model Resource Station (sota.jiqizhixin.com) to obtain the model implementation code, pre-trained models, and API resources included in this article.
Access via Web: Enter the new site address sota.jiqizhixin.com in the browser address bar to go to the “SOTA! Model” platform and check if the models you are interested in have new resources included.
Access via Mobile: Search for the service account name “Machine Heart SOTA Model” or ID “sotaai” in the WeChat mobile client, follow the SOTA! model service account, and you can use platform functions through the bottom menu of the service account, with the latest AI technologies, development resources, and community dynamics regularly pushed.