
0x0. Background
Trying to run the DeepSeek V2 released on HuggingFace, I encountered several issues. Here are the solutions. The open-source DeepSeek V2 repo link provided by HuggingFace is: https://huggingface.co/deepseek-ai/DeepSeek-V2
0x1. Error 1: KeyError: ‘sdpa’
This issue has also been reported by the community. https://huggingface.co/deepseek-ai/DeepSeek-V2/discussions/3
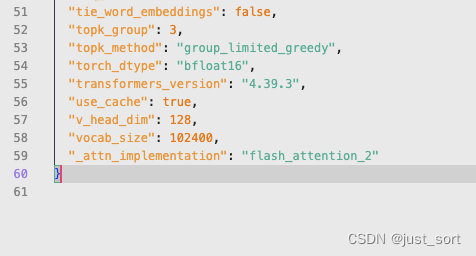
The solution is quite simple; just add the following line to the end of the config.json in the project: "_attn_implementation": "flash_attention_2":
0x2. Error 2: Initialization Phase Hangs
I have submitted a PR to accelerate to solve this issue. https://github.com/huggingface/accelerate/pull/2756
Background
When I tried to perform inference with the deepseek-v2 model using the transformers library:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# `max_memory` should be set based on your devices
max_memory = {i: "75GB" for i in range(8)}
# `device_map` cannot be set to `auto`
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
I found that the program got stuck…
Solution
According to the stack information, it got stuck here (https://github.com/huggingface/accelerate/blob/main/src/accelerate/utils/modeling.py#L1041).

For DeepSeek V2, the length of module_sizes is 68185, and the code complexity here is O(N^2) (where N = module_sizes), which takes a very long time to execute, giving the illusion of being stuck. This PR optimized the code, reducing its complexity to O(N), allowing it to quickly reach the stage of loading large models. On a single node with 8xA800, after this optimization, the inference results were also normal.
0x3. Single Node A800 Inference Requires Limiting Output Length
Due to the model’s parameter count of 236B, using bf16 to store it, each A800 card on a single node has already occupied about 60G. If the output length is too long, the KV Cache cannot handle it during direct inference with HuggingFace. If you want to run it on a single node and do some debugging, set the input prompt shorter, and max_new_tokens can be set to 64. It has been tested to run normally. The script I used is:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "/mnt/data/zhaoliang/models/DeepSeek-V2/"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# `max_memory` should be set based on your devices
max_memory = {i: "75GB" for i in range(8)}
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="auto", torch_dtype=torch.bfloat16, max_memory=max_memory)
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)

0x4. VLLM
If you want to speed up inference on a single node with 8xA100/A800 and output longer text, you can currently use the VLLM implementation, see this PR: https://github.com/vllm-project/vllm/pull/4650
The open source of deepseek-v2, technical report, and model architecture innovation are all great, respect. But personally, I feel that when uploading the open-source code, it would be good to do some testing as well.