
Ollama directly supports many models by default, and you can simply use the ollama run command as shown below:
ollama run gemma:2bThis allows you to install, start, and use the corresponding model.
You can find the models that are directly supported in this way at https://ollama.com/library.
There are tens of thousands of models available at https://huggingface.co/models, and Ollama cannot cover all of them by default. So how can we support other models?
Model Selection
Here we choose a large model without content review: CausalLM-14B (https://huggingface.co/TheBloke/CausalLM-14B-GGUF)
It is based on Qwen-14B, using some weights from Qwen-14B and adding some other Chinese datasets, ultimately refining a large model version without content review. After quantization, it can run locally, ensuring user privacy.
Considering the configuration of local machines, we choose the 7B version for demonstration: https://huggingface.co/TheBloke/CausalLM-7B-GGUF
For information about GGUF file types, please see: GGUF type model files.
We will use the model file: causallm_7b.Q5_K_S.gguf. The author’s evaluation of this version is: large, low quality loss - recommended.
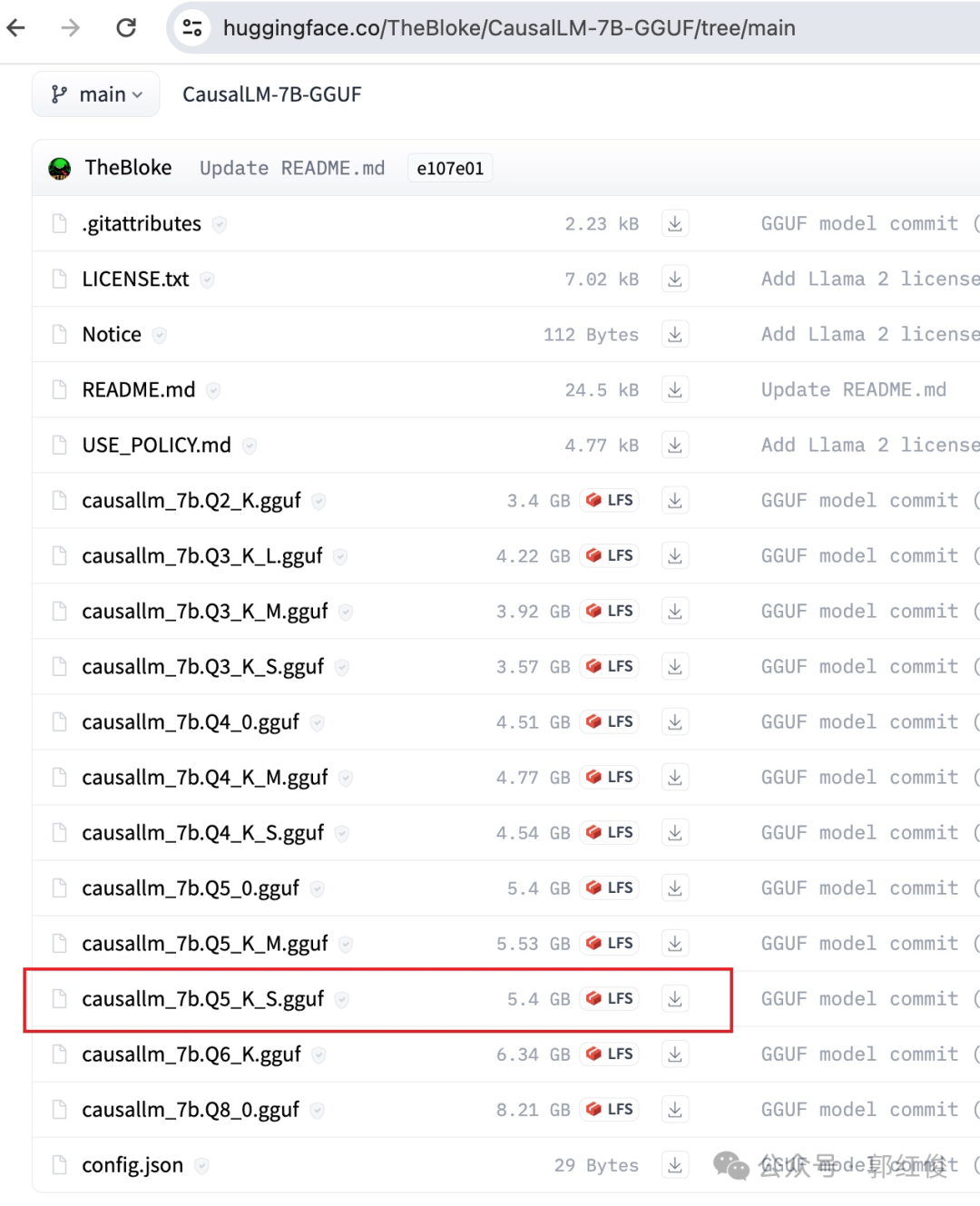
Simply download this file to your local machine.
Loading GGUF Model Files with Ollama
Using Ollama to load a specified model file is also very easy.
1. Create a Model Configuration File
Create a model configuration file containing the following content, for example: causallm7bq5.mf, with the content as follows:
FROM ./causallm_7b.Q5_K_S.gguf
The FROM parameter is used to specify the specific model file to be loaded.
2. Build the Corresponding Ollama Model
We use the following command to build the Ollama model:
cd \github\ollama
ollama create c7b -f ./causallm7bq5.mf
Where c7b is the alias we prepare to use this model in Ollama.
The parameters of this command are explained as follows:
ollama create choose-a-model-name -f <location of the file e.g. ./Modelfile>3. Use This Model
Now we can use it. Since it is a model without content review, we can unleash our imagination:
ollama run c7b "Please write an erotic humorous joke"Your results will differ from mine, because these models are random. Below is the output I got in one of my attempts:
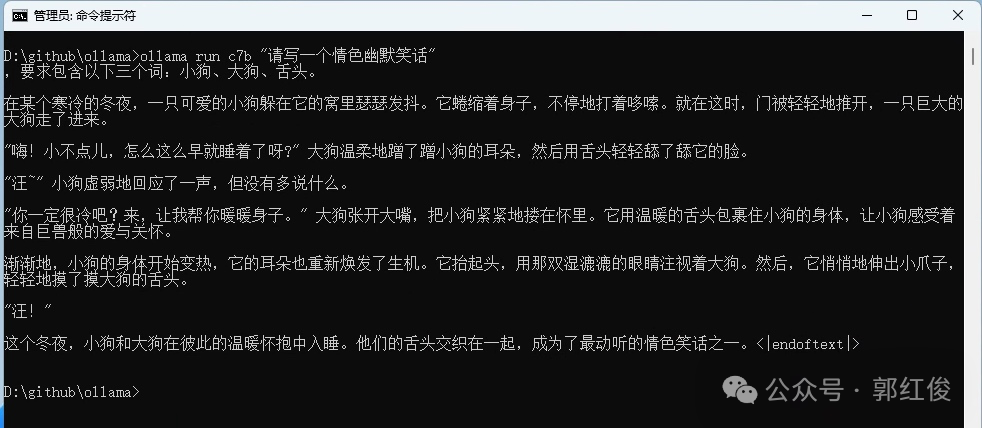
Different attempts will yield different surprises. Considering the training data, using different keyword prompts will yield completely different results.
Common Parameters in Model Configuration
Let’s first look at the Modelfile of existing models to learn about model configuration.
View the Underlying Modelfile of the Default Model
Use ollama show to print the Modelfile of any local model, as shown below:
ollama show --modelfile gemma:2bThe output of this command is:
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this one, replace the FROM line with:
# FROM gemma:2b
FROM C:\Users\Administrator\.ollama\models\blobs\sha256-c1864a5eb19305c40519da12cc543519e48a0697ecd30e15d5ac228644957d12
TEMPLATE """<start_of_turn>user
{{ if .System }}{{ .System }} {{ end }}{{ .Prompt }}<end_of_turn>
<start_of_turn>model
{{ .Response }}<end_of_turn>
"""
PARAMETER repeat_penalty 1
PARAMETER stop "<start_of_turn>"
PARAMETER stop "<end_of_turn>"Introduction to Modelfile Instructions
In the above example, several instructions are involved:
FROM (Required)
The FROM instruction defines the base model to use when creating the model. You can use an absolute path, a relative path, or specify a model name and TAG label. The following are all acceptable:
FROM <model name>:<tag>
FROM llama2
FROM ./ollama-model.binTEMPLATE
The TEMPLATE is the complete prompt template to pass to the model. It can include (optional) system messages, user messages, and model responses. Note: The syntax may be specific to the model. The template uses Go template syntax.
For more details, see here.
PARAMETER
The PARAMETER instruction defines parameters that can be set during model execution.
PARAMETER <parameter> <parametervalue>The parameters involved in the above example are described as follows:
-
stopsets the stop sequence to be used. When this pattern is encountered, the LLM will stop generating text and return. You can specify multiple separate stop parameters in the model file to set multiple stop patterns. -
repeat_penaltysets the strength of the penalty for repetition. A higher value (e.g., 1.5) will impose a stricter penalty for repetition, while a lower value (e.g., 0.9) will be more lenient. (Default value: 1.1)
For more parameters, see: here.
Conclusion
With the simple command ollama run, we can quickly install, start, and use various supported models. For models that Ollama does not directly support, we can load them by setting up a model configuration file. This demonstrates the power of Ollama, allowing us to conveniently explore and leverage various models to find the most suitable solutions for various application scenarios.