Source: Machine Heart
This article is approximately 3200 words long and is recommended for a 5-minute read.
This article introduces a brand new large language model (LLM) architecture that is expected to replace the Transformer, which has been dominant in the AI field until now.
From 125M to 1.3B large models, performance has improved.
Incredible, this is finally happening.
A brand new large language model (LLM) architecture is expected to replace the Transformer, which has been dominant in the AI field until now, and it performs better than Mamba. This Monday, a paper on Test-Time Training (TTT) became a hot topic in the AI community.
Paper link: https://arxiv.org/abs/2407.04620
The authors of this study come from Stanford University, the University of California, Berkeley, the University of California, San Diego, and Meta. They designed a new architecture called TTT, replacing the hidden states of RNN with machine learning models. This model compresses context through the actual gradient descent of input tokens.
One of the authors, Karan Dalal, stated that he believes this will fundamentally change the approach to language models.
In the machine learning model, the TTT layer directly replaces Attention and unlocks linear complexity architecture through expressive memory, allowing us to train LLMs with millions (sometimes billions) of tokens in context.
The authors conducted a series of comparisons on large models ranging from 125M to 1.3B parameters and found that both TTT-Linear and TTT-MLP can match or outperform the most powerful Transformers and Mamba architecture methods.
The TTT layer serves as a new information compression and model memory mechanism, which can simply replace the self-attention layer in Transformers.
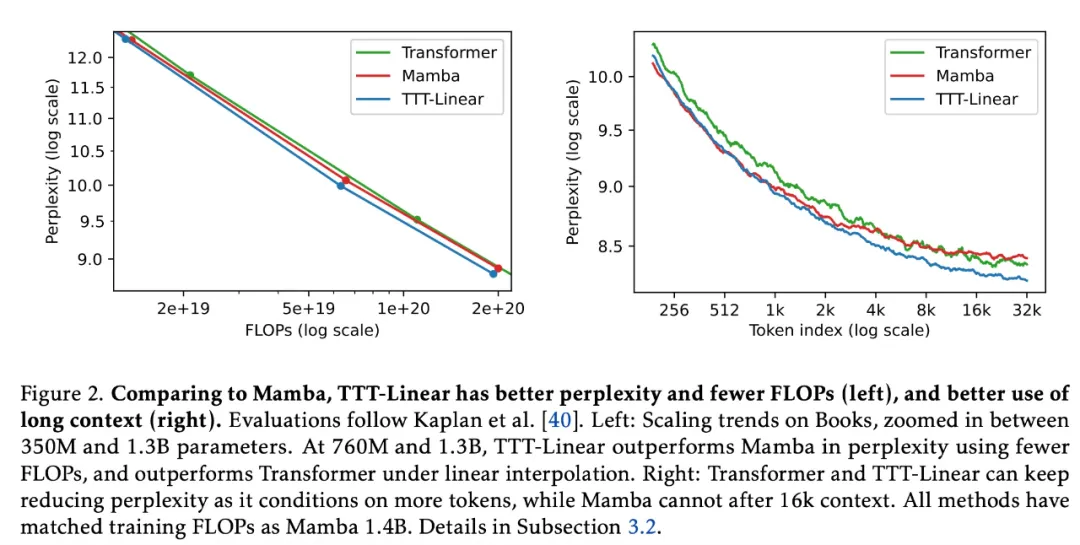
Compared to Mamba, TTT-Linear has lower perplexity, fewer FLOPs (left), and better utilization of long context (right):
This is not only theoretically linear complexity, but also faster in actual running time.
-
After the paper went online, the authors made the code available with JAX for people to train and test:
https://github.com/test-time-training/ttt-lm-jax
-
There is also PyTorch inference code:
https://github.com/test-time-training/ttt-lm-pytorch
The challenge of long context is inherent in RNN layers: unlike self-attention mechanisms, RNN layers must compress context into a fixed-size hidden state, and the update rule needs to discover the underlying structure and relationships among thousands or even millions of tokens.
The research team first observed that self-supervised learning can compress a large training set into the weights of models like LLM, which often exhibit a profound understanding of the semantic connections between their training data.
Inspired by this observation, the research team designed a new class of sequence modeling layers where the hidden state is a model, and the update rule is a step of self-supervised learning. Since the process of updating the hidden state on the test sequence is equivalent to training the model at test time, the research team named this new layer Test-Time Training (TTT) layer.
The research team introduced two simple instances: TTT-Linear and TTT-MLP, where the hidden states are linear models and two-layer MLPs, respectively. The TTT layer can be integrated into any network architecture and optimized end-to-end, similar to RNN layers and self-attention.
To make the TTT layer more efficient, the study took several tricks to improve the TTT layer:
First, similar to taking gradient steps on small batches of sequences during regular training for better parallelism, the study used small batches of tokens during TTT.
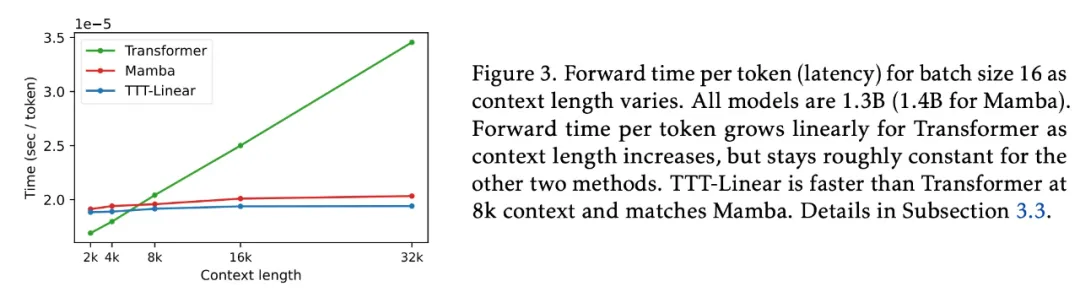
Second, the study developed a dual form for operations within each TTT mini-batch to better leverage modern GPUs and TPUs. The output of the dual form is equivalent to a simple implementation but is over 5 times faster in training speed. As shown in Figure 3, TTT-Linear is faster than Transformer at 8k context and comparable to Mamba.
The research team believes that all sequence modeling layers can be viewed as storing historical context into hidden states, as shown in Figure 4.
For example, RNN layers (such as LSTM, RWKV, and Mamba layers) compress context into a fixed-size state across time. This compression has two consequences: on one hand, mapping the input token x_t to the output token z_t is efficient because each token’s update rule and output rule require constant time. On the other hand, the performance of RNN layers in long contexts is limited by the expressiveness of their hidden states s_t.
Self-attention can also be viewed from the above perspective, except that its hidden state (commonly referred to as Key-Value cache) is a list that grows linearly with t. Its update rule simply appends the current KV tuple to that list, while the output rule scans all tuples before t to form the attention matrix. The hidden state explicitly stores all historical context without compression, making self-attention more expressive in long contexts compared to RNN layers. However, the time required to scan this linearly growing hidden state also grows linearly.To maintain high efficiency and expressiveness in long contexts, researchers need a better compression heuristic. Specifically, they need to compress thousands or possibly millions of tokens into a single hidden state to effectively capture their underlying structures and relationships. This may sound challenging, but many people are quite familiar with this heuristic.
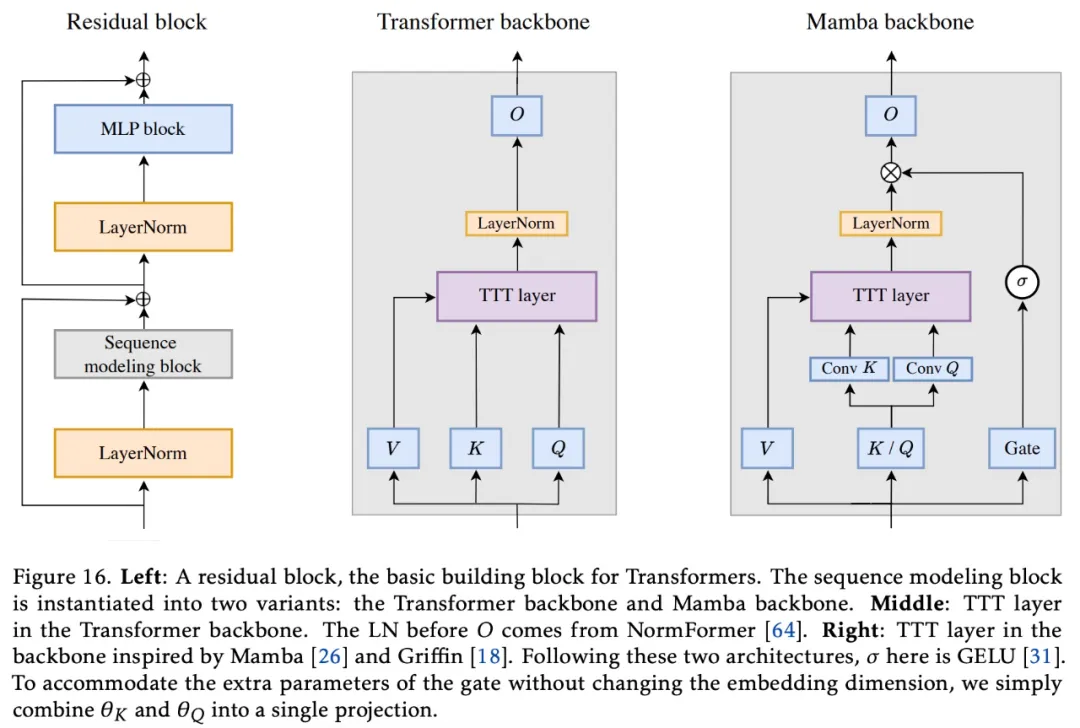
The backbone architecture. The simplest way to integrate any RNN layer into a larger architecture is to directly replace the self-attention in Transformer, referred to here as the backbone. However, existing RNNs (such as Mamba and Griffin) use different backbone layers than Transformers. Notably, their backbone layers include temporal convolutions before the RNN layers, which may help collect local information across time. After experimenting with the Mamba backbone, researchers found that it also improves the perplexity of the TTT layer, thus incorporating it into the proposed method, as detailed in Figure 16.
In the experiments, the researchers compared TTT-Linear and TTT-MLP with the two baselines, Transformer and Mamba.
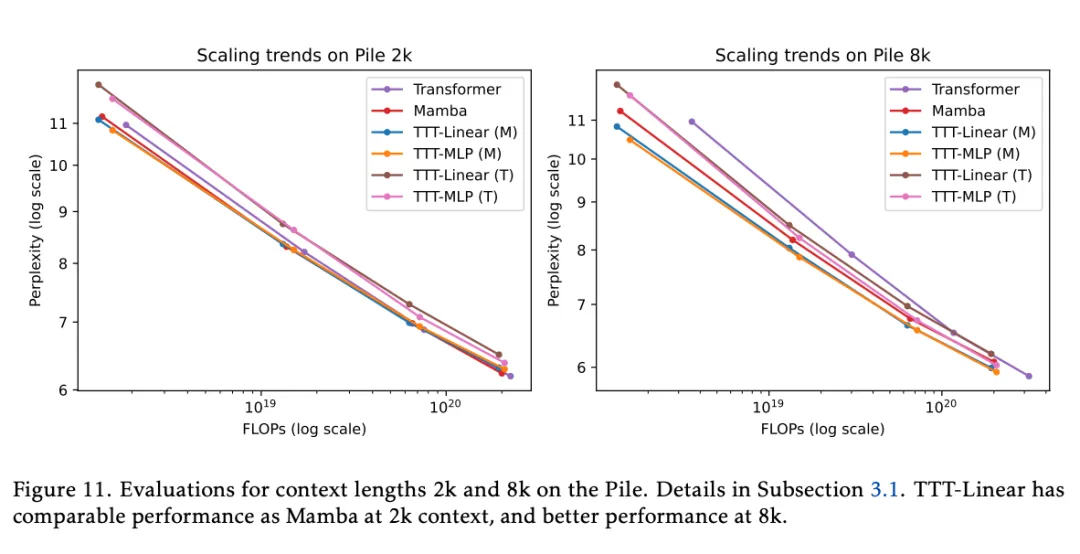
The following conclusions can be drawn from Figure 11:
-
At 2k context, the performance of TTT-Linear (M), Mamba, and Transformer is comparable as the lines mostly overlap. In cases with a larger FLOP budget, TTT-MLP (M) performs slightly worse. Although TTT-MLP has better perplexity than TTT-Linear at various model sizes, the additional FLOPs cost offsets this advantage.
-
At 8k context, both TTT-Linear (M) and TTT-MLP (M) outperform Mamba, which is a stark contrast to observations at 2k context. Even TTT-MLP (T) using the Transformer backbone is slightly better than Mamba at around 1.3B. A significant observation is that as the context length increases, the advantage of the TTT layer over the Mamba layer also expands.
-
At a context length of 8k, the Transformer still performs well in perplexity at every model size, but is no longer competitive due to the cost of FLOPs.
 The above results demonstrate the impact of switching the TTT layer from the Mamba backbone to the Transformer backbone. The researchers hypothesize that when the expressiveness of the hidden state in the sequence modeling layer is lower, the temporal convolution in the Mamba backbone is more helpful. Linear models are less expressive than MLPs, thus benefiting more from the convolution.
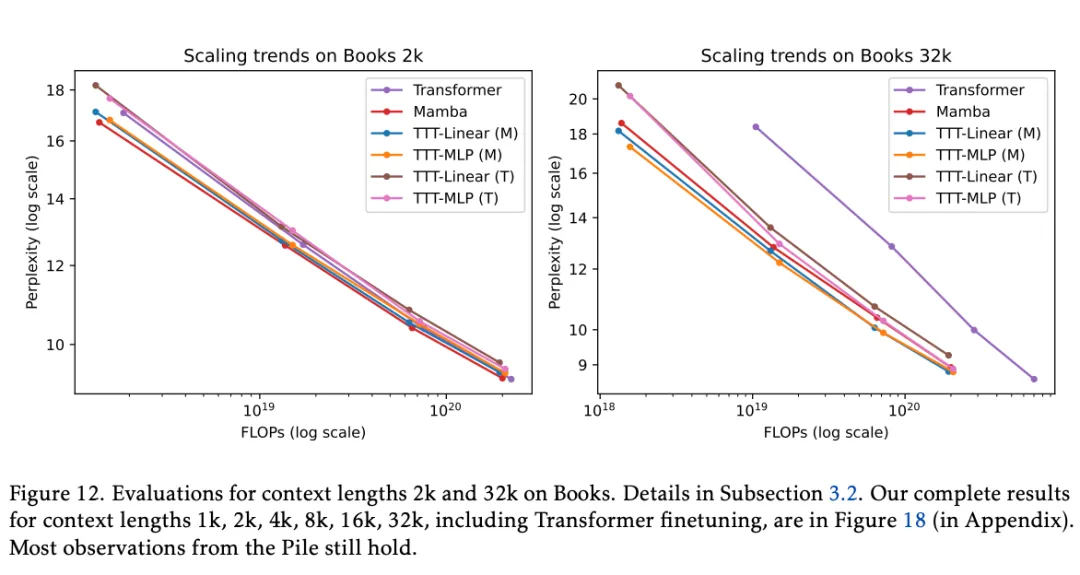
To evaluate long context capabilities, the researchers used a popular subset of Pile, Books3, and conducted experiments on context lengths from 1k to 32k with a doubling increment. The training methods here are the same as those for Pile, and all experiments with the TTT layer were completed in a single training run. From the subset of results in Figure 12, they made the following observations:
In the 2k context of Books, all observations from Pile 2k still hold, except that Mamba now performs slightly better than TTT-Linear (and their lines roughly overlap in Pile 2k).
In the 32k context, both TTT-Linear (M) and TTT-MLP (M) outperform Mamba, similar to the observations at Pile 8k. Even TTT-MLP (T) using the Transformer backbone performs slightly better than Mamba in 32k context.
TTT-MLP (T) is only slightly inferior to TTT-MLP (M) at the 1.3B scale. As mentioned above, due to the lack of clear linear fitting, it is difficult to derive empirical scaling laws. However, the strong trend of TTT-MLP (T) suggests that the Transformer backbone may be better suited for larger models and longer contexts beyond our evaluation range.
The training and inference of LLM can be decomposed into forward, backward, and generation. The handling of prompts during inference (also known as pre-filling) is the same as the forward operation during training, except that backward operations do not need to store intermediate activation values.
Since both forward (during training and inference) and backward can be processed in parallel, a dual form is used here. Generating new tokens (also known as decoding) is inherently sequential, so the original form is used here.
The researchers mentioned that due to resource limitations, the experiments in this paper were written in JAX and run on TPU. On a v5e-256 TPU pod, the Transformer baseline requires 0.30 seconds per iteration of training with a context of 2k, while TTT-Linear requires 0.27 seconds per iteration, which is 10% faster without any system optimizations. Given that Mamba (implemented in PyTorch, Triton, and CUDA) can only run on GPU, the researchers optimized this method preliminarily to run on GPU for a fair comparison.
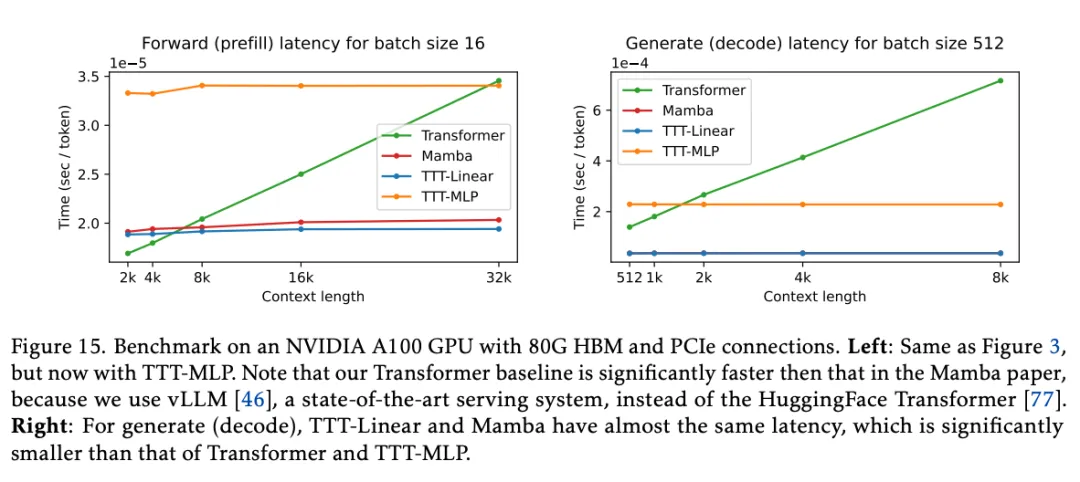
Figure 15 on the left shows the latency of the forward kernels of each model with a batch size of 16. All models are 1.3B (Mamba is 1.4B). Notably, the Transformer baseline here is much faster than that in the Mamba paper because vLLM was used here instead of HuggingFace Transformer.
Additionally, the researchers wrote another GPU kernel for generation and benchmarked its speed on the right side of Figure 15 with a batch size of 512. Another commonly used wall-clock time metric is throughput, which considers the potential benefits of using larger batch sizes. For throughput, the ordering of all observations and methods remains valid.
After the submission of the TTT study, one of the paper’s authors, UCSD Assistant Professor Xiaolong Wang, tweeted his congratulations. He stated that the TTT research lasted for a year and a half, but the idea of test-time training (TTT) has actually been around for five years since its inception. Although the initial idea and the current results are entirely different.
The three main authors of the TTT paper come from Stanford, UC Berkeley, and UCSD.
Among them, Yu Sun is a postdoctoral fellow at Stanford University, who graduated from UC Berkeley EECS, and has long been researching TTT.
Xinhao Li is a doctoral student at UCSD, who graduated from the University of Electronic Science and Technology of China.
Karan Dalal is a doctoral student at UC Berkeley, who co-founded a telemedicine startup called Otto during high school.
All three of them have written test-time training as the first line of their research directions on their personal websites.
The above results demonstrate the impact of switching the TTT layer from the Mamba backbone to the Transformer backbone. The researchers hypothesize that when the expressiveness of the hidden state in the sequence modeling layer is lower, the temporal convolution in the Mamba backbone is more helpful. Linear models are less expressive than MLPs, thus benefiting more from the convolution.
To evaluate long context capabilities, the researchers used a popular subset of Pile, Books3, and conducted experiments on context lengths from 1k to 32k with a doubling increment. The training methods here are the same as those for Pile, and all experiments with the TTT layer were completed in a single training run. From the subset of results in Figure 12, they made the following observations:
In the 2k context of Books, all observations from Pile 2k still hold, except that Mamba now performs slightly better than TTT-Linear (and their lines roughly overlap in Pile 2k).
In the 32k context, both TTT-Linear (M) and TTT-MLP (M) outperform Mamba, similar to the observations at Pile 8k. Even TTT-MLP (T) using the Transformer backbone performs slightly better than Mamba in 32k context.
TTT-MLP (T) is only slightly inferior to TTT-MLP (M) at the 1.3B scale. As mentioned above, due to the lack of clear linear fitting, it is difficult to derive empirical scaling laws. However, the strong trend of TTT-MLP (T) suggests that the Transformer backbone may be better suited for larger models and longer contexts beyond our evaluation range.
The training and inference of LLM can be decomposed into forward, backward, and generation. The handling of prompts during inference (also known as pre-filling) is the same as the forward operation during training, except that backward operations do not need to store intermediate activation values.
Since both forward (during training and inference) and backward can be processed in parallel, a dual form is used here. Generating new tokens (also known as decoding) is inherently sequential, so the original form is used here.
The researchers mentioned that due to resource limitations, the experiments in this paper were written in JAX and run on TPU. On a v5e-256 TPU pod, the Transformer baseline requires 0.30 seconds per iteration of training with a context of 2k, while TTT-Linear requires 0.27 seconds per iteration, which is 10% faster without any system optimizations. Given that Mamba (implemented in PyTorch, Triton, and CUDA) can only run on GPU, the researchers optimized this method preliminarily to run on GPU for a fair comparison.
Figure 15 on the left shows the latency of the forward kernels of each model with a batch size of 16. All models are 1.3B (Mamba is 1.4B). Notably, the Transformer baseline here is much faster than that in the Mamba paper because vLLM was used here instead of HuggingFace Transformer.
Additionally, the researchers wrote another GPU kernel for generation and benchmarked its speed on the right side of Figure 15 with a batch size of 512. Another commonly used wall-clock time metric is throughput, which considers the potential benefits of using larger batch sizes. For throughput, the ordering of all observations and methods remains valid.
After the submission of the TTT study, one of the paper’s authors, UCSD Assistant Professor Xiaolong Wang, tweeted his congratulations. He stated that the TTT research lasted for a year and a half, but the idea of test-time training (TTT) has actually been around for five years since its inception. Although the initial idea and the current results are entirely different.
The three main authors of the TTT paper come from Stanford, UC Berkeley, and UCSD.
Among them, Yu Sun is a postdoctoral fellow at Stanford University, who graduated from UC Berkeley EECS, and has long been researching TTT.
Xinhao Li is a doctoral student at UCSD, who graduated from the University of Electronic Science and Technology of China.
Karan Dalal is a doctoral student at UC Berkeley, who co-founded a telemedicine startup called Otto during high school.
All three of them have written test-time training as the first line of their research directions on their personal websites.
Data Pie THU, as a public account on data science, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a data talent aggregation platform, creating the strongest group of big data in China.

Sina Weibo: @Data Pie THU
WeChat Video Account: Data Pie THU
Today’s Headlines: Data Pie THU