

New Intelligence Report
New Intelligence Report
[New Intelligence Introduction] Inspired by the human visual system, MVDiffusion++ combines computational fidelity with the flexibility of human vision, generating dense, high-resolution images with pose from any number of unposed images, achieving high-quality 3D model reconstruction.
The human visual system exhibits remarkable flexibility.

For example, in the left image above, although the human brain cannot create millimeter-precise 3D models, the human visual system can combine information from a few images to form a coherent 3D representation in the mind, including the complex facial features of a tiger or the arrangement of blocks forming a toy train, even for completely occluded parts.
3D reconstruction technology has evolved fundamentally over the past fifteen years.
Unlike the human ability to infer 3D shapes from a few images, this technology requires hundreds of images of the object, estimating their precise camera parameters and reconstructing high-fidelity 3D geometries with sub-millimeter accuracy.
Recently, researchers from Simon Fraser University and other institutions proposed a new 3D reconstruction paradigm that combines computational fidelity with the flexibility of the human visual system, inspired by the recent advancements in multi-view image generation models, especially MVDiffusion, MVDream, and Wonder3D, which demonstrate the potential of generating 3D models through large generative models.

Paper link: https://arxiv.org/abs/2402.12712
Project website: https://mvdiffusion-plusplus.github.io/
The article introduces a new method capable of generating high-resolution dense image sets for 3D model reconstruction without precise camera poses, based on diffusion models and a “view dropout” training strategy, achieving 3D consistency learning.
This method exhibits excellent performance in novel view synthesis, single view reconstruction, and sparse view reconstruction, surpassing existing technologies, while also exploring text-to-3D applications in conjunction with text-to-image models.

Specific Method Introduction
Specific Method Introduction
MVDiffusion++ can generate dense, high-resolution posed images from any number of unposed images. Learning 3D consistency is core to 3D modeling, typically requiring precise image projection models and/or camera parameters.
Surprisingly, self-attention between 2D latent image features is all that is needed for 3D learning, without projection models or camera parameters, and a simple training strategy will further achieve dense and high-resolution multi-view image generation.
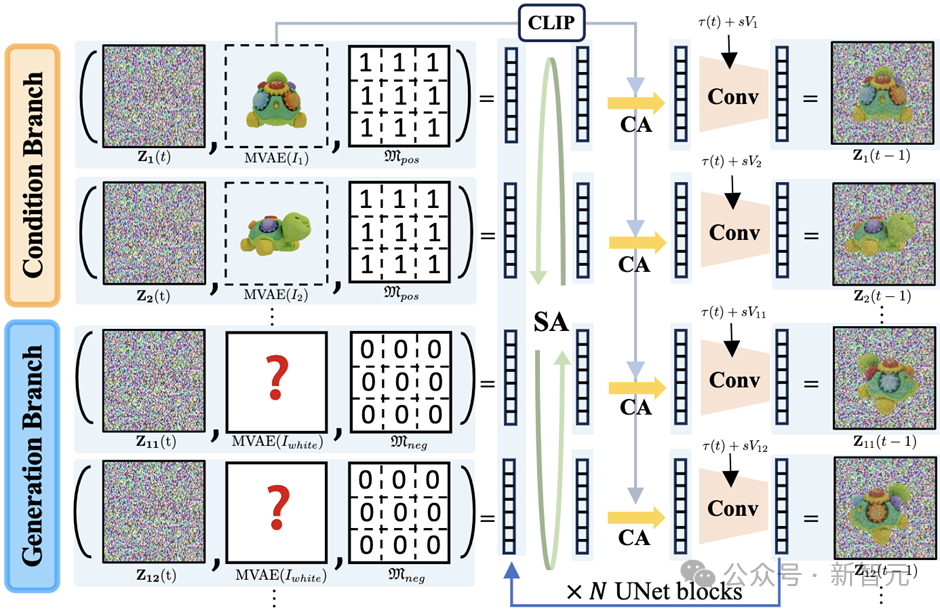
The generation target of MVDiffusion++ is a set of dense (32 images) and high-resolution (512×512 pixels) images, evenly located on a spherical 2D grid. Specifically, there are eight azimuths (one every 45°) and four elevations (one every 30° in the range of [-30°, 60°]).
The upward vector of the camera is aligned with gravity, with its optical axis passing through the center of the sphere. The input conditions are one or several images without camera poses, where visual overlap may be minimal or nonexistent, making it impossible to estimate precise camera poses through structure from motion. MVDiffusion++ supports up to 10 input images with a resolution of 512×512.
MVDiffusion++ is a multi-view diffusion model with a structure that includes a conditional branch for single-view or sparse-view input images and a generative branch for output images. Note that the conditional branch shares the same architecture, aiming to generate conditional images (a straightforward task).

Forward Diffusion Process
All 512 X 512 input/output images and their foreground masks are converted to a 64 X 64 latent space Z through a fine-tuned VAE, adding linear Gaussian noise to each feature Z in this latent space.
Reverse Diffusion Process
The denoising process is shown in the above diagram, where MVDiffusion++ uses UNet to denoise all Z_i(t). This UNet consists of 9 network module blocks at four feature pyramid levels on both the encoder and decoder sides. Specific details are described below.
First UNet Block
The input feature U_i^0 is initialized through the following inputs:
1) Noisy latent Z_i(t);
2) A constant binary mask, either all 0s or all 1s, indicating the branch type (conditional or generative);
3) Features Z of the latent space, where VAE is used to encode conditional images and their segmentation masks into Z. Note that this input has 9=(4+4+1) channels, and a 1 X 1 convolution layer reduces the channel dimension to 4. For the generative branch, a white image is passed as a binary image 1 as the segmentation mask.
Each Intermediate UNet Block
Processes the input with three network modules:
1) Global self-attention mechanism among UNet features of all images, learning 3D consistency;
2) Cross attention mechanism, injecting the CLIP embedding of the conditional image into all other images through CLIP;
3) CNN layers, injecting time step frequency encoding embeddings and learnable embeddings of image indices while processing features of each image. For the self-attention module, the network architecture and model weights are replicated and applied to all views.
Last UNet Block
Outputs noise estimates, using the standard DDPM sampler to produce the next time step Z_i(t-1).
View Dropout
MVDiffusion++ training faces scalability challenges. A total of 42 UNet features generate over 130k tokens, where even with the latest flash attention, global self-attention cannot be achieved.
The team proposed a simple yet surprisingly effective view dropout training strategy that completely drops a set of views from all layers during training.
Specifically, the team randomly drops 24 out of 32 views for each object during each training iteration, significantly reducing memory consumption during training. During testing, the entire architecture is run and generates 32 views.
Experimental Results
Experimental Results
MVDiffusion++ is trained using objaverse, and the following are the experimental results from testing on Google scanned objects.
1. Single View Reconstruction
The main baseline consists of three state-of-the-art single-view object modeling methods: SyncDreamer[1], Wonder3D[2], and Open-LRM[3].
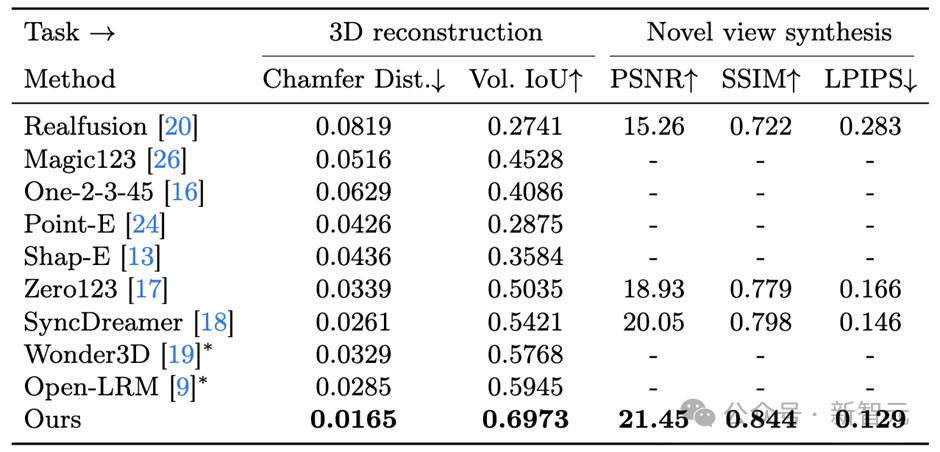
The table above presents quantitative assessments of the reconstructed 3D mesh and generated images. MVdiffusion++ consistently outperforms all competing methods.
The above image shows the generated images and reconstructed 3D mesh. The MVDiffusion++ method clearly displays the numbers on the clock (3rd row), while the numbers shown by other methods are blurry. Another example (5th row) shows two perfectly symmetrical windows generated by the new method, contrasting sharply with Wonder3D’s failure to maintain symmetry or clarity.
2. Sparse Multi-View Reconstruction Experiment
Sparse view unlocalized input images present a challenging setup. MVDiffusion++ selects LEAP as the baseline for comparison of view generation results. The literature on multi-view 3D reconstruction is extensive, and although these methods require input camera poses, comparison with the new method remains valuable.
As a compromise, the team chose NeuS as the second benchmark for comparing 3D reconstruction accuracy, providing them with real camera poses as input.
The table and image above present qualitative and quantitative comparison results. The image quality generated by MVDiffusion++ is significantly better than that of LEAP. Both LEAP and the new method utilize multi-view self-attention to establish global 3D consistency.
Thus, the team attributes the better performance to the strong image priors inherited from the pre-trained latent diffusion model. The meshes reconstructed by MVDiffusion++ exceed those of NeuS in most settings, which is a noteworthy achievement considering NeuS uses real camera poses.
This comparison highlights the practicality of the new method, enabling users to obtain high-quality 3D models from just a few snapshots of objects.
Conclusion
Conclusion
This article presents a pose-free technique for reconstructing objects using any number of images. The core of this method is a complex multi-branch, multi-view diffusion model.
This model can handle any number of conditional images, generating dense, consistent views from fixed perspectives. This capability significantly enhances the performance of existing reconstruction algorithms, allowing them to generate high-quality 3D models. The results indicate that MVDiffusion++ sets new performance standards for single-view and sparse-view object reconstruction.
