
Jishi Guide
Recently, AI drawing has become very popular, and one of the core technologies behind it is the Diffusion Model. Although fully understanding the Diffusion Model and its complex formula derivations requires mastering a considerable amount of prerequisite mathematics, this does not prevent us from grasping its principles. Next, I will explain what the Diffusion Model is from my understanding. >> Join the Jishi CV technology group to stay at the forefront of computer vision
What is the Diffusion Model
Forward Diffusion Process
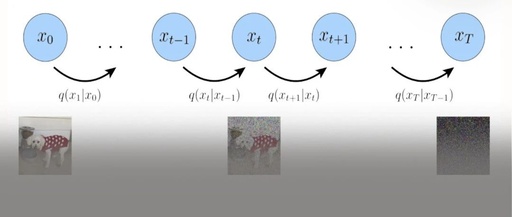
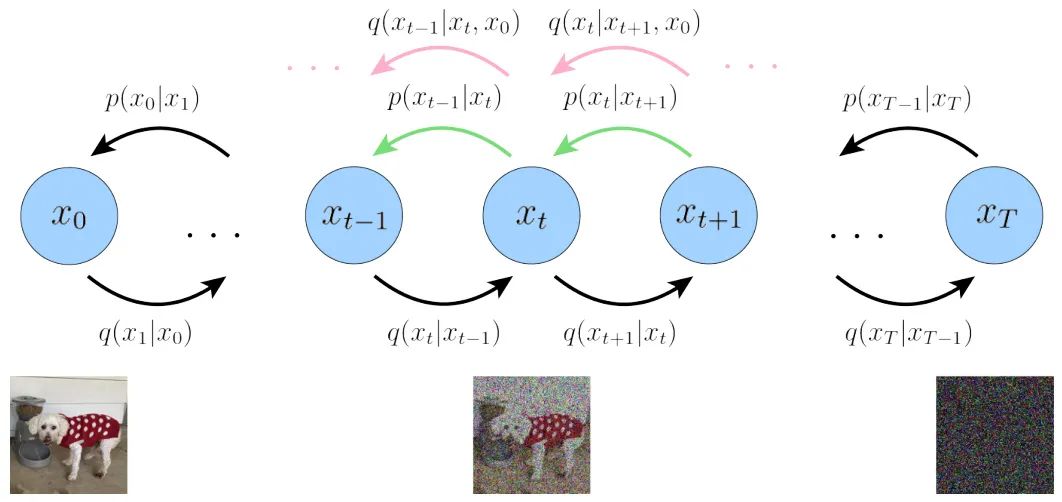
The Diffusion Model first defines a forward diffusion process, which contains a total of T time steps, as shown in the figure below:
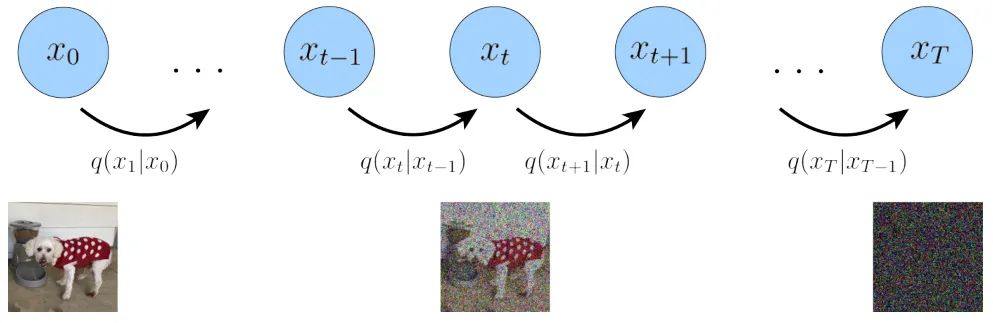
The leftmost blue circle x0 represents the real natural image, corresponding to the dog image below.
The rightmost blue circle xT represents pure Gaussian noise, corresponding to the noise image below.
The middle blue circle xt represents the noisy x0, corresponding to the dog image with noise added below.
The expression below the arrow q(xt|xt-1) represents a Gaussian distribution with the previous state xt-1 as the mean, from which xt is sampled.
The so-called forward diffusion process can be understood as a Markov chain (see reference [7]), which gradually adds Gaussian noise to a real image until it eventually becomes a pure Gaussian noise image.
So how is noise added specifically? The formula is represented as follows:
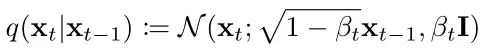
That is, at each time step, xt is sampled from a Gaussian distribution with mean sqrt(1-βt) multiplied by xt-1, and βt is the variance.
Where βt, t ∈ [1, T] is a series of fixed values generated by a formula.
In reference [2], T=1000, β1=0.0001, βT=0.02 is set, and all βt values can be generated with this line of code:
# https://pytorch.org/docs/stable/generated/torch.linspace.html
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
Then, when sampling to obtain xt, it is not sampled directly from the Gaussian distribution q(xt|xt-1), but a reparameterization trick is used (see reference [4] page 5 for details).
In simple terms, if you want to sample from a Gaussian distribution with arbitrary mean μ and variance σ^2
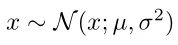
You can first sample ε from a standard Gaussian distribution (mean 0, variance 1).
Then μ + σ·ε is equivalent to the result of sampling from any Gaussian distribution. The formula is represented as follows:
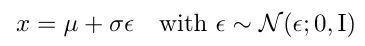
Next, let’s look at how to sample the noise image xt?
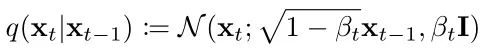
First, sample from the standard Gaussian distribution, then multiply by the standard deviation and add the mean. The pseudocode is as follows:
# https://pytorch.org/docs/stable/generated/torch.randn_like.html
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
noise = torch.randn_like(x_0)
xt = sqrt(1-betas[t]) * xt-1 + sqrt(betas[t]) * noise
Then, the forward diffusion process has another property: you can directly sample xt from x0 at any intermediate time step, as shown in the formula below:
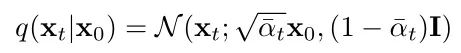
Where αt is represented as:
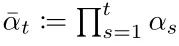
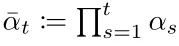
The specific derivation can be found in reference [4] page 11, and the pseudocode is represented as follows:
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
alphas = 1 - betas
# cumprod is equivalent to calculating a prefix product for the array alphas at each time step t
# https://pytorch.org/docs/stable/generated/torch.cumprod.html
alphas_cum = torch.cumprod(alphas, 0)
alphas_cum_s = torch.sqrt(alphas_cum)
alphas_cum_sm = torch.sqrt(1 - alphas_cum)
# Apply the reparameterization trick to sample xt
noise = torch.randn_like(x_0)
xt = alphas_cum_s[t] * x_0 + alphas_cum_sm[t] * noise
Through the above explanation, readers should have a clearer understanding of the forward diffusion process of the Diffusion Model.
However, our goal is to generate images, right?
So far, we’ve only obtained a noise image from the real image in the dataset; how do we generate images specifically?
Reverse Diffusion Process
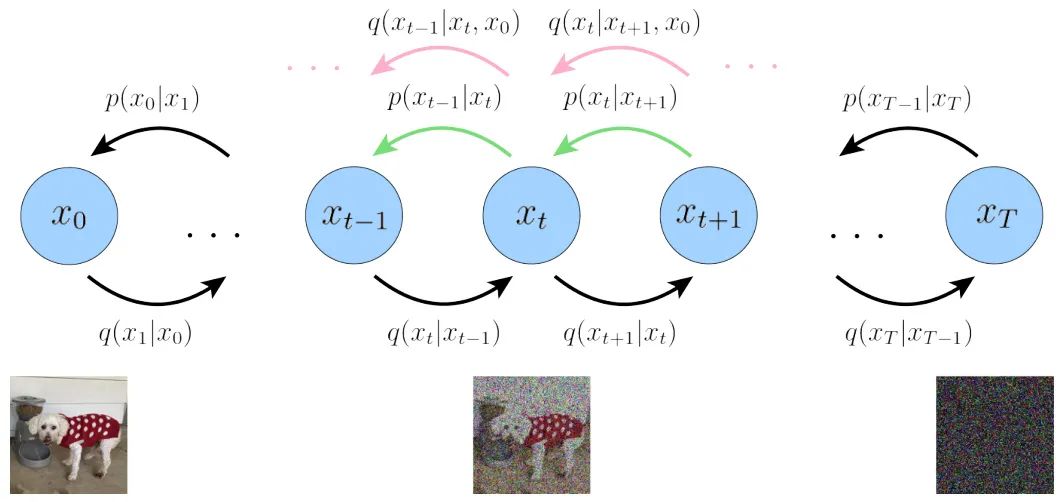
The reverse diffusion process q(xt-1|xt, x0) (see the pink arrow) is the posterior probability distribution of the forward diffusion process q(xt|xt-1).
In contrast to the forward process, it starts from the pure Gaussian noise image on the far right and gradually samples to obtain the real image x0.
The posterior probability q(xt-1|xt, x0) can be derived based on Bayes’ theorem (the derivation process can be found in reference [4] page 12):
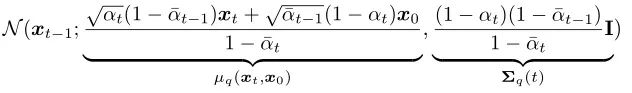
It is also a Gaussian distribution.
Its variance, as seen from the formula, is a constant, and the variance values for all time steps can be calculated in advance:
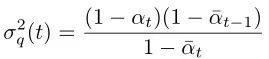
The calculation pseudocode is as follows:
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
alphas = 1 - betas
alphas_cum = torch.cumprod(alphas, 0)
alphas_cum_prev = torch.cat((torch.tensor([1.0]), alphas_cum[:-1]), 0)
posterior_variance = betas * (1 - alphas_cum_prev) / (1 - alphas_cum)
Next, let’s look at the calculation of the mean,
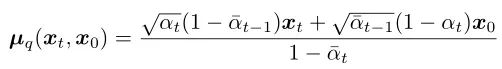
For the reverse diffusion process, when sampling to generate xt-1, xt is known, while the other coefficients are constants that can be calculated in advance.
However, now the problem arises: when actually generating images through the reverse process, we do not know x0, as this is the target image to be generated.
It seems to become a chicken-and-egg problem; what should we do?
Diffusion Model Training Objective
When a probability distribution q is difficult to solve, we can change our thinking (see reference [5,6]).
By artificially constructing a new distribution p, the goal becomes to minimize the difference between distributions p and q.
By continuously modifying the parameters of p to minimize the difference, when p and q are sufficiently similar, p can replace q.
Returning to the reverse diffusion process, since the posterior distribution q(xt-1|xt, x0) cannot be directly solved,
We construct a Gaussian distribution p(xt-1|xt) (see the green arrow), making its variance consistent with the posterior distribution q(xt-1|xt, x0):
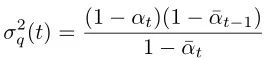
Its mean is set as:
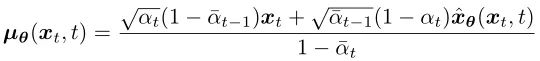
The difference between q(xt-1|xt, x0) and p(xt-1|xt) is that x0 is replaced by xθ(xt, t), which is predicted by a deep learning model, with the model input being the noisy image xt and the time step t.
Then, the goal function to minimize the difference between distributions p(xt-1|xt) and q(xt-1|xt, x0) becomes optimizing the following objective function (the derivation process can be found in reference [4] page 13):
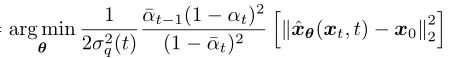
However, if we let the model directly predict x0 from xt, the fitting difficulty is too high, so we continue to change our thinking.
In the previous introduction of the forward diffusion process, it was mentioned that xt can be directly obtained from x0:
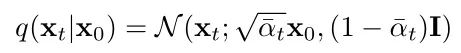
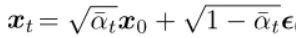
By rearranging the above formula:
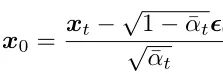
Substituting into the mean expression of q(xt-1|xt, x0) yields (derivation process can be found in reference [4] page 15):
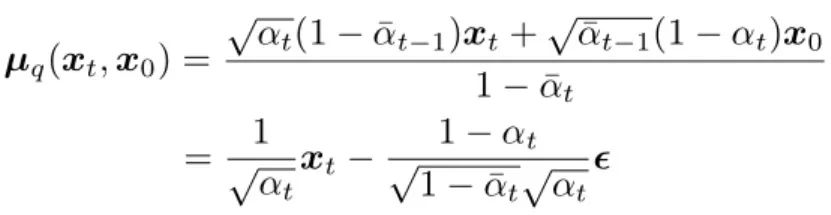
Looking at the transformed expression above, we find that the mean of the posterior probability q(xt-1|xt, x0) only relates to xt and the noise added during the forward diffusion at time step t.
So we also modify the mean of the constructed distribution p(xt-1|xt):
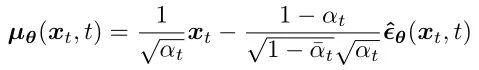
We change the model to predict the Gaussian noise ε added at the forward time step t, with the model input being xt and the time step t:
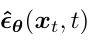
Then the optimized objective function becomes (derivation process can be found in reference [4] page 15):
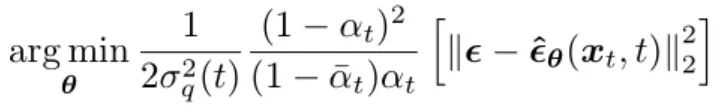
The training process algorithm description is as follows. The final objective function has its coefficients removed because they are constants:

Although the preceding derivation process is complex, the training process is quite simple.
First, each iteration involves taking a real image x0 from the dataset and sampling a time step t from a uniform distribution,
Then, sample Gaussian noise ε from a standard Gaussian distribution and calculate xt based on the formula.
Next, input xt and t into the model to fit and predict the noise ε, and update the model through gradient descent, repeating this until convergence.
The deep learning model used is structured similarly to UNet (see reference [2] Appendix B).
The pseudocode for the training process is as follows:
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
alphas = 1 - betas
alphas_cum = torch.cumprod(alphas, 0)
alphas_cum_s = torch.sqrt(alphas_cum)
alphas_cum_sm = torch.sqrt(1 - alphas_cum)
def diffusion_loss(model, x0, t, noise):
# Calculate xt based on the formula
xt = alphas_cum_s[t] * x0 + alphas_cum_sm[t] * noise
# Model predicts noise
predicted_noise = model(xt, t)
# Calculate Loss
return mse_loss(predicted_noise, noise)
for i in len(data_loader):
# Read a batch of real images from the dataset
x0 = next(data_loader)
# Sample time step
t = torch.randint(0, 1000, (batch_size,))
# Generate Gaussian noise
noise = torch.randn_like(x_0)
loss = diffusion_loss(model, x0, t, noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Diffusion Model Image Generation Process
Once the model is trained, during the actual inference phase, we must start generating images step by step from time step T, as described by the algorithm below:

Initially, generate noise from a standard Gaussian distribution, then at each time step t, input the previously generated image xt into the model to predict the noise. Next, sample noise from the standard Gaussian distribution, and based on the reparameterization trick, the posterior probability mean and variance formulas, calculate xt-1 until reaching time step 1.
Improvements to the Diffusion Model
Article [3] proposes some improvements to the Diffusion Model.
Improvement of Variance βt
It was previously mentioned that the generation of βt involves dividing a given range uniformly into T parts, with each time step corresponding to a certain point:
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
Then article [3] observed through experiments that generating variance βt in this way leads to a problem where too much noise is added at later time steps during the forward diffusion.
The result of this is that at later time steps in the forward process, there is not much contribution during reverse generation sampling, and skipping them would not significantly affect the generation results.
Next, the paper [3] proposes a new strategy for generating βt, with the comparison to the original strategy in the forward diffusion shown in the figure below:

The first row is the original generation strategy, where you can see that it has already become pure Gaussian noise before reaching the last time step,
while the second row shows the improved strategy, which adds noise more slowly and appears more reasonable.
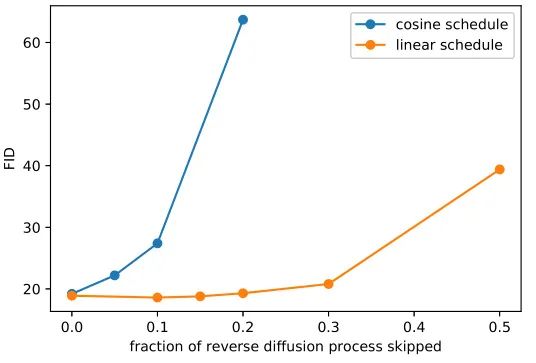
Experimental results indicate that for images of size 64x64 from the imagenet dataset, the original strategy does not significantly affect the metrics even if the first 20% of time steps are skipped during reverse diffusion.
Now let’s look at the newly proposed strategy formula:
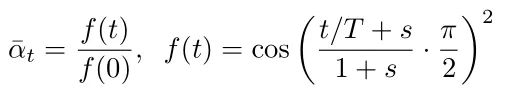
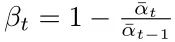
Where s is set to 0.008 and the maximum value of βt is limited to 0.999. The pseudocode is as follows:
T = 1000
s = 8e-3
ts = torch.arange(T + 1, dtype=torch.float64) / T + s
alphas = ts / (1 + s) * math.pi / 2
alphas = torch.cos(alphas).pow(2)
alphas = alphas / alphas[0]
betas = 1 - alphas[1:] / alphas[:-1]
betas = betas.clamp(max=0.999)
Improvement of the Number of Time Steps in the Generation Process
Originally, the model was trained assuming it would train under T time steps, and during image generation, it had to traverse from T to 1. However, the paper [3] proposes a method to reduce the number of generation steps without retraining, significantly improving generation speed.
This method is simply described as follows: originally T time steps are now set to a smaller number of time steps S, where each time step s in the S series corresponds to a step t in the T series. The pseudocode is as follows:
T = 1000
S = 100
start_idx = 0
all_steps = []
frac_stride = (T - 1) / (S - 1)
cur_idx = 0.0
s_timesteps = []
for _ in range(S):
s_timesteps.append(start_idx + round(cur_idx))
cur_idx += frac_stride
Next, calculate the new β, where St is the s_timesteps calculated above:
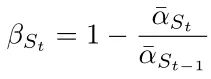
The pseudocode is as follows:
alphas = 1 - betas
alphas_cum = torch.cumprod(alphas, 0)
last_alpha_cum = 1.0
new_betas = []
# Traverse the original alpha prefix product sequence
for i, alpha_cum in enumerate(alphas_cum):
# When the index i of the original sequence T is in the new sequence S, calculate the new beta
if i in s_timesteps:
new_betas.append(1 - alpha_cum / last_alpha_cum)
last_alpha_cum = alpha_cum
Let’s take a look at the experimental results:
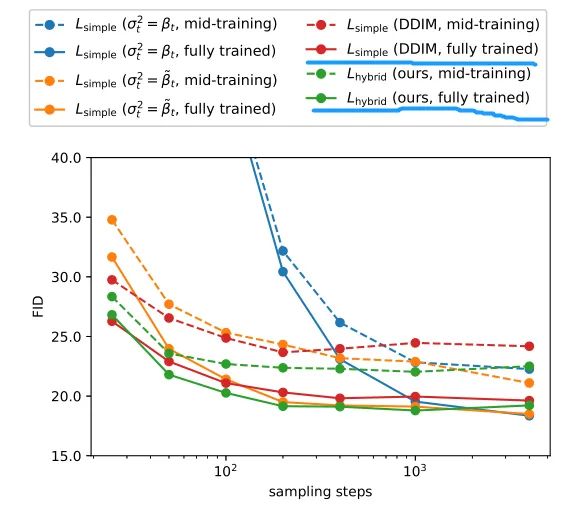
Pay attention to the red and green solid lines drawn in blue; you can see that reducing the sampling steps from 1000 to 100 does not significantly decrease the metrics.
References
-
[1] https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/ -
[2] https://arxiv.org/pdf/2006.11239.pdf -
[3] https://arxiv.org/pdf/2102.09672.pdf -
[4] https://arxiv.org/pdf/2208.11970.pdf -
[5] https://www.zhihu.com/question/41765860/answer/1149453776 -
[6] https://www.zhihu.com/question/41765860/answer/331070683 -
[7] https://zh.wikipedia.org/wiki/%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB%E9%93%BE -
[8] https://github.com/rosinality/denoising-diffusion-pytorch -
[9] https://github.com/openai/improved-diffusion

Reply