Research Direction | Recommendation, Search, NLP, etc.
Introduction
I really like the imagery often found in science fiction novels that “the universe is a computer.” After diffusion models represented by Disco Diffusion and Stable Diffusion became popular, I often face many questions from people—what is the principle of diffusion models? Why do they produce astonishing images? And why do they sometimes generate nonsensical images?I find it very difficult to explain this clearly—you cannot explain Markov processes, sampling, and parameter estimation to an artist; therefore, I want to write an article, starting from the idea of “the universe as a computer,” trying to visually explain what diffusion models are, what happens, and how they are trained. I hope this article can help everyone understand diffusion models (intuitively).Related: Most of the diagrams in this article were generated through the Zcool AI Lab [1]. A small portion comes from Illustrated Stable Diffusion [2].
A Big Bang—From Nothing to Something
According to cosmological theories, a uniform and isotropic universe expands from a “singularity”; this expansion process is called The Big Bang—宇宙大爆炸 [3]. Shortly after the Big Bang, due to the influence of random quantum fluctuations [4], various fundamental particles that make up matter gradually precipitate from isotropic energy; subsequently, under the influence of four fundamental forces: strong force, weak force, electromagnetic force, and gravity, the fundamental particles scattered in space gradually gather to form atoms, molecules, and molecular clusters, which in turn form nebulae, stars, and planets.Once matter appears, stable material structures and physical laws begin to dominate the universe, and the random effects of quantum fluctuations gradually recede. This means that you will not suddenly find a large hole in your chest while walking down the street or be crushed by a rock that appears out of nowhere.
▲ Figure 1: The evolution of the universeIf everyone has a certain understanding of the Diffusion Model, we can find that the above image is astonishingly similar to the denoising process in the Diffusion Model:
▲ Figure 2: The process of image generation by diffusion modelsTherefore, we can also view the process of generating images by the Diffusion Model as a kind of “creation evolution” model: from a blank image, through random sampling (quantum fluctuations) generates meaningless noise (fundamental particles); guided by the “physical laws” provided by the model, the noise gradually evolves into colors, lines, textures, and eventually forms objects, faces, images, scenes, and pictures. From this perspective, the operating principle of the Diffusion Model is completely different from human thinking; the painting process of the Diffusion Model is a bottom-up process.In contrast, human painting is top-down: first, there is a scene—like “a beautiful girl walking in the forest”; an experienced painter will outline only a few lines and gradually refine each element in the picture: where is the girl, how many trees are in the forest, what does the girl look like, what is she wearing, what types of trees are in the forest; while the Diffusion Model is: first randomly generate pixels, then slowly reveal characters, scenes, etc. from these pixels.The following image shows the process of generating “a girl in the forest” after 50 iterations; the bottom right corner is the original noise image, iterating from right to left, from bottom to top; each generation is related to the previous result (first-order Markov chain).As we can see, at first, the image is completely noise, and nothing can be seen; after several iterations, if you have enough imagination, you should be able to envision that the white area emerging in the middle can be drawn into a human figure, and the chaotic green textures behind it can be refined into a forest background; after several more iterations, the image has basically taken shape, and the outlines of the person and the forest appear; after multiple iterations, a logically and semantically coherent image is finally generated.
▲ Figure 3: The process of generating an image after 50 iterations, from the bottom right to the top leftWhat if we change the initial noise? We used the same text condition to regenerate an image, but the initial noise was randomly regenerated, as shown in the following image (for convenience, during the 50-step generation process, only 9 intermediate steps were retained, outputting one image every 5-6 steps):
▲ Figure 4: From the top left to the bottom right, the process of generating an image again using the exact same prompt as Figure 1
It is easy to see that the introduction of “randomness” can produce completely different results under the same initial conditions. The explanation of randomness and determinism in diffusion models will be detailed in Section 4.
Where Do the “Physical Laws” in Creation Games Come From?
Everything in the universe is formed by self-organization: quarks formed by the Big Bang; celestial bodies generated in cosmic nebulae; the formation of the Earth’s lithosphere; crystallization of gypsum and sodium chloride; the condensation of hexagonal snowflakes; and so on. The four forces in the universe: strong force, weak force, electromagnetic force, and gravity are universal adhesives, promoting complex organizations to spontaneously build. … The self-organization process of non-living matter does not require templates, or it can be said to require templates, but these templates are very simple and omnipresent in the universe. Therefore, the sun and stars 10 billion light-years away can have the same growth process; if snowflakes fall on the planets of the Barnard star system, they can only be hexagonal and never pentagonal.
—— Jin-Kang Wang, “Mercury Sowing”
In the analogy of the image generation process in creation games, we know that “physical laws” are an important component of the “universal generation game.” Without the constraints of physical laws, completely random quantum fluctuations would produce a universe filled with isotropic, restless virtual particles, even at the microscopic scale; similarly, if there are no rules in the image generation process, then the image will forever remain a pile of noise.In the Diffusion Model, the “physical laws” include two parts, corresponding to the two modes of generation: unconditioned generation and conditionally guided generation.First, let’s look at unconditioned generation. Unconditioned generation corresponds to the “basic physical rules” in the creation game: suppose we delineate a space in the universe created after the Big Bang, only specifying the basic physical laws, then in this space, through the joint action of random quantum fluctuations and physical laws, it is possible to produce nebulae, stars, black holes, or even a community of life.In the image generation process, the result depends on the initial rules and the knowledge learned by the model from the “sample data universe”: if the dataset contains only pictures of human faces, then through an unconditioned generation process, a photo of a dog will never be produced, but rather a human face, because the model can only learn the “physical laws” of “how to generate human faces” from this data. However, for a model trained on an all-encompassing dataset, this experiment becomes much more interesting:
▲ Figure 5: Two images randomly generated without any initial guiding conditionsWe used stable diffusion to generate images twice without any initial condition input (no prompt, input_image, or input mask, using random seed); we can see that the images generated can be called “meaningful images,” but they are completely uncontrollable, and the two images even have no connection. This means that the model itself stores the “rules” of “generating images from noise”—although what kind of image can be generated is like the famous Schrödinger’s cat, we cannot imagine or decide before generation.As for conditional guidance, it corresponds to another mode of the “creation game.” For example, we delineate a space, and in addition to specifying the basic physical laws, we also impose some “guiding rules”:
Increase the probability of generating heavy elements; after light elements are generated, let them have a higher probability of generating heavy elements;
When heavy elements are generated, they have a higher probability of aggregating together;
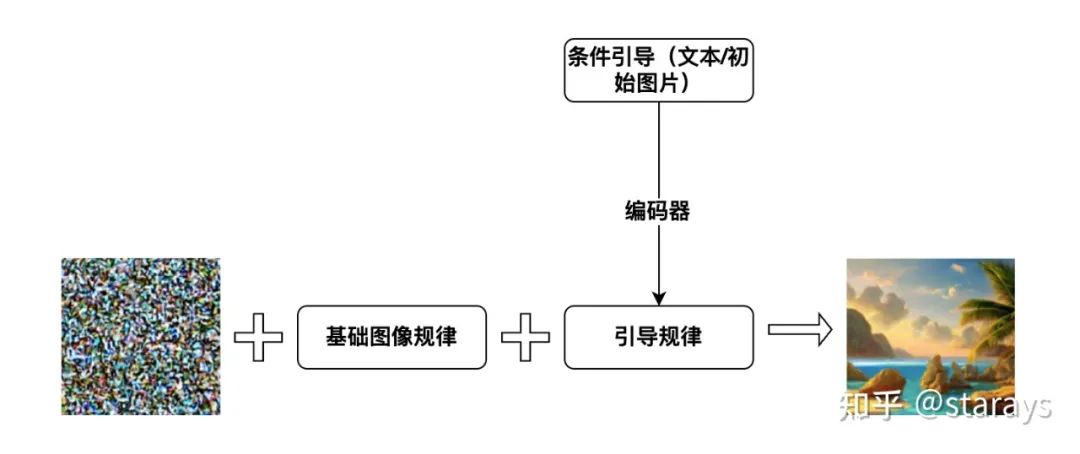
Then, in this space, it is more likely to produce a rocky planet rather than a gaseous nebula or interstellar dust dispersed throughout the space.In the Diffusion Model, when inputting text guidance or initial image guidance, it actually introduces “guiding rules” in addition to the “basic physical laws.” When we use text guidance, such as “a photo of a beautiful girl,” the text will be encoded by the model into “guiding rules,” which, together with the “basic laws of image generation,” guide the generation of the image—when the noise undergoes random disturbances and a line appears, the “text guiding rules” tend to interpret this line as the girl’s hair or clothing folds, and push the pixels in that area to change towards “refining the texture of hair/clothing folds.” Therefore, the operation process of the Diffusion Model is actually:
▲ Figure 6: The basic principle of the Diffusion Model. It should be noted that concepts such as “basic image rules,” “guiding rules,” and “encoder” are created for ease of understanding and are not the basis for dividing network modules in the Diffusion Model
“Basic image rules” and “guiding rules” are encoded in the parameters of the neural network, which differ from the rules mastered by human painters (how to compose, what kind of brush strokes to use, how to draw lines, etc.); the Diffusion Model encodes the “rules of pixel movement and change under certain guiding conditions.” So, where do the rules encoded in the neural network come from? The answer is: learned from samples. If only image data is used, the neural network learns the “basic image rules”; if paired data of “text and images” is used, the neural network can learn not only the “basic image rules” but also the “text guiding rules.” With the maturity of multimodal matching technologies like CLIP, much of the work of “learning image generation rules from text guidance” does not need to start from scratch. This is also one reason why text-to-image models exploded in 2022 (the CLIP model was released by OpenAI in early 2021).
Why Use Multi-Step Iteration for Generation?
In general neural network models, the “prediction” or “inference” part is usually end-to-end—inputs are sent to the model, and after one run and processing of the model, results can be directly generated. In the Diffusion Model, this process is completed through dozens to hundreds of time steps. Why is that?Just like in the creation game, to generate a rocky planet, from the beginning of the Big Bang to the generation of the planet, it has undergone billions of years of evolution. If we break down this billions of years of evolutionary process into countless time slices, then the induction of physical rules becomes relatively simple— for example, the creator tells a deity, give you a bunch of samples, each sample containing particle dynamics systems composed of billions of particles and the state of that system one second ago and one second later, you summarize the dynamics laws of the particles, which is relatively straightforward.However, if you want to go directly from time point 0 to the final current time point, then the summary of the “physical rules” becomes extremely complex:
What elements make up the crust, mantle, and core of the rocky planet? What rules do they follow?
What elements make up the atmosphere? Will it dissipate?
Is there a biosphere? What is its composition?
And so on.Although the deity has not studied geology and biology, with the summarized particle dynamics laws, near-infinite computational power, and a long time, this deity can still evolve a rocky planet from a pile of interstellar particles.For neural network models, it is the same. Neural network models essentially encode “rules”; the simpler the rules to encode, the easier the training of the neural network, and the higher the computational efficiency. In practice, the training process of the Diffusion Model is “iterative.” In the training of the Diffusion Model, the training samples are paired samples of the form . The Diffusion Model learns:
If we have a certain initial state at a time slice and want to get the next state, what are the corresponding “rules of pixel movement or change”?
Or, if a guiding condition is added, under the input of and , what are the corresponding “rules of pixel movement or change”?
These learned rules are encoded in the parameters of the neural network. The models of Stable Diffusion and Disco Diffusion (if you run the models on your computer, you will need to download these model parameters) are the encodings of these rules that are trained, fixed, and stored.Correspondingly, generation is also an iterative inversion. Each step of iteration in the Diffusion Model only considers what the next state will be based on “the current state of the image” and “the rules encoded in the model.” After dozens of iterations, the generated image may differ greatly from the initial state, but it is still an image and conforms to semantic guidance.
Randomness and Determinism in the Diffusion Model
When using Stable Diffusion, everyone often has a confusion at the beginning: why do the images generated from the same text differ greatly?The answer is: randomness. As we illustrated in the first section, different initial conditions can produce different results. The image generation process is always filled with randomness:
The initial image (noise image) is randomly generated;
In each step of iterative generation, the movement process of the “pixels” also introduces a certain randomness.
Similar to the evolution of the universe, where different celestial bodies evolve from isotropic space and energy, the random quantum fluctuations during the inflationary era are the main reason— even for celestial bodies of the same type, the size, elemental composition, landforms, and environments of rocky planets can vary greatly. But when the era dominated by “randomness” passes, matter begins to settle, and random disturbances gradually give way to determined physical laws.As shown in Figures 3 and 4, although the differences in images generated from the same text are significant due to random disturbances, if we continue to iterate from the second half of the generation process shown in Figure 3 (after it has “roughly taken shape”), randomness becomes less important, and we will have a high probability of obtaining images similar to the final result of Figure 3.However, the von Neumann architecture computer is not a quantum computer. Here, it is important to understand a concept: in classical structured computers, there exists only pseudo-randomness [5]— if the inputs are exactly the same, the outputs must be exactly the same. In the use of the Diffusion Model, we can guarantee that the results of two generations are the same by specifying the Seed (the seed for generating random numbers; the same seed will produce exactly the same sequence of random numbers).
Common Questions: Why Can’t Stable Diffusion Correctly Generate Images like “A Man to the Left of a Woman” or “Normal Human Face”?
Another common question is: the results generated by the Diffusion Model often fill the entire picture with tension but are particularly poor at handling details and logical concepts. For example:
Positional relationships: If the input is “a man to the left of a woman,” it seems that the positions of the two people are random;
Quantity: If the input is “five tigers,” it is likely to result in a number of tigers that are not equal to five;
Details: If drawing “a portrait of a person,” it may yield a delicate face; but if drawing “a handsome warrior galloping on a vast grassland,” it seems that this warrior has no facial features…
The reasons for these issues are complex and may not be singular. The most plausible guesses include:
Neural network mechanism issues. Neural network models tend to “remember” rather than “deduce”; for humans, the simple logic of “A leads to B” is for neural networks only learned through extensive data samples, trying to remember “if A appears, then B appears”; however, this kind of memory cannot be “derived”; for example, “because A, therefore B; because B, therefore C”; for humans, it is easy to deduce “because A, therefore C”; but for neural networks, it cannot combine two rules to get “if A appears, then C appears”;
Data issues. The common issue of “poor hand drawing” is often speculated to be due to the significant differences in hand shapes in photos under different angles and scenes (such as fist, handshake, fingers spread, V sign), which are all labeled as “hand” in corresponding texts; and some anime characters (often with four fingers or even no fingers) also confuse the neural network regarding the concept of “hand”;
Neural network attention issues. The gradient backpropagation training mechanism of neural networks causes the model to focus on the overall picture rather than local details. “Overall picture OK but local details wrong” corresponds to “overall picture wrong but local details perfect”; its loss function has a smaller value, meaning the model can receive more rewards and less punishment; when the model cannot achieve “both overall picture and local details are perfect,” it often tends to pursue overall picture quality; this also causes the phenomenon of “portraits being exquisite, but faces in a grand scene often resembling ghosts”;
In addition to these issues, data bias often leads to deviations in the model’s output. For example, research institutions have found that when inputting “CEO,” the Diffusion Model has a high probability of generating “an image of a middle-aged/older white male in a suit” rather than a female, a person of color, or a teenager; even when inputting “Black teenager CEO,” there is still a considerable probability of producing this image. This is because in the training samples of the model, the term “CEO” often appears simultaneously with “middle-aged/older white male in a suit,” leading the model to learn this bias incorrectly.
Citations and Thanks
1. Some images and descriptions in this article come from Illustrated Stable Diffusion [6]. Jay Alammar [7] is a popular science writer in computer science that I really like, and he is also very active on Discord, participating in many discussions on NLP and CV.
2. Some descriptions in this article are inspired by The Talk of Generative Diffusion Models: DDPM = Demolition + Construction (although there are significant differences in description);
3. If you want to delve into the principles and components of diffusion models, you can start from GitHub – divamgupta/stable-diffusion-tensorflow: Stable Diffusion in TensorFlow / Keras [8]. Although this is only an incomplete implementation of stable diffusion (only the generation process without the training process and removing many components), it is clearer and easier to understand.
4. The cover of this article was generated by www.zcool.com.cn/ailab.
How can more quality content reach readers with a shorter path, reducing the cost of finding quality content for readers? The answer is: people you do not know.
There are always some people you do not know who know what you want to know. PaperWeekly may become a bridge to facilitate the collision of scholars and academic inspirations from different backgrounds and directions, sparking more possibilities.
PaperWeekly encourages university laboratories or individuals to share various quality content on our platform, which can be the latest paper interpretations, analysis of academic hotspots, research insights or competition experience explanations, etc. Our only goal is to let knowledge truly flow.
📝 Basic Requirements for Submissions:
• The article is indeed an individual original work and has not been published in public channels; if the article has been published or is to be published on other platforms, please clearly indicate it
• Submissions are recommended to be written in markdown format, with images sent as attachments, requiring the images to be clear and without copyright issues
• PaperWeekly respects the author’s right to attribution and will provide industry-competitive remuneration for each accepted original first-published article, specifically calculated based on the article’s reading volume and quality tier
• Please include your immediate contact information (WeChat) in the submitted materials so that we can contact the author at the first opportunity when the manuscript is selected
• You can also directly add the editor’s WeChat (pwbot02) for quick submissions, with a note: name-submission
△ Long press to add PaperWeekly editor
🔍
Now, you can also find us on “Zhihu”
Enter the Zhihu homepage and search for “PaperWeekly”