

1 Introduction
1.1 Background of Generative Adversarial Networks
Generative Adversarial Networks (GAN) [1] are a type of generative model, which is a major class of machine learning methods, in contrast to discriminative models. Assuming x is the observed feature and y is the corresponding class label, the goal of a discriminative model is to model p(y|x), which learns the mapping relationship from input features to class labels. Unlike discriminative models, generative models model p(x|y), which means modeling the corresponding feature distribution given the class. Before GANs, the influence of deep generative models was much smaller compared to discriminative models, mainly due to difficulties in approximating many tricky probability calculations during the learning process of generative models through methods like maximum likelihood estimation. Additionally, it was difficult to utilize the advantages of piecewise linear units in generative contextual scenarios [1][2][3][4]. Due to these defects in existing deep generative models, Goodfellow et al. proposed Generative Adversarial Networks.
In GANs, there is a generator and a discriminator. The generator is responsible for capturing the data distribution of real samples and can generate new samples, while the discriminator is usually a binary classifier that determines whether the input samples are generated samples or real samples. The optimization process of the entire GAN is a minimax game problem. During training, the objective of training the discriminator is to minimize its classification loss, while the optimization of the generator and discriminator is a minimax game problem. When Nash equilibrium is reached, the generator can capture the distribution of data samples, thus achieving sample generation. In the paper by Goodfellow et al. in 2014 [1], they proved that the aforementioned game problem is equivalent to optimizing the Jensen-Shannon divergence between the data distribution and the generative model distribution.
Due to a series of good characteristics of GANs, they have been applied in various fields since their inception, with the most attention being in the field of computer vision, including applications such as image generation, image segmentation, and style transfer. Moreover, they have also attracted significant attention in other fields, such as information retrieval and text generation. They have quickly become one of the most discussed generative models in recent years, leading to a series of research works.
This paper will review the work on GANs in recent years, focusing on the following two aspects. The first aspect is the theoretical research of GANs, where progress in training methods and generative diversity will be emphasized. The second aspect will introduce the progress of GANs in various application fields, providing a comprehensive overview of the current applications of GANs, with a focus on analyzing the differences and applicability of various works.
1.2 Differences from Other Generative Models
GANs differ from autoencoders (Auto-encoder, AE), which are unsupervised neural network algorithms that utilize backpropagation. The main principle is to produce outputs similar to the input data through neural networks, making the function of the neural network equivalent to an identity function. Although the identity function is simple, autoencoders usually restrict the size of hidden variables, for example, encoding a large number of inputs into a smaller number of hidden variables, and then decoding from a smaller number of hidden variables back to outputs similar to the input data. Since hidden variables typically have a lower dimension than the input, autoencoders can often be used for dimensionality reduction. The assumption behind setting smaller hidden variable parameters is that there is a correlation between features, allowing the algorithm to find these correlations to represent the data with lower-dimensional hidden variables.
Furthermore, to solve complex probabilistic inference problems, Kingma et al. [8] proposed a stochastic gradient variational Bayesian method, which, when applied to neural networks, yields Variational Autoencoders. The main goal of Variational Autoencoders is to infer the posterior of hidden variables by establishing a variational lower bound that can be directly optimized through stochastic gradient methods. The authors showed that, on independent and identically distributed data, the posterior estimates can be fitted to an approximate inference model using the proposed lower bound.
An important difference between autoencoders and GANs is that the loss function of autoencoders typically uses a simple metric, such as Euclidean distance, leading to images generated by autoencoders often being blurry, while the metric function of GANs is more suitable for high-dimensional data.
The difference between GANs and Variational Autoencoders is that Variational Autoencoders have a variational lower bound, which deviates from the true sample distribution, while GANs, lacking a variational lower bound, can better fit the data distribution assuming the training data is good enough.
The Pixel Recurrent Neural Networks (PixelRNN) model [9] proposed by Van Den Oord et al. in 2016 is a generative model that generates samples pixel by pixel using recurrent neural networks. Compared to the PixelRNN model, GANs generate a complete sample at once, while PixelRNN generates samples pixel by pixel, thus offering better time performance.
2 Domestic Research Progress
2.1 Theoretical Research Progress of GANs in China
Compared to the application of GANs, there has not been much work on the theoretical research of GANs in China.
In terms of GAN training, City University of Hong Kong proposed a least squares loss function [93] to address the gradient vanishing problem caused by the original GAN’s loss function. In the original GAN, the discriminator uses the sigmoid function, which can easily saturate and cause gradient vanishing. In the least squares generative adversarial network (LSGAN) proposed in reference [93], the discriminator uses a non-saturating L2 loss function, providing the network with a continuous and stable gradient, thus stabilizing the training process, as shown in Figure 3.1.

Figure 2.1 Comparison of the learning capabilities of original GAN and LSGAN, where LSGAN learns the true distribution of data better, while original GAN is prone to mode collapse and struggles to learn the global true distribution. Image source: Reference [72]
In terms of GAN structure, Tsinghua University proposed an improved structured generative adversarial network (SGAN) [94], which has good controllability and decoupling, and can assist semi-supervised learning by generating high-quality labeled data. The main idea of SCAN is to divide the input vector into a category vector and a noise vector, encoding category information and other category-independent information respectively. By embedding the generated images back into the original category vector and noise vector, decoupling is achieved. Additionally, SCAN uses adversarial loss to maintain the authenticity of the generated images and the one-to-one correspondence between category and image, as well as between noise vector and image. Furthermore, Tsinghua University also proposed a Triple Generative Adversarial Nets (Triple-GAN) [95] in another work to address two issues that exist in general GANs (i.e., the generator and discriminator may not reach optimal simultaneously, and the generator cannot control the semantic information of the generated images). A classifier was added to the traditional adversarial framework between the generator and discriminator. The generator models the conditional probability distribution of images given labels, while the classifier models the conditional probability distribution of labels given images. From the real data, generator, and classifier, three joint probability distributions about images and labels can be obtained, and the discriminator focuses on determining the authenticity of the image-label pairs sampled from the three distributions. The ultimate optimization goal is to make the three joint probability distributions converge. Additionally, the paper introduced standard supervised loss to ensure this consistency. Triple-GAN achieved optimal classification results among generative models at that time and could decouple category and style information, achieving smooth transitions in category-limited latent space interpolation. Moreover, Shanghai Jiao Tong University proposed an improved Activation Maximization Generative Adversarial Network (AMGAN) [96] to address issues in the method mentioned in reference [13], outperforming similar conditional adversarial networks LabelGAN [13] and ACGAN [96]. The authors theoretically analyzed that the discriminator loss of LabelGAN optimizes generated samples toward a specific true category direction, rather than merely toward the direction of true samples, while the generator loss of LabelGAN optimizes generated samples toward the direction of true samples without a specified category, leading to inconsistent optimization directions between the generator and discriminator. Therefore, the authors proposed to change the generator loss of LabelGAN to optimize toward a specific true category direction, resulting in AMGAN.
In terms of evaluation metrics for GANs, Shanghai Jiao Tong University proposed a new sample quality metric called AM Score in their work on AMGAN. This was to address the issue that the commonly used Inception Score overly focuses on the diversity of generated samples while insufficiently addressing their quality.
2.2 Application Progress of GANs in China
Research on the application of GANs is quite active in China.
In image synthesis, the University of Science and Technology of China, the Chinese Academy of Sciences, and the Chinese University of Hong Kong proposed Conditional Variational Auto-encoder Generative Adversarial Network (CVAE-GAN) [97], Two-Pathway Generative Adversarial Network (TPGAN) [98], and FaceID-GAN [99], respectively, for identity/category-preserving face synthesis. One important step is to extract identity/category features using deep networks to ensure the identity/category of the generated images. Figure 3.2 shows the face image generation effect of FaceID-GAN.

Figure 2.2 FaceID-GAN generation result: It can generate images of a person from any angle and expression while maintaining that person’s identity. Image source: Reference [99]
In cross-domain image generation, the Chinese Academy of Sciences proposed Duplex Generative Adversarial Network (DupGAN) [100] for unsupervised domain adaptation, learning domain-invariant features through dual discriminators, achieving state-of-the-art results in unsupervised domain adaptation. City University of Hong Kong addressed the poor performance of multi-domain image generation by proposing Regularized Conditional GAN (RegCGAN) [101], which uses two regularization terms to guide the model in learning semantic information from different domains. Traditional domain adaptation targets the scenario where the source and target domain class spaces are the same, but often the target domain classes are only a subset of the source domain. The Chinese Academy of Sciences proposed Selective Adversarial Network (SAN) [102] to address this issue, achieving partial domain adaptation, as illustrated in Figure 3.3. Additionally, Tsinghua University proposed CartoonGAN [103] for cartoonizing real photos.
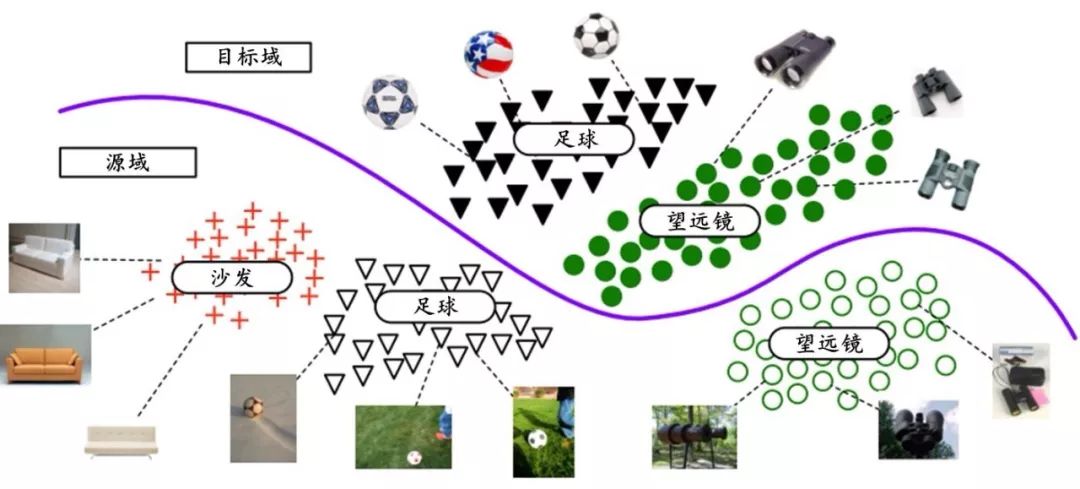
Figure 2.3 Partial domain adaptation issue, where the source domain classes and target domain classes differ. Image source: Reference [102]
In text generation, as previously mentioned in section 2.2.8, Shanghai Jiao Tong University was the first to propose Sequence Generative Adversarial Net (SeqGAN) [68], achieving a breakthrough in generating discrete sequences using GANs. SeqGAN views the sequence generation problem as a sequential decision-making problem, treating the generator as an agent in reinforcement learning, using the discriminator to provide rewards, and employing policy gradients for parameter updates. The Chinese University of Hong Kong also used GANs for text generation, improving the naturalness and diversity of generated sentences [104]. Tsinghua University in Taiwan explored cross-domain generation of text sequences [105]. This work used two discriminators, one to determine the domain of the text and the other to determine whether the text matches the image, successfully achieving unsupervised cross-domain generation. The Shanghai Jiao Tong University team that proposed SeqGAN also proposed a method for generating long texts [71], where the discriminator reveals some extracted features to the generator at intermediate time steps, guiding the generator in sequential generation.
Additionally, there are many other application works on GANs in China, such as object detection [106][107], pedestrian re-identification [108][109], image denoising and inpainting [110][111][112][113][114] and information retrieval [115][116][117][118][119].
3 Development Trends and Prospects
It can be seen that both domestically and internationally, theoretical and application research on GANs is rapidly developing. The main issues currently faced by GANs include the following aspects: 1) Unstable training processes; although this issue has been partially addressed with the introduction of WGAN [10], research on the stability of generated samples still requires different designs under different network structures, making this an ongoing area of study; 2) Quantitative evaluation metrics for generated samples; the current Inception Score [13], while capable of evaluating the quality of generated images, still cannot accurately assess multiple aspects of generated images, and better evaluation metrics are still needed; 3) Quality of generated samples; currently, most GANs can generate images with limited resolution. On this front, NVIDIA proposed a progressive growing GAN structure [120], but this structure is non-conditional, indicating that there is still room for further research into methods for generating higher resolution images. Furthermore, there remains a gap between the quality of generated samples and real samples; how to improve the quality of generated samples for various application fields remains a challenge for researchers to explore and propose more effective methods.
4 Conclusion
This paper mainly starts from the background of GANs, their basic structure, and comparisons with other generative models, although it introduced the progress of GANs in theoretical research and applications, and briefly described the evaluation index system of GANs. In section three, the domestic research work on GANs was presented. Finally, the future development trends of GANs were discussed.
Overall, since the introduction of GANs in 2014, they have experienced vigorous development, achieving stable training models in theoretical research, and numerous research works in various application fields have emerged, continuously improving the generation effects. However, there are still some shortcomings and defects in GANs that depend on researchers to further address. In the long run, due to the widespread applications of GANs, research on GANs holds significant practical significance and broad prospects.
Acknowledgments
This report was supported by the National Natural Science Foundation of China’s key project group, and the major research plan of military-civilian integration “Knowledge Representation, Inference, Online Learning Theory and Application Research for Big Data” (No: 61432008, U1435214). Thanks to Li Taotao, Ma Minglin, and Hou Haodi for their contributions to the report.
Author Information
Huo Jing

Name: Huo Jing
Affiliation: Nanjing University
Title: Assistant Researcher
Research Direction: Computer Vision, Machine Learning
CCF Position: CCF Member

Lan Yanyan

Name: Lan Yanyan
Affiliation: Institute of Computing Technology, Chinese Academy of Sciences
Title: Associate Researcher
Research Direction: Machine Learning and Information Retrieval
CCF Position: CCF Member

Gao Yang

Name: Gao Yang
Affiliation: Nanjing University
Title: Professor
Research Direction: Artificial Intelligence, Machine Learning, Big Data
CCF Position: Standing Committee Member of the Artificial Intelligence and Pattern Recognition Committee, Member of the Big Data Expert Committee, CCF Senior Member

China Computer Federation
WeChat ID: ccfvoice

Long press to identify the QR code to follow us
CCF Recommended
【Quality Articles】
-
CCF Releases the 2017-2018 China Computer Science and Technology Development Report
-
Research Progress and Trends of Formal Methods
-
Big Data Management and Analysis Technologies
-
Research Progress and Trends of Deep Integration of AI and System Software
-
System Engineering Perspective of Knowledge Graphs
Click“Read the Original”, to download and browse the report.