
Source: DeepHub IMBA
This article is approximately 7000 words long and is recommended to be read in over 10 minutes.
This article delves into the LLM Graph Transformer framework of LangChain and its dual-mode implementation mechanism for text-to-graph conversion.
The conversion from text to graph is a research area with technical challenges, where the core task is to transform unstructured text data into a structured graph representation. Although this technology has been around for a long time, its application scope has significantly expanded with the development of Large Language Models (LLMs), gradually becoming one of the mainstream technical solutions.
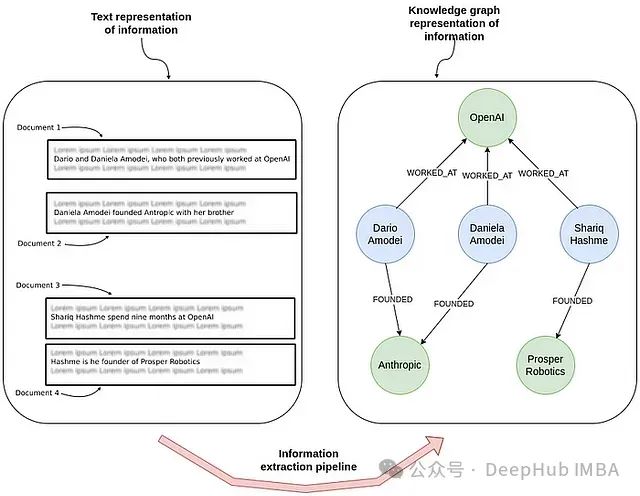
The above image illustrates the process of information extraction during the conversion from text to knowledge graph. The left side of the image shows an unstructured text document describing relationships between individuals and companies; the right side shows the same information in a structured representation within a knowledge graph, clearly presenting the working and founding relationships between individuals and organizations.
Structured representation of text information has significant application value, especially in Retrieval-Augmented Generation (RAG) systems. While applying text embedding models directly to unstructured text is a feasible solution, it often fails to meet requirements when dealing with complex queries that require understanding relationships between multiple entities or performing structured operations such as filtering, sorting, and aggregation. By converting text information into a knowledge graph, not only can data organization be made more efficient, but a framework that supports understanding complex entity relationships can also be built. This structured approach significantly enhances the accuracy of information retrieval and expands the types of queries the system can handle.
In the past year, LangChain has integrated knowledge graph construction in the form of LLM Graph Transformer into its framework. This article, written by a code contributor to LangChain, will provide a detailed introduction to these contents, and the article will also include source code provided by the author at the end.
Neo4j Environment Configuration
This implementation uses Neo4j as the graph data storage system, and its built-in graphical visualization functionality provides intuitive support for analysis. It is recommended to use the free cloud instance of Neo4j Aura to quickly start experiments. Alternatively, you can deploy the database instance locally by installing the Neo4j Desktop application.
from langchain_community.graphs import Neo4jGraph graph = Neo4jGraph( url="bolt://54.87.130.140:7687", username="neo4j", password="cables-anchors-directories", refresh_schema=False )
LLM Graph Transformer Technical Architecture
LLM Graph Transformer is designed as a graph construction framework adaptable to any LLM. Given the large number of different model providers and model versions in the current market, achieving this universality is a complex technical challenge. LangChain plays an important role here by providing the necessary standardization processing. LLM Graph Transformer adopts a dual-mode design, offering two independent operating modes.
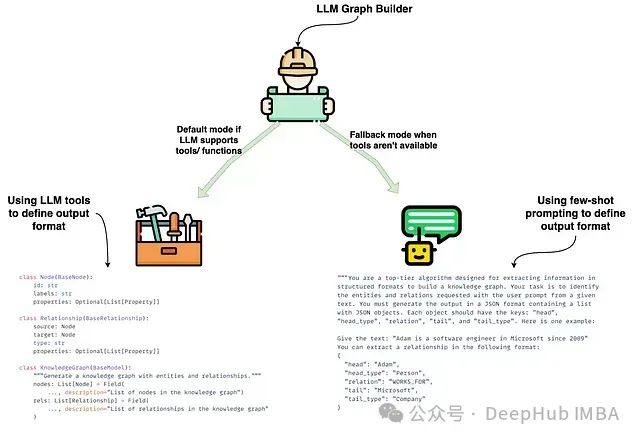
LLM Graph Transformer implements two different document graph generation modes, optimized for different scenarios of LLM applications:
-
Tool-Based Mode (Default Mode): This mode is suitable for LLMs that support structured output or function calls, and it achieves tool invocation through the LLM’s built-in with_structured_output functionality. The tool specification defines a standardized output format, ensuring the structural and standardized nature of the entity and relationship extraction process. This implementation method is illustrated on the left side of the graph, containing the core code implementation of the Node and Relationship classes. -
Prompt-Based Mode (Alternative Mode): This alternative is designed for LLMs that do not support tool or function calls. This mode defines the output format through few-shot prompting techniques, guiding the LLM to extract entities and relationships in text form. A custom parsing function is used to convert the LLM output into standard JSON format, which is then used to construct nodes and relationships. This mode relies entirely on prompt guidance rather than structured tools. The right side of the graph showcases example prompts and corresponding JSON output results.
This dual-mode design ensures that the LLM Graph Transformer can adapt to different types of LLMs, whether building directly through tools or generating graph structures through text prompt parsing.
Even when using models that support tools/functions, the prompt-based extraction mode can be enabled by setting the _ignore_tools_usage=True_ parameter.
Tool-Based Extraction Implementation
The reason for choosing the tool-based extraction method as the primary implementation scheme is that it minimizes the dependence on complex prompt engineering and custom parsing functions. In the LangChain framework, the with_structured_output method supports information extraction through tools or functions, and the output format can be defined through JSON structure or Pydantic objects. Considering maintainability, the author chose Pydantic objects as the definition method.
First, define the Node class:
class Node(BaseNode): id: str = Field(..., description="Name or human-readable unique identifier") # Name or human-readable unique identifier label: str = Field(..., description=f"Available options are {enum_values}") # Available label options properties: Optional[List[Property]] # Optional properties list
The Node class contains id, label, and optional properties fields. The description of id as a human-readable unique identifier is significant because some LLMs may interpret the ID property as a traditional random string or incrementing integer. In this implementation, we expect to use the entity name as the id property. By explicitly listing available options in the label description, we can restrict the label types. For LLMs that support the enum parameter (such as OpenAI’s models), we also leverage this feature. The definition of the Relationship class is as follows:
class Relationship(BaseRelationship): source_node_id: str # Source node identifier source_node_label: str = Field(..., description=f"Available options are {enum_values}") # Source node label target_node_id: str # Target node identifier target_node_label: str = Field(..., description=f"Available options are {enum_values}") # Target node label type: str = Field(..., description=f"Available options are {enum_values}") # Relationship type properties: Optional[List[Property]] # Optional properties list
This is the second iterative version of the Relationship class. In the initial version, the source and target nodes were represented using nested Node objects, but practice has shown that this structure reduces the accuracy and quality of the extraction process. Therefore, in the current version, we decompose the source and target nodes into independent fields, such as source_node_id, source_node_label, and target_node_id, target_node_label. Additionally, valid values for node labels and relationship types are clearly defined in the description to ensure that the LLM strictly adheres to the specified graph pattern.
The tool-based extraction method supports defining properties for nodes and relationships. The definition of the Property class is as follows:
class Property(BaseModel): """A single property consists of key-value pairs""" key: str = Field(..., description=f"Available options are {enum_values}") # Available options for property key value: str # Property value
Property is defined in key-value pair form. Although this design offers flexibility, it also has some technical limitations:
-
It is not possible to provide independent descriptions for each property; -
It is not possible to specify a distinction between required and optional properties; -
Property definitions are shared globally, rather than defined separately for specific node or relationship types.
The system also implements detailed system prompts to guide the extraction process. However, experience shows that function and parameter descriptions often have a greater impact on extraction quality than system messages.
A current limitation of the LLM Graph Transformer framework is the lack of a convenient mechanism for customizing function or parameter descriptions.
Prompt-Based Extraction Implementation
Considering that currently only a few commercial LLMs and LLaMA 3 support native tool functionality, we have implemented an alternative for models that do not support tools. Even when using models that support tools, the prompt-based extraction method can be enabled by setting ignore_tool_usage=True.
The main prompt engineering implementation and examples for the prompt-based method were contributed by Geraldus Wilsen. In this method, the output structure is directly defined in the prompt. Here is the core part of the system prompt:
You are a high-performance algorithm specifically designed for structured information extraction to build knowledge graphs. Your task is to identify entities and relationships specified by the user prompt from the given text and generate output in JSON format. The output should be a list of JSON objects, each containing the following fields:
- **"head"**: The extracted entity text, which must match the type specified in the user prompt - **"head_type"**: The type of the extracted head entity, selected from the specified type list - **"relation"**: The relationship type between "head" and "tail", selected from the allowed relationship list - **"tail"**: The text representation of the tail entity of the relationship - **"tail_type"**: The type of the tail entity, selected from the provided type list
Requirements: 1. Maximize the extraction of entity and relationship information 2. Ensure consistency in entity representation: Different representations of the same entity (e.g., "John Doe" might be represented as "Joe" or the pronoun "he") should be unified using the most complete identifier 3. The output should contain only structured data, without any additional explanations or text
```
The prompt-based method has several key differences from the tool-based method: 1. It only extracts relationships without extracting independent nodes, thus avoiding _isolated nodes_ 2. Considering that models without native tool support generally perform poorly, property extraction is not supported to simplify the output structure
Here is a typical few-shot example implementation:
```python
examples = [ { "text": ( "Adam is a software engineer in Microsoft since 2009, " # Adam has been a software engineer at Microsoft since 2009 "and last year he got an award as the Best Talent" # last year he received the Best Talent award ), "head": "Adam", "head_type": "Person", "relation": "WORKS_FOR", "tail": "Microsoft", "tail_type": "Company", }, { "text": ( "Adam is a software engineer in Microsoft since 2009, " "and last year he got an award as the Best Talent" ), "head": "Adam", "head_type": "Person", "relation": "HAS_AWARD", "tail": "Best Talent", "tail_type": "Award", }, ... ]
```
In the current implementation, it is not possible to add custom few-shot examples or supplementary instructions; the only customization method is to modify the overall prompt content through the prompt property. Expanding customization features is an important development direction for the future.<h2><span><strong><span>Graph Pattern Definition</span></strong></span></h2><p><span>When using LLM Graph Transformer for information extraction, a comprehensive graph pattern definition is crucial for building high-quality knowledge representation. A standardized graph pattern clarifies the types of nodes, relationship types, and related properties that need to be extracted, providing a clear extraction guidance framework for the LLM.</span></p><p><span>To verify the implementation effect, we selected the opening paragraph of Marie Curie's Wikipedia page as the test data and added a piece of information about Robin Williams at the end:</span></p><pre><code class="language-python"> from langchain_core.documents import Document text = """ Marie Curie, 7 November 1867 – 4 July 1934, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity. She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields. Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes. She was, in 1906, the first woman to become a professor at the University of Paris. Also, Robin Williams. """ documents = [Document(page_content=text)]
In the experiment, GPT-4 was used as the base model:
from langchain_openai import ChatOpenAI import getpass import os os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI api key") llm = ChatOpenAI(model='gpt-4o')
First, analyze the information extraction effect without defining a graph pattern:
from langchain_experimental.graph_transformers import LLMGraphTransformer no_schema = LLMGraphTransformer(llm=llm)
Use the asynchronous function aconvert_to_graph_documents to process documents. In LLM extraction scenarios, the advantage of asynchronous processing lies in supporting parallel processing of multiple documents, significantly improving processing efficiency and throughput:
data = await no_schema.aconvert_to_graph_documents(documents)
The graph document structure returned by LLM Graph Transformer is as follows:
[ GraphDocument( nodes=[ Node(id="Marie Curie", type="Person", properties={}), Node(id="Pierre Curie", type="Person", properties={}), Node(id="Nobel Prize", type="Award", properties={}), Node(id="University Of Paris", type="Organization", properties={}), Node(id="Robin Williams", type="Person", properties={}), ], relationships=[ Relationship( source=Node(id="Marie Curie", type="Person", properties={}), target=Node(id="Nobel Prize", type="Award", properties={}), type="WON", properties={}, ), Relationship( source=Node(id="Marie Curie", type="Person", properties={}), target=Node(id="Nobel Prize", type="Award", properties={}), type="WON", properties={}, ), Relationship( source=Node(id="Marie Curie", type="Person", properties={}), target=Node( id="University Of Paris", type="Organization", properties={} ), type="PROFESSOR", properties={}, ), Relationship( source=Node(id="Pierre Curie", type="Person", properties={}), target=Node(id="Nobel Prize", type="Award", properties={}), type="WON", properties={}, ), ], source=Document( metadata={"id": "de3c93515e135ac0e47ca82a4f9b82d8"}, page_content="\nMarie Curie, 7 November 1867 – 4 July 1934, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.\nShe was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.\nHer husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.\nShe was, in 1906, the first woman to become a professor at the University of Paris.\nAlso, Robin Williams!\n", ), ) ]
The graph document includes three main parts: nodes, relationships, and source, which correspond to the extracted nodes, relationships, and source document information, respectively. Using the Neo4j Browser, these output results can be visualized intuitively.
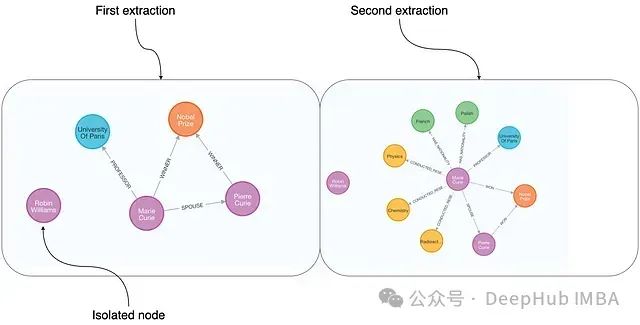
The above image shows the results of two independent extraction processes on the same paragraph of Marie Curie’s text. Here, the GPT-4 model supporting tool-based extraction was used, allowing for the generation of isolated nodes. Since no graph pattern was defined, the LLM autonomously decided the content of the extracted information during runtime, leading to uncertainty in the output results. Even with the same input text, the results of different extraction processes differ in detail. For instance, the left image labels Marie as the WINNER of the Nobel Prize, while the right image uses WON to denote the award relationship.
For models that support tools, the prompt-based extraction mode can be enabled by setting the ignore_tool_usage parameter:
no_schema_prompt = LLMGraphTransformer(llm=llm, ignore_tool_usage=True) data = await no_schema.aconvert_to_graph_documents(documents)
Let’s also perform visual analysis on the results of two independent executions using this method.
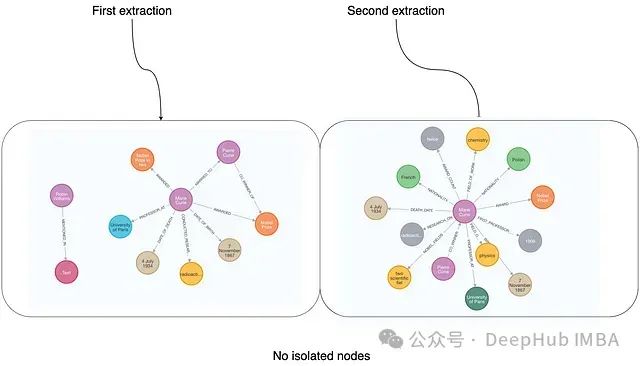
The prompt-based method does not generate isolated nodes, which is a significant difference from the tool mode. However, similar to the previous case, due to the lack of explicit pattern constraints, the output structure still exhibits variability between different runs.
Next, we will explore how to enhance output consistency by defining appropriate graph patterns.
Node Type Definition
Constraining the graph structure is a key technical means to enhance information extraction quality. By precisely defining the graph pattern, the model can be guided to focus on specific entity types and relationship patterns, thereby improving the consistency and predictability of extraction results. A standardized pattern definition not only ensures the standardization of extracted data but also effectively avoids omissions of key information and the introduction of unintended elements.
First, define the expected node types using the allowed_nodes parameter:
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"] nodes_defined = LLMGraphTransformer(llm=llm, allowed_nodes=allowed_nodes) data = await nodes_defined.aconvert_to_graph_documents(documents)
The above code defines five core node types. To evaluate its effect, we will compare and analyze the results of two independent executions:
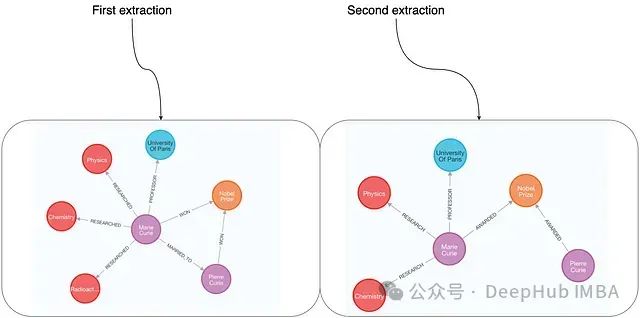
By predefining node types, the consistency of extraction results has significantly improved. However, there are still some detail-level differences, such as the first run recognizing “radioactivity” as a research field, while the second run failed to capture this information.
Since no constraints were placed on relationship types, the results of relationship extraction still exhibit significant variability between different runs. Additionally, the granularity of information captured varies across different runs. For example, the MARRIED_TO relationship between Marie and Pierre was not recognized in both extractions.
Relationship Type Definition
To address the inconsistencies in relationship extraction, it is necessary to introduce a mechanism for defining relationship types. The most basic method is to standardize relationships through a list of available types:
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"] allowed_relationships = ["SPOUSE", "AWARD", "FIELD_OF_RESEARCH", "WORKS_AT", "IN_LOCATION"] rels_defined = LLMGraphTransformer( llm=llm, allowed_nodes=allowed_nodes, allowed_relationships=allowed_relationships ) data = await rels_defined.aconvert_to_graph_documents(documents)
Analyze the results of two independent executions:
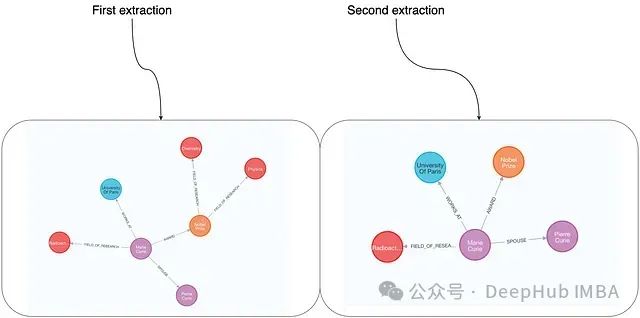
Comparison of the results of two extractions under predefined node and relationship type conditions. Provided by the author.
The dual constraints of node and relationship types significantly enhance the consistency of extraction results. For example, Marie’s award information, spousal relationship, and work relationship at the University of Paris were consistently extracted across different runs. However, since relationship definitions were made in a generic list format, there remains some variability, such as the FIELD_OF_RESEARCH relationship potentially connecting Person and ResearchField, or Award and ResearchField. Due to the lack of definition for relationship directionality, inconsistencies may arise in the direction of relationships in the extraction results.
To further enhance the accuracy of relationship extraction, we introduced a more refined relationship definition method:
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"] allowed_relationships = [ ("Person", "SPOUSE", "Person"), ("Person", "AWARD", "Award"), ("Person", "WORKS_AT", "Organization"), ("Organization", "IN_LOCATION", "Location"), ("Person", "FIELD_OF_RESEARCH", "ResearchField") ] rels_defined = LLMGraphTransformer( llm=llm, allowed_nodes=allowed_nodes, allowed_relationships=allowed_relationships ) data = await rels_defined.aconvert_to_graph_documents(documents)
Here, relationships are defined in the form of triples, specifying the source node type, relationship type, and target node type, thereby achieving stricter relationship constraints. Let’s analyze the extraction results using the triple relationship definition:

The triple relationship definition method provides stricter pattern constraints for the extraction process, significantly improving consistency across runs. However, considering the inherent characteristics of LLMs, the completeness of extracted details may still vary. For instance, the right-side image shows information about Pierre receiving the Nobel Prize, while the left-side image fails to capture this detail.
Property Definition Mechanism
The final optimization layer of the graph pattern is the definition of properties for nodes and relationships. The system provides two property definition methods:
The first method is to set node_properties or relationship_properties to true, allowing the LLM to autonomously decide which properties to extract:
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"] allowed_relationships = [ ("Person", "SPOUSE", "Person"), ("Person", "AWARD", "Award"), ("Person", "WORKS_AT", "Organization"), ("Organization", "IN_LOCATION", "Location"), ("Person", "FIELD_OF_RESEARCH", "ResearchField") ] node_properties=True relationship_properties=True props_defined = LLMGraphTransformer( llm=llm, allowed_nodes=allowed_nodes, allowed_relationships=allowed_relationships, node_properties=node_properties, relationship_properties=relationship_properties ) data = await props_defined.aconvert_to_graph_documents(documents) graph.add_graph_documents(data)
Analyze the extraction results:
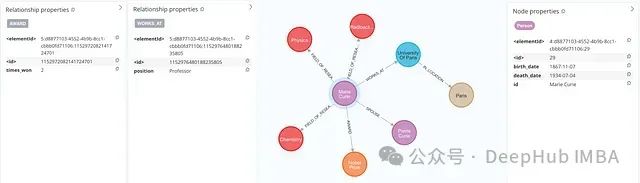
By enabling the LLM’s autonomous property extraction capability, the system successfully captured multiple important properties. For example, Marie Curie’s birth and death dates, her professorship at the University of Paris, and her multiple Nobel Prize achievements. These supplementary properties significantly enhance the information density of the graph.
The second method is to explicitly define the node and relationship properties to be extracted:
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"] allowed_relationships = [ ("Person", "SPOUSE", "Person"), ("Person", "AWARD", "Award"), ("Person", "WORKS_AT", "Organization"), ("Organization", "IN_LOCATION", "Location"), ("Person", "FIELD_OF_RESEARCH", "ResearchField") ] node_properties=["birth_date", "death_date"] relationship_properties=["start_date"] props_defined = LLMGraphTransformer( llm=llm, allowed_nodes=allowed_nodes, allowed_relationships=allowed_relationships, node_properties=node_properties, relationship_properties=relationship_properties ) data = await props_defined.aconvert_to_graph_documents(documents) graph.add_graph_documents(data)
Properties are defined through two independent lists. Check the extraction results:
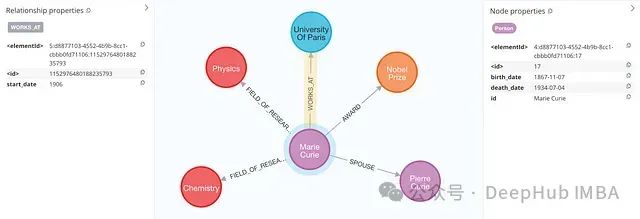
Under the predefined property pattern, the system accurately extracted the birth and death dates of individuals. Additionally, it successfully captured the start date information for Marie’s teaching position at the University of Paris.
Although property extraction significantly enriches the information content of the graph, the current implementation has the following technical limitations:
-
Property extraction only supports the tool-based mode; -
All property values are uniformly processed as string types; -
Property definitions are shared globally, and cannot be customized for specific node labels or relationship types; -
Lack of a customization mechanism for property descriptions, which prevents the provision of more precise extraction guidance for the LLM.
Strict Mode Implementation
Although we strive to ensure that the LLM adheres to predefined patterns through carefully designed prompt engineering, practice has shown that particularly for lower-performing models, achieving complete compliance with instructions remains challenging. Therefore, we introduce strict_mode as a post-processing mechanism to filter extraction results that do not conform to the predefined graph pattern, ensuring the regularity of the output. strict_mode is enabled by default and can be turned off using the following configuration:
LLMGraphTransformer( llm=llm, allowed_nodes=allowed_nodes, allowed_relationships=allowed_relationships, strict_mode=False )
When strict mode is turned off, the LLM may generate node or relationship types outside the predefined pattern, and this flexibility may lead to uncertainty in the output structure.
Graph Document Database Import
The graph documents extracted by LLM Graph Transformer can be imported into graph databases such as Neo4j using the add_graph_documents method to support subsequent analysis and applications. The system provides various import options to meet different scenario needs.
Basic Import Implementation
The simplest import method is as follows:
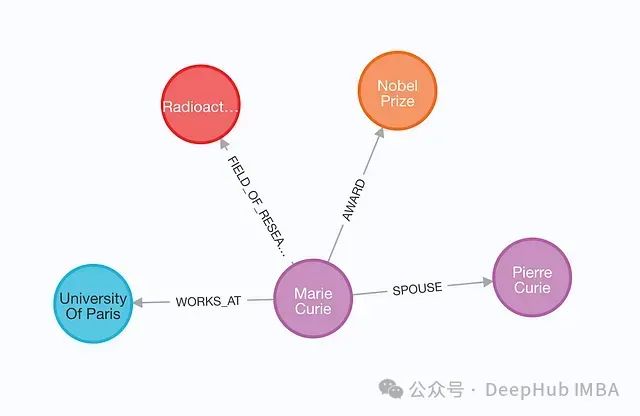
graph.add_graph_documents(graph_documents)
This method directly imports all node and relationship data from the graph document. All the examples mentioned earlier in this article used this method for result demonstration.
Basic Entity Tag Mechanism
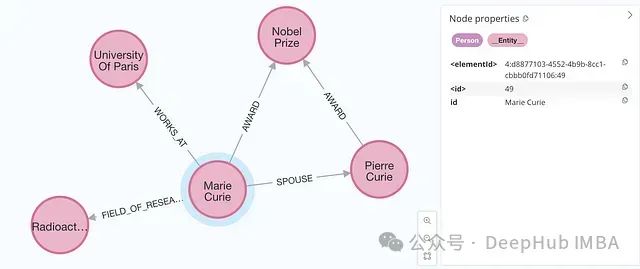
Graph databases typically use indexes to optimize data import and retrieval performance. Taking Neo4j as an example, indexes can only be built on specific node labels. Since it is impossible to predict all possible node labels, the system adds a unified secondary label to each node through the baseEntityLabel parameter, thereby achieving efficient use of indexes:
graph.add_graph_documents(graph_documents, baseEntityLabel=True)
When this parameter is enabled, each node will receive an additional __Entity__ label.
Source Document Association Mechanism
The system also supports importing source document information for entities, facilitating the tracking of the text source of the entities. This function can be enabled through the include_source parameter:
graph.add_graph_documents(graph_documents, include_source=True)
Example of import results:

The blue nodes in the image represent the source documents, which are connected to the extracted entities through the MENTIONS relationship. This design supports a mixed application of structured and unstructured retrieval.
Conclusion
This article delves into the LLM Graph Transformer framework of LangChain and its dual-mode implementation mechanism for text-to-graph conversion. As the main technical route, the tool-based mode leverages structured output and function call capabilities, effectively reducing the complexity of prompt engineering and supporting property extraction. The prompt-based mode, on the other hand, provides an alternative for models that do not support tool calls, guiding model behavior through few-shot examples.
Research shows that precisely defined graph patterns (including node types, relationship types, and their constraints) can significantly enhance the consistency and reliability of extraction results. Regardless of the mode used, the LLM Graph Transformer provides a reliable technical solution for the structured representation of unstructured data, effectively supporting RAG applications and complex query processing.
The code for this article can be found here, interested parties can check it out:
https://github.com/tomasonjo/blogs/blob/master/llm/llm_graph_transformer_in_depth.ipynb
Author: Tomaz Bratanic
About Us
Data Party THU, as a data science public account, backed by the Tsinghua University Big Data Research Center, shares cutting-edge data science and big data technology innovation research dynamics, continuously disseminates data science knowledge, and strives to build a platform for gathering data talents and create the strongest group in China’s big data.

Sina Weibo: @数据派THU
WeChat Video Number: 数据派THU
Today’s Headlines: 数据派THU