Author: Leonie Monigatti
Translation: Zhao Jiankai
Proofreading: zrx
This article is approximately 4800 words long and is recommended for a 7-minute read.
This article introduces you to the LangChain framework.
Tags: LangChain, LLM Application, OpenAI
Since the release of ChatGPT, large language models (LLMs) have gained significant popularity. Even if you may not have enough funding and computational resources to train an LLM from scratch in your basement, you can still build some cool things using pre-trained LLMs, such as:
-
A chatbot tailored to your specific data
-
A personal assistant that interacts with the outside world
-
Summaries of your documents or code
With its quirky APIs and rapid engineering design, LLMs are changing the way we build AI products. This is why new development tools are emerging everywhere under the term “LLMOpS”, one of which is LangChain (https://github.com/hwchase17/langchain).
What is LangChain?
LangChain is a framework designed to help you more easily build LLM-supported applications by providing you with:
-
A universal interface for various foundational models (see Models);
-
A framework to help you manage prompts (see Prompts);
-
And a central interface for long-term memory (see Memory), external data (see Index), other LLMs (see Chains), and other agents that LLMs cannot handle (e.g., computation or search).
This is an open-source project created by Harrison Chase (GitHub repository).
Due to the many features of LangChain, we will discuss the six key modules of LangChain in this article to give you a better understanding of its capabilities.
Setting Up the Environment
In this tutorial, you will need to install the langchain Python package and be ready with all relevant API keys. Before installing the langchain package, ensure your Python version is ≥ 3.8.1 and < 4.0.
To install the langchain Python package, you can use pip.
In this tutorial, we are using version 0.0.147. The GitHub repository is very active; thus, ensure you have the current version. Once everything is set up, import the langchain Python package.
Building applications with LLMs requires API keys for certain services you will use, and some APIs are paid.
LLM Provider (Required): You first need the API key from the LLM provider. We are currently experiencing an “AI Linux moment” where developers must choose between proprietary or open-source foundational models based mainly on performance and cost trade-offs.

LLM Providers: Proprietary and open-source foundational models (author’s image inspired by Fiddler.ai, first published on W & B’s blog)
Proprietary Models are closed foundational models owned by companies with large expert teams and substantial AI budgets. They are typically larger than open-source models and thus offer better performance, but they also come with expensive APIs. Examples of proprietary model providers include OpenAI, co:here, AI21 Labs, or Anthropic. Most available LangChain tutorials use OpenAI, but note that the OpenAI API (which is not expensive for experiments, but it is not free). To obtain an OpenAI API key, you need an OpenAI account and then create a “New Key” under API Keys.
import os
os.environ["OPENAI_API_KEY"] = ... # insert your API_TOKEN here
Open-Source Models are generally smaller models that are less capable than proprietary models but more cost-effective. Examples of open-source models include:
As a community hub, many open-source models are organized and hosted on Hugging Face. To obtain a Hugging Face API key, you need a Hugging Face account and create a “New Token” under Access Tokens.
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = ... # insert your API_TOKEN here
For open-source LLMs, you can use Hugging Face for free, but you will be limited to lower-performing smaller LLMs.
Personal Notes: You can try open-source foundational models here. I attempted to make this tutorial work only with open-source models hosted on Hugging Face under regular accounts (google/flan-t5-xl and sentence transformer/all-MiniLM-L6-v2). It works for most examples, but getting some examples to work was also a pain. In the end, I set up a paid account with OpenAI because most examples in LangChain seem to be optimized for the OpenAI API. Overall, running some experiments for this tutorial cost me about $1.
Vector Database (Optional): If you want to use a specific vector database like Pinecone, Weaviate, or Milvus, you need to register with them for an API key and confirm their pricing. In this tutorial, we are using Faiss, which does not require registration.
Tools (Optional): Depending on the tools you want the LLM to interact with (e.g., OpenWeatherMap or SerpAPI), you may need to register with them for an API key and check their pricing. In this tutorial, we are only using tools that do not require API keys.
What Can We Do with LangChain?
The package provides a universal interface for many foundational models, allows for prompt management, and serves as a central interface for other components (such as prompt templates, other LLMs, external data, and other tools) through agents. At the time of writing, LangChain (version 0.0.147) covers six modules:
-
Models: Choose from different LLMs and embedding models
-
-
Input Chains: Combine LLMs with other components
-
Index: Access external data
-
Memory: Remember previous conversations
-
Agents: Access other tools
The code examples in the following sections are copied and modified from the LangChain documentation.
Models: Choose from Different LLMs and Embedding Models
Currently, many different LLMs are emerging. LangChain provides integration for various models and a simplified interface for all models. LangChain distinguishes three types of models, each with different inputs and outputs:
-
LLMs take strings as input (prompts) and output strings (completions).
# Proprietary LLM from e.g. OpenAI
# pip install openai
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
# Alternatively, open-source LLM hosted on Hugging Face
# pip install huggingface_hub
from langchain import HuggingFaceHub
llm = HuggingFaceHub(repo_id = "google/flan-t5-xl")
# The LLM takes a prompt as an input and outputs a completion
prompt = "Alice has a parrot. What animal is Alice's pet?"
completion = llm(prompt)
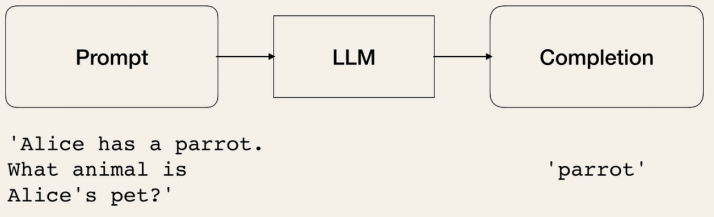
LLM Models
-
Chat Models are similar to LLMs. They take a list of chat messages as input and return chat messages.
-
Text Embedding Models take text input and return a list of floats (embeddings), which are numerical representations of the input text. Embeddings help extract information from text. This information can then be used, for example, to calculate similarity between texts (e.g., movie summaries).
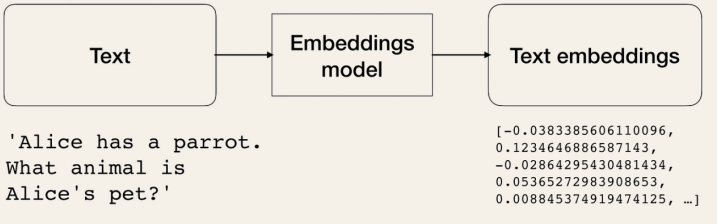
Text Embedding Models
Prompts: Managing LLM Inputs
LLMs have quirky APIs. Although inputting prompts to LLMs in natural language should feel intuitive, a lot of adjustments are needed to the prompts before obtaining the desired output from the LLM. This process is called prompt engineering. Once you have a good prompt, you may want to use it as a template for other purposes. Therefore, LangChain provides you with what is called a prompt template to help you build prompts from multiple components.
from langchain import PromptTemplate
template = "What is a good name for a company that makes {product}?"
prompt = PromptTemplate( input_variables=["product"], template=template,)
prompt.format(product="colorful socks")
The above prompt can be seen as Zero-shot Learning (zero-shot learning is a setting where the model can learn to recognize things it has not explicitly seen during training), and you hope the LLM has been trained on sufficient relevant data to provide satisfactory results. Another trick to improve LLM output is to add some examples in the prompt and make it a few-shot setting.
from langchain import PromptTemplate, FewShotPromptTemplate
examples = [ {"word": "happy", "antonym": "sad"}, {"word": "tall", "antonym": "short"},]
example_template = """Word: {word}Antonym: {antonym}\n"""
example_prompt = PromptTemplate( input_variables=["word", "antonym"], template=example_template,)
few_shot_prompt = FewShotPromptTemplate( examples=examples, example_prompt=example_prompt, prefix="Give the antonym of every input", suffix="Word: {input}\nAntonym:", input_variables=["input"], example_separator="\n",)
few_shot_prompt.format(input="big")
The above code generates a prompt template and composes the following prompt based on the provided examples and input:
Give the antonym of every input
Word: happyAntonym: sad
Word: tallAntonym: short
Word: bigAntonym:
Chain: Combining LLMs with Other Components
In LangChain, a Chain simply describes the process of combining LLMs with other components to create applications. Some examples include: combining LLMs with prompt templates (see this section), sequentially combining multiple LLMs by using the output of the first LLM as the input for the second LLM (see this section), and combining LLMs with external data, for example, for question answering (see Index), and combining LLMs with long-term memory, for example, for chat history (see Memory). We created a prompt template when we wanted to use it with our LLM; we can use LLMChain as follows:
from langchain.chains import LLMChain
chain = LLMChain(llm = llm, prompt = prompt)
# Run the chain only specifying the input variable.chain.run("colorful socks")
If we want to use the output of this first LLM as the input for the second LLM, we can use a SimpleSequentialChain:
from langchain.chains import LLMChain, SimpleSequentialChain
# Define the first chain as in the previous code example# ...
# Create a second chain with a prompt template and an LLMsecond_prompt = PromptTemplate( input_variables=["company_name"], template="Write a catchphrase for the following company: {company_name}",)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Combine the first and the second chain overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Run the chain specifying only the input variable for the first chain.catchphrase = overall_chain.run("colorful socks")

Example Result
Index: Accessing External Data
One limitation of LLMs is their lack of contextual information (e.g., access to specific documents or emails). You can solve this issue by allowing LLMs to access specific external data. To do this, you first need to use a document loader to load external data. LangChain provides various loaders for different types of documents, from PDFs and emails to websites and YouTube videos. Let’s load some external data from a YouTube video. If you want to load a large text document and split it with a text splitter, you can refer to the official documentation.
# pip install youtube-transcript-api
# pip install pytube
from langchain.document_loaders import YoutubeLoader
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=dQw4w9WgXcQ")
documents = loader.load()
Now that you have prepared external data as documents, you can index them using a text embedding model (see Models) in a vector database (VectorStore). Popular vector databases include Pinecone, Weaviate, and Milvus. In this article, we are using Faiss, as it does not require an API key.
# pip install faiss-cpu
from langchain.vectorstores import FAISS
# create the vectorestore to use as the index
db = FAISS.from_documents(documents, embeddings)
Your documents (in this case, the video) are now stored as embeddings in the vector store. Now you can do various things with this external data. Let’s use it for a question-answering task with an information retriever:
from langchain.chains import RetrievalQA
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True)
query = "What am I never going to do?"
result = qa({"query": query})
print(result['result'])

Example Result
Memory: Remembering Previous Conversations
For applications like chatbots, being able to remember previous conversations is crucial. However, by default, LLMs have no long-term memory unless you input the chat history.
 Comparison of Chatbots with and without Memory
Comparison of Chatbots with and without Memory
LangChain addresses this issue by providing several different options for handling chat history:
-
-
Retain the latest k conversations
-
In this example, we will use ConversationChain as the session memory for this application.
from langchain import ConversationChain
conversation = ConversationChain(llm=llm, verbose=True)
conversation.predict(input="Alice has a parrot.")
conversation.predict(input="Bob has two cats.")
conversation.predict(input="How many pets do Alice and Bob have?")
This will generate the right-hand dialogue in the above image. Without the ConversationChain to maintain memory, the dialogue would look like the left-hand dialogue in the above image.
Agents: Accessing Other Tools
Although LLMs are very powerful, they still have some limitations: they lack contextual information (e.g., access to specific knowledge not included in the training data), they may become outdated quickly (e.g., GPT-4 was trained on data before September 2021), and they are not good at math.
Because LLMs may hallucinate about tasks they cannot complete, we need to give them access to supplementary tools, such as search (e.g., Google Search), calculators (e.g., Python REPL or Wolfram Alpha), and lookup (e.g., Wikipedia). Additionally, we need agents to decide which tools to use to complete tasks based on the output of the LLM.
Note that certain LLMs (e.g., google/flan-t5-xl) are not suitable for the following examples as they do not follow the conversation-reaction-description template. This is why I set up a paid account with OpenAI and switched to the OpenAI API.
Below is an example where the agent first looks up Obama’s birth date on Wikipedia and then uses a calculator to calculate his age in 2022.
# pip install wikipedia
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("When was Barack Obama born? How old was he in 2022?")
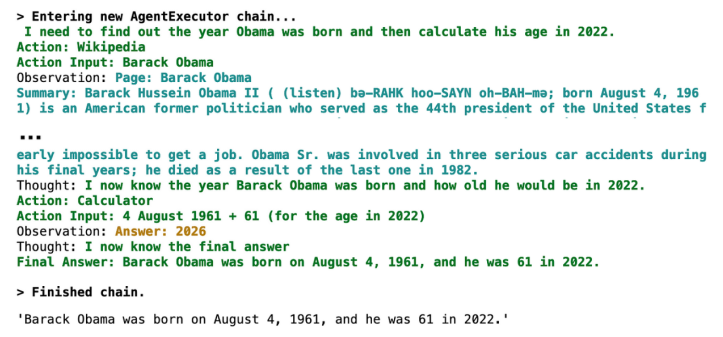
Just a few months ago, all of us (or at least most of us) were impressed by the capabilities of ChatGPT. Now, new developer tools like LangChain allow us to build equally impressive prototypes on our laptops in just a few hours—these are truly exciting times!
LangChain is an open-source Python library that enables anyone who can write code to build LLM-powered applications. The package provides a universal interface for many foundational models, allows for prompt management, and serves as a central interface for other components (such as prompt templates, other LLMs, external data, and other tools) through agents. The library offers more features than mentioned in this article. With the current pace of development, this article may also become outdated within a month.
At the time of writing, I noticed that the library and documentation revolve around the OpenAI API. Although many examples use the open-source foundational model google/flan-t5-xl, I opted for the OpenAI API. While not free, trying the OpenAI API in this article cost me about $1.
Getting Started with LangChain: A Beginner’s Guide to Building LLM-Powered Applications
https://towardsdatascience.com/getting-started-with-langchain-a-beginners-guide-to-building-llm-powered-applications-95fc8898732c
Zhao Jiankai, a graduate student in Management Science and Engineering at Zhejiang University, focuses on the application of machine learning in social commerce.
Translation Group Recruitment Information
Job Description: Requires a meticulous heart to translate selected foreign articles into fluent Chinese. If you are an overseas student in data science/statistics/computer-related fields, or working abroad in related jobs, or are confident in your foreign language proficiency, you are welcome to join the translation team.
You will get: Regular translation training to improve volunteers’ translation skills, enhance awareness of cutting-edge data science, and overseas friends can stay in touch with domestic technological application development. The THU Datapi industry-university-research background offers good development opportunities for volunteers.
Other Benefits: You will have the opportunity to work with data scientists from renowned companies, students from prestigious universities like Peking University and Tsinghua University, and other overseas institutions.
Click on the end of the article “Read the Original” to join the Datapi team~
Reprint Notice
For reprints, please prominently indicate the author and source at the beginning (transferred from: Datapi ID: DatapiTHU), and place a prominent QR code of Datapi at the end of the article. For articles with original markings, please send [Article Name – Pending Authorized Public Account Name and ID] to the contact email to apply for whitelist authorization and edit according to requirements.
Please feedback the link to the contact email after publication (see below). Unauthorized reprints and adaptations will be pursued legally.
Click “Read the Original” to embrace organization


