Written by/Zhuang Yueting
This article is divided into four parts: first, the research background and content; second, the introduction of the current two research approaches; third, the research foundation and progress made; and finally, the conclusion and outlook.
1 Research Background and Content
Currently, large models/multi-modal large language models (LLM/MLLM) have reached new heights in multi-modal understanding, reasoning, and cognitive decision-making capabilities, with performances on various tasks even exceeding human levels. As shown in Figure 1, the work done by companies such as OpenAI and Google is now multi-modal, with some achieving very high levels, and the parameter count continuously growing from billions to trillions. However, large models are not omnipotent; they are like powerful but resource-limited AI ‘giants’. According to the Scaling Law, once the parameter scale increases, many new capabilities will emerge, but at the same time, there are issues such as hallucinations, low reasoning efficiency, high costs, and a lack of specialized capabilities.
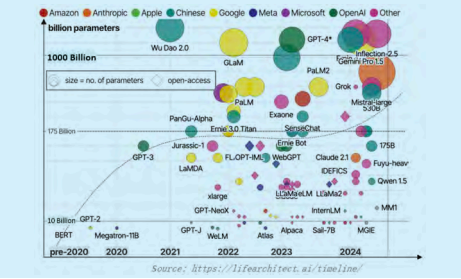
Figure 1 Development Trends of Large Models
Currently, the AI community has accumulated many small models (SLM). Although these small models are smaller in scale, they are rich, diverse, lightweight, efficient, highly specialized, and capable of real-time learning, performing excellently on specific tasks, so they should not be overlooked. For example, Hugging Face and the MoDa community host over 300,000 small models covering various tasks across modalities such as images, videos, languages, audio, and 3D, with many similar small models available domestically.
Therefore, we propose that large and small models collaborate closely, complementing each other’s strengths to accomplish cross-modal intelligent tasks more accurately, efficiently, and at lower costs. By exploring collaboration methods between large and small models, we aim to overcome the limitations of single models and fully leverage their respective advantages to achieve a more efficient and precise cross-media intelligent system encompassing perception, understanding, reasoning, and decision-making. However, constructing such intelligent systems faces three challenges.
Challenge 1: Unclear Mechanism of Large and Small Model Collaboration
Although the trend of collaboration between large and small models is becoming increasingly evident, it is still in its infancy, primarily characterized by unidirectional calls and a lack of exploration of more complex collaboration mechanisms. As shown in Figure 2, the image generation in GPT-4 actually calls the large model DALL-E 3, which generates images from text; in the ecosystem created by GPT Store, GPT also widely calls specialized models. However, the relationship between large and small models is clearly not a simple calling and being called relationship. How to transition from ‘unidirectional calling’ to ‘networked collaboration’ is the first research challenge.
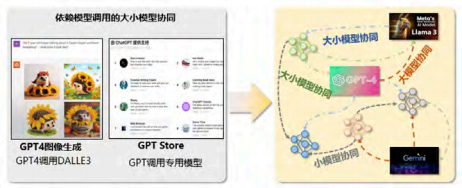
Figure 2 Transition from Unidirectional Calls to Networked Collaboration
Challenge 2: Lack of a Unified Computing Framework
Currently, large and small models are usually trained independently and then used in a chained manner. Independent training means that their training data is different, and after generalization, chaining them together may lead to issues. Therefore, a better approach would be to adopt a unified training and collaborative reasoning method. How to transition from ‘independent training, chained use’ to ‘unified training, collaborative reasoning’, i.e., designing a unified training reasoning computing framework (see Figure 3), is the second challenge.
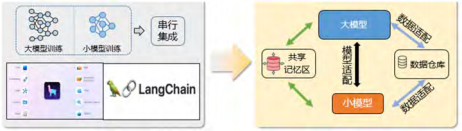
Figure 3 Simple Deployment of Large and Small Models to a Unified Computing Framework
Challenge 3: Difficulty in Integrating Knowledge from Large and Small Models
Large and small models can be seen as heterogeneous knowledge representations. Different models imply different expression methods, including differences in model scale, knowledge hierarchy between general and specialized models, and differences in data modalities. Therefore, how to transition from ‘single model knowledge’ to ‘cross-model knowledge integration’ is the third challenge we face (see Figure 4).
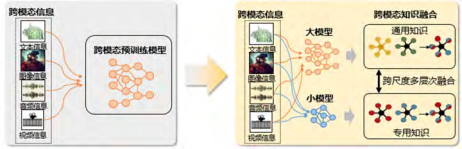
Figure 4 Transition from ‘Single Model Knowledge’ to ‘Cross-Model Knowledge Integration’
The framework for collaboration between large and small models aims to integrate the broad knowledge of large models with the specialized capabilities of small models. To achieve this, it is necessary to establish knowledge integration based on planning, division of labor, and collaboration mechanisms, organically combining the foundational knowledge of large models with the specialized knowledge of small models. Specifically, an overall strategy should first be formulated to guide the collaboration of large and small models; the responsibilities and tasks of large and small models should be clarified, and communication mechanisms and data exchange methods between models should be established. By integrating the broad understanding of large models with the specialized knowledge of small models, task accuracy can be significantly improved; the efficiency of overall processing can be enhanced by leveraging the efficiency of small models, thereby reducing computational costs through reasonable task allocation; in specialized fields, combining the reasoning capabilities of large models with the specialized knowledge of small models can achieve a performance leap, obtaining a result where 1+1>2.
In a review article by Wang Fali et al. published in November 2024 (arXiv: 2411.03350), there is a download statistics for large and small models, which shows that the download volume of small models far exceeds that of large models, indicating that small models are still widely used in the era of large models.
Therefore, we study the foundational theories of large and small model collaboration, propose a unified training and collaborative reasoning computing framework, and integrate multiple knowledge expressions such as foundational large models, specialized small models, expert knowledge, and knowledge graphs to accomplish cross-modal knowledge fusion computing more accurately, efficiently, and at lower costs, achieving artificial intelligence systems with perception, understanding, reasoning, and decision-making capabilities. This is our research goal, which includes four specific topics, as shown in Figure 5.
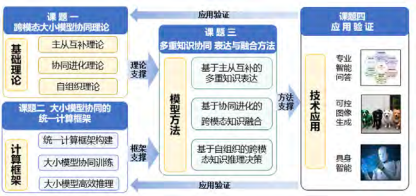
Figure 5 Overall Research Content and Ideas
2 Research Approaches
The collaboration between large and small models has two approaches, which are described below.
2.1 Small Model Enhancing Large Model Methods
Small model enhancing large model methods include data optimization, weak-to-strong learning, capability expansion, and reasoning efficiency improvement.
(1) Data Optimization: Using SLMs to filter and reconstruct pre-training and instruction adjustment data to improve data quality. For example, Deepmind and Stanford University use small models for data weighting (arXiv: 2305.10429) to improve the quality of large-scale pre-training data and optimize large models.
(2) Weak-to-Strong Learning: This involves using smaller models to guide and supervise more powerful LLMs to achieve knowledge transfer. For example, the Weak-to-Strong paradigm (arXiv:2312.09390) uses small models to guide large models (OpenAI) to enable mutual teaching and learning among machines without complete or reliable human supervision, training human-level large models through weak supervision from small models, proposing ‘generalization from weak to strong’ by using weak models to supervise strong models.
(3) Capability Expansion: Expanding the capabilities of large models through small models or external tools. For example, Toolformer (arXiv: 2302.04761) enables language models to autonomously decide when and how to use external tools (such as calculators, Q&A systems, search engines, translation systems, and calendars) to assist in task completion through self-supervised learning.
(4) Reasoning Efficiency Improvement: Combining different sized models through model cascading or model routing to enhance reasoning efficiency. As shown in Figure 6, the Hybrid LLM (arXiv: 2404.14618) adopts a mixed reasoning method that combines the advantages of large and small models, dynamically allocating queries to large models based on predicted query difficulty and desired quality levels through a router (router) small model, thus fully leveraging their strengths.
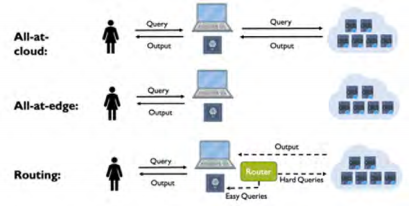
Figure 6 Mixed Reasoning Method
Additionally, proxy fine-tuning (arXiv:2401.08565) is a method that adjusts small models (expert models). By comparing the prediction results of expert models and unadjusted models (anti-expert models), the differences between the two are fed back into the predictions of large models, guiding large models to adjust towards more accurate directions.
2.2 Large Model Enhancing Small Model Methods
Large model enhancing small model methods mainly include knowledge distillation and data synthesis.
(1) Knowledge Distillation: This includes both white-box and black-box methods for transferring knowledge from large models to small models. For example, distilling TinyLLM (arXiv:2402.04616) from multiple LLMs to learn diverse knowledge and reasoning skills (see Figure 7). This involves integrating reasons from different teacher models into a unified multi-task instruction adjustment framework. Not only does it learn to predict correct answers, but it also learns the reasoning produced by the teacher models.
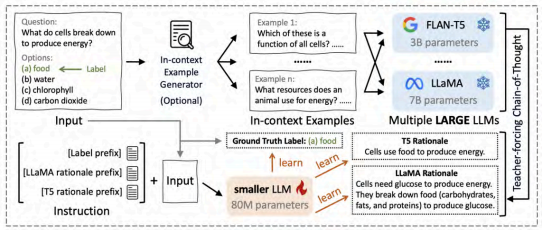
Figure 7 TinyLLM
(2) Data Synthesis: Utilizing large models to generate high-quality training data or enhance existing data, which can significantly improve the performance of small models, bringing them close to or even exceeding large models on specific tasks. For example, Zerogen (EMNLP 2022) proposes a zero-shot learning framework that generates data using large models and trains small task models without human-annotated data, achieving efficient reasoning and deployment. Figure 8 is from Zerogen.
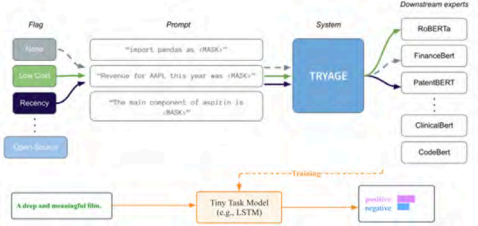
Figure 8 Using LLM to Generate Datasets for Solving Downstream Tasks
3 Research Foundation and Progress
3.1 HuggingGPT: A Typical Example of Large and Small Model Collaboration
In 2023, we proposed HuggingGPT (NeurIPS2023) as a typical example of large and small model collaboration. Although there are now many AI models available for various fields and modalities, they cannot independently handle tasks and lack a universal framework capable of solving problems in complex multi-domain and multi-modal scenarios. HuggingGPT uses language as an interface, leveraging LLMs as controllers to manage existing AI models and solve complex AI tasks. For instance, ChatGPT can handle text-to-text tasks but cannot manage any cross-modal tasks. Therefore, we use large language models (ChatGPT) as controllers to plan and call small models. As shown in Figure 9, HuggingGPT, based on the collaboration of large and small models, can produce excellent cross-modal perception and reasoning capabilities.
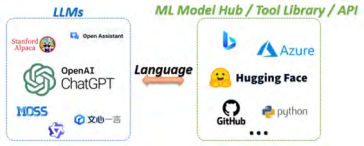
Figure 9 Large Language Models as Tools to Plan and Call Small Models
HuggingGPT was published at NeurIPS 2023 and has been cited over 900 times, including references in papers by Turing Award winners Bengio and Hinton (2024 Nobel Prize winner). Stanford guest professor Andrew Ng, Nvidia GEAR Lab director Jim Fan, OpenAI researchers, and other scientists have recommended this paper in their blog posts; the GitHub repository has received over 20,000 stars and won the 2022-2023 Top-100 Open Source Achievement Award from the International Testing Committee. The demo system was ranked among the Top 10 on Hugging Face Space and has had a significant impact in the industry, with teams like Hugging Face, Langchain, and ModelScope launching TransformersAgent, Langchain HuggingGPT, and ModelScope Agent.
3.2 Large-Scale Multi-Modal Pre-Trained Models
We have conducted extensive work on multi-modal pre-trained large models and multi-modal generative models to handle any cross-modal tasks. Therefore, we use large language models (ChatGPT) as controllers to plan and call small models. As shown in Figure 9, HuggingGPT, based on the collaboration of large and small models, can produce excellent cross-modal perception and reasoning capabilities. In October 2022, we released the collaborative result with Huawei—multi-modal pre-trained large model LOUPE (NeurIPS 2022), which surpassed OpenAI CLIP in multi-modal fine-grained semantic understanding capabilities several times and won the Huawei Cloud Excellent Innovation Cooperation Team Award. In September 2023, we developed a multi-modal pre-trained large model—Cheetor (ICLR 2024 Spotlight Top 5%), which proposed a controllable knowledge injection mechanism, supporting interleaved multi-modal intelligent Q&A, achieving the best performance on multiple multi-modal instruction understanding datasets such as MME; in February 2024, we developed a multi-modal generative large model—Morph MLLM (ICML 2024 Spotlight), which significantly outperformed existing models on multiple image-text content generation and image editing datasets. These works lay an important foundation for future research on large and small model collaboration.
3.3 Large and Small Model Collaboration
3.3.1 TeamLoRA
The multi-LoRA architecture was proposed to address performance deficiencies in multi-dimensional task scenarios. The naive multi-LoRA architecture introduces a multiplication of matrix operation counts, greatly increasing training costs and inference delays, contrary to the high-efficiency characteristics of PEFT methods. The multi-LoRA architecture usually employs gating mechanisms to determine the participation level of experts, which may lead to load imbalance and overconfidence, affecting the effectiveness of integrating and transferring expert knowledge in multi-task learning.
Our proposed TeamLoRA (arXiv:2408.09856) introduces collaboration and competition modules to achieve a more efficient and accurate PEFT paradigm. The efficient collaboration module designs a novel knowledge-sharing and organization mechanism, appropriately reducing the scale of matrix operations, thus improving training and inference speed. The effective competition module utilizes a game-theory-based interaction mechanism, encouraging experts to transfer corresponding domain-specific knowledge when facing diverse downstream tasks, thereby enhancing performance.
Comparative results with existing models show that TeamLoRA achieves significant performance improvements in both large language models and multi-modal large models; compared to the multi-LoRA architecture, it reduces training time by approximately 30% on average and achieves 1.4 times faster inference responses.
3.3.2 HyperLLaVA
The current multi-modal large model paradigms such as LLaVA often adopt static networks (fixed parameters) to achieve alignment of visual-text features and multi-modal instruction fine-tuning. However, this learning strategy with shared static parameters presents interference between tasks, limiting the model’s performance in handling cross-scenario multi-tasking. We propose HyperLLaVA (arXiv:2403.13447), introducing dynamic expert models for dynamic learning with multi-modal large models. The introduced visual expert model can adaptively extract visual features based on image inputs, achieving dynamic visual-text projection; the introduced language expert model can capture and analyze the correlations of multi-task scenarios, utilizing dynamic LLM parameters for sample-level instruction fine-tuning. In this paper, we propose a comprehensive multi-modal task benchmark (CMT), covering seven categories of tasks: Visual QA, Visual Captioning Spatial Inference, Detailed Description, Visual Storytelling, Knowledge OCR, and Text-Rich Images QA; the training set contains 505,405 instruction groups; the test set contains 1,149 instruction groups.
Compared to LLaVA-1.5, the HyperLLaVA-7B model achieves optimal results on 12 benchmarks, while the HyperLLaVA-13B model achieves optimal results on 10 benchmarks; both HyperLLaVA-7B and HyperLLaVA-13B achieve optimal results on the CMT benchmark.
3.3.3 TaskBench
Evaluating the effectiveness of the collaboration process between large and small models is a crucial yet challenging task, involving task planning, tool selection, and parameter prediction during the collaboration process. Due to the complexity of the evaluation system and the lack of high-quality annotated data, accurately assessing the effectiveness of large models calling small models and optimizing them has been difficult. To address this, we propose TaskBench (NeurIPS 2024), a dedicated evaluation framework for large and small model collaboration and large model task automation.
TaskBench designs knowledge-guided instruction data generation and multi-level evaluation methods to achieve knowledge-based reverse generation of instruction data. By constructing a tool-oriented knowledge graph, a multi-level evaluation system covering task planning, tool invocation, and parameter parsing is established. Through TaskBench, the performance of large and small model collaboration in multi-task scenarios can be comprehensively evaluated, and this evaluation framework and its data generation mechanism can optimize the task processing capabilities of large language models, significantly contributing to the research on large and small model collaboration in complex multi-task scenarios.
3.3.4 Data-Copilot
In industries such as energy, meteorology, finance, and retail, massive amounts of structured data are generated daily, but current large language models cannot directly process this vast structured data and also pose risks of data leakage. Therefore, we designed a system called Data-Copilot (arXiv:2306.07209) that understands natural language and facilitates interaction for data management and analysis. Facing the demands of processing large volumes of dynamic data and sensitive information, Data-Copilot parses user natural language commands through large models to generate task plans, while small models handle specific data operations and tool invocation, achieving efficient and dynamic data management and analysis.
By leveraging the collaboration of large and small models, Data-Copilot not only significantly enhances the efficiency of structured data analysis but also enables natural language-driven interaction and intelligent feedback, providing convenient intelligent solutions for energy scheduling, meteorological early warning, financial risk control, and retail management.
3.3.5 Data Shunt
As shown in Figure 10, Prompt Pruning (PP) utilizes the predictions of small models to refine the prediction space of large models. By integrating the prediction confidence of small models into prompts, the large model’s ability to discern other distributions can be enhanced. Prompt Transferring (PT) decomposes complex tasks into multiple sub-tasks, some of which can be handled by small models. This allows the large model to focus on the more challenging sub-tasks, thereby improving overall performance.
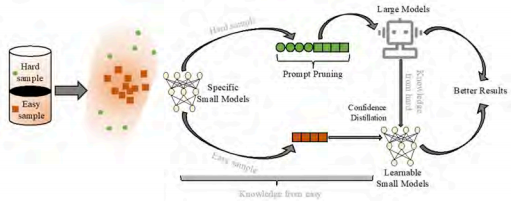
Figure 10 Data Shunt System
The large model performs 2-Stage Confidence Distillation on the small model, conducting knowledge distillation based on the confidence levels of both small and large models, imparting the knowledge of the large model to the small model while preventing the small model from forgetting the knowledge acquired during training.
In the data shunt (arXiv:2406.15471), DS+ utilizes the confidence of small models to decide whether input data should be processed solely by small models or require the involvement of large models. If the confidence of the small model exceeds a threshold, it processes the data; otherwise, the large model handles it, thus reducing costs based on different scheduling data for large and small models.
4 Conclusion and Outlook
Since large models can provide broad knowledge and powerful reasoning capabilities, while small models contribute specialized domain abilities and computational efficiency, a complementary advantage has been achieved; by reasonably allocating tasks, over-reliance on large models has been reduced, lowering overall computational costs and energy consumption. The prediction results refine the prediction space of large models. By integrating the prediction confidence of small models into prompts, the large model’s ability to discern other distributions can be enhanced. Prompt Transferring (PT) decomposes complex tasks into multiple sub-tasks, some of which can be handled by small models. This allows the large model to focus on the more challenging sub-tasks, thereby improving overall performance. Resource optimization has been achieved; small models handle specific tasks, improving overall response speed, while large models focus on complex issues, enhancing the overall performance of the system. Furthermore, the collaboration between large and small models dynamically adjusts the model combinations according to task requirements, enhancing the system’s adaptability in different scenarios. Large models can guide small models in knowledge updates; small models can provide large models with new knowledge from specialized fields, enabling them to continue learning.
In recent years, the research trend of large and small model collaboration has become increasingly evident, with related literature and applications continuously emerging, indicating that this direction has broad prospects in both academia and industry. Although our research work is still in its preliminary stages, these explorations provide important insights for the future development of large and small model collaboration. With the continuous optimization of collaboration mechanisms, large and small model collaboration will open up more possibilities for multi-modal tasks, complex reasoning, and the construction of intelligent systems in specialized fields.
(References omitted)

Join the Society for More Resources