

Truly, “Three cobblers with their wits combined equal Zhuge Liang” —
Three Agents based on open-source small models collaborate to achieve tool invocation effects comparable to GPT-4!
Without further ado, let’s look at the execution records of two systems.
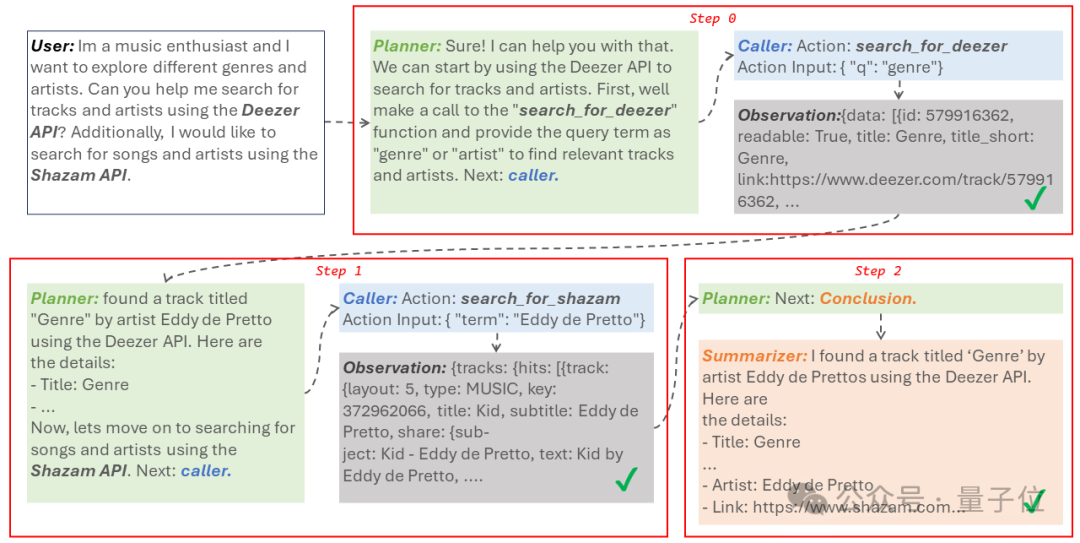
The user stated they are a music enthusiast and want to explore different music genres and musicians. Therefore, they specified the model to use the APIs of Deezer and Shazam to search for some music tracks and corresponding artist information.
Then, the three Agents, each playing different roles, collaborated to complete the task within two steps.
In a more challenging scenario, without specifying tools, the model was tasked to find the most popular landscape painting tutorial video and upload the channel details of that video.
In this case, the model usually encounters issues with changing tool states, such as tools being removed or changes in the required parameters for the tools.
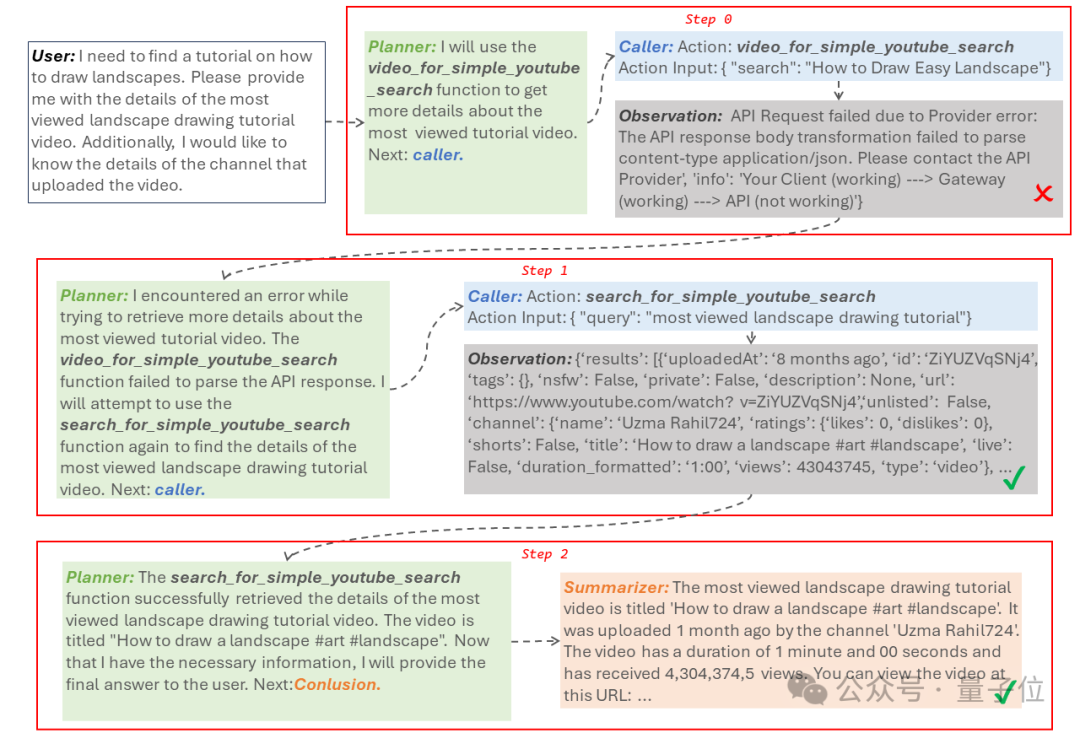
However, using the aforementioned method, the model attempted to use video_for_simple_youtube_search to obtain video details in step 0, but found that this API was broken and could not be called.
Thus, the Agent playing the planner role changed its approach, informing the caller role Agent to try another API, and ultimately discovered the details through a new API, solving the user’s task.
This is a collaborative Agent framework based on open-source small models proposed by Sun Yat-sen University and Alibaba Tongyi Laboratory — α-UMi.

α-UMi achieves collaborative operations through fine-tuning multiple open-source small models, achieving tool invocation effects comparable to GPT-4.
In summary, compared to other closed-source API frameworks, α-UMi has the following advantages:
-
Based on the α-UMi multi-model collaborative framework, three small models: planner, caller, and summarizer are responsible for path planning, tool invocation, and summarizing responses, respectively, offloading the workload of small models.
-
Compared to a single model Agent, it supports more flexible prompt design. It outperforms single model Agent frameworks on multiple benchmarks such as ToolBench, ToolAlpaca corpus, achieving performance comparable to GPT-4.
-
It proposes a “global-local” multi-stage fine-tuning paradigm (GLPFT), which successfully trains a multi-model collaborative framework on open-source small models. Experimental results indicate that this two-stage paradigm is currently the best training paradigm for exploring multi-model collaborative Agents and can be widely applied.
What Does the Multi-Model Collaborative Framework α-UMi Look Like?
Currently, tools learning Agents based on large models invoking APIs, functions, and code interpreters, such as OpenAI code interpreter, AutoGPT, etc., have attracted widespread attention in both industry and academia.
With the support of external tools, large models can autonomously complete more complex tasks such as web browsing, data analysis, address navigation, etc., thus AI Agents are regarded as an important direction for the practical application of large models.
However, some of the mainstream projects mentioned above are primarily based on closed-source ChatGPT and GPT-4 large models, which are already strong enough in reasoning, step planning, request generation, and summarizing responses.
In contrast, due to limitations in model capacity and pre-training capabilities, single open-source small models are unable to achieve performance comparable to large models across tasks such as reasoning, planning, tool invocation, and response generation simultaneously.
To address this issue, the researchers proposed α-UMi.
α-UMi consists of three small models: planner, caller, and summarizer.
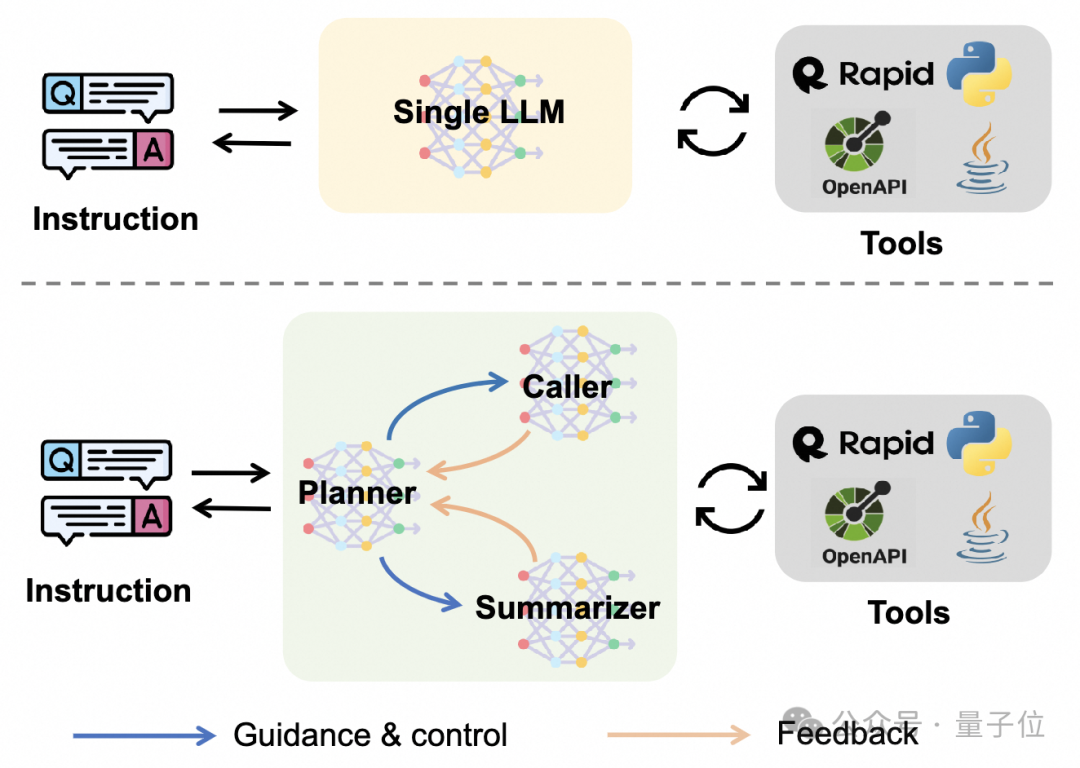
The planner model serves as the core brain of the system, responsible for activating the caller or summarizer within a certain Agent execution step and providing corresponding reasoning (rationale) guidance;
while the caller and summarizer are responsible for receiving the planner’s guidance to complete subsequent work, with the caller generating instructions for tool interaction, and the summarizer summarizing the final response to feedback to the user.
All three models are fine-tuned on different types of data based on open-source small models.
Additionally, the researchers proposed the global-local multi-stage fine-tuning paradigm — GLPFT.
Implementing a multi-model collaborative framework based on open-source small models is not a simple task, as there are two opposing influencing factors:
One is that generating Rationale, Action, and Final Answer tasks can promote each other during training, enhancing the model’s overall understanding of Agent tasks. Therefore, most current work trains a single model to generate rationale, action, and final answer simultaneously.
The second is model capacity and the data ratio for different tasks, which also limit our ability to train a single model to achieve peak performance across all three tasks simultaneously.
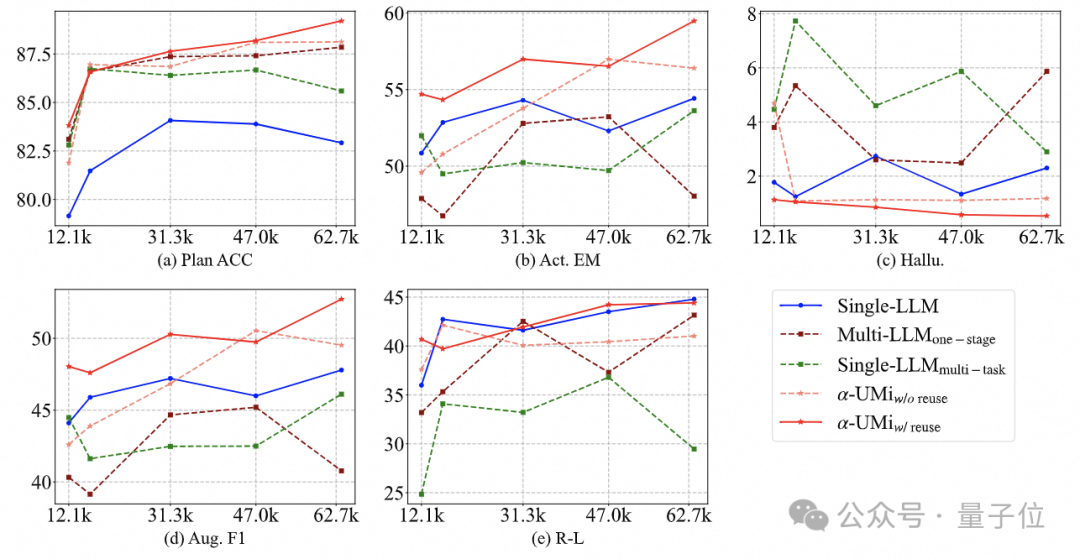
As shown in the figure below, the amount of data required for a single model Agent to reach peak performance varies across different metrics, making it difficult to find a dataset and model checkpoint that achieves peak performance across all metrics.
Through multi-model collaboration, this issue can be resolved.
Considering the above two points, the researchers proposed a “global-local” multi-stage training method aimed at taking full advantage of the mutual promotion of Rationale, Action, and Final Answer during training to obtain a better single model initialization, followed by multi-model fine-tuning focusing on improving sub-task performance.
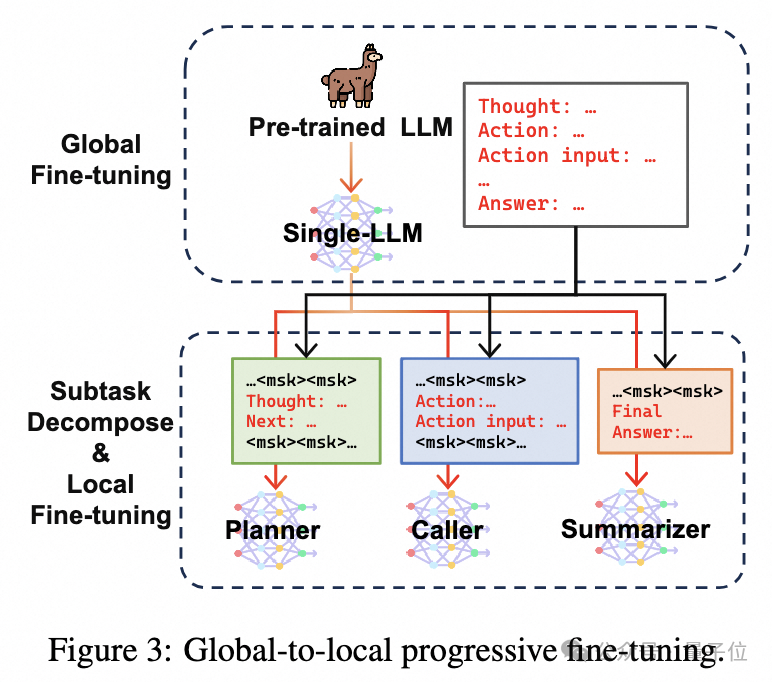
The above figure illustrates the process of this multi-stage fine-tuning. In the first stage, a pre-trained LLM is fine-tuned to complete the tool invocation Agent task, obtaining a single model Agent LLM initialization.
Next, in the second stage, the researchers reconstructed the training data for the tool invocation Agent task, decomposing it into three sub-tasks: generating rationale, generating tool interaction actions, and generating final responses, and replicated the single-LLM Agent base trained in the first stage three times, further fine-tuning each on different sub-tasks.
Performance Comparable to GPT-4
Static Evaluation
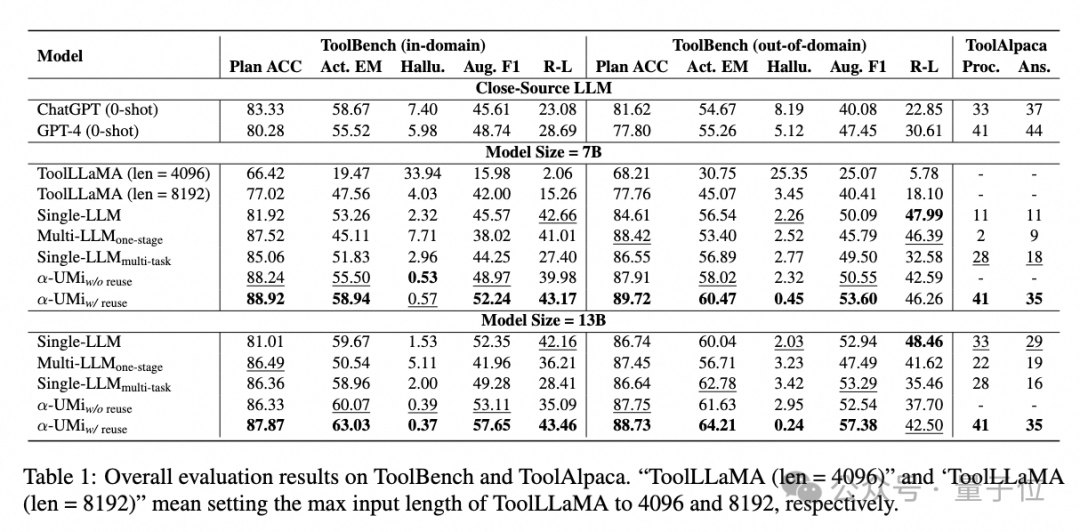
In static evaluations, the outputs of all baseline comparisons were compared with annotated outputs, and it can be seen that:
-
The α-UMi system significantly outperformed ChatGPT and the open-source model ToolLLaMA, achieving performance comparable to GPT-4.
It is worth mentioning that ToolLLaMA requires an output length of 8192 to achieve satisfactory results, while α-UMi only needs an input length of 4096, thanks to the more flexible prompt design brought by the multi-model framework.
-
In the comparison of fine-tuning schemes for multi-model collaborative framework models, directly fine-tuning three models or multi-task fine-tuning of a single model cannot enable the multi-model collaborative framework to perform effectively; only using the multi-stage fine-tuning GLPFT can achieve optimal performance, opening up new ideas for subsequent multi-model collaborative training.
Real API Call Evaluation
The authors also introduced a real API call evaluation method on the ToolBench dataset, with the experimental results as follows:
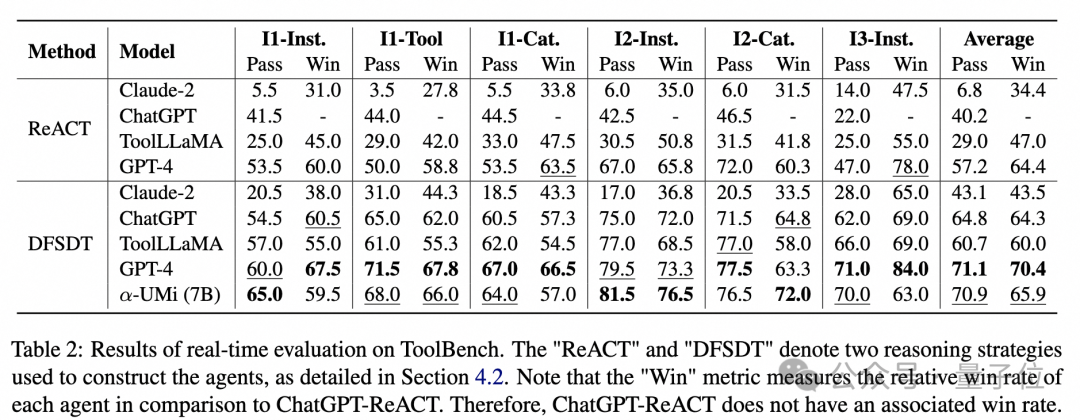
In the real API call experimental results, α-UMi still outperformed ChatGPT and ToolLLaMA, achieving a success rate comparable to GPT-4.
Model Costs
Seeing this, some may ask, will multi-model collaboration introduce more costs? The authors also explored the cost comparisons of the multi-model collaborative framework in training, inference, and storage phases:
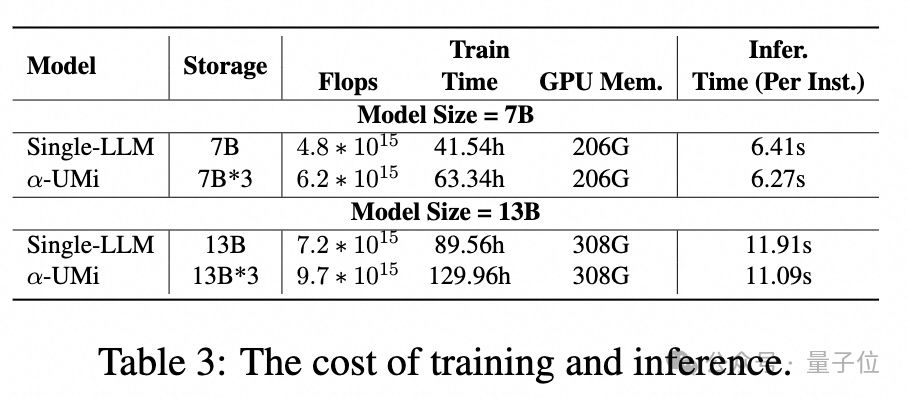
Overall, the multi-model collaborative framework does introduce higher costs in training and model parameter storage, but its inference speed is comparable to single model frameworks.
Of course, considering that the performance of a multi-model collaborative Agent framework using a 7B base far exceeds that of a 13B single model Agent, the overall cost is also lower. This means that it is possible to choose a multi-model collaborative Agent framework based on small models to reduce costs while exceeding the performance of large model single Agent frameworks.
Finally, the researchers concluded that multi-agent collaboration is the trend for future Agent development, and how to train and enhance the multi-agent collaboration capabilities of open-source small models is a crucial aspect for practical implementation. This paper opens up new ideas for multi-agent collaboration based on open-source small models and achieves tool invocation results that exceed single model Agent baselines, comparable to GPT-4, across multiple tool invocation benchmarks.
In the future, they will enhance the generalization of the planner to apply to a wider range of Agent task scenarios, localize the caller model for private use, focusing on local tool invocation tasks, and create a “large-small” model collaborative framework that combines cloud-based large models with local small models.
Project links: [1]https://arxiv.org/abs/2401.07324[2]https://github.com/X-PLUG/Multi-LLM-agent[3]https://modelscope.cn/models/iic/alpha-umi-planner-7b/summary

Scan the QR code to add the assistant WeChat
About Us
