MLNLP community is a well-known machine learning and natural language processing community, covering graduate students, university professors, and researchers in enterprises both domestically and internationally.The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for beginners.Reprinted from | Qingke AIAuthor | Li Haochen
This work primarily outlines the planning capabilities in LLM-based agents.
Paper: Understanding the planning of LLM agents: A survey
ArXiv: https://arxiv.org/abs/2402.02716
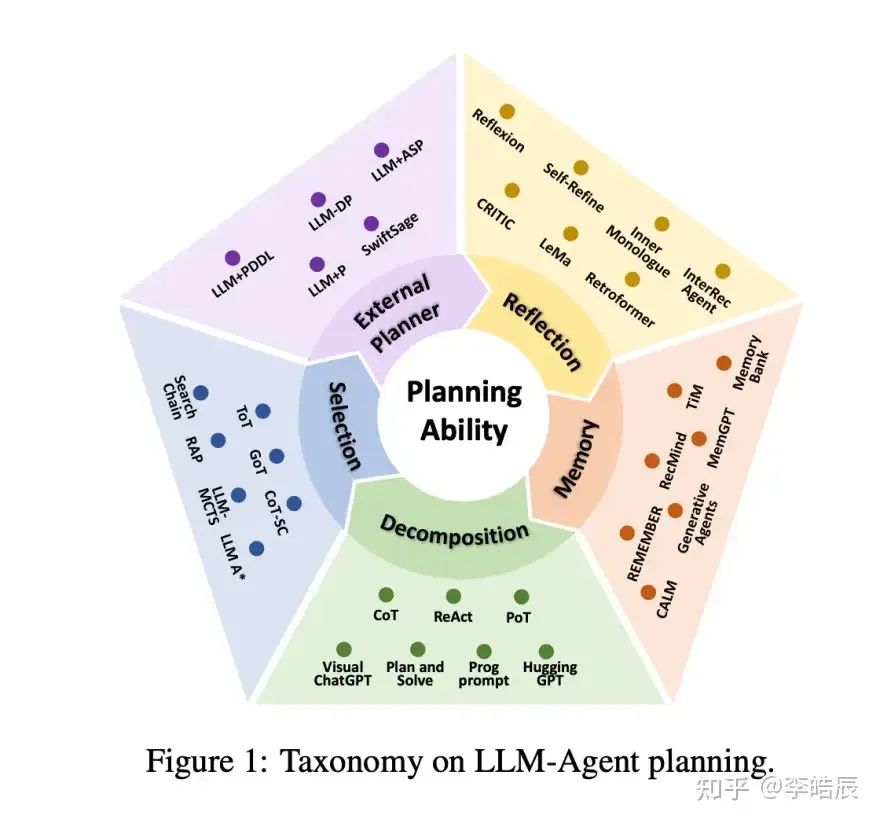
In the article, the author further breaks down the planning capability into five dimensions:
• Task Decomposition• Plan Selection• External Planner• Reflection and Refinement• Memory
1. Introduction
• Autonomous Intelligent Agents: Defined as intelligent entities capable of completing specific tasks. They achieve their goals by perceiving the environment, planning, and executing actions.• Importance of Planning: Planning is one of the most critical abilities of an agent, requiring complex understanding, reasoning, and decision-making processes.• General Representation of Planning Tasks: Given a time step, the environment is represented as , action space as , task goal as , and action at time step as . The planning process can be expressed as generating a sequence of actions: . Where and represent the parameters of the LLM and the prompts for the task, respectively.• Limitations of Traditional Methods: Previous works mainly relied on symbolic methods or reinforcement learning-based approaches, such as Planning Domain Definition Language (PDDL) or policy learning. These traditional methods have limitations, such as requiring human expertise to convert natural language problem descriptions into symbolic modeling, and lacking fault tolerance. Reinforcement learning methods often require a large number of samples (interactions) with the environment to learn effective strategies, which may be impractical in time-consuming or costly data collection scenarios.• Potential of LLMs: In recent years, the emergence of large language models (LLMs) marks a paradigm shift. LLMs have achieved significant success in various fields, demonstrating important intelligence in reasoning, tool usage, planning, and instruction following. This intelligence provides the possibility of using LLMs as the cognitive core of agents, potentially enhancing planning capabilities.• This Work: Although there have been surveys attempting to summarize the technologies of LLMs, the literature often lacks detailed analysis of planning capabilities. This survey aims to analyze the latest research works, discuss advantages and limitations, and provide a systematic perspective on planning capabilities in LLM-based agents.
2. Task Decomposition
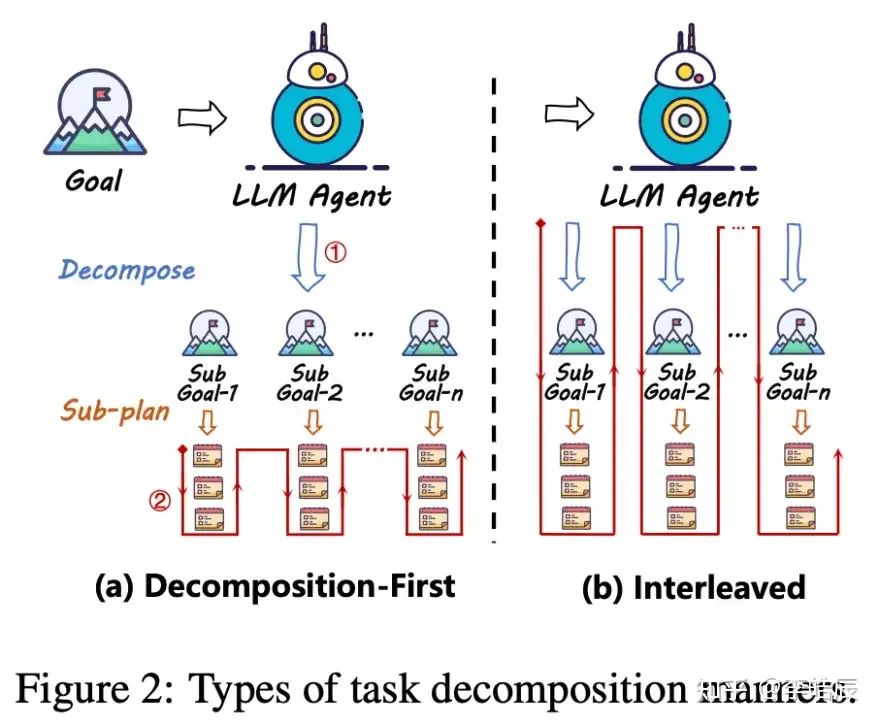
Tasks in the real world are often complex and multi-step, making it a significant challenge to solve complex tasks directly through a single-step planning process. Task decomposition makes the planning process more feasible by breaking complex tasks into multiple simpler subtasks.
Classification of Decomposition Methods: Task decomposition methods are mainly divided into two categories:
• Decomposition-First Methods: First decompose the task into sub-goals, then sequentially formulate rules for each sub-goal.• Interleaved Decomposition Methods: Interleave between task decomposition and subtask planning, revealing one or two subtasks of the current state at a time.
Representative Works of Decomposition-First Methods:
• HuggingGPT: LLM as a controller responsible for decomposing human-input tasks into subtasks, selecting models, and generating final responses.• Plan-and-Solve: Transforms the original “let’s think step by step” into two-step prompt instructions: “First, we make a plan” and “We execute the plan”.• ProgPrompt: Transforms natural language described tasks into coding problems, formalizing each action as a function and each object as a variable.
Representative Works of Interleaved Decomposition Methods:
• **Chain-of-Thought (CoT)**: Guides LLM in reasoning about complex problems through constructed trajectories, leveraging LLM’s reasoning capabilities for task decomposition.• Zero-shot CoT: Uses the instruction “let’s think step by step” to unlock LLM’s zero-shot reasoning capabilities.• ReAct: Decouples reasoning and planning, alternating between reasoning (thinking steps) and planning (action steps).
Discussion:
• The advantage of decomposition-first methods lies in creating a strong association between subtasks and the original task, reducing the risk of task forgetting and hallucinations. However, additional adjustment mechanisms are needed to avoid overall failure due to errors in a single step.• Interleaved decomposition methods can dynamically adjust decomposition based on environmental feedback, improving fault tolerance. However, for complex tasks, overly long trajectories may lead LLM to hallucinate, deviating from the original goal.• Challenges: Although task decomposition significantly enhances the ability of LLM agents to solve complex tasks, challenges remain, including the additional overhead, time costs, and computational costs introduced by task decomposition, as well as the context length limitations of LLMs.
3. Multi-Plan Selection
Due to the complexity of tasks and the inherent uncertainty of LLMs, LLM agents may generate multiple different plans for a given task. Multi-plan generation involves utilizing the uncertainty in the decoding process of generative models to produce multiple candidate plans through different sampling strategies.
• Self-consistency: Adopts a simple intuition that solutions to complex problems are rarely unique. Obtains multiple different reasoning paths through temperature sampling, top-k sampling, etc.• Tree-of-Thought (ToT): Proposes two strategies, “sampling” and “proposing,” to generate plans. LLM samples multiple plans during the decoding process and generates various plans through a few example prompts.• Graph-of-Thought (GoT): Builds upon ToT by adding thought transformations, supporting the aggregation of arbitrary thoughts. – LLM-MCTS and RAP: Utilize LLM as a heuristic strategy function to obtain multiple potential actions using the Monte Carlo Tree Search (MCTS) algorithm.
Optimal Plan Selection: Various heuristic search algorithms are employed when selecting the optimal plan among candidate plans.
• Self-consistency: Uses a simple majority voting strategy, viewing the plan with the most votes as the optimal choice.• Tree-of-Thought (ToT): Supports tree search algorithms, such as breadth-first search (BFS) and depth-first search (DFS), using LLM to evaluate multiple actions and select the optimal action.• LLM-MCTS and RAP: Also use tree structures to assist multi-plan searches, but they employ the MCTS algorithm for searching.• LLM A: Utilizes the classic A algorithm to assist LLM in searching, using the Chebyshev distance from the current position to the target position as a heuristic cost function to select the optimal path.
Discussion:
• The scalability of multi-plan selection significantly enhances the ability to explore potential solutions more broadly in vast search spaces.• However, this advantage comes with increased computational demands, particularly for models with a large token count or computations, which is especially important in resource-constrained situations.• The role of LLMs in planning evaluation introduces new challenges, as the performance of LLMs in task ranking is still under scrutiny and requires further validation and fine-tuning of their capabilities in this specific context.• The stochastic nature of LLMs adds randomness to the selection process, potentially affecting the consistency and reliability of the selected plans.
4. External Planner-Aided Planning
Although LLMs have demonstrated strong capabilities in reasoning and task decomposition, they still face challenges when confronted with environments with complex constraints, such as mathematical problem-solving or generating executable actions.
Method Classification: Depending on the type of planner introduced, these methods can be divided into two categories:
• Symbolic Planner: Based on formal models, such as PDDL, using symbolic reasoning to find the optimal path from the initial state to the goal state.• Neural Planner: Deep models trained using reinforcement learning or imitation learning techniques, demonstrating effective planning capabilities for specific domains.
Representative Works of Symbolic Planners:
• LLM+P: Combines a PDDL-based symbolic planner, using LLM to organize problems into PDDL language format, and utilizes the Fast Downward solver for planning.• LLM-DP: Specifically designed for dynamic interactive environments, formalizing environmental feedback information into PDDL language and using BFS solver to generate plans.• LLM+PDDL: Adds a manual verification step in the PDDL model generated by LLM and proposes using the planning generated by LLM as the initial heuristic solution for local search planners.• LLM+ASP: Converts natural language described tasks into ASP problems, then uses the ASP solver CLINGO to generate plans.
Representative Works of Neural Planners:
• CALM: Combines language models with RL-based neural planners, using language models to generate candidate actions, then re-ranking them using the DRRN strategy network to select the optimal action.• SwiftSage: Divides the planning process into fast thinking and slow thinking, with fast thinking implemented through a DT model trained by imitation learning, while slow thinking involves LLM reasoning and planning based on the current state.
Discussion:
• In these strategies, LLM mainly plays a supporting role, with its primary functions including parsing text feedback and providing additional reasoning information to assist in planning, especially when solving complex problems.• Traditional symbolic AI systems are complex and rely on human experts when constructing symbolic models, whereas LLMs can accelerate this process, helping to establish symbolic models more quickly and effectively.• The advantages of symbolic systems include theoretical completeness, stability, and interpretability. The combination of statistical AI and LLM is expected to become a major trend in the future development of artificial intelligence.
5. Reflection and Refinement
Feedback and refinement are indispensable components of the planning process, enhancing the fault tolerance and error correction capabilities of LLM agents. Since LLMs may generate hallucinations or have insufficient reasoning capabilities in complex problems during the planning process, reflecting on and summarizing failures helps agents correct errors and break cycles in subsequent attempts.
• Self-refine: Utilizes an iterative process involving generation, feedback, and refinement. After each generation, LLM provides feedback on the plan, facilitating feedback-based adjustments.• Reflexion: Extends the ReAct method by introducing an evaluator to assess trajectories. LLM generates self-reflection upon detecting errors, aiding in error correction.• CRITIC: Uses external tools, such as knowledge bases and search engines, to verify actions generated by LLM. Then utilizes external knowledge for self-correction, significantly reducing factual errors.• InteRecAgent: Employs a self-correction mechanism called ReChain. LLM is used to evaluate responses and tool usage plans generated by interactive recommendation agents, summarizing error feedback and deciding whether to re-plan.• LEMA: First collects samples of erroneous plans, then uses a more powerful GPT-4 for correction. These corrected samples are subsequently used to fine-tune LLM agents, achieving significant performance improvements across various scales of LLaMA models.
Discussion:
• Self-reflection strategies are similar to principles of reinforcement learning, where agents act as decision-makers, and environmental feedback triggers updates in the strategy network. However, unlike deep reinforcement learning, which updates by modifying model parameters, in LLM agents, this update is achieved through the self-reflection of LLM, ultimately forming text-based feedback.• This text feedback can serve as long-term and short-term memory, influencing the subsequent planning outputs of the agent through prompts. However, there is currently no conclusive evidence that this text-based update ultimately enables LLM agents to achieve specific goals.
6. Memory-Augmented Planning
Memory is a key avenue for enhancing the planning capabilities of agents, helping them learn from experience and adapt to new situations.
RAG-based Memory:
• Concept: Uses Retrieval-Augmented Generation (RAG) technology to store memory in text form and retrieve it when needed to assist in planning.• Methods: Such as MemoryBank, TiM, and RecMind, these methods encode memory into vectors using text encoding models and establish indexing structures for retrieving experiences related to the current task during planning.
Embodied Memory:
• Concept: Enhances memory capability by embedding the agent’s historical experience samples into the model parameters through fine-tuning.• Methods: Such as CALM and TDT, these methods use data collected from the agent’s interactions with the environment to fine-tune the model, enabling it to remember planning-related information and perform better in planning tasks.
Memory Update Methods:
• RAG-based: Provides real-time, low-cost external memory updates but relies on the accuracy of retrieval algorithms.• Finetuning: Offers greater memory capacity but comes with higher costs for memory updates and challenges in retaining details.
Discussion:
• Memory-augmented LLM agents exhibit stronger growth potential and fault tolerance in planning, but memory generation largely depends on the generative capabilities of LLMs themselves.• Enhancing the capabilities of weaker LLM agents through self-generated memory remains a challenging area.
Challenges:
Despite the advantages of memory-augmented LLM agents in planning, they still face challenges in memory generation, particularly in self-generated memory.
7. Evaluation
Evaluating the planning capabilities of agents is a key issue in the research field. The author investigates several mainstream benchmarking methods and classifies them into the following categories:
Interactive Gaming Environments:
• Provide real-time multimodal feedback based on agent actions, such as text and visual feedback.• For example, in Minecraft, agents need to collect materials to craft tools for more rewards, with common evaluation metrics being the number of tools created by the agent.
Text-based Interactive Environments:
• Agents are situated in environments described in natural language, with limited actions and positions.• Common evaluation metrics include success rates or rewards obtained, such as in ALFWorld and ScienceWorld.
Interactive Retrieval Environments:
• Simulate the process of human information retrieval and reasoning in real life.• Agents can interact with search engines and other web services, obtaining more information by searching keywords or executing clicks, forward, and backward operations to complete Q&A tasks or information retrieval tasks.
Interactive Programming Environments:
• Simulate the interaction between programmers and computers, testing the planning capabilities of agents in solving computer-related problems.• Agents need to interact with computers by writing code or instructions to solve problems.
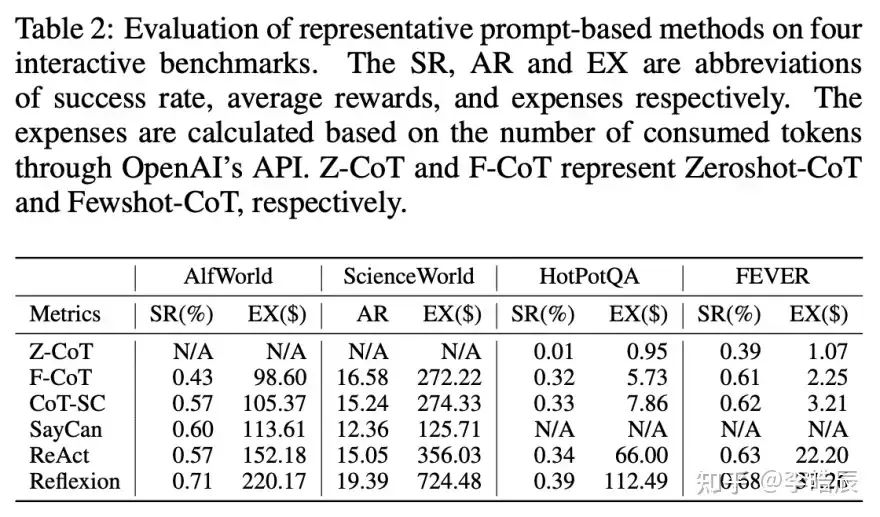
Experiments:
The author conducted experiments on four benchmark tests to verify the performance of representative methods. These benchmarks include ALFWorld, ScienceWorld, HotPotQA, and FEVER, covering interactive gaming and Q&A benchmarks.The experimental results show that performance improves with increased costs, indicating that more detailed thinking (i.e., consuming more tokens) can lead to performance enhancements.Additionally, for complex tasks, examples (e.g., Zero-shot CoT and Few-shot CoT) are crucial for LLMs to further understand tasks.Reflection plays a key role in improving success rates, especially in complex tasks, demonstrating LLM’s error correction capabilities.
Discussion:
Most existing benchmark tests rely on the final completion state of tasks, lacking fine-grained step-by-step evaluations.Environmental feedback is often regularized, simplified, and distanced from real-world scenarios.Future directions may include utilizing high-intelligence models like LLMs to design more realistic evaluation environments.
8. Conclusions and Future Directions
• Summary of Progress: Since LLMs have exhibited intelligence, research on enhancing agent planning capabilities using LLMs has received increasing attention. The author outlines the main research directions and provides detailed comparisons and analyses of various methods in the text.• Experimental Results: The author conducted experiments on four benchmark tests, comparing the effectiveness of several representative methods, and noted that performance increased with higher input costs.• Challenges: Despite the enhancements in planning capabilities, several significant challenges remain:• Hallucination Issues: LLMs may generate hallucinations during the planning process, leading to irrational plans or inability to follow complex instructions.• Feasibility of Generated Plans: Compared to symbolic AI, LLMs may struggle to adhere to complex constraints during optimization, resulting in plans lacking feasibility.• Efficiency of Plans: The planning processes of existing LLM agents may not consider the efficiency of generated plans, and future developments may require the introduction of additional efficiency evaluation modules.
Future Directions:
• Multimodal Environmental Feedback: Consider integrating the development of multimodal large models and re-evaluating relevant planning strategies to handle multimodal feedback, including images and audio.• Fine-Grained Evaluation: Utilize high-intelligence models like LLMs to design more realistic evaluation environments, providing more detailed step-by-step evaluations to better simulate real-world scenarios.Technical Group Invitation:
△ Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue Systems)to apply to join the Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from home and abroad, which has developed into a well-known machine learning and natural language processing community, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing.The community can provide an open communication platform for relevant practitioners’ further education, employment, and research. Everyone is welcome to pay attention to and join us.