MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university professors, and researchers from enterprises.
The vision of the community is to promote communication and progress between the academic and industrial worlds of natural language processing and machine learning, especially for the advancement of beginners.
Reprinted from | Machine Heart
The research team led by Professor Wang Haofen from Tongji University and Professor Xiong Yun from Fudan University has published a comprehensive review on Retrieval-Augmented Generation (RAG), covering core paradigms, key technologies, and future development trends. This work provides researchers with a clear blueprint for the development of RAG technology, pointing out future research exploration directions. At the same time, it offers developers a reference to help identify the advantages and disadvantages of different technologies and guide the most effective use of these technologies in diverse application scenarios.
Large language models (LLMs) have become part of our lives and work, transforming the way we interact with information through their astonishing versatility and intelligence.
However, despite their impressive capabilities, they are not without flaws. These models can produce misleading “hallucinations,” the information they rely on may be outdated, and they may be inefficient in handling specific knowledge, lacking in-depth insights into specialized fields, while also falling short in reasoning abilities.
In real-world applications, data needs to be constantly updated to reflect the latest developments, and the generated content must be transparent and traceable to control costs and protect data privacy. Therefore, simply relying on these “black box” models is insufficient; we need more refined solutions to meet these complex demands.
It is against this backdrop that Retrieval-Augmented Generation technology (RAG) has emerged as a major trend in the AI era.
RAG enhances the accuracy and relevance of content by first retrieving relevant information from a vast document database before the language model generates answers, thereby guiding the generation process. RAG effectively alleviates the hallucination problem, increases the speed of knowledge updates, and enhances the traceability of content generation, making large language models more practical and trustworthy in real-world applications. The emergence of RAG is undoubtedly one of the most exciting developments in the field of artificial intelligence research.
This review will provide you with a comprehensive understanding of RAG, exploring its core paradigms, key technologies, and future trends, offering readers and practitioners an in-depth and systematic insight into large models and RAG, while elaborating on the latest advancements and key challenges in retrieval-augmented technologies.
-
Original paper: https://arxiv.org/abs/2312.10997
-
Official repository: https://github.com/Tongji-KGLLM/RAG-Survey
What is RAG?
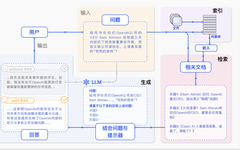
Figure 1 Example of RAG technology in QA problems
A typical example of RAG is illustrated in the figure. If we ask ChatGPT about OpenAI CEO Sam Altman’s sudden firing and subsequent reinstatement within a few days. Due to the limitations of pre-training data and a lack of knowledge about recent events, ChatGPT states that it cannot answer. RAG addresses this gap by retrieving the latest document excerpts from an external knowledge base. In this example, it acquires a series of news articles related to the inquiry. These articles, along with the original question, are then merged into a rich prompt, enabling ChatGPT to synthesize a well-informed response.
Development of RAG Technology Paradigms
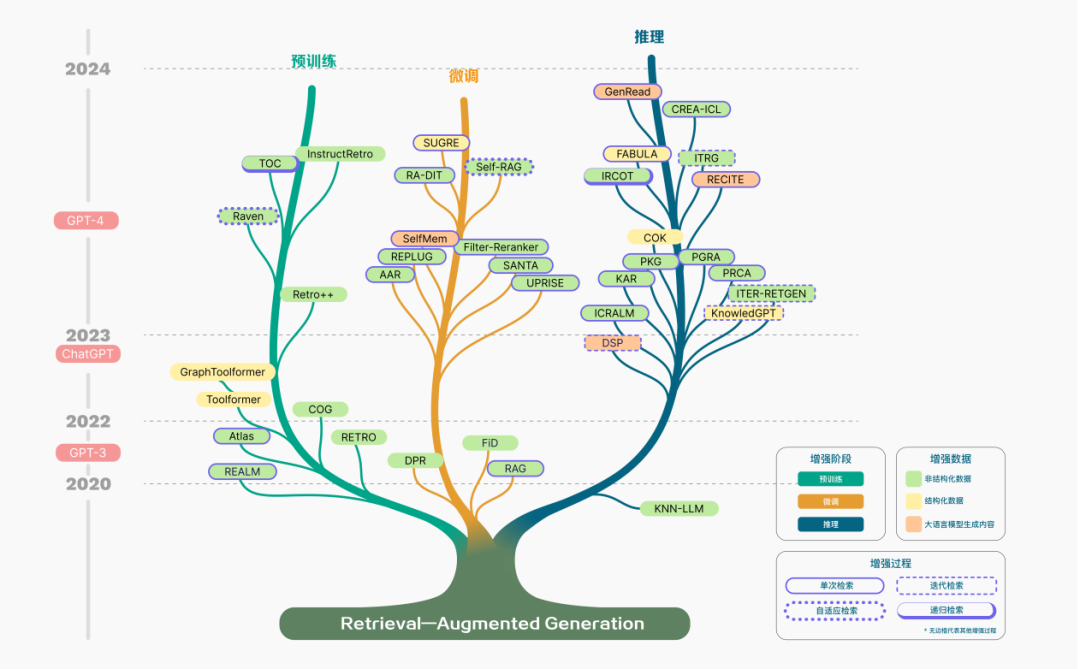
The concept of RAG was first proposed in 2020 and has since entered a rapid development phase. The evolution of RAG technology can be clearly divided into several key stages. In the early pre-training phase, the focus of research was on how to inject additional knowledge through pre-trained models to enhance the capabilities of language models. With the emergence of ChatGPT, interest in using large models for deep contextual learning surged, driving rapid development of RAG technology in research. As the potential of LLMs is further developed, research on RAG gradually focuses on enhancing reasoning capabilities and explores various improvement methods during the fine-tuning process. Particularly with the release of GPT-4, RAG technology underwent a profound transformation. Research focus began to shift towards a new method that integrates RAG and fine-tuning strategies while continuously optimizing pre-training methods.
Figure 2 Technology tree of RAG development
In the process of RAG’s technological development, we summarize its stages from the perspective of technological paradigms as follows:
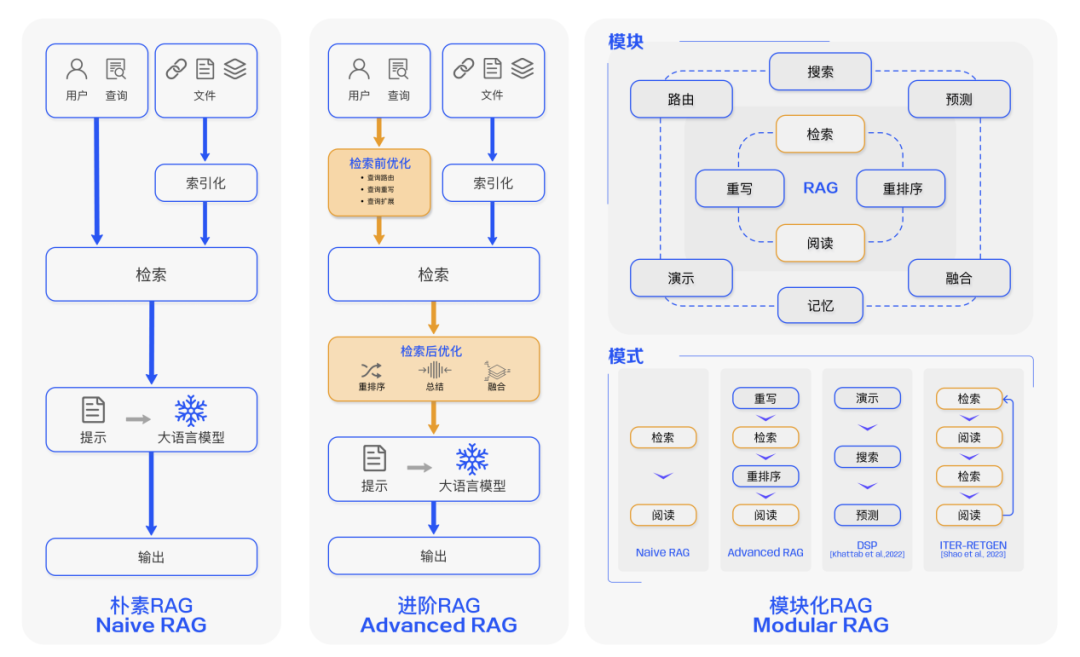
The classic RAG process demonstrated in the previous example is also known as Naive RAG. It mainly includes three basic steps:
1. Indexing — Splitting the document library into shorter chunks and building a vector index using an encoder.
2. Retrieval — Retrieving relevant document fragments based on the similarity between the question and the chunks.
3. Generation — Generating answers to questions conditioned on the retrieved context.
Naive RAG faces several challenges in retrieval quality, response generation quality, and enhancement processes. The Advanced RAG paradigm was subsequently proposed, incorporating additional processing both before and after retrieval. By enhancing text consistency, accuracy, and retrieval efficiency through more refined data cleaning, designing document structures, and adding metadata, the quality of the retrieval process can be improved. In the pre-retrieval phase, semantic differences between questions and document chunks can be aligned using methods such as question rewriting, routing, and expansion. In the post-retrieval phase, reordering the retrieved document library can avoid the “Lost in the Middle” phenomenon, or the window length can be shortened through context filtering and compression.
As RAG technology further develops and evolves, new techniques break away from the traditional Naive RAG retrieval-generation framework, leading us to propose the concept of Modular RAG. Structurally, it is more free and flexible, introducing more specific functional modules, such as query search engines and integrating multiple answers. Technically, it merges retrieval with fine-tuning, reinforcement learning, and other techniques. In terms of process, it designs and orchestrates the RAG modules, resulting in various RAG modes. However, Modular RAG did not emerge suddenly; the three paradigms are related through inheritance and development. Advanced RAG is a specific form of Modular RAG, while Naive RAG is a specific form of Advanced RAG.
Figure 3 Comparison of RAG paradigms
How to Implement Retrieval-Augmented Generation?
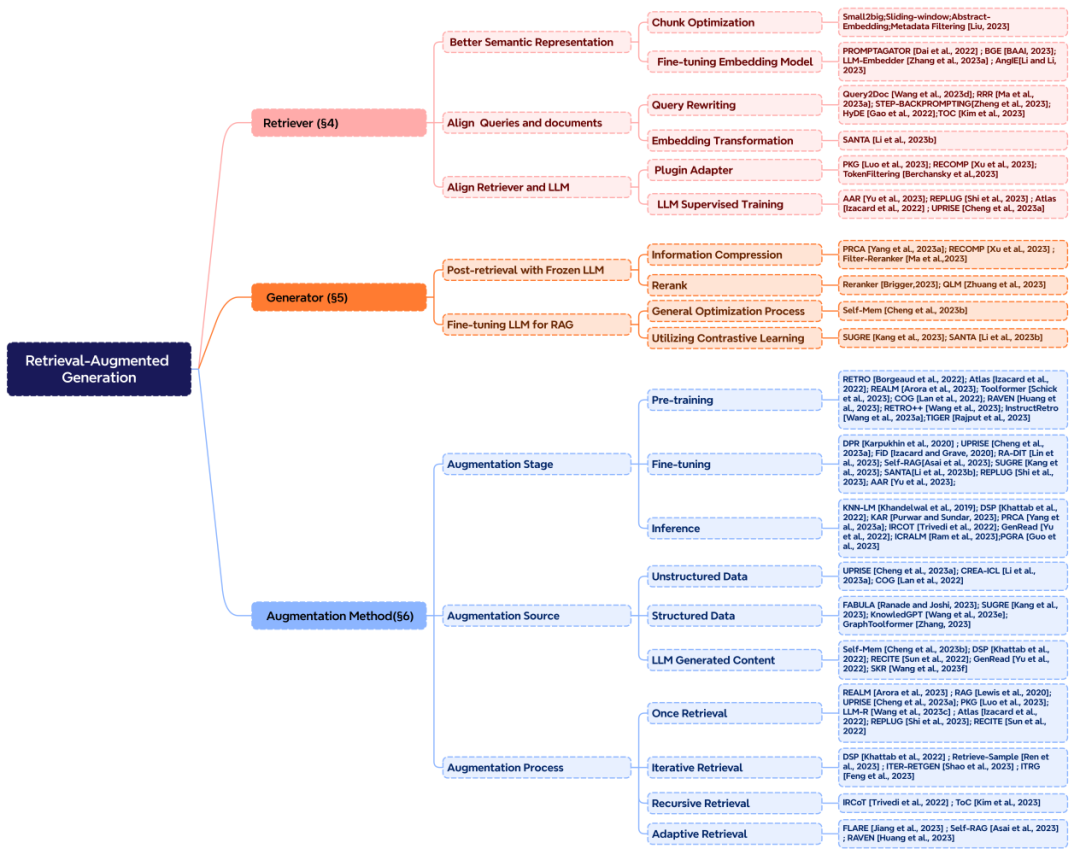
The RAG system mainly includes three core components: “Retrieval,” “Augmentation,” and “Generation,” which correspond to the three initials of RAG. To build a good RAG system, the augmentation part is key, and three critical questions need to be considered: What to retrieve? When to retrieve? How to use the retrieved content?
Stages of retrieval augmentation: Retrieval augmentation can occur during the pre-training, fine-tuning, and inference stages, determining the degree of external knowledge parameterization, which corresponds to different computational resource requirements.
Data sources for retrieval augmentation: Augmentation can utilize various forms of data, including unstructured text data such as text paragraphs, phrases, or individual words. Additionally, structured data can be leveraged, such as indexed documents, triple data, or subgraphs. Another approach is to rely on the internal capabilities of LLMs, retrieving content generated by the model itself.
The process of retrieval augmentation: The initial retrieval is a one-time process, while in the development of RAG, iterative retrieval, recursive retrieval, and adaptive retrieval methods, where LLMs determine when to retrieve, have gradually emerged.
Figure 4 Classification system of RAG core components
How to Choose Between RAG and Fine-Tuning?
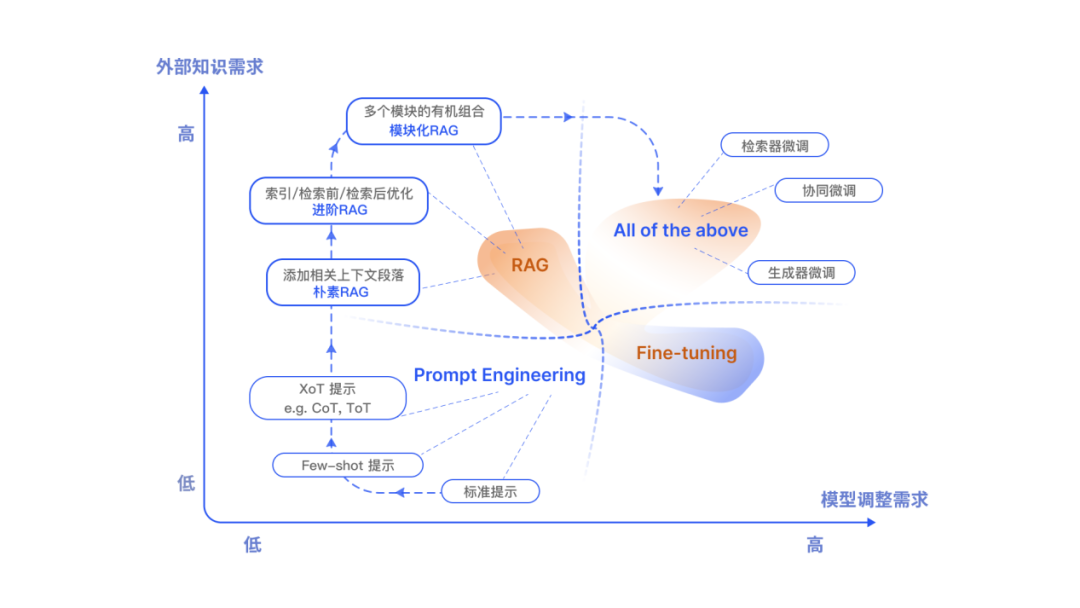
In addition to RAG, the main optimization methods for LLMs also include prompt engineering and fine-tuning (FT). They each have their unique characteristics. Depending on the reliance on external knowledge and the requirements for model adjustments, each has suitable scenarios.
RAG is like giving the model a textbook for customized information retrieval, making it particularly suitable for specific queries. On the other hand, FT is like a student internalizing knowledge over time, making it more suitable for mimicking specific structures, styles, or formats. FT can improve the model’s performance and efficiency by enhancing the foundational model’s knowledge, adjusting outputs, and teaching complex instructions. However, it is less adept at integrating new knowledge or rapidly iterating new use cases. RAG and FT are not mutually exclusive; they can be complementary, and using them together may yield the best performance.
Figure 5 Comparison of RAG with other large model fine-tuning techniques
How to Evaluate RAG?
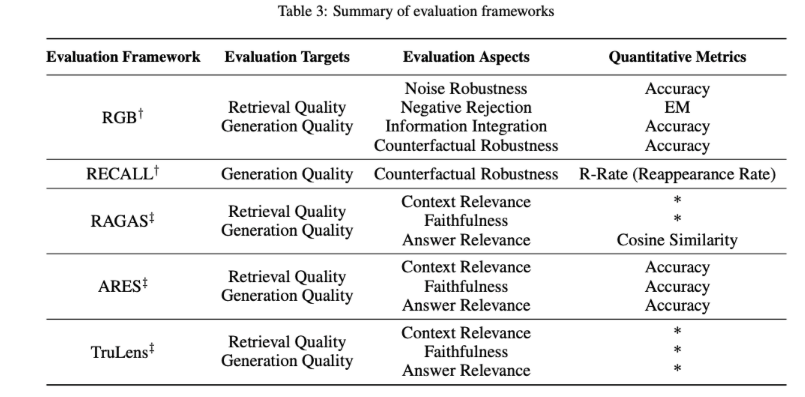
The evaluation methods for RAG are diverse, mainly including three quality scores: contextual relevance, answer fidelity, and answer relevance. Additionally, evaluation involves four key capabilities: noise robustness, refusal capability, information integration, and counterfactual robustness. These evaluation dimensions combine traditional quantitative metrics with specialized evaluation standards for RAG, although these standards have not yet been unified.
In terms of evaluation frameworks, there are benchmark tests such as RGB and RECALL, as well as automated evaluation tools like RAGAS, ARES, and TruLens, which help comprehensively measure the performance of RAG models. The table summarizes how traditional quantitative metrics can be applied to RAG evaluation and the evaluation content of various RAG evaluation frameworks, including the objects, dimensions, and metrics of evaluation, providing valuable insights for understanding the performance and potential applications of RAG models.
What are the Future Prospects for RAG?
The development of RAG is still in its early stages, and there are several issues worth further research. We will explore from three aspects:
1. Vertical Optimization of RAG
Vertical optimization aims to further address the challenges currently faced by RAG;
Long document length. What to do if the retrieved content exceeds the window limit? If the context window of LLMs is no longer limited, how should RAG improve?
Robustness. How to handle incorrect content retrieved? How to filter and verify retrieved content? How to enhance the model’s ability to resist noise and toxicity?
Collaboration with fine-tuning. How to leverage the effects of both RAG and FT simultaneously? How to organize them: serially, alternately, or end-to-end?
Scaling Law: Does the RAG model comply with the Scaling Law? Under what scenarios might RAG exhibit the phenomenon of Inverse Scaling Law?
The role of LLMs. How can LLMs be used for retrieval (replacing retrieval with LLMs’ generation or retrieving LLMs’ memory), for generation, and for evaluation? How to further explore the potential of LLMs in RAG?
Engineering practice. How to reduce retrieval latency for ultra-large-scale corpora? How to ensure that retrieved content is not leaked by large models?
2. Multimodal Expansion of RAG
How to continually expand the evolving technologies and ideas of RAG into other modalities of data such as images, audio, video, or code? This can enhance single-modal tasks and also integrate multiple modalities through the ideas of RAG.
The application of RAG is no longer limited to question-answer systems; its influence is expanding into more fields. Now, various tasks such as recommendation systems, information extraction, and report generation are beginning to benefit from the application of RAG technology. Meanwhile, the RAG technology stack is also booming. In addition to known tools like Langchain and LlamaIndex, more targeted RAG tools are emerging in the market, such as customization for specific use cases, simplifying usage to lower the entry barrier, and specializing functions gradually aimed at production environments.
Figure 6 Overview of the RAG ecosystem
For more details, please refer to the original paper.
Technical Communication Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue Systems)
to apply for joining the Natural Language Processing/PyTorch technical communication group.
About Us
MLNLP community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from both domestic and international backgrounds. It has now developed into a well-known community for machine learning and natural language processing, aiming to promote progress among the academic and industrial circles of machine learning and natural language processing as well as enthusiasts.
The community can provide an open communication platform for practitioners in further education, employment, and research. Everyone is welcome to follow and join us.